Check out the different ways to ingest data into Elasticsearch and dive into practical examples to try something new.
Elasticsearch is packed with new features to help you build the best search solutions for your use case. Start a free cloud trial or try Elastic on your local machine now.
Extracting content from binary files is a common use case. Some PDF files can be huge — think GB or more. Elastic has come a long way in handling documents like this, and today, we're excited to discuss our new tool, the Data Extraction Service:
- Released in 8.9
- To date, no bugs reported!
- As of today, the code is free and open!
To put this in its context, this blog will walk you through our journey to get here:
- Starting with using Apache Tika as a library in Workplace Search, with a 20 MB download limit
- Hacking around this limit and going up to 100 MB by leveraging the Elasticsearch Attachment Processor
- Obliterating limits altogether and ingesting file content in the gigabytes with our new tool, the Data Extraction Service
- Our aspirations for future evolution
Background: Handling binary documents at Elastic
At Elastic, and specifically in the search team, we’ve had a long history of working to extract and retrieve textual data from binary data formats. So much enterprise data lives in PDFs, Microsoft Word documents, Powerpoint presentations, etc. If you’ve never tried to open one of these files with vim, nano, or cat, you might be surprised to know that these files are NOT stored as human-readable text on your hard drive.

The image above is what you get if you save the word “test” as a Microsoft Word 2007 (.docx) Document, on a Mac, from the TextEdit app, and then attempt to open it in nano.
Rather than delving into the minutia of different formats and their structures, the point here is just to establish that when we talk about “binary” content, this is what is being referred to. Something where the bytes are not actually human-readable strings - unlike in cases of .txt, .rtf, .md, .html, .csv, etc.
Why does this matter?

Relevance
Search relevance is at the core of just about everything we do at Elastic. For text search to be relevant, Elasticsearch really needs textual data. While I could absolutely base64 encode the above .docx contents and send them to Elasticsearch, they wouldn’t be very valuable in an index, and any query for the string “test” would not match such a document.

