Cross-cluster replication
editCross-cluster replication
editWith cross-cluster replication, you can replicate indices across clusters to:
- Continue handling search requests in the event of a datacenter outage
- Prevent search volume from impacting indexing throughput
- Reduce search latency by processing search requests in geo-proximity to the user
Cross-cluster replication uses an active-passive model. You index to a leader index, and the data is replicated to one or more read-only follower indices. Before you can add a follower index to a cluster, you must configure the remote cluster that contains the leader index.
When the leader index receives writes, the follower indices pull changes from the leader index on the remote cluster. You can manually create follower indices, or configure auto-follow patterns to automatically create follower indices for new time series indices.
You configure cross-cluster replication clusters in a uni-directional or bi-directional setup:
- In a uni-directional configuration, one cluster contains only leader indices, and the other cluster contains only follower indices.
- In a bi-directional configuration, each cluster contains both leader and follower indices.
In a uni-directional configuration, the cluster containing follower indices must be running the same or newer version of Elasticsearch as the remote cluster. If newer, the versions must also be compatible as outlined in the following matrix.
Version compatibility matrix
Local cluster |
|||||||||
Remote cluster |
5.0–5.5 |
5.6 |
6.0–6.6 |
6.7 |
6.8 |
7.0 |
7.1–7.16 |
7.17 |
8.0–8.6 |
5.0–5.5 |
|
|
|
|
|
|
|
|
|
5.6 |
|
|
|
|
|
|
|
|
|
6.0–6.6 |
|
|
|
|
|
|
|
|
|
6.7 |
|
|
|
|
|
|
|
|
|
6.8 |
|
|
|
|
|
|
|
|
|
7.0 |
|
|
|
|
|
|
|
|
|
7.1–7.16 |
|
|
|
|
|
|
|
|
|
7.17 |
|
|
|
|
|
|
|
|
|
8.0–8.6 |
|
|
|
|
|
|
|
|
|
Multi-cluster architectures
editUse cross-cluster replication to construct several multi-cluster architectures within the Elastic Stack:
- Disaster recovery in case a primary cluster fails, with a secondary cluster serving as a hot backup
- Data locality to maintain multiple copies of the dataset close to the application servers (and users), and reduce costly latency
- Centralized reporting for minimizing network traffic and latency in querying multiple geo-distributed Elasticsearch clusters, or for preventing search load from interfering with indexing by offloading search to a secondary cluster
Watch the cross-cluster replication webinar to learn more about the following use cases. Then, set up cross-cluster replication on your local machine and work through the demo from the webinar.
In all of these use cases, you must
configure security independently on every
cluster. The security configuration is not replicated when configuring cross-cluster replication for
disaster recovery. To ensure that the Elasticsearch security feature state is backed up,
take snapshots regularly. You can then restore
the native users, roles, and tokens from your security configuration.
Disaster recovery and high availability
editDisaster recovery provides your mission-critical applications with the tolerance to withstand datacenter or region outages. This use case is the most common deployment of cross-cluster replication. You can configure clusters in different architectures to support disaster recovery and high availability:
Single disaster recovery datacenter
editIn this configuration, data is replicated from the production datacenter to the disaster recovery datacenter. Because the follower indices replicate the leader index, your application can use the disaster recovery datacenter if the production datacenter is unavailable.

