Build your own dashboard
editBuild your own dashboard
editWant to load some data into Kibana and build a dashboard? This tutorial shows you how to:
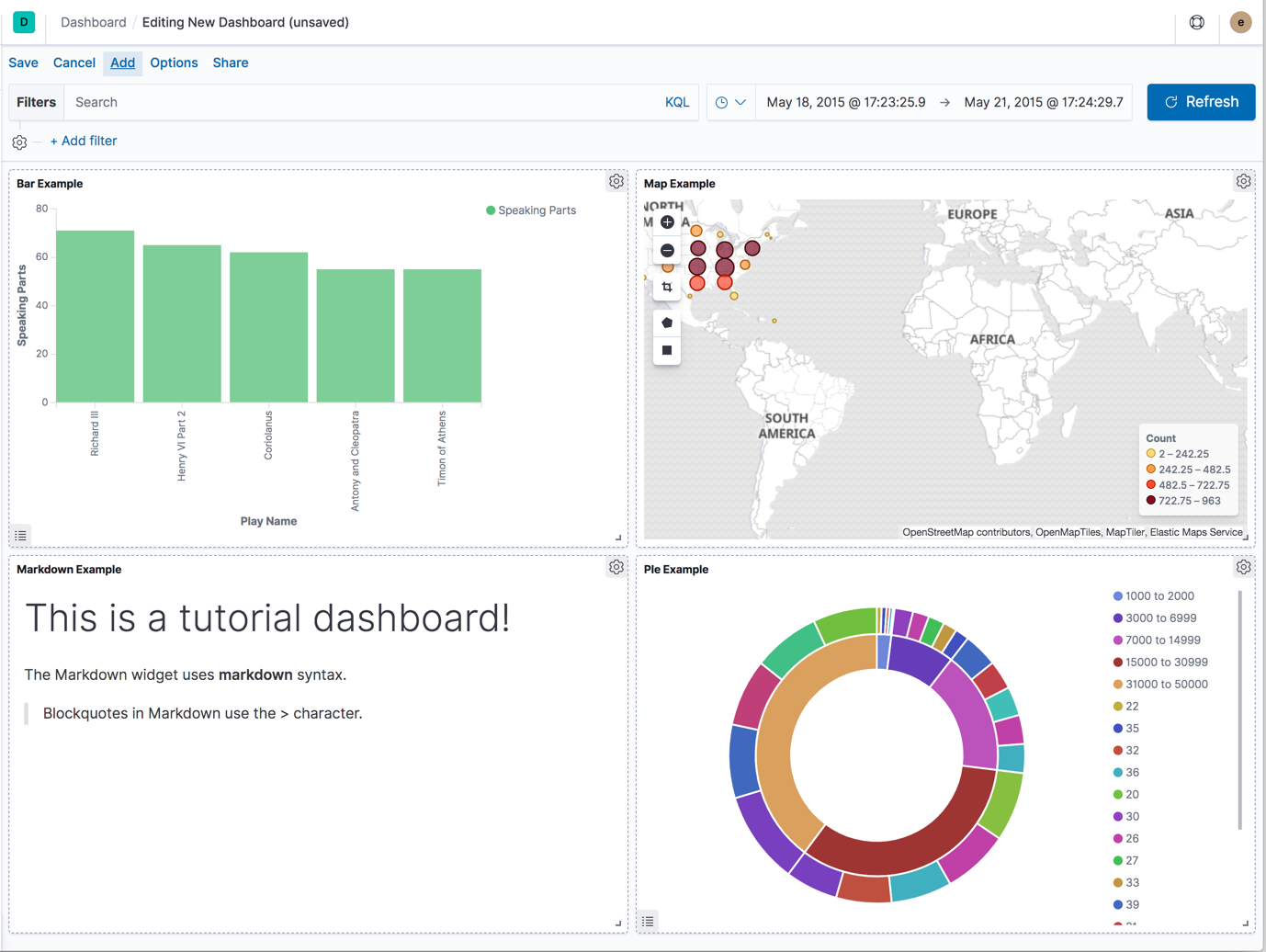
When you complete this tutorial, you’ll have a dashboard that looks like this.
Load sample data
editThis tutorial requires you to download three data sets:
- The complete works of William Shakespeare, suitably parsed into fields
- A set of fictitious accounts with randomly generated data
- A set of randomly generated log files
Download the data sets
editCreate a new working directory where you want to download the files. From that directory, run the following commands:
curl -O https://download.elastic.co/demos/kibana/gettingstarted/8.x/shakespeare.json curl -O https://download.elastic.co/demos/kibana/gettingstarted/8.x/accounts.zip curl -O https://download.elastic.co/demos/kibana/gettingstarted/8.x/logs.jsonl.gz
Two of the data sets are compressed. To extract the files, use these commands:
unzip accounts.zip gunzip logs.jsonl.gz
Structure of the data sets
editThe Shakespeare data set has this structure:
{
"line_id": INT,
"play_name": "String",
"speech_number": INT,
"line_number": "String",
"speaker": "String",
"text_entry": "String",
}
The accounts data set is structured as follows:
{
"account_number": INT,
"balance": INT,
"firstname": "String",
"lastname": "String",
"age": INT,
"gender": "M or F",
"address": "String",
"employer": "String",
"email": "String",
"city": "String",
"state": "String"
}
The logs data set has dozens of different fields. Here are the notable fields for this tutorial:
{
"memory": INT,
"geo.coordinates": "geo_point"
"@timestamp": "date"
}
Set up mappings
editBefore you load the Shakespeare and logs data sets, you must set up mappings for the fields. Mappings divide the documents in the index into logical groups and specify the characteristics of the fields. These characteristics include the searchability of the field and whether it’s tokenized, or broken up into separate words.
If security is enabled, you must have the all Kibana privilege to run this tutorial.
You must also have the create, manage read, write, and delete
index privileges. See Security privileges
for more information.
In Kibana Dev Tools > Console, set up a mapping for the Shakespeare data set:
PUT /shakespeare
{
"mappings": {
"properties": {
"speaker": {"type": "keyword"},
"play_name": {"type": "keyword"},
"line_id": {"type": "integer"},
"speech_number": {"type": "integer"}
}
}
}
This mapping specifies field characteristics for the data set:
-
The
speakerandplay_namefields are keyword fields. These fields are not analyzed. The strings are treated as a single unit even if they contain multiple words. -
The
line_idandspeech_numberfields are integers.
The logs data set requires a mapping to label the latitude and longitude pairs
as geographic locations by applying the geo_point type.
PUT /logstash-2015.05.18
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
PUT /logstash-2015.05.19
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
PUT /logstash-2015.05.20
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
The accounts data set doesn’t require any mappings.
Load the data sets
editAt this point, you’re ready to use the Elasticsearch bulk API to load the data sets:
curl -u elastic -H 'Content-Type: application/x-ndjson' -XPOST '<host>:<port>/bank/_bulk?pretty' --data-binary @accounts.json curl -u elastic -H 'Content-Type: application/x-ndjson' -XPOST '<host>:<port>/shakespeare/_bulk?pretty' --data-binary @shakespeare.json curl -u elastic -H 'Content-Type: application/x-ndjson' -XPOST '<host>:<port>/_bulk?pretty' --data-binary @logs.jsonl
Or for Windows users, in Powershell:
Invoke-RestMethod "http://<host>:<port>/bank/account/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "accounts.json" Invoke-RestMethod "http://<host>:<port>/shakespeare/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "shakespeare.json" Invoke-RestMethod "http://<host>:<port>/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "logs.jsonl"
These commands might take some time to execute, depending on the available computing resources.
Verify successful loading:
GET /_cat/indices?v
Your output should look similar to this:
health status index pri rep docs.count docs.deleted store.size pri.store.size yellow open bank 1 1 1000 0 418.2kb 418.2kb yellow open shakespeare 1 1 111396 0 17.6mb 17.6mb yellow open logstash-2015.05.18 1 1 4631 0 15.6mb 15.6mb yellow open logstash-2015.05.19 1 1 4624 0 15.7mb 15.7mb yellow open logstash-2015.05.20 1 1 4750 0 16.4mb 16.4mb