So if we want to enable good search experiences over enterprise data, we need to be able to get the plain-text contents out of these binary formats.
Enter Apache Tika. This open-source library has been the gold-standard of text extraction for my entire career (~2014), though it’s been around since at least 2007. Built on the JVM, Tika makes it relatively easy to:
- Determine if a given sequence of bytes is garbage or matches a known format specification
- If it matches any known format, identify which format it matches
- If it matches a known format, parse the data according to that format, and extract text and metadata properties
So there’s a stable, industry standard tool that works for a wide variety of formats. What’s the problem? Why is this topic worthy of a blog post?
Architecture, and performance.
At Elastic, we value Speed, SCALE, Relevance. We’ve already addressed relevance, somewhat, in noting that textual content is preferred over binary content when it comes to search. Next, let’s talk about scale.
Scale
In my above example of “test” in a .docx file, the file contents are 3.4KB. That same “test” string in a .txt file is only 4B. That’s a storage size increase of x850! Beyond that, when read into a Java object memory model (which Tika leverages for parsing), that’s likely to expand significantly. This means that memory concerns become very real at representative scales of data. It’s not uncommon to see PDFs that are MB large, and it’s not even unheard of to see PDFs that are GB large. Is all that data text data? Almost certainly not. One of my favorite factoids is that the entire novel, War and Peace by Tolstoy is only about 3MB of plain text. Hopefully there aren’t too many office documents out there that exceed 600k words. But even if the output plain text is practically guaranteed to be in the mere MB scale, that does NOT guarantee that your RAM requirement to parse the original file will be so low. Depending on the parser and how smart your code is at reading it, you may need to hold the entire file in-memory, in a Java object model. You may also need multiple copies of it. With the above in mind, this means that, in practice, you often need GB of RAM (“heap”, for Java/Tika specifically) to be able to ensure that a rogue large file does not crash your whole process.
Speed
Now, let’s talk about speed. If I have N documents to process, the fastest way to process them is to “parallelize” - processing multiple (or all) documents at once. This is influenced heavily by scale. If N=10, and a given document takes about 1 second to process, 10 seconds might not be that long to wait. But if N=1,000,000,000, 31 years is likely far too slow. So at large scales, larger parallelization is required.
However, when considered alongside the memory cost for scale we discussed above, this compounds your memory requirement. A single document at a time might only require a few GB for worst-case scenarios, but if I’m trying to parallel-process 1000 documents at a time, I’m suddenly looking at potentially needing TB worth of RAM for a worst-case scenario.
With this context in mind, it’s not hard to understand why Workplace Search, a product that has been part of Elastic’s offering since 7.6.0, has always had pretty strict limits around parallelization and document size when it comes to extracting text from binary documents. Each Content Source can only process a single binary document at a time, caps the input size of binary documents at 20 MB, and even limits the output length to 100KB (by default - this is configurable). These limits are pretty conservative, but they make sense when you consider that the JVM processing any binary files in Enterprise Search is the same JVM that runs the Enterprise Search server and all its other background work. Workplace Search therefore has to be very careful to not consume more than its share of resources, or risk impacting other Enterprise Search functionality.
These conservative limits, along with others, are part of why we're working to shift customers away from Workplace Search. (To read more about that shift, check out the Evolution of Workplace Search blog post.) In the last few years, we’ve seen an uptick in the number of customers who have a larger volume of documents to process, and limiting them to one at a time (like Workplace Search does) hasn’t been sufficient.
Enter the Attachment Processor. Originally an installed-separately Elasticsearch Plugin, the Attachment Processor also utilizes Apache Tika to extract plain text from binary documents. Unlike the text extraction in Workplace Search, however, this tool runs inside Elasticsearch, and can be leveraged inside of Elastic Ingest Pipelines. The search team began to lean heavily into using Ingest Pipelines around 8.3.0, first in our App Search Crawler, and then with our Connector Packages, and most recently with our Native and Client Connectors. Utilizing it in our architecture came with a few bonuses:
- Elasticsearch did not need to limit the input size of the documents to a mere 20MB.
- Elasticsearch was already built to do distributed processing at ingest time with its Ingest Nodes (meaning we could easily horizontally scale, and process more than 1 document at a time)
- By utilizing a feature in Elasticsearch, we could ensure our text extraction behavior was aligned with that of other Elastic use cases.
- This was particularly important for our newer connectors, which are intended to run outside the Enterprise Search server, and should not be constrained to a single ecosystem. By using Elasticsearch for text extraction, we removed the requirement that our connectors be capable of running Tika (JVM, remember?) internal to themselves, but still kept a consistent text extraction behavior by not switching tools.
This certainly helped us improve our ingestion speeds, and became a major part of our strategy for a number of releases. After looking at some telemetry for the Attachment Processor, it became pretty clear that Enterprise Search’s usage of it is the largest stakeholder. This isn’t surprising, given how all our connectors and crawlers use the Attachment Processor by default. It’s the first processor in our ent-search-generic-ingestion pipeline - the default pipeline for all new connectors and crawlers.
\

In fact, the Attachment Processor had become so important to our use case that we were the driving motivation behind converting the Attachment Plugin to an out-of-the-box module (automatically available with Elasticsearch).

However, it came with some tradeoffs.
First, while Elasticsearch did not present the same 20MB limit we’d had in Enterprise Search, it does have a hard limit of 100MB for a maximum payload size (defined by http.max_content_length). You can get around this with multipart form data, but the Elasticsearch core devs have strongly advised that we not pursue this train of thought, because the 100MB limit exists for a reason. In fact, while this limit is technically configurable, we strongly advise not increasing it, because we’ve historically observed that doing so can dramatically reduce the stability of your Elasticsearch cluster.
Second, while Workplace Search being overzealous in binary processing could lead to Enterprise Search server failures, if the Attachment Processor is provided with too large of a workload, it can threaten the health of your Elasticsearch cluster. Typically, that’s worse. While Elasticsearch is capable of doing distributed processing (CPU) workloads at ingest time, that’s not its primary concern. Elasticsearch is primarily designed for search, and its capability to do distributed processing is not a main focus. It shouldn’t be (and will not be) optimized for heavy workloads of processing multiple large PDF files.
Instead, our team moved to a new approach - building a dedicated service for binary content extraction which operates outside the current set of processes.
Introducing the Data Extraction Service
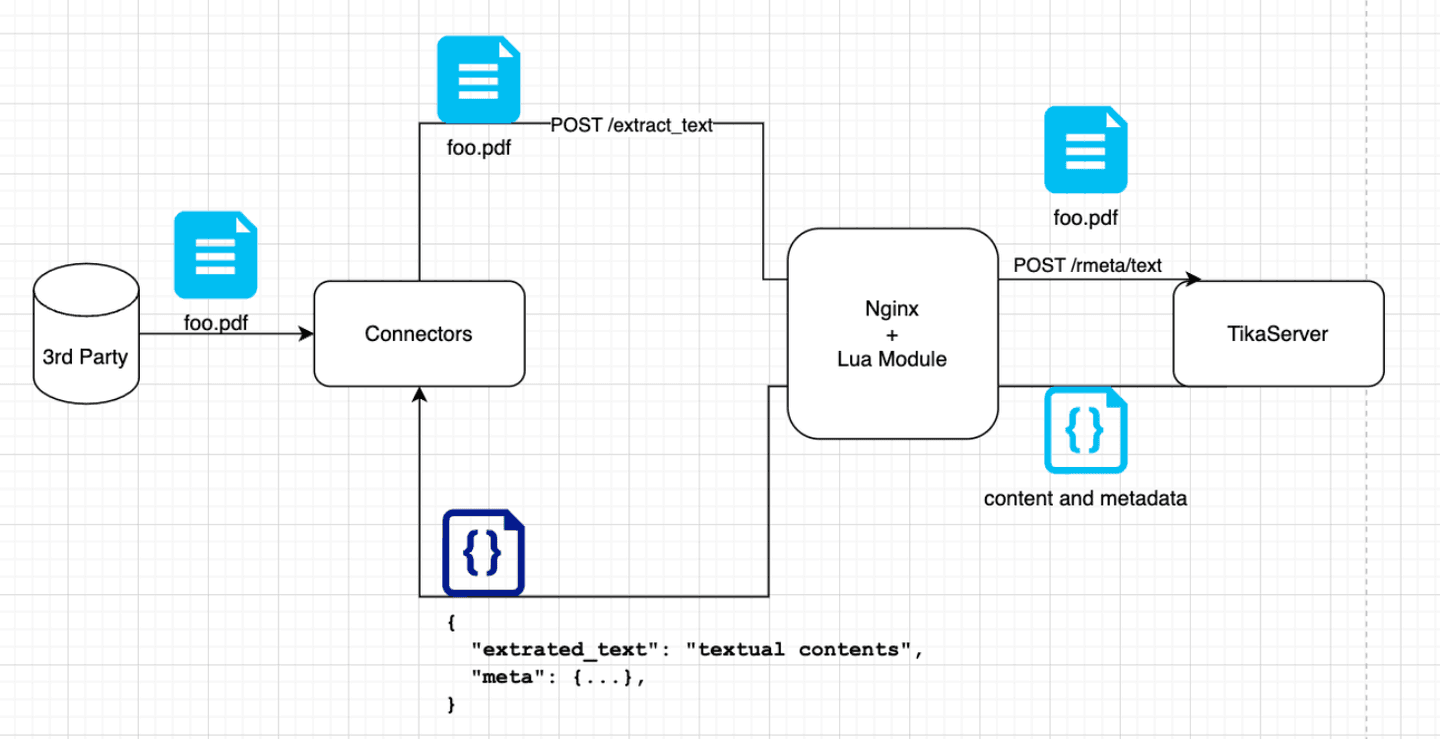
This service came out (in Beta) with the Elastic 8.9.0 release. It is a dedicated, standalone server that is capable of taking your binary documents as input (via a REST API) and responding with their plain-text contents, as well as some minimal metadata.
By separating the process from both our connectors and from Elasticsearch, we’ve created a service that is easily horizontally scalable. This way, the tradeoff between cost and speed can be easily controlled, and you’re not locked in to optimizing for one over the other.
In addition, the service being separated allows you to deploy it on the edge near your connectors, to avoid extra network hops with large file payloads. By leveraging file pointers when connectors and the Data Extraction Service are co-located on the same filesystem, we can eliminate the need to send the file over the network at all once it’s fetched from the source system.
For the time being the service is mostly just a wrapper around Tika Server. However, we hope to (one day) exercise fine-grained control over how we parse/handle each type of file type. Perhaps there are tools that are more performant than Tika for some file type X. For example, some anecdotal evidence suggests that the tool pdf2txt may be more efficient than Tika at parsing PDF files. If further experimentation confirms this, it would benefit our product to use the best tool for the job.
We’ve architected for this by making the Data Extraction Service out of an Nginx reverse-proxy that can define its own REST API, and then dynamically route incoming requests to various backends. This is done with some custom Lua scripts (an Nginx feature).

Initial reception of this tool has been overwhelmingly positive. The only “bugs” we’ve had reported against it (so far!) have been:
- It was too hard to find the docker images for it.
- The code was not open.
We’ve received far more enhancement requests, which we’re excited to be prioritizing, and we feel this just goes to show how much enthusiasm there’s been for this project.
Regarding the bugs though, we’ve fixed the docker image ambiguity, and you can now easily browse all our artifacts here: https://www.docker.elastic.co/r/enterprise-search/data-extraction-service. Regarding the source code, I’m absolutely thrilled to announce that the GitHub repository is now public - making the Data Extraction Service code free and open!
What’s next?
First, we hope that by opening the repository, we can further engage our community of enthusiastic users. We want to centralize the enhancement requests, and start soliciting more public feedback. We’d also absolutely welcome community contributions! We believe that this is the best way to make sure this continues to evolve organically to the benefit of all.
What’s the long-term dream?
Caveat, Elastic isn’t committing to this. The whole team might not even agree. But for the sake of enthusiasm, I want to share with you my personal vision.
I hope to grow this service beyond merely extracting plain text from office documents. Searchable data is present in images (scanned/photocopied documents, graphical banners/slides), audio files (music, podcasts, audiobooks, phone recordings, zoom audio), and video files (movies, tv shows, zoom video). And even plain text has subtext data embedded in it, which can be accessed with modern machine learning techniques (sentiment, entity recognition, semantic text, GenAI). All of these share the common problems of requiring large files and document processing in order to facilitate a first-rate search experience. They’d all benefit from the relevant search that Elasticsearch provides, but might not all be great fits for the CPU-intensive ingest workloads they require upfront. All of these might benefit from having a dedicated, horizontally scalable, extraction service that can live “on the edge” to improve ingestion speeds at scale.

This isn’t a reality yet. It’s a goal. A North star. The vision may shift as we get closer to it, but that’s not going to stop us from taking small, strategic, steps towards the goal.
If you want to help us get there, head on over to https://github.com/elastic/data-extraction-service, and join the project. New contributors welcome.
Frequently Asked Questions
What is the Data Extraction Service at Elastic?
It is a dedicated, standalone server that is capable of taking your binary documents as input (via a REST API) and responding with their plain-text contents, as well as some minimal metadata.
Related Content
June 19, 2026
Why your Elasticsearch cluster is hitting disk watermarks: 14 real-world causes explained
Learn how Elasticsearch disk watermarks work, why they trigger, and how to diagnose 14 of the most common scenarios Support encounters, from index bloat to ILM stalls.
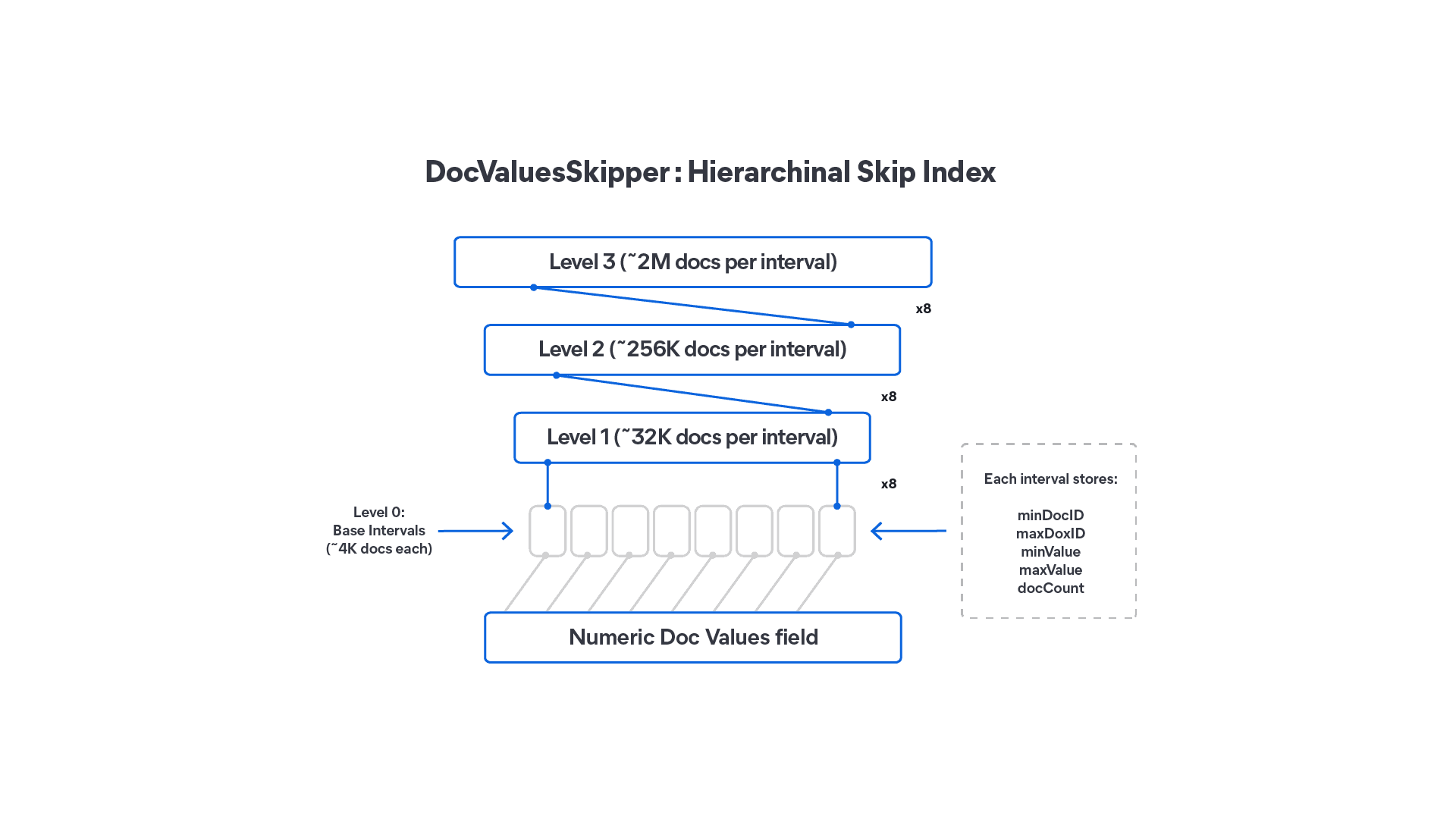
June 12, 2026
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.

June 2, 2026
Elasticsearch reindex now relocates across nodes automatically: zero user intervention, no lost progress
Elasticsearch reindex now survives node shutdowns, uses Point in Time for more efficient source iteration, and ships with dedicated management APIs. Reindex-from-remote is GA in Serverless.

May 20, 2026
Elasticsearch downsampling methods: last-value vs. aggregate sampling
Elasticsearch downsampling now gives you a choice: last-value sampling for maximum storage savings or aggregate sampling for precise rate calculations and counter resets, both fully queryable in ES|QL.

April 2, 2026
When TSDS meets ILM: Designing time series data streams that don't reject late data
How TSDS time bounds interact with ILM phases; and how to design policies that tolerate late-arriving metrics.