Multiple disaster recovery datacenters
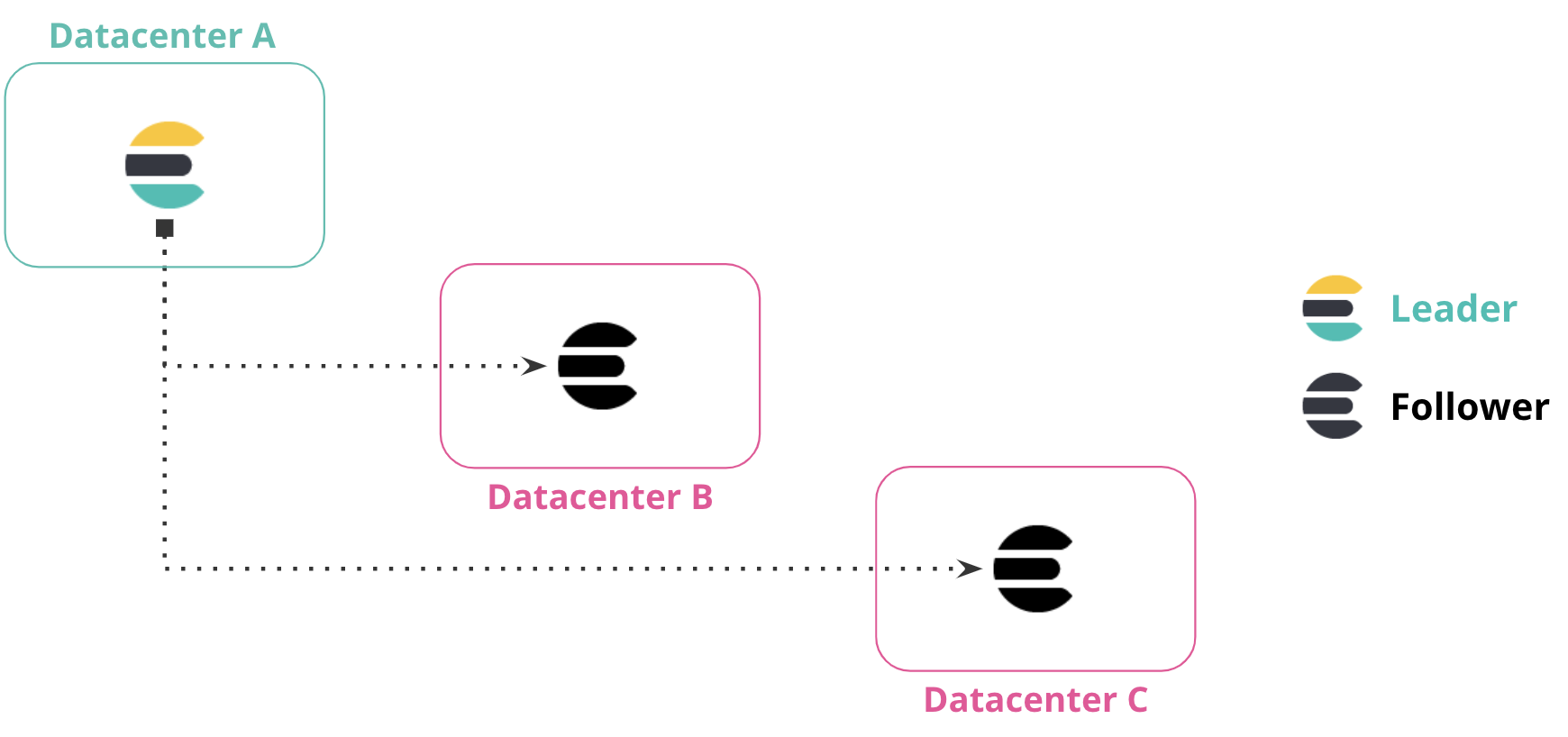
editYou can replicate data from one datacenter to multiple datacenters. This configuration provides both disaster recovery and high availability, ensuring that data is replicated in two datacenters if the primary datacenter is down or unavailable.
In the following diagram, data from Datacenter A is replicated to Datacenter B and Datacenter C, which both have a read-only copy of the leader index from Datacenter A.
Chained replication
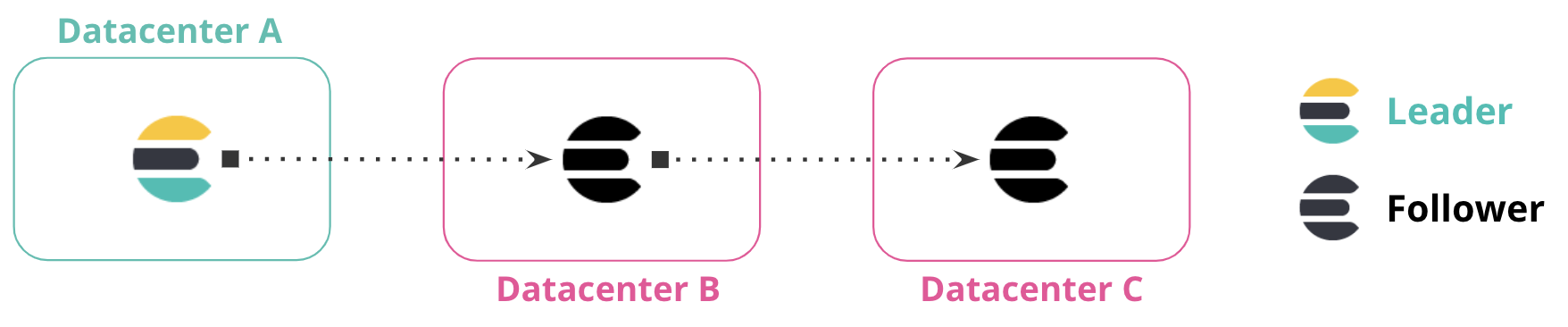
editYou can replicate data across multiple datacenters to form a replication chain. In the following diagram, Datacenter A contains the leader index. Datacenter B replicates data from Datacenter A, and Datacenter C replicates from the follower indices in Datacenter B. The connection between these datacenters forms a chained replication pattern.
Bi-directional replication
editIn a bi-directional replication setup, all clusters have access to view all data, and all clusters have an index to write to without manually implementing failover. Applications can write to the local index within each datacenter, and read across multiple indices for a global view of all information.
This configuration requires no manual intervention when a cluster or datacenter is unavailable. In the following diagram, if Datacenter A is unavailable, you can continue using Datacenter B without manual failover. When Datacenter A comes online, replication resumes between the clusters.
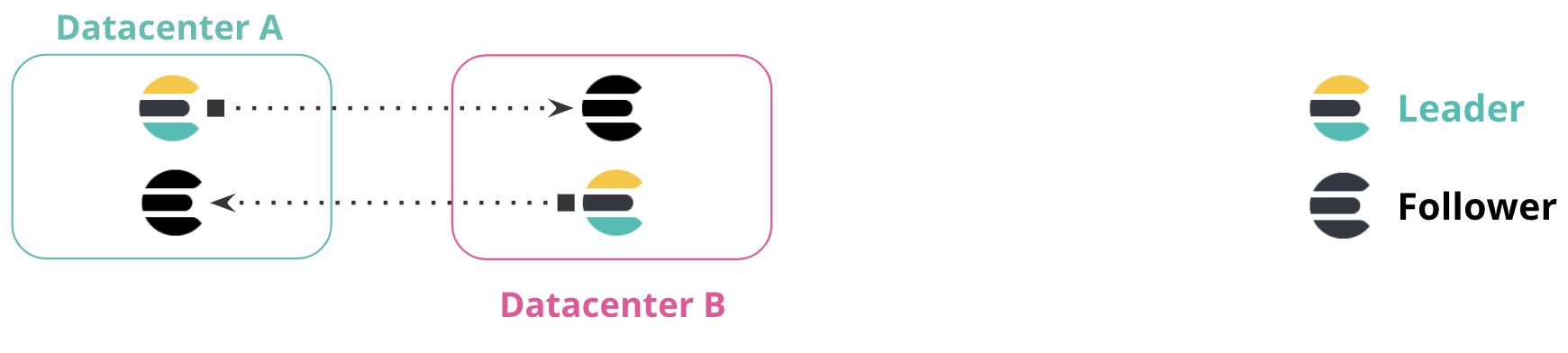
This configuration is particularly useful for index-only workloads, where no updates to document values occur. In this configuration, documents indexed by Elasticsearch are immutable. Clients are located in each datacenter alongside the Elasticsearch cluster, and do not communicate with clusters in different datacenters.
Data locality
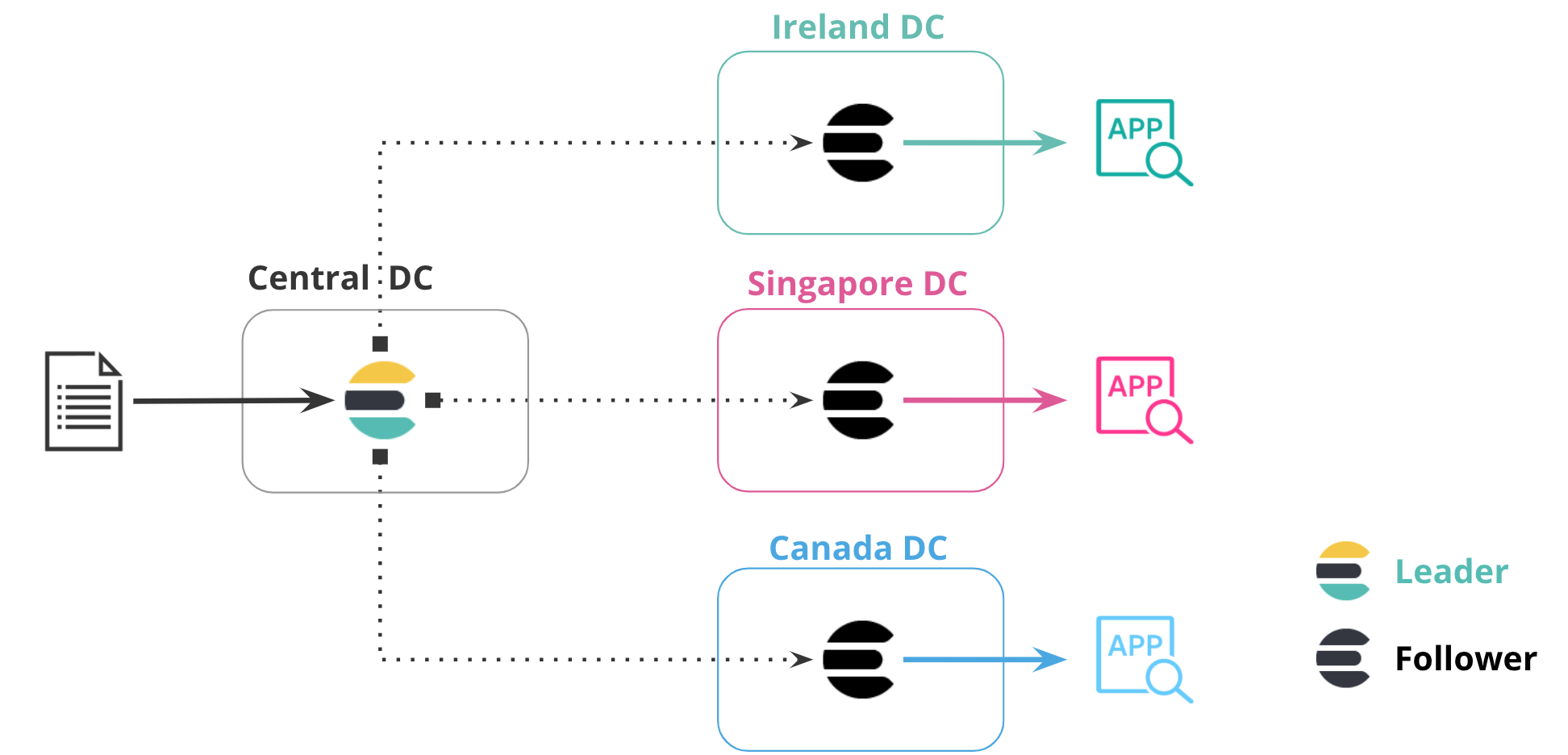
editBringing data closer to your users or application server can reduce latency and response time. This methodology also applies when replicating data in Elasticsearch. For example, you can replicate a product catalog or reference dataset to 20 or more datacenters around the world to minimize the distance between the data and the application server.
In the following diagram, data is replicated from one datacenter to three additional datacenters, each in their own region. The central datacenter contains the leader index, and the additional datacenters contain follower indices that replicate data in that particular region. This configuration puts data closer to the application accessing it.
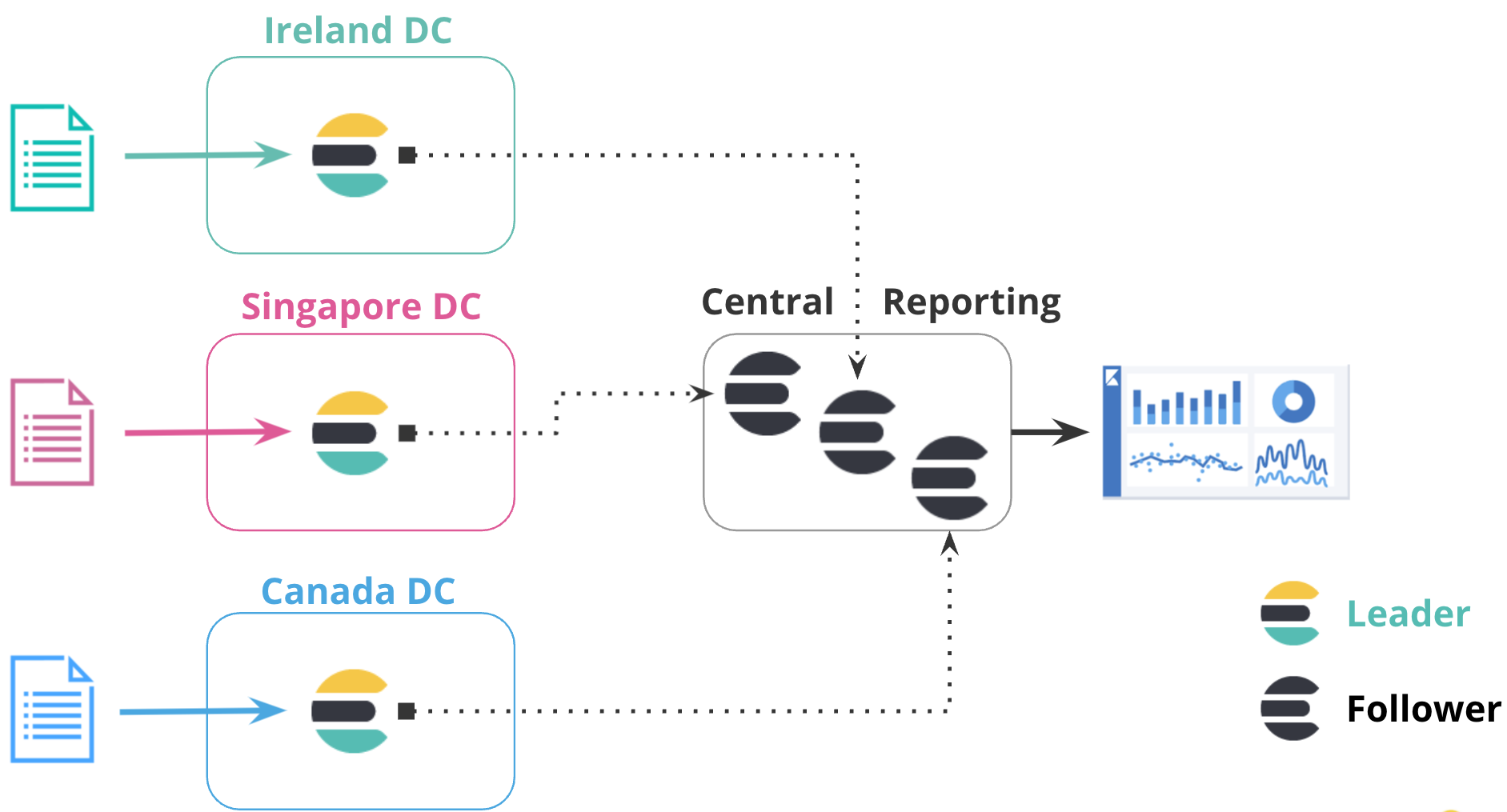
Centralized reporting
editUsing a centralized reporting cluster is useful when querying across a large network is inefficient. In this configuration, you replicate data from many smaller clusters to the centralized reporting cluster.
For example, a large global bank might have 100 Elasticsearch clusters around the world that are distributed across different regions for each bank branch. Using cross-cluster replication, the bank can replicate events from all 100 banks to a central cluster to analyze and aggregate events locally for reporting. Rather than maintaining a mirrored cluster, the bank can use cross-cluster replication to replicate specific indices.
In the following diagram, data from three datacenters in different regions is replicated to a centralized reporting cluster. This configuration enables you to copy data from regional hubs to a central cluster, where you can run all reports locally.
Replication mechanics
editAlthough you set up cross-cluster replication at the index level, Elasticsearch achieves replication at the shard level. When a follower index is created, each shard in that index pulls changes from its corresponding shard in the leader index, which means that a follower index has the same number of shards as its leader index. All operations on the leader are replicated by the follower, such as operations to create, update, or delete a document. These requests can be served from any copy of the leader shard (primary or replica).
When a follower shard sends a read request, the leader shard responds with any new operations, limited by the read parameters that you establish when configuring the follower index. If no new operations are available, the leader shard waits up to the configured timeout for new operations. If the timeout elapses, the leader shard responds to the follower shard that there are no new operations. The follower shard updates shard statistics and immediately sends another read request to the leader shard. This communication model ensures that network connections between the remote cluster and the local cluster are continually in use, avoiding forceful termination by an external source such as a firewall.
If a read request fails, the cause of the failure is inspected. If the cause of the failure is deemed to be recoverable (such as a network failure), the follower shard enters into a retry loop. Otherwise, the follower shard pauses until you resume it.
Processing updates
editYou can’t manually modify a follower index’s mappings or aliases. To make changes, you must update the leader index. Because they are read-only, follower indices reject writes in all configurations.
Although changes to aliases on the leader index are replicated to follower
indices, write indices are ignored. Follower indices can’t accept direct writes,
so if any leader aliases have is_write_index set to true, that value is
forced to false.
For example, you index a document named doc_1 in Datacenter A, which
replicates to Datacenter B. If a client connects to Datacenter B and attempts
to update doc_1, the request fails. To update doc_1, the client must
connect to Datacenter A and update the document in the leader index.
When a follower shard receives operations from the leader shard, it places those operations in a write buffer. The follower shard submits bulk write requests using operations from the write buffer. If the write buffer exceeds its configured limits, no additional read requests are sent. This configuration provides a back-pressure against read requests, allowing the follower shard to resume sending read requests when the write buffer is no longer full.
To manage how operations are replicated from the leader index, you can configure settings when creating the follower index.
Changes in the index mapping on the leader index are replicated to the follower index as soon as possible. This behavior is true for index settings as well, except for some settings that are local to the leader index. For example, changing the number of replicas on the leader index is not replicated by the follower index, so that setting might not be retrieved.
If you apply a non-dynamic settings change to the leader index that is needed by the follower index, the follower index closes itself, applies the settings update, and then re-opens itself. The follower index is unavailable for reads and cannot replicate writes during this cycle.
Initializing followers using remote recovery
editWhen you create a follower index, you cannot use it until it is fully initialized. The remote recovery process builds a new copy of a shard on a follower node by copying data from the primary shard in the leader cluster.
Elasticsearch uses this remote recovery process to bootstrap a follower index using the data from the leader index. This process provides the follower with a copy of the current state of the leader index, even if a complete history of changes is not available on the leader due to Lucene segment merging.
Remote recovery is a network intensive process that transfers all of the Lucene segment files from the leader cluster to the follower cluster. The follower requests that a recovery session be initiated on the primary shard in the leader cluster. The follower then requests file chunks concurrently from the leader. By default, the process concurrently requests five 1MB file chunks. This default behavior is designed to support leader and follower clusters with high network latency between them.
You can modify dynamic remote recovery settings to rate-limit the transmitted data and manage the resources consumed by remote recoveries.
Use the recovery API on the cluster containing the follower
index to obtain information about an in-progress remote recovery. Because Elasticsearch
implements remote recoveries using the
snapshot and restore infrastructure, running remote
recoveries are labelled as type snapshot in the recovery API.
Replicating a leader requires soft deletes
editCross-cluster replication works by replaying the history of individual write operations that were performed on the shards of the leader index. Elasticsearch needs to retain the history of these operations on the leader shards so that they can be pulled by the follower shard tasks. The underlying mechanism used to retain these operations is soft deletes.
A soft delete occurs whenever an existing document is deleted or updated. By retaining these soft deletes up to configurable limits, the history of operations can be retained on the leader shards and made available to the follower shard tasks as it replays the history of operations.
The index.soft_deletes.retention_lease.period
setting defines the maximum time to retain a shard history retention lease
before it is considered expired. This setting determines how long the cluster
containing your follower index can be offline, which is 12 hours by default. If
a shard copy recovers after its retention lease expires, but the missing
operations are still available on the leader index, then Elasticsearch will establish a
new lease and copy the missing operations. However Elasticsearch does not guarantee to
retain unleased operations, so it is also possible that some of the missing
operations have been discarded by the leader and are now completely
unavailable. If this happens then the follower cannot recover automatically so
you must recreate it.
Soft deletes must be enabled for indices that you want to use as leader indices. Soft deletes are enabled by default on new indices created on or after Elasticsearch 7.0.0.
Cross-cluster replication cannot be used on existing indices created using Elasticsearch 7.0.0 or earlier, where soft deletes are disabled. You must reindex your data into a new index with soft deletes enabled.
Use cross-cluster replication
editThis following sections provide more information about how to configure and use cross-cluster replication:
Cross-cluster replication limitations
editCross-cluster replication is designed to replicate user-generated indices only, and doesn’t currently replicate any of the following:
If you want to replicate any of this data, you must replