Pontuação de anomalia no Machine Learning e o Elasticsearch - Como funciona
Nota do editor (3 de agosto de 2021): este post usa recursos obsoletos. Consulte a documentação de mapeamento de regiões customizadas com geocodificação reversa para obter as instruções atuais.
Nós recebemos muitas perguntas sobre a “pontuação de anomalia” do machine learning da Elastic e como as diferentes pontuações nos dashboards se relacionam com ocorrências incomuns no conjunto de dados. É muito útil entender como a pontuação de anomalia se manifesta, do que ela depende e como você pode usar a pontuação como um alerta proativo. Este blog, mesmo não sendo um guia definitivo, tem com objetivo explicar da forma mais prática possível como o machine learning faz a pontuação.
A primeira coisa importante é que são três formas distintas de se pensar (e principalmente pontuar) o que é incomum: a nota de uma anomalia individual (um registro), a nota de uma entidade como um usuário ou um endereço IP (um influenciador) e a nota de uma janela de tempo (um balde). Também veremos como essas notas se relacionam uma com a outra em uma espécie de hierarquia.
Pontuação de registro
O primeiro tipo de pontuação, no nível mais baixo da hierarquia, é o quanto uma instância específica de algo é incomum. Por exemplo:
- A taxa de logins falhos para user=admin observada foi de 300 no último minuto.
- O valor do tempo de resposta para um middleware específico pulou de repente para 300% do usual.
- O número de pedidos sendo processados nesta tarde é muito menor do que costuma ser num dia como hoje.
- A quantidade de dados sendo transferidos para um endereço IP remoto é muito maior do que a quantidade sendo transferida para outros IPs remotos.
Cada uma das ocorrências acima tem uma probabilidade calculada, um valor que é calculado de forma precisa (até valores baixos como 1e-308) com base em comportamento passado, o que cria um modelo de probabilidade para aquele item. No entanto, esse valor bruto de probabilidade, embora seja útil, não abarca algumas informações de contexto como:
- Como o comportamento anômalo atual se compara a anomalias passadas? É mais ou menos anômalo do que no passado?
- Como a anomalia desse item se compara a outras anomalias em potencial (outros usuários, outros endereços de IP, etc…)?
Para que seja mais fácil para o usuário entender e priorizar, o machine learning normaliza a probabilidade para que ela classifique o grau de anomalia de um item em uma escala de 0 a 100. Esse valor se chama “pontuação de anomalia” na interface do usuário.
Para oferecer mais contexto, a interface do usuário usa uma de quatro etiquetas de gravidade para as anomalias de acordo com sua pontuação: crítico (entre 75 e 100), grande (entre 50 e 75), pequena (entre 25 e 50) e alerta (entre 0 e 25), cada uma com uma cor diferente.
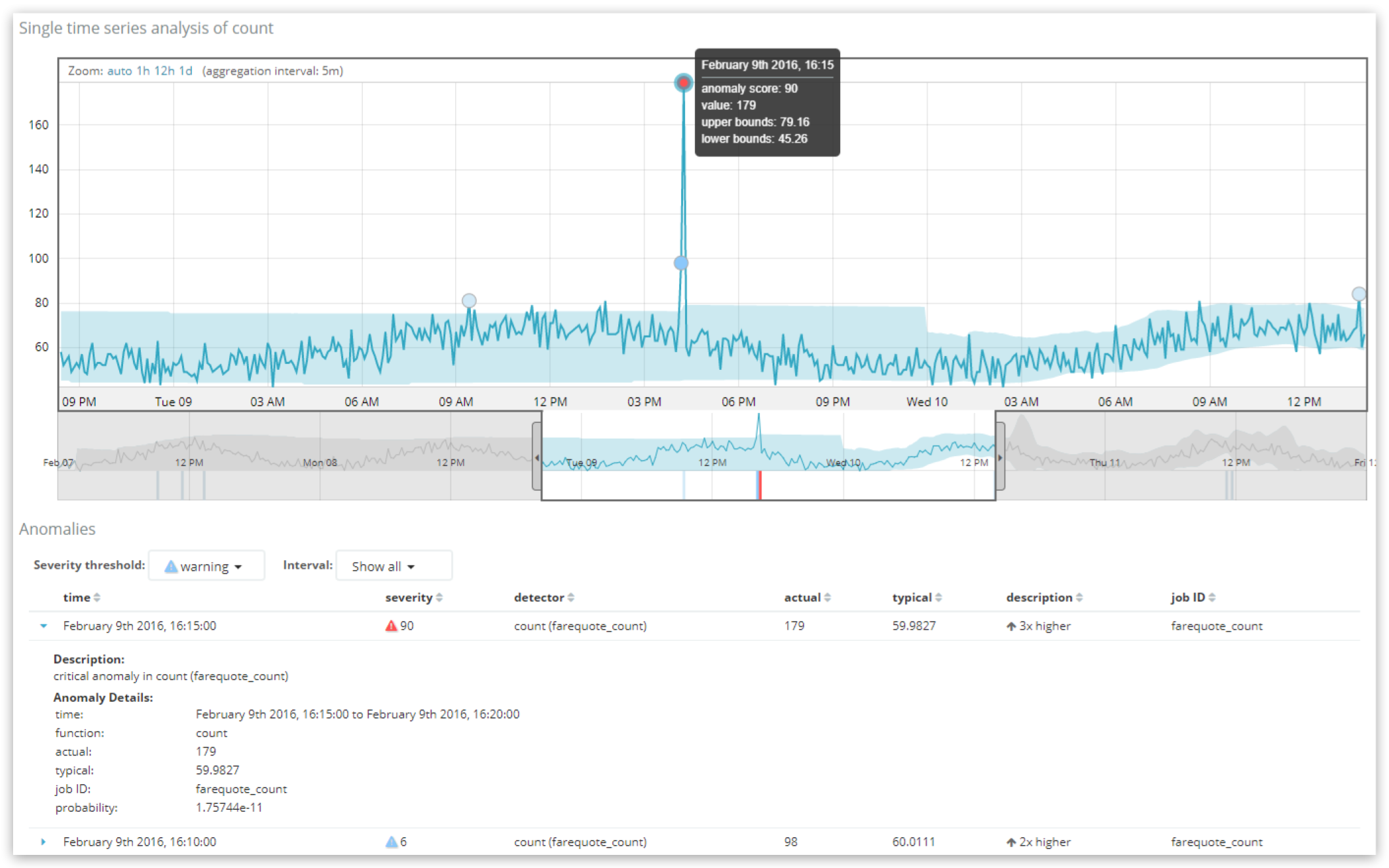
Aqui vemos dois registros de anomalias exibidos no Single Metric Viewer, com o registro mais anômalo sendo um “crítico” com nota 90. O controle de “limite de severidade” acima da tabela pode ser usado para filtrar a tabela pelas anomalias mais graves, enquanto o controle de “intervalo” permite agrupar registros para mostrar o mais grave por hora ou dia.
Se fôssemos criar uma query for record results na API do machine learning para pedir informações sobre anomalias em um intervalo específico de 5 minutos (em que farequote_count é o nome do job):
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
Veríamos o seguinte resultado:
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
Aqui, podemos ver que, durante esse intervalo de 5 minutos (o bucketspan do trabalho) o recordscore foi de 90.6954 (de 100) e a “probabilidade” bruta foi de 1.75744e-11. Isso quer dizer que é muito pouco provável que o volume de dados neste intervalo específico de 5 minutos tenha uma taxa de 179 documentos, pois ela costuma ser muito mais baixa, próxima de 60.
Observe como os valores aqui mapeiam o que é exibido para o usuário na interface. O valor ‘probability’ de 1.75744e-11 é muito pequeno, o que significa que algo provavelmente não aconteceu, mas a escala do número não é intuitiva. É por isso que é mais útil projetá-lo em uma escala de 0 a 100. O processo pelo qual essa normalização acontece é proprietário, mas é baseado em uma análise quantitativa na qual os valores de probabilidade historicamente vistos para anomalias neste job são classificados em comparação. Ou seja, as menores probabilidades daquele job, historicamente falando, recebem as pontuações de anomalias mais altas.
Uma confusão comum é que a pontuação da anomalia seja relacionada diretamente ao desvio articulado na coluna “description” da interface do usuário (aqui “3x mais alta”). A pontuação da anomalia é simplesmente conduzida pelo cálculo da probabilidade. A “descrição” e até mesmo o valor ‘typical’ são partes simplificadas das informações de contexto para facilitar o entendimento da anomalia.
Pontuação do influenciador
Agora que falamos do conceito de pontuação de um registro individual, a segunda forma de considerar uma anomalia é classificar ou pontuar entidades que possam ter contribuído para uma anomalia. Em machine learning, nos referimos a essas entidades como “influenciadores”. No exemplo acima, a análise foi muito simples para ter influenciadores, já que era só uma série única. Em análises mais complexas, existem campos auxiliares que influenciam a existência de uma anomalia.
Por exemplo, na análise de atividades de internet de uma população de usuários, na qual o job do machine learning veja bytes enviados incomuns e domínios acessados incomuns, você poderia especificar “usuário” como um possível influenciador, já que a entidade não está “causando” a anomalia (algo precisa estar enviando esses bytes para um domínio de destino). Uma pontuação de influenciador será dada para cada usuário dependendo do grau de anomalia que seja atribuído a ele em uma ou ambas essas áreas (bytes enviados e domínios acessados) durante cada intervalo de tempo.
Quanto maior a pontuação do influenciador, mais a entidade terá contribuído para as anomalias (ou será responsável por ela). Isso nos oferece uma visão poderosa dos resultados do machine learning, particularmente para aqueles jobs com mais de um detector.
Observe que para todos os jobs de machine learning, um influenciador chamado ‘bucket_time’ será sempre adicionado durante a criação do trabalho. Ele usa uma agregação de todos os registros no período.
Para demonstrar um exemplo de influenciadores, um job de machine learning é definido com dois detectores em um conjunto de dados de tempo de resposta de chamadas API para um motor de geração de tarifas de uma companhia aérea:
countde chamadas à API, divididas/particionadas emairlinemean(responsetime)das chamadas à API, divididas/particionadas emairline
com airline especificado como influenciador.
Ao observar os resultados no “Explorador de Anomalias”:
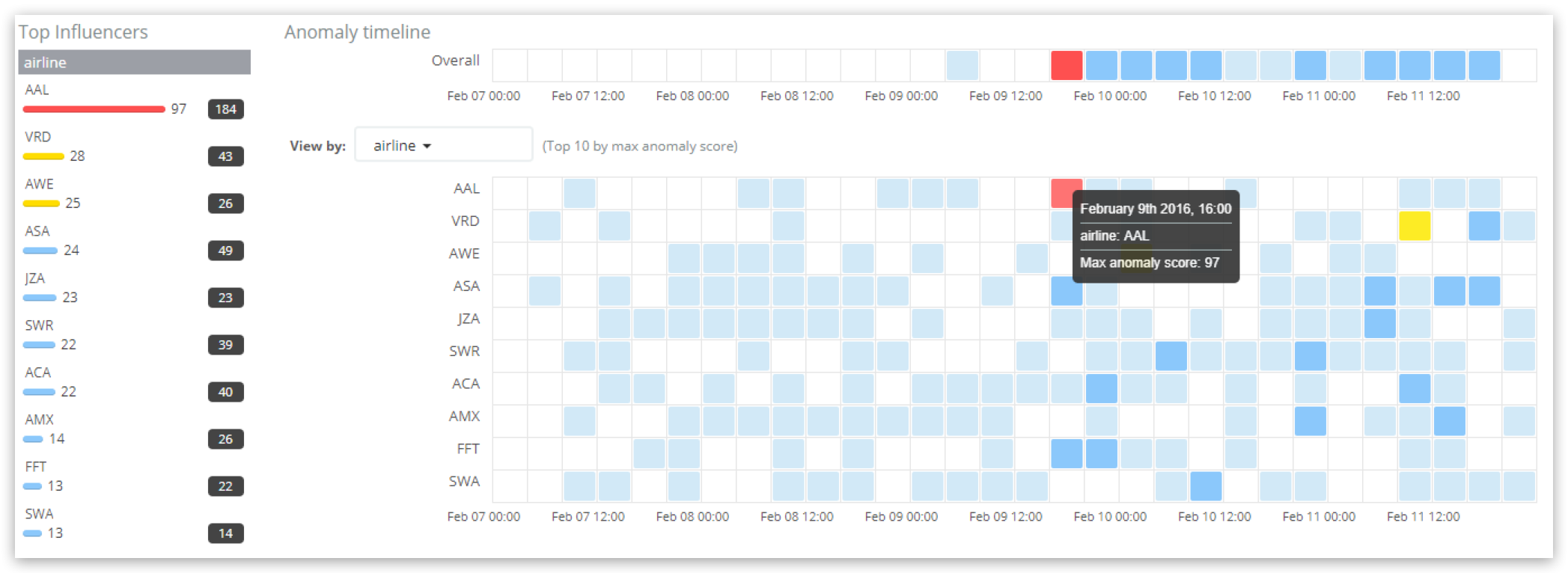
Os influenciadores com pontuação mais alta ao longo do tempo selecionados no painel estão listados na seção “Principais influenciadores” à esquerda. Para cada influenciador, a pontuação máxima de influenciadores (em qualquer período) é exibida junto com a pontuação total do influenciador na faixa de tempo do painel (some de todos os períodos). Aqui, a companhia aérea “AAL” tem a pontuação de influenciador mais alta de 97, com uma soma de pontuação de influenciador total de 184 ao longo de toda a faixa do tempo. A timeline principal mostra os resultados por influenciador e a companhia aérea com pontuação de influenciador mais alta está realçada, mostrando novamente a pontuação de 97. Observe que as pontuações mostradas nos gráficos e tabelas de “Anomalias” para a companhia aérea AAL serão diferentes da pontuação do influenciador, pois exibem as “pontuações do registro” das anomalias individuais.
Na hora de fazer queries na API no nível do influenciador:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
the following information is returned:
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
A saída contém um resultado para a companhia aérea AAL com o ‘influencerscore’ de 97.1547, espelhando o valor exibido na interface de usuário do Explorador de Anomalias (arredondado para 97). O valor ‘probability’ de 6.56622e-40 novamente é a base do ‘influencerscore’ (antes de ser normalizado) e leva em conta as probabilidades das anomalias individuais que aquela companhia aérea em particular influencia e o grau no qual ela é influenciada.
Observe que a saída também contém um ‘initialinfluencerscore’ de 98.5096, que era a pontuação quando o resultado foi processado, antes das normalizações subsequentes ajustarem para 97.1547. Isso ocorre porque o job de machine learning processa dados em ordem cronológica e nunca volta para reler dados brutos antigos para analisar novamente. Observe também que um segundo influenciador, a companhia aérea AWE, também foi identificado, mas sua pontuação de influenciador é tão baixa (arredondada para zero) que deve ser ignorada por razões práticas.
Como o ‘influencer_score’ é uma visão agregada por múltiplos detectores, você verá que a API não retorna os valores reais ou típicos para a contagem ou o meio de tempos de resposta. Se você precisar acessar essas informações detalhadas, elas ainda estarão disponíveis pelo mesmo período como um resultado de registro, conforme mostrado anteriormente.
Pontuação de período
A última forma de pontuar algo incomum (no topo da hierarquia) é focar no tempo, em particular, no bucket_span do job de machine learning. Coisas incomuns acontecem em horários específicos e é possível que um ou mais (ou diversos) itens possam ser incomuns se ao mesmo tempo (dentro do mesmo período).
Portanto, a anomalia de um período de tempo depende de diversas coisas:
- A magnitude das anomalias individuais (registros) que ocorrem dentro desse período.
- O número de anomalias individuais (registros) que ocorrem dentro desse período. Ele poderá ser grande se o trabalho tiver “divisões” com byfields e/ou partitionfields ou se existirem diversos detectores no trabalho.
Observe que o cálculo por trás da pontuação do período é mais complexo do que a média simples de todas as pontuações de registros de anomalias individuais, mas terão uma contribuição das pontuações do influenciador em cada período.
Voltando ao job de machine learning do exemplo anterior, com os dois detectores:
count, split/partitioned onairlinemean(responsetime), split/partitioned onairline
Ao olhar para o Explorador de Anomalia
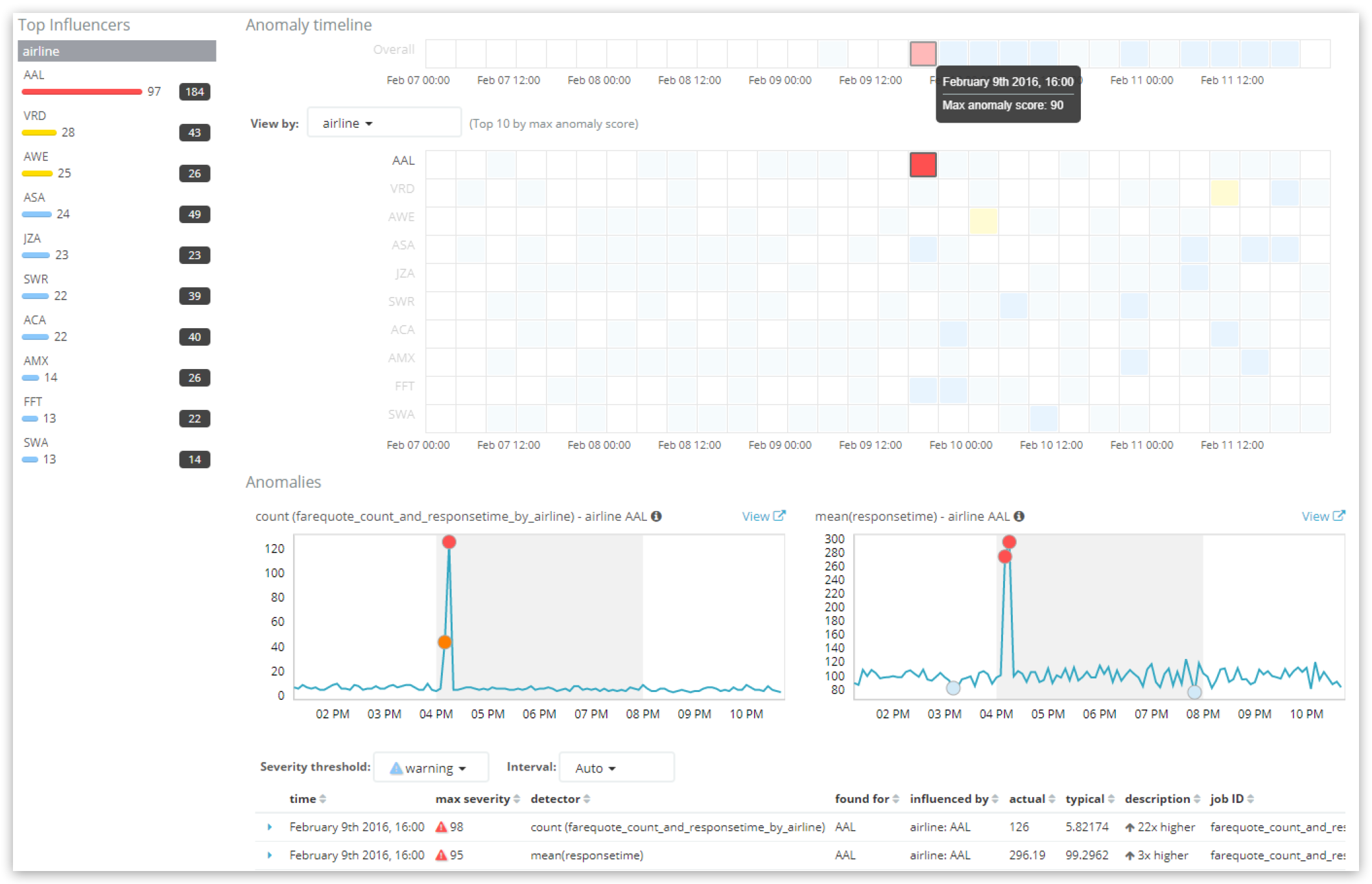
Observe que o campo “geral” da “Timeline da Anomalia” no topo da tela exibe a pontuação para aquele período. Mas cuidado. Se a faixa de tempo selecionada na interface do usuário for ampla, mas o ‘bucket_span’ do job de machine learning for relativamente pequeno, então um “pedaço” da interface do usuário pode ser uma série de períodos agregados.
O pedaço selecionado mostrado acima tem uma pontuação de 90 e existem duas anomalias de registro críticas neste período, uma para cada detector com pontuação de registro de 98 e 95.
Na hora de fazer queries na API no nível do período:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
a seguinte informação está presente:
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
Observe na saída especialmente o seguinte:
- ‘anomaly_score’ - a pontuação geral normalizada e agregada (aqui 90.7).
initial_anomaly_score- oanomaly_scoreno momento em que o período foi processado (novamente, nesse caso, normalizações posteriores alteraram o valor original doanomaly_score). Oinitial_anomaly_scorenão é mostrado em nenhum lugar da interface do usuário.bucket_influencers- uma faixa de tipos de influenciadores presentes neste período. Conforme se suspeitava, por causa da nossa discussão dos influenciadores acima, essa faixa contém entradas tanto parainfluencer_field_name:airlineeinfluencer_field_name:bucket_time(que é sempre adicionado com um influenciador incorporado). Os detalhes de quais valores de influenciadores específicos (por exemplo, qual companhia aérea) estão disponíveis quando alguém envia uma query para a API especificamente para os valores de influenciador ou registro, conforme mostrado anteriormente.
Como usar a pontuação de anomalia para alertas
Então, se houver três pontuações fundamentais (uma para registros individuais, outra para influenciadores e outra para o período de tempo), qual seria usado para alerta? A resposta é que depende do que você quer e da granularidade e, consequentemente, da taxa dos alertas que você deseja receber.
Se, por um lado, você está tentando detectar e alertar a respeito de desvios significativos no conjunto de dados geral como uma função do tempo, a pontuação de anomalia baseada no período acaba sendo mais útil. Se você quer receber um alerta das entidades mais incomuns ao longo do tempo, considere usar influencer_score. Ou, se estiver tentando detectar e alertar a respeito das anomalias mais incomuns dentro de uma janela de tempo, pode ser melhor usar o record_score como base para seus relatórios ou alertas.
Para evitar o excesso de alertas, recomendamos usar a pontuação de anomalia baseada em período porque ela tem limitação de taxa, ou seja, você nunca vai receber mais de 1 alerta por bucket_span. Por outro lado, se você se concentrar em criar alertas usando o record_score, o número de registros anômalos por unidade é arbitrário, com a possibilidade de ser muitos. Tenha isso em mente que, se você estiver usando a pontuação de registros individuais para alertas.
Leitura adicional: