O que há de novo no Elastic Observability 7.11: página de visão geral do serviço do APM e mais a disponibilidade geral da biblioteca de logging do ECS
Temos o prazer de anunciar a versão 7.11 do Elastic Observability, introduzindo vários recursos que aceleram os fluxos de trabalho investigativos e reduzem o tempo médio para insight (MTTI) e o tempo médio de resolução (MTTR) em casos de uso de observabilidade. A nova página de visão geral do serviço no Elastic APM agrega os principais aspectos da integridade do serviço em uma única visualização, permitindo que os desenvolvedores e engenheiros de confiabilidade solucionem rapidamente problemas no serviço e identifiquem a causa raiz com um mínimo de troca de contexto. Da mesma forma, o app Metrics adiciona uma visualização aprimorada que apresenta a integridade do host em um único painel, simplificando o monitoramento da infraestrutura e os fluxos de trabalho de solução de problemas. Por fim, as bibliotecas de logging do Elastic Common Schema (ECS), que injetam automaticamente o contexto de traces nos logs das aplicações para permitir a correlação log ↔ trace, agora estão com disponibilidade geral.
Experimente a versão mais recente do Elastic Observability no nosso Elasticsearch Service on Elastic Cloud (uma avaliação gratuita de 14 dias está disponível) ou instale a versão mais recente do Elastic Stack para ter uma experiência autogerenciada.
E agora, sem mais delongas, aqui estão alguns dos destaques desta versão.
A nova visão geral da integridade do serviço no Elastic APM acelera a análise da causa raiz e a solução de problemas
As modernas aplicações nativas da nuvem costumam ser compostas por dezenas ou centenas de microsserviços. A capacidade de identificar rapidamente o estado de um serviço individual é fundamental para um fluxo de trabalho de investigação de incidentes e pode ajudar a baixar o MTTI/MTTR. Por exemplo, um mapa de serviços pode ajudar a relacionar um problema de uma aplicação a um serviço específico, mas então você precisa descobrir por que esse serviço está se comportando mal. Na versão 7.11, apresentamos uma nova página de visão geral do serviço que resume todas as informações sobre a integridade de um serviço em um só lugar, para que os desenvolvedores e SREs possam responder a esses “por ques” em uma única página:
- Como uma nova implantação afetou o desempenho?
- Quais são as transações mais afetadas?
- A regressão é introduzida por serviços downstream ou backends?
- Como o desempenho se correlaciona com a infraestrutura subjacente? Em quais instâncias (containers, VMs) estão ocorrendo os problemas de desempenho?
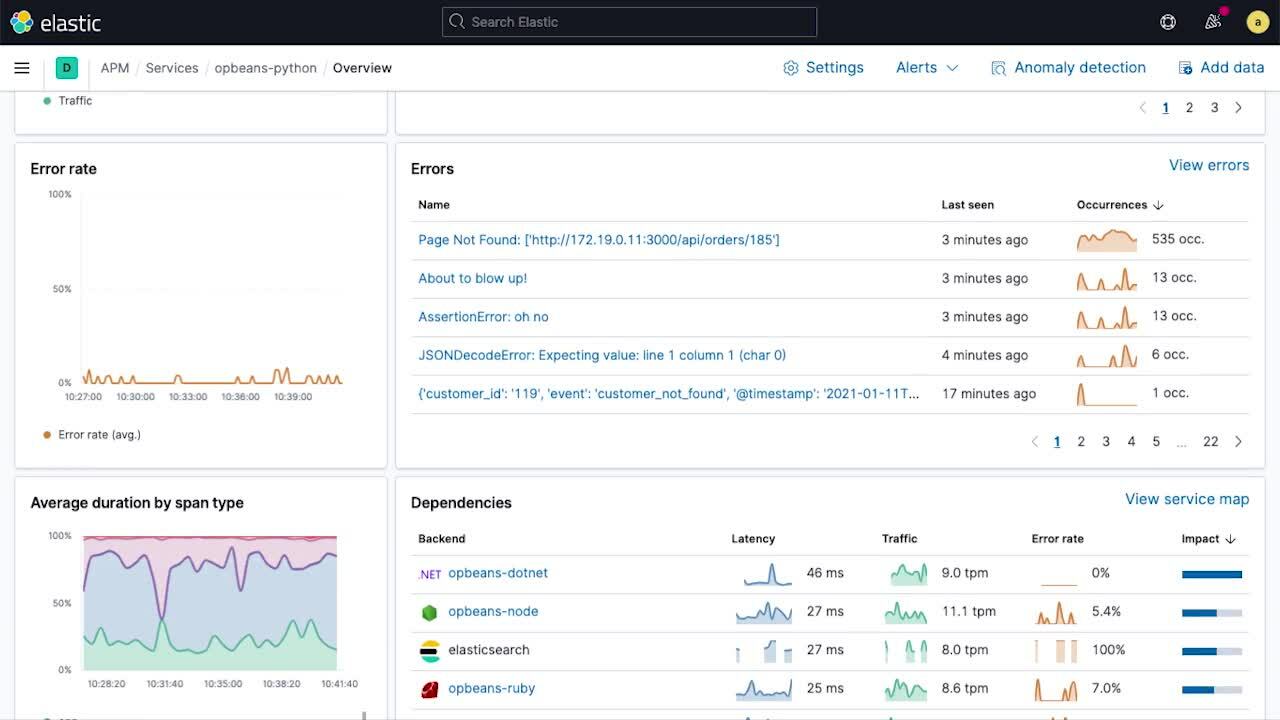
Os gráficos de série temporal que mostram a latência do serviço, o tráfego e a taxa de erros fornecem uma visão geral dos KPIs do serviço ao longo do tempo. Anotações sobrepostas — marcadores de implantação, alertas de anomalia etc. — nos gráficos de série temporal fornecem um rico contexto de eventos importantes que podem ter contribuído para mudanças no comportamento. Essas anotações ajudam imediatamente a estreitar o escopo das investigações que podem oferecer um caminho de remediação (por exemplo, rollback).
Os minigráficos na página de visão geral do serviço apresentam uma visualização compacta das tendências temporais dos subcomponentes, facilitando a detecção de mudanças incomuns no comportamento (por exemplo, quando a taxa de erro em uma determinada transação aumenta repentinamente) e revelando boas “próximas etapas” durante uma investigação. A página de visão geral também mostra a integridade do serviço dividida por instâncias de infraestrutura (por exemplo, containers) nas quais o serviço está implantado, facilitando o estabelecimento da relação entre questões e problemas na infraestrutura subjacente.
A versão 7.11 apresenta a primeira fase dessa nova visualização da integridade do serviço, e versões futuras contribuirão com mais contexto e visualizações ao mix a fim de otimizar e acelerar ainda mais os fluxos de trabalho de solução de problemas e análise de causa raiz.
Solucione problemas de infraestrutura mais rapidamente com a nova visualização aprimorada de detalhes do host
O heatmap de recursos no app Metrics oferece uma visão panorâmica do estado da sua infraestrutura, facilitando a rápida detecção dos recursos problemáticos (por exemplo, hosts com pico de uso de CPU) e afunilando as próximas etapas de uma investigação com a identificação dos hosts que precisam de uma inspeção mais minuciosa. Estamos introduzindo uma nova visualização no app Metrics que torna fácil partir dessa visão geral e ampliar para uma tendência histórica das principais métricas de hosts individuais.
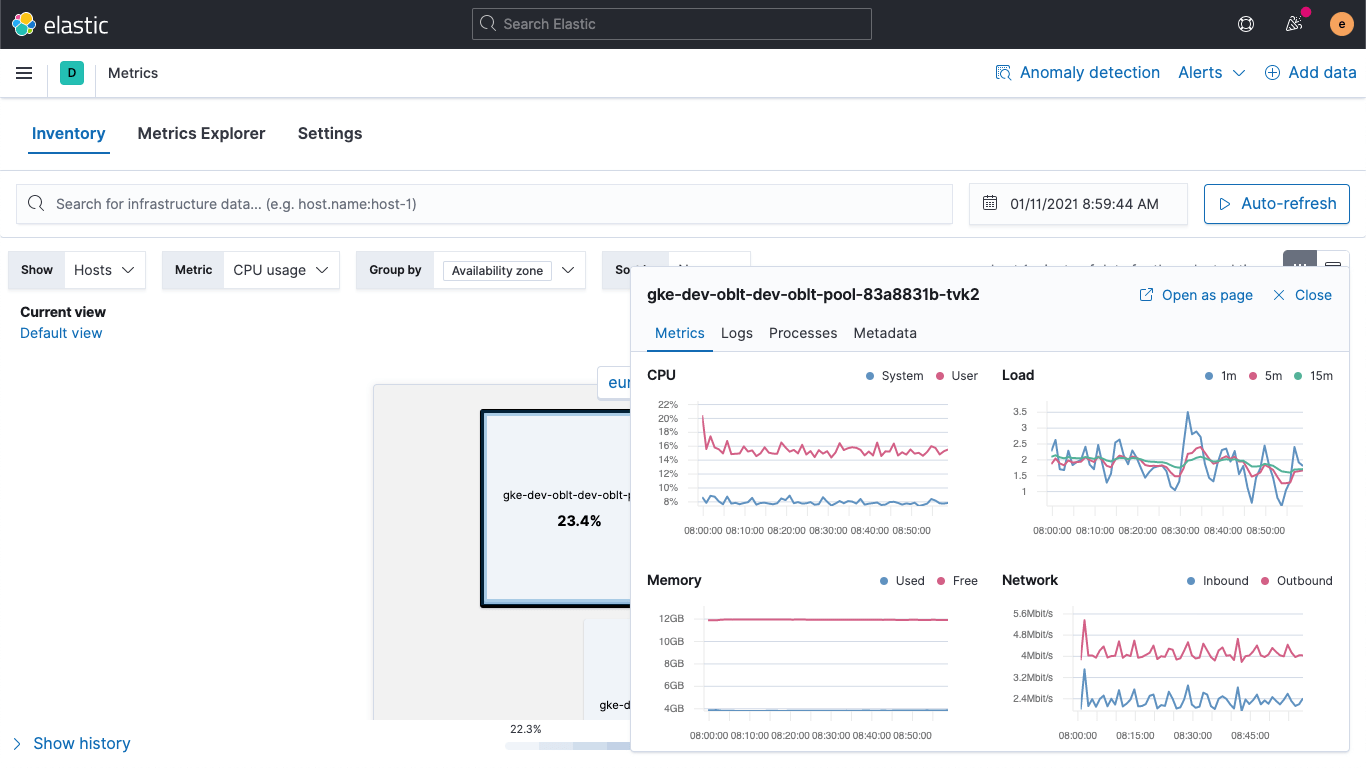
Semelhante ao modo como a nova página de destino do serviço no APM fornece tendências instantâneas, a visualização aprimorada de detalhes do host ajuda a acelerar a análise da causa raiz consolidando todas as informações (logs, métricas, processos etc.) necessárias sobre um host em uma única visualização, para que as equipes de operações de infraestrutura possam monitorar e solucionar problemas de infraestrutura com mais facilidade.
Ao clicar em um bloco no heatmap, você abre uma janela pop-up que exibe informações importantes sobre o host, incluindo:
- Gráficos de tempo das principais métricas do host (CPU, memória, rede etc.)
- Logs gerados pelo host ou serviços em execução nesse host
- Principais processos em execução no host (por CPU ou memória)
- Metadados do host (detalhes do sistema operacional, do provedor de serviços em nuvem)
- Links para obter informações ainda mais detalhadas de dados de trace ou tempo de funcionamento
A versão 7.11 estreia essa visualização aprimorada para hosts ou VMs, e versões futuras estenderão essa funcionalidade a outros tipos de recursos (pods, containers etc.) no app Metrics.
Saiba mais sobre a página de visão geral do serviço e outros novos recursos do APM nos documentos sobre o que há de novo na versão 7.11.
As bibliotecas de logging do ECS aprofundam a observabilidade das aplicações com vinculação automática entre logs e traces
Ser capaz de correlacionar logs e traces da aplicação e navegar entre eles sem perder o contexto são vitais para os fluxos de trabalho de solução de problemas da aplicação. Quais logs pertencem a um determinado trace ou qual trace os gerou? Qual solicitação da aplicação disparou esses logs? Com as bibliotecas de logging do Elastic Common Schema (ECS), agora com disponibilidade geral na versão 7.11, fica mais fácil para os desenvolvedores de aplicações injetarem automaticamente o contexto do trace capturado pelo agente de APM nos logs das aplicações, proporcionando a correlação entre logs e traces necessária para uma análise otimizada.
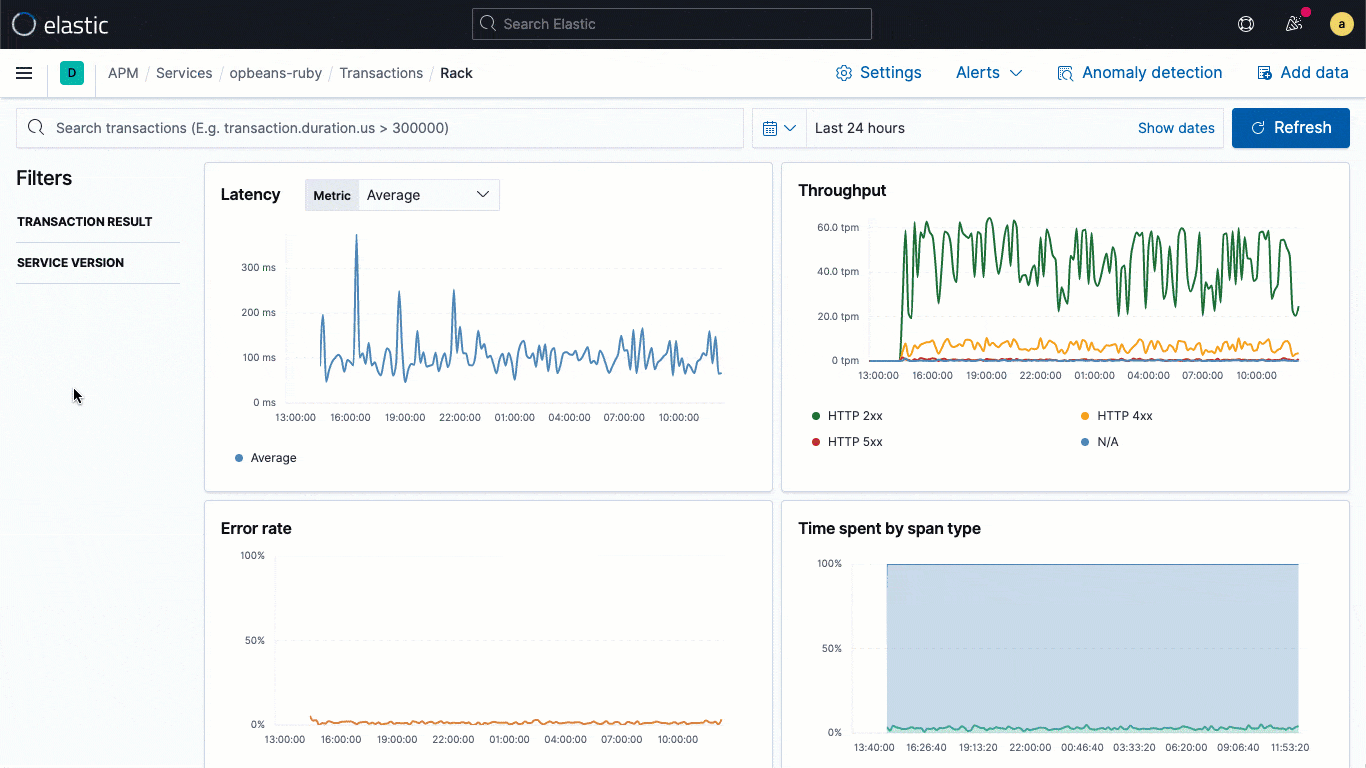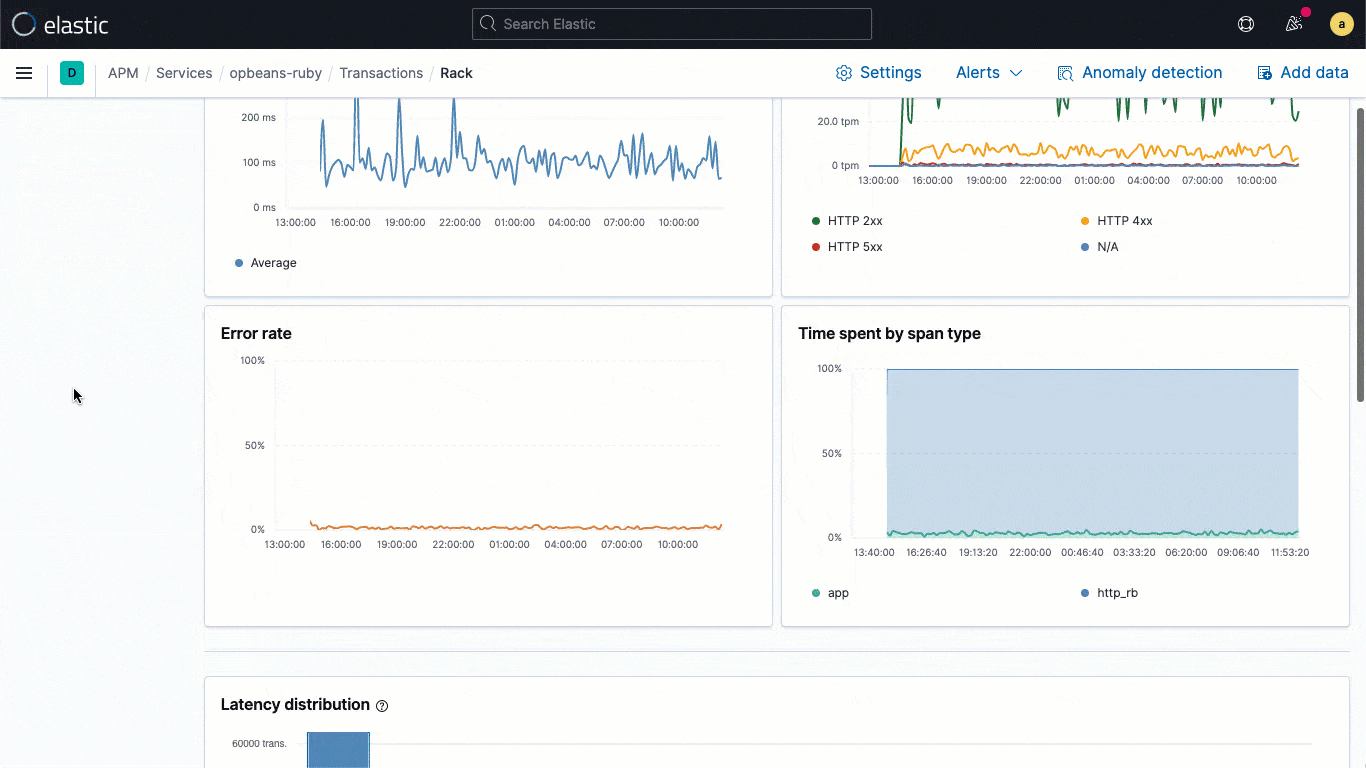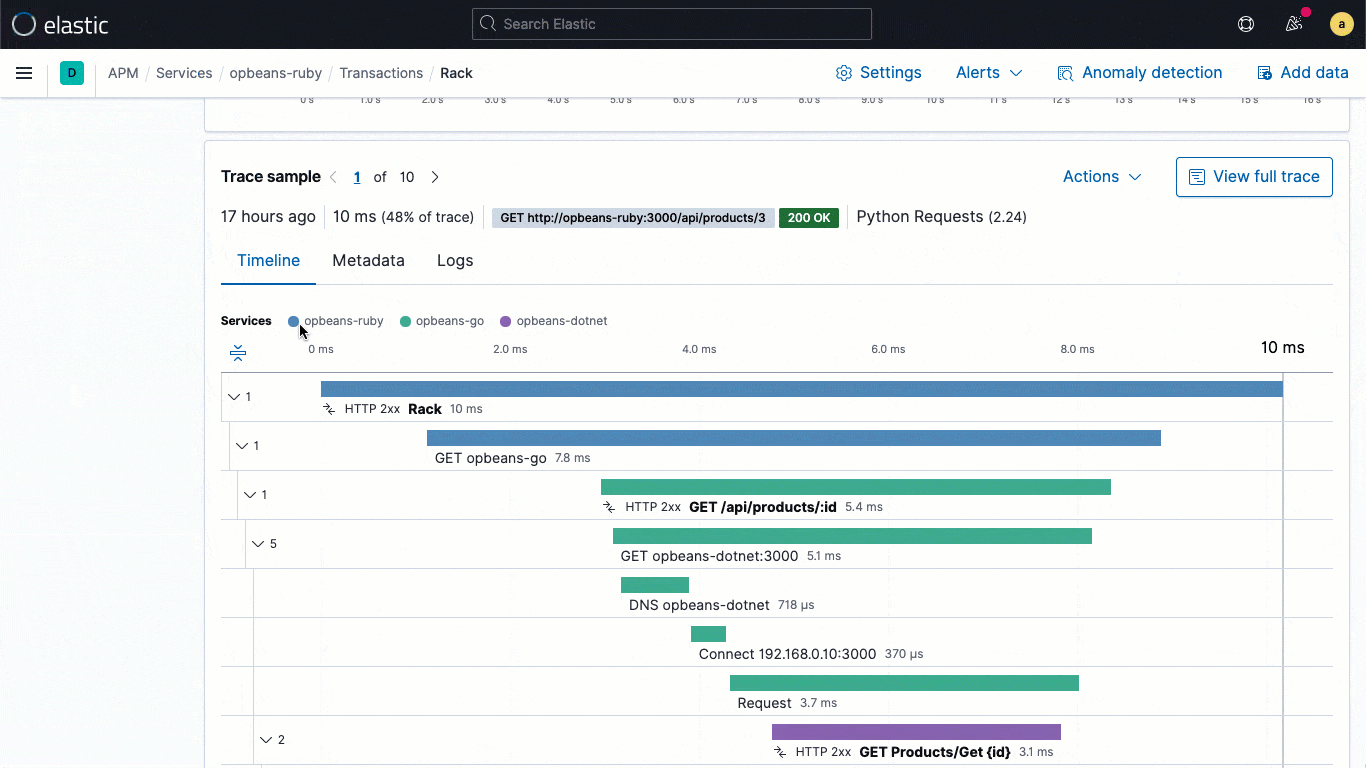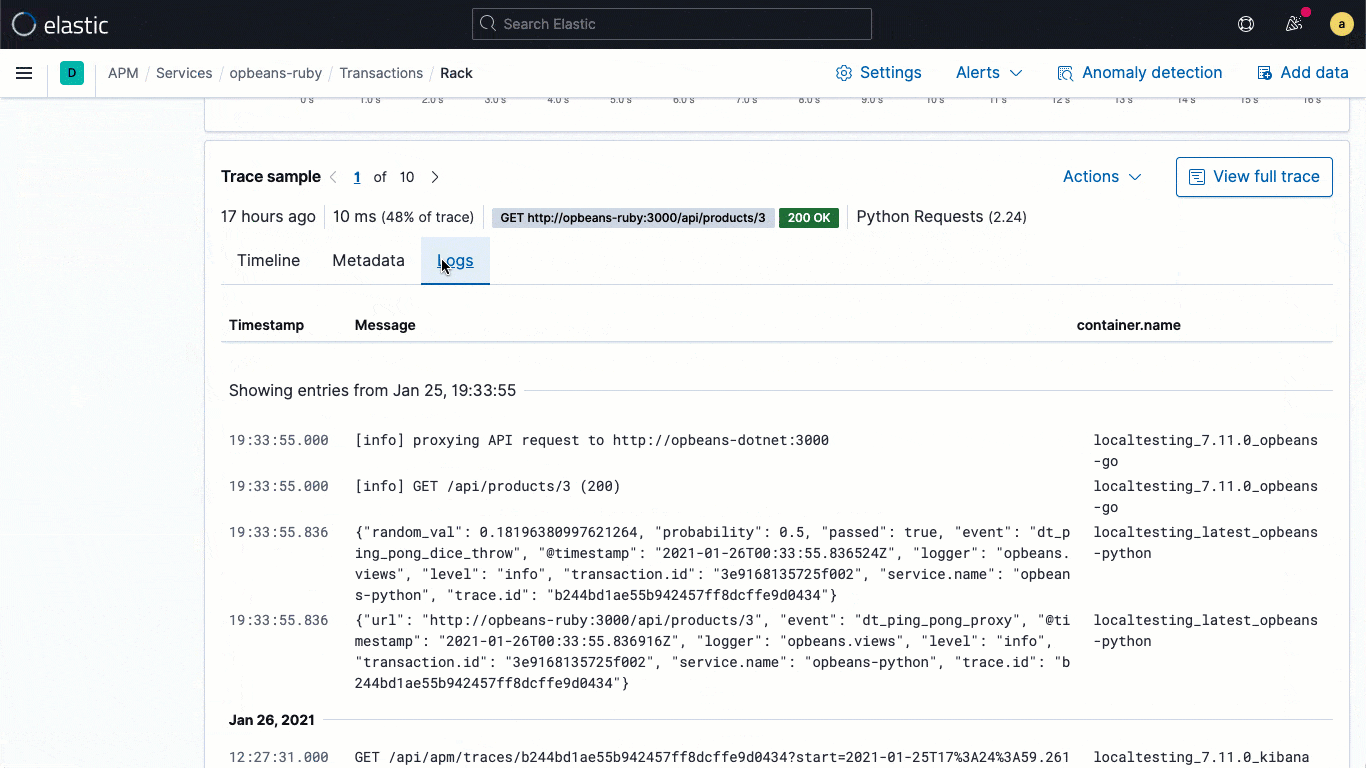
As bibliotecas de logging do ECS são plugins para os seus frameworks de logging favoritos (por exemplo, o log4j) e possibilitam que os desenvolvedores gravem facilmente logs de aplicações no formato JSON compatível com ECS, sem alterar seus fluxos de trabalho nativos. Os loggers do ECS incluem automaticamente o contexto de trace relevante capturado pelo agente de APM no log, ajudando os desenvolvedores a criar aplicações observáveis sem nenhum trabalho extra. O contexto de trace capturado normalmente inclui trace.id, transaction.id e span.id, conforme necessário.
Com base nessa vinculação fundamental no nível dos dados, o 7.11 traz um fluxo de logs incorporado diretamente à visualização do trace, o que significa que os usuários podem ver diretamente os logs associados a um trace específico sem mudar de contexto visual durante uma investigação.
Além dessa correlação log ↔ trace, a captura de logs no formato do ECS proporciona outros benefícios, incluindo análise automática, logs em formato legível por humanos e um modelo de dados normalizado em toda a sua stack de aplicações.
Saiba mais sobre esse e outros aprimoramentos para monitoramento de infraestrutura em o que há de novo na versão 7.11
Outros destaques notáveis
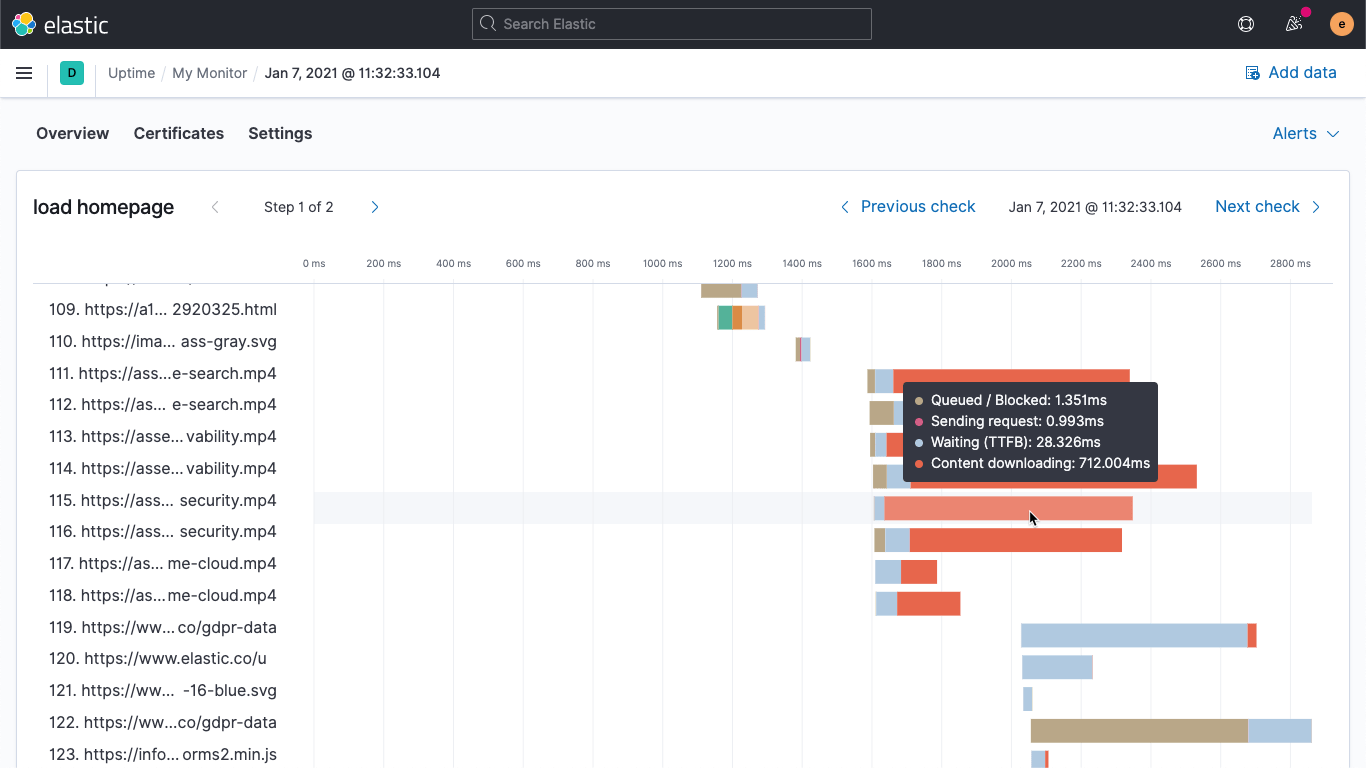
Gráfico em cascata de carregamento de página
Na versão 7.10, lançamos o monitoramento sintético para jornadas de usuários em várias etapas. Com a versão 7.11, estamos lançando a primeira iteração da nossa cascata de carregamento de página que exibe as estatísticas de conexão para cada objeto na página. A visualização em cascata do tempo de carregamento permite identificar rapidamente o gargalo de desempenho na experiência do usuário final durante os testes sintéticos.
Os campos em tempo de execução são a base para o esquema na leitura
Como o nome sugere, os campos em tempo de execução, um dos recursos mais solicitados pela comunidade do Elastic Observability, permitem criar novos campos em tempo real no momento da execução, transformando, enriquecendo ou extraindo campos de dados indexados. É um recurso fundamental que permite a criação de novos fluxos de trabalho de observabilidade, incluindo um dos recursos mais solicitados de todos os tempos: o esquema na leitura.
Com o lançamento desse recurso, os usuários agora têm o melhor dos dois mundos: use o esquema na gravação e aproveite a velocidade da busca e da analítica, analisando e estruturando dados no momento da indexação. Ou fique com o esquema na leitura, definindo campos em tempo real no momento da execução para ter mais flexibilidade nos fluxos de trabalho analíticos.
Os campos em tempo de execução têm suporte no Elasticsearch na versão 7.11, com suporte de UI limitado no Kibana. Leia tudo sobre a nossa visão no post dedicado ao tema.
Os snapshots buscáveis e a camada cold agora estão com disponibilidade geral
Os snapshots buscáveis, que foram introduzidos como um recurso beta na versão 7.10, agora estão com disponibilidade geral. Os snapshots buscáveis permitem que os usuários busquem e analisem dados diretamente em armazenamentos de objetos como o S3, facilitando a implementação de uma estratégia de hierarquização de dados para alcançar um equilíbrio entre desempenho e custo. A nova camada cold, baseada nos snapshots buscáveis, pode reduzir os custos de armazenamento em até 50% com mínimo impacto no desempenho.
Os snapshots buscáveis e as camadas de dados são recursos revolucionários para casos de uso de observabilidade, permitindo que os usuários façam mais com menos sem aumentar a complexidade operacional, alterar fluxos de trabalho investigativos ou dificultar o acesso aos dados.
Experimente a nova versão hoje mesmo!
Conheça mais detalhes sobre todos esses novos recursos e muito mais nos destaques da versão.
Melhor ainda: comece a usar esses incríveis recursos atualizando a sua implantação para a versão 7.11, obtendo uma avaliação gratuita de 14 dias do Elasticsearch Service ou instalando a versão mais recente do Elastic Stack.