Elasticsearch 클러스터 간 복제 기능을 사용한 데이터센터 간 복제
데이터센터 간 복제 기능은 한동안 Elasticsearch의 중요 업무용 애플리케이션의 필수 요건이었으며 이전에는 추가 기술을 활용하여 부분적으로 해결하였습니다. Elasticsearch 6.7에 클러스터 간 복제 기능이 도입됨에 따라 추가적인 기술이 필요 없이 데이터센터, 지역 또는 Elasticsearch 클러스터 전반에서 데이터를 복제할 수 있습니다.
CCR(클러스터 간 복제)을 사용하면 특정 인덱스를 하나의 Elasticsearch 클러스터에서 하나 이상의 Elasticsearch 클러스터로 복제할 수 있습니다. 데이터센터 간 복제 외에도, 데이터 지역성(제품 카탈로그를 전 세계 20개의 서로 다른 데이터센터에 복제하는 것과 같이 사용자/애플리케이션 서버에 더 가까이 두기 위한 데이터 복제) 또는 Elasticsearch 클러스터에서 중앙 보고 클러스터로 데이터 복제(예: 전 세계 1000개 은행 지점이 모두 로컬 Elasticsearch 클러스터에 쓰고, 보고 목적으로 HQ의 클러스터로 다시 복제) 등 CCR에 대한 다양한 추가 사용 사례가 있습니다.
CCR을 사용한 데이터센터 간 복제에 대한 이 튜토리얼에서는 CCR 기본 사항을 간략하게 살펴보고 아키텍처 옵션 및 절충을 강조하며 데이터 센터 간 샘플 배포를 구성하고 관리 명령을 강조합니다. CCR에 대한 기술 소개는 리더 팔로우: Elasticsearch에서 클러스터 간 복제 기능 소개를 참조하십시오.
CCR은 플래티넘 레벨 기능이고 30일 평가판 라이센스를 통해 사용할 수 있으며 시험판 시작 API를 통해 활성화하거나 Kibana에서 직접 활성화할 수 있습니다.
CCR(클러스터 간 복제) 기본 요소
인덱스 수준에서(또는 인덱스 패턴을 기반으로) 복제 구성
CCR은 Elasticsearch의 인덱스 수준에서 구성됩니다. 인덱스 수준에서 복제를 구성하면, 세분화된 데이터센터 간 아키텍처뿐만 아니라 수많은 복제 전략을 사용할 수 있어서 한 방향으로 일부 인덱스를 복제하고 다른 방향으로는 다른 인덱스를 복제하는 일도 가능합니다.
복제된 인덱스는 읽기 전용입니다
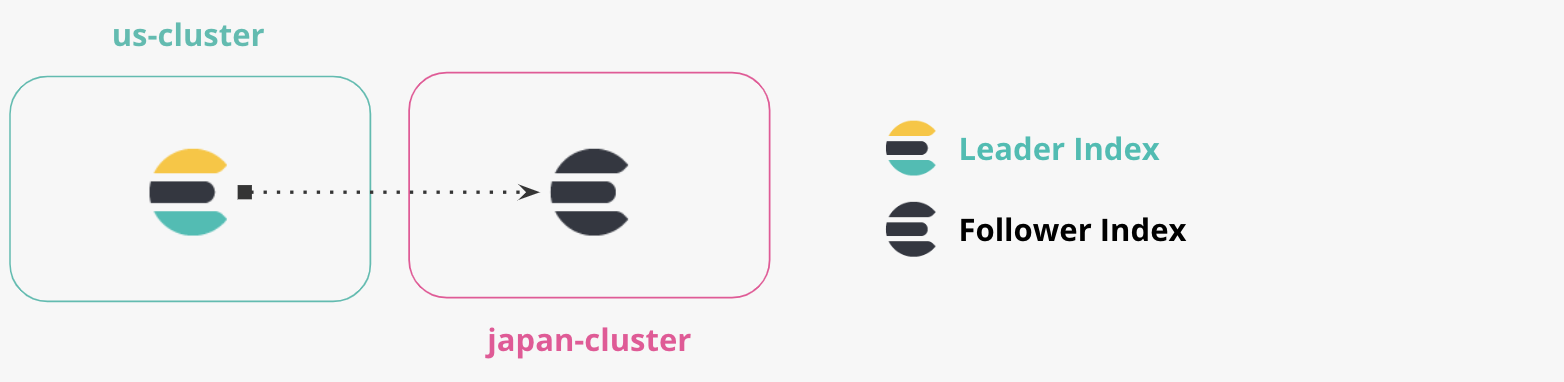
인덱스는 하나 이상의 Elasticsearch 클러스터로 복제할 수 있습니다. 인덱스를 복제하는 각 클러스터는 인덱스의 읽기 전용 복사본을 유지관리합니다. 쓰기를 승인할 수 있는 활성 인덱스를 리더라고 합니다. 해당 인덱스의 수동 읽기 전용 복사본을 팔로워라고 합니다. 클러스터/데이터 센터 중단과 같은 리더 인덱스를 사용할 수 없는 경우 새 리더에 대한 선택 개념이 없으며, 애플리케이션 또는 클러스터 관리자가 쓰기를 위해 대부분 다른 클러스터에서 다른 인덱스를 명시적으로 선택해야 합니다.
높은 처리량을 가진 다양한 사용 사례에 대해 CCR 기본값이 선택됨
값 조정이 시스템에 미치는 영향에 대하여 완전한 이해 없이 기본값을 변경하는 것은 좋지 않습니다. 대부분의 옵션은 "max_read_request_operation_count" 또는 "max_retry_delay"와 같은 팔로어 API 생성에서 찾을 수 있습니다. 고유한 워크로드에 맞게 이러한 매개 변수를 조정하는 방법에 대한 게시물을 곧 게시할 예정입니다.
보안 요건
CCR 시작 가이드에 요약된 것처럼 소스 클러스터의 사용자에게는 "read_ccr" 클러스터 권한, "monitor" 및 "read" 인덱스 권한이 있어야 합니다. 대상 클러스터 내에서 사용자에게는 “manage_ccr” 클러스터 권한과“monitor”, “read”, “write” 및 “manage_follow_index” 인덱스 권한이 있어야 합니다. LDAP와 같은 중앙 인증 시스템도 사용될 수 있습니다.
데이터센터 간 CCR 아키텍처 샘플
생산 및 DR 데이터센터
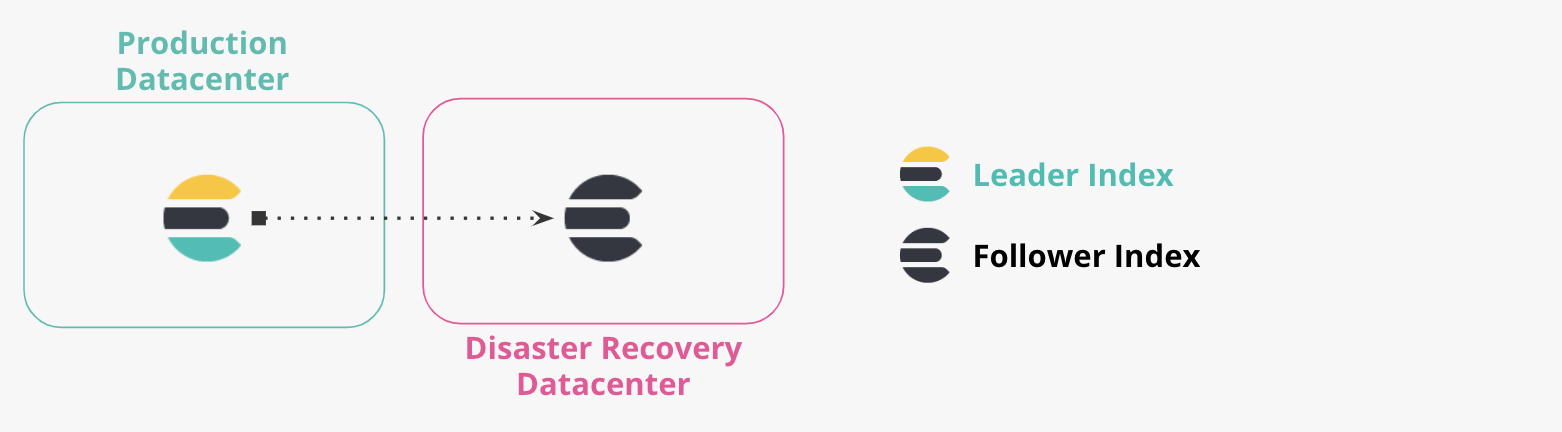
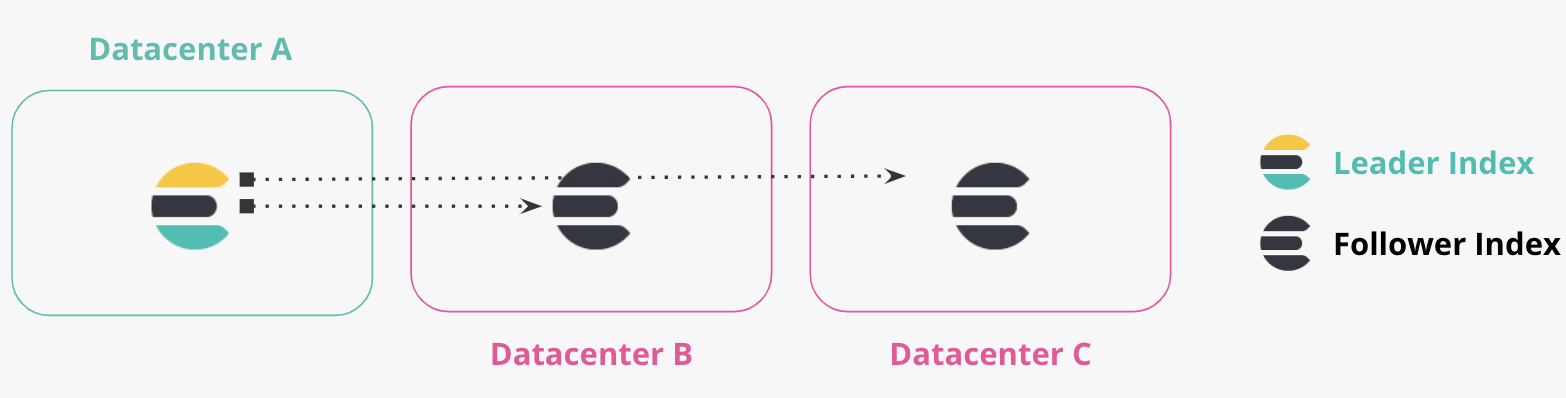
둘 이상의 데이터 센터
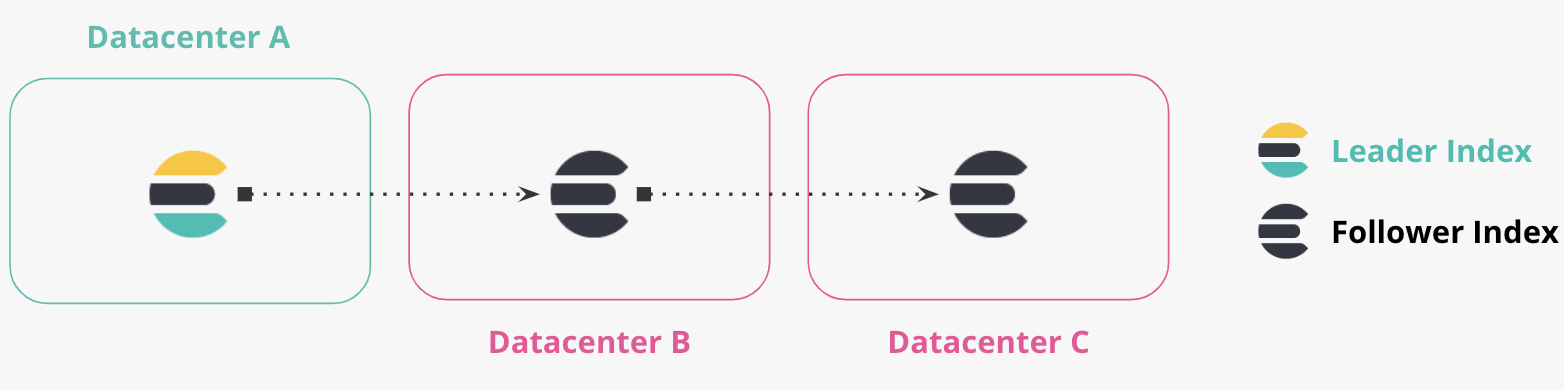
연결된 복제
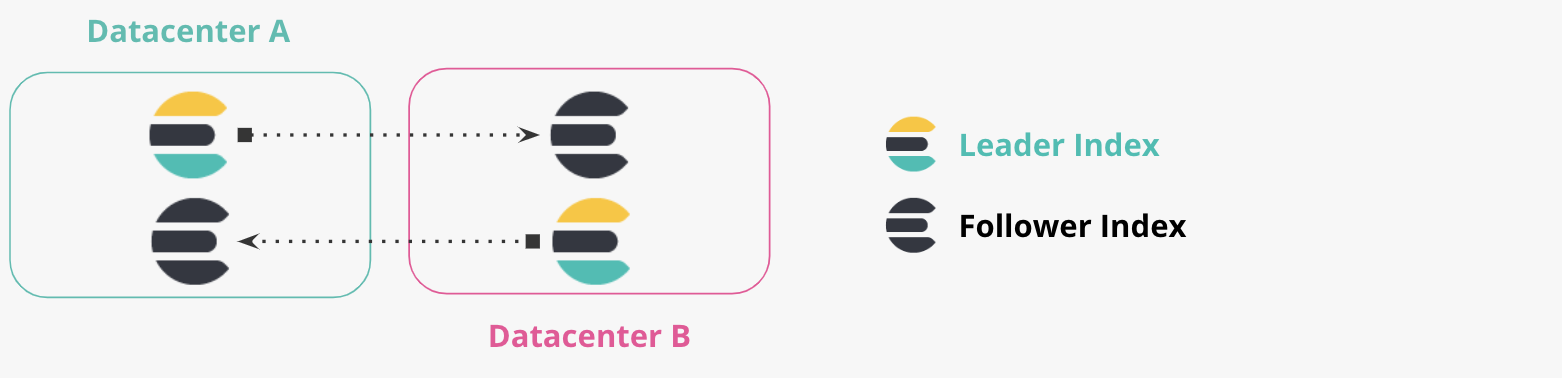
양방향 복제
데이터센터 간 배포 튜토리얼
1. 설정
이 튜토리얼에서는 두 개의 클러스터를 사용하며 두 클러스터는 모두 로컬 컴퓨터에 있습니다. 원하는 곳에서 클러스터를 둘 수 있습니다.
- ‘us-cluster’: 이것은 "미국 클러스터"이며 포트 9200에서 로컬로 실행됩니다. 미국 클러스터에서 일본 클러스터로 문서를 복제합니다.
- 'japan-cluster': 이것은 "일본 클러스터"이며 포트 8200에서 로컬로 실행됩니다. 일본 클러스터는 미국 클러스터에서 복제된 인덱스를 유지합니다.
2. 원격 클러스터 정의
CCR을 설정할 때 Elasticsearch 클러스터는 다른 Elasticsearch 클러스터에 대해 알아야 합니다. 이는 단방향 요구 사항이며, 대상 클러스터는 소스 클러스터에 대한 단방향 연결을 유지합니다. 다른 Elasticsearch 클러스터를 원격 클러스터로 정의하고 이를 설명하는 별칭을 지정합니다.
우리는 ‘japan-cluster’가 ‘us-cluster'에 대해 알고 있는지 확인하고 싶습니다. CCR에서의 복제는 끌어오기 기반이므로 'us-cluster'에서 'japan-cluster'와의 연결을 지정할 필요가 없습니다.
'japan-cluster'에서 API 호출을 통해 ‘us-cluster’를 정의해 보겠습니다.
# japan-cluster에서 us-cluster에 액세스하는 방법을 정의하겠습니다.
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(API 기반 명령의 경우 Kibana 내에서 개발자 도구 콘솔을 사용하는 것이 좋으며 콘솔은 Kibana -> 개발자 도구 -> 콘솔에서 찾을 수 있습니다)
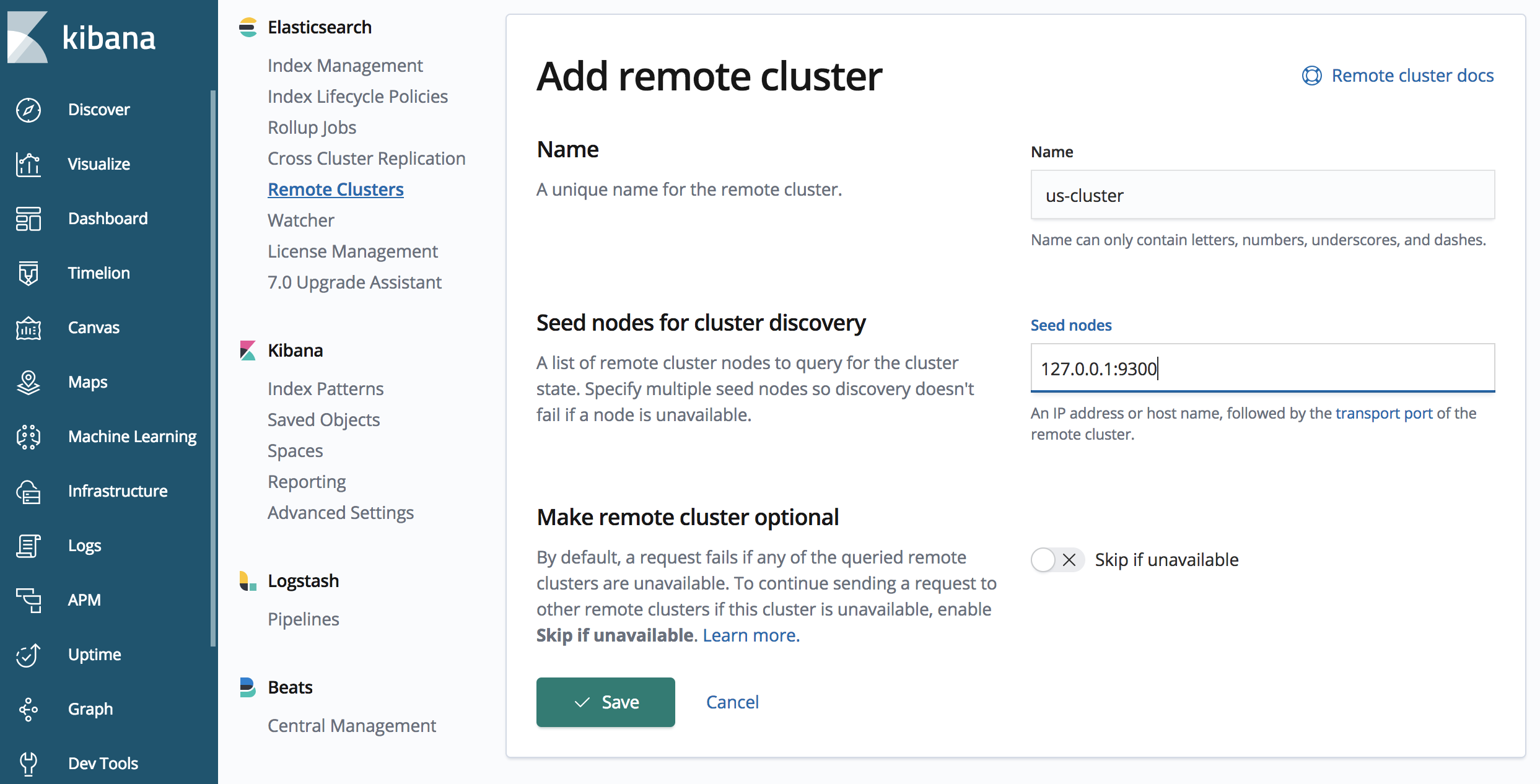
위의 API 호출은 "us-cluster"라는 별칭을 가진 원격 클러스터를 정의하며, "127.0.0.1:9300"에서 액세스할 수 있습니다. 하나 이상의 시드를 지정할 수 있으며 핸드쉐이크 단계에서 시드를 사용할 수 없는 경우에 대비하여 일반적으로 둘 이상의 시드를 지정하는 것이 좋습니다.
원격 클러스터 구성에 대한 자세한 내용은 원격 클러스터 정의에 대한 참조 설명서를 참조하십시오.
또한 'us-cluster'에 연결하기 위해 포트 9300을 유념해야 합니다. 'us-cluster'는 포트 9200에서 HTTP 프로토콜을 수신합니다(기본값이며, ‘us-cluster’의 경우 elasticsearch.yml 파일에 지정되어 있습니다). 그러나 복제는 노드와 노드 간 통신의 경우 Elasticsearch 전송 프로토콜을 사용하여 수행하며 기본값은 포트 9300입니다.
Kibana에는 원격 클러스터를 위한 관리 UI가 있습니다. 이 튜토리얼에서는 CCR 용 UI와 API를 모두 살펴보겠습니다. Kibana의 원격 클러스터 UI에 액세스하려면 왼쪽 탐색 패널에서 "Management(관리)"(기어 아이콘)를 클릭한 다음 Elasticsearch 섹션 내의 "Remote Clusters(원격 클러스터)"로 이동하십시오.
3. 복제할 인덱스 생성
'us-cluster'에서 'products'라는 인덱스를 생성해보겠습니다. 이 인덱스를 소스 'us-cluster'에서 대상 'japan-cluster'로 복제합니다.
‘us-cluster’에서:
# 제품 색인 생성
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
"soft_deletes" 설정을 보셨을 것입니다. 인덱스가 CCR의 리더 인덱스 역할을 하려면 소프트 삭제가 필요합니다(자세한 내용은 기록을 모르는 사용자 참조).
soft_deletes: 기존 문서를 삭제하거나 업데이트할 때마다 소프트 삭제가 발생합니다. 이러한 소프트 삭제를 구성 가능한 한계까지 유지하면 작업 기록을 리더 샤드에 보관하고 작업 기록을 재생할 때 팔로워 샤드 작업에 사용할 수 있습니다.
팔로워 샤드는 리더에서 작업을 복제할 때 리더 샤드에 마커를 남길 수 있어서 리더는 기록에서 팔로워가 어디에 있는지 알 수 있습니다. 이러한 마커 아래의 소프트 삭제 작업은 병합될 수 있습니다. 이러한 마커 위의 리더 샤드는 샤드 기록 유지 리스 기간까지 이러한 작업을 유지하며, 기본 시간은 12시간입니다. 이 기간은 팔로워가 훨씬 멀리 떨어져 있어서 리더에서 재부팅해야 할 위험에 처하기 전에 오프라인 상태가 될 수 있는 시간을 결정합니다.
4. 복제 시작
원격 클러스터에 대한 별칭을 만들고 복제할 인덱스를 만들었으므로 이제 복제를 시작하겠습니다.
‘japan-cluster’에서:
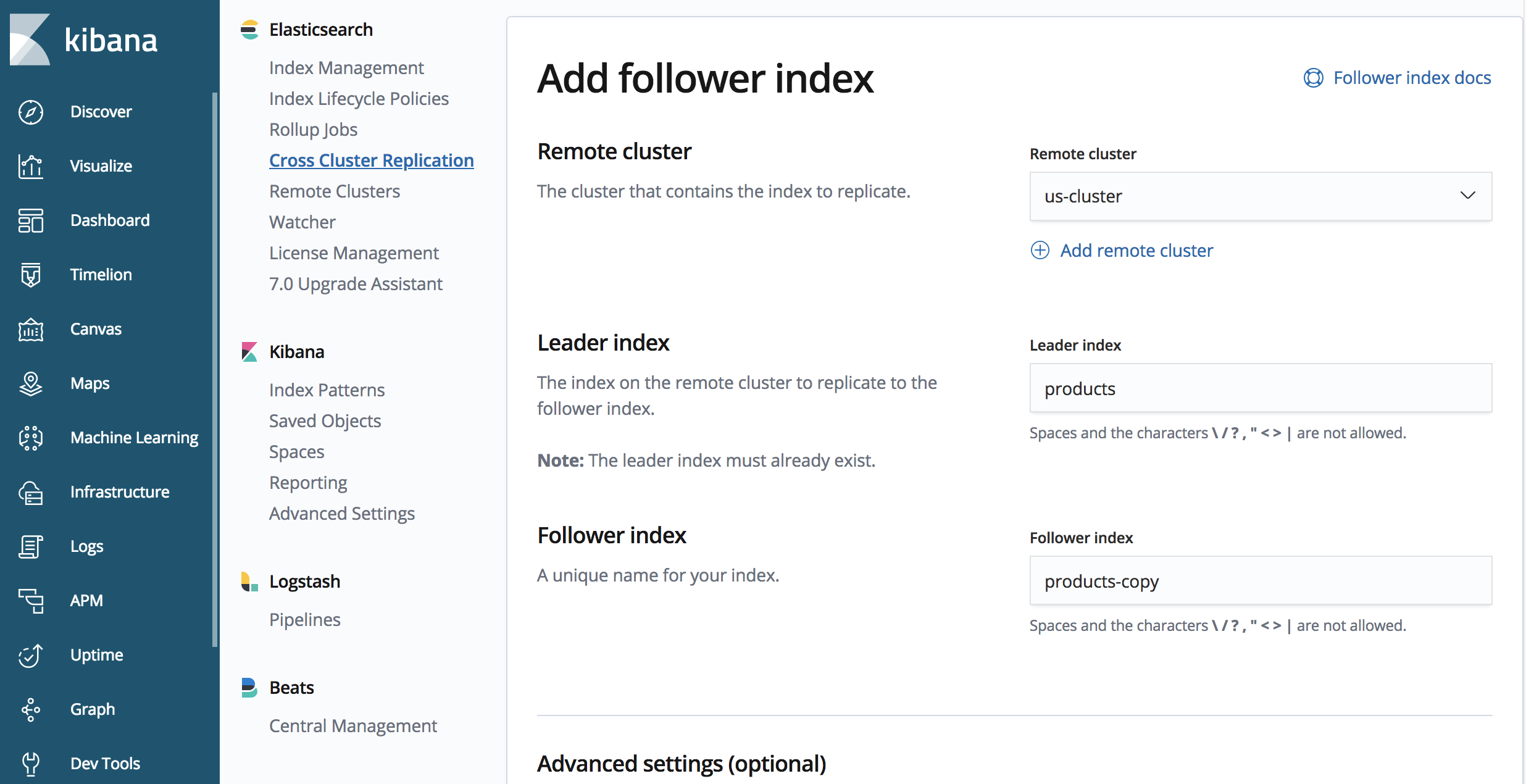
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
엔드포인트에 'products-copy'가 포함되어 있습니다. 이것은 'japan-cluster' 클러스터 내에서 복제된 인덱스의 이름입니다. 이전에 정의한 'us-cluster' 클러스터에서 복제하며, 복제할 인덱스의 이름을 'us-cluster' 클러스터에서 'products'으로 합니다.
복제된 인덱스는 읽기 전용이므로 쓰기 작업을 허용할 수 없습니다.
다 됐습니다! 하나의 Elasticsearch 클러스터에서 다른 클러스터로 복제하도록 인덱스를 구성했습니다!
인덱스 패턴에 대한 복제 시작
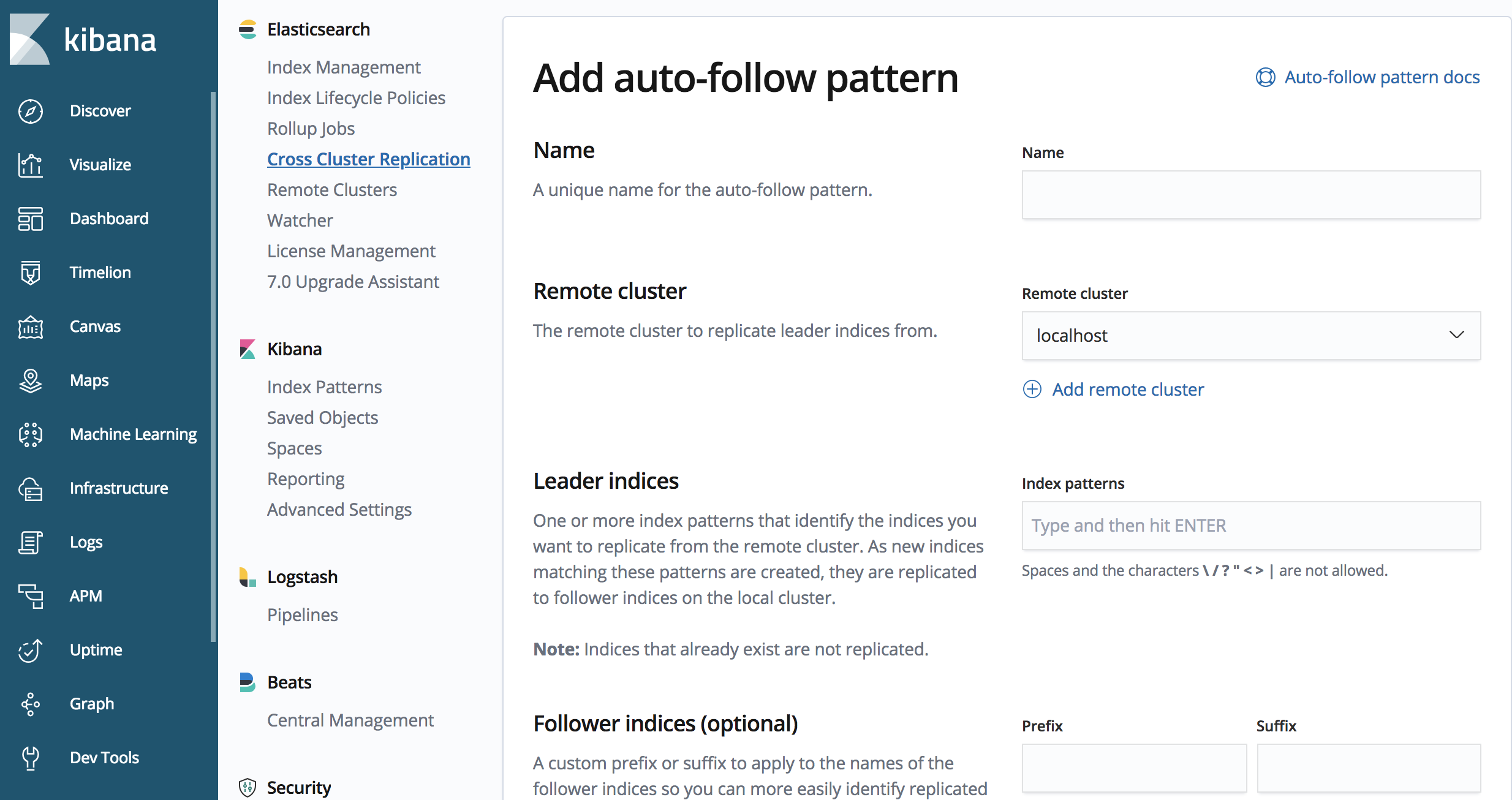
위의 예는 일일 인덱스가 있는 시간 기반 사용 사례 또는 데이터 양에 대해 잘 작동하지 않을 수 있습니다. CCR API에는 자동 팔로우 패턴, 즉 어떤 인덱스 패턴을 복제해야 하는지 정의하는 방법도 포함되어 있습니다.
CCR API를 사용하여 자동 팔로우 패턴을 정의할 수 있습니다
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
위의 샘플 API 호출은 'metricbeat'또는 'packetbeat'로 시작하는 인덱스를 복제합니다.
Kibana의 CCR UI를 사용하여 자동 팔로우 패턴을 정의할 수도 있습니다.
5. 테스트 복제 설정
이제 제품 인덱스가 ‘us-cluster’에서 ‘japan-cluster'로 복제되었으므로 테스트 문서를 삽입하고 복제되었는지 확인하겠습니다.
‘us-cluster’ 클러스터에서:
POST /products/_doc
{
"name" : "My cool new product"
}
이제 'japan-cluster'를 쿼리하여 문서가 복제되었는지 확인합니다.
GET /products-copy/_search
'us-cluster'에 쓰고 'japan-cluster'에 복제된 단일 문서가 있어야 합니다.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
데이터센터 간 관리 정보
CCR 용 관리 API의 일부와 조정 가능한 설정을 살펴보고 Elasticsearch에서 복제된 인덱스를 일반 인덱스로 변환하는 방법을 간략하게 살펴보겠습니다.
복제를 위한 관리 API
Elasticsearch에는 CCR에 유용한 관리 API가 여러 가지가 있습니다. 복제 디버깅, 복제 설정 수정 또는 자세한 진단 수집에 도움이 될 수 있습니다.
# CCR과 관련된 모든 통계를 반환
GET /_ccr/stats
# 주어진 인덱스에 대한 복제 일시 중지
POST //_ccr/pause_follow
# 대부분의 경우 일시 중지된 후 복제 재개
POST //_ccr/resume_follow
{
}
# 먼저 복제를 일시 중지해야 하는 인덱스에 대한 팔로우 해제(대상 인덱스에 대한 복제 중지)
POST //_ccr/unfollow
# 다음 인덱스에 대한 통계
GET //_ccr/stats
# 자동 팔로우 패턴 제거
DELETE /_ccr/auto_follow/
# 모든 자동 팔로우 패턴을 보거나 이름으로 자동 팔로우 패턴 가져오기
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
CCR 관리 API에 대한 자세한 내용은 Elasticsearch 참조 문서에서 확인할 수 있습니다.
팔로워 인덱스를 일반 인덱스로 변환
위의 관리 API의 하위 집합을 사용하여 Elasticsearch에서 팔로워 인덱스를 일반 인덱스로 변환하여 쓰기를 수락할 수 있습니다.
위의 예에서는 매우 간단한 설정을 했습니다. 'japan-cluster'에서 복제된 'products-copy' 인덱스는 읽기 전용이므로 쓰기를 허용할 수 없습니다. Elasticsearch에서 'products-copy' 인덱스를 일반 인덱스(쓰기 허용 가능)로 변환하려는 경우 다음 명령을 수행할 수 있습니다. 참고로 원래 인덱스('products')에 대한 쓰기는 계속 가능하며 ‘products-copy’ 인덱스를 일반 Elasticsearch 인덱스로 변환하기 전에 먼저 'products' 인덱스에 대한 쓰기를 제한해야 할 수도 있습니다.
# 복제 일시 정지
POST //_ccr/pause_follow
# 인덱스를 닫기
POST /my_index/_close
# 팔로우 해제
POST //_ccr/unfollow
# 색인 열기
POST /my_index/_open
Elasticsearch에서 CCR (Cross Cluster Replication) 계속 탐색
Elasticsearch에서 CCR을 시작하는 데 도움이 되도록 이 가이드를 작성했습니다. 이 가이드를 통해 CCR을 숙지하고 다양한 CCR API(Kibana에서 사용 가능한 UI 포함)에 대해 알아보고 기능을 테스트하는 데 도움이 되길 바랍니다. 추가 리소스에는 클러스터 간 복제 기능 시작 가이드 및 클러스터 간 복제 API 참조 가이드가 포함됩니다.
기존 방식대로 질문이 가득한 토론 포럼에 의견을 남겨주시면 최대한 빨리 답변해 드리겠습니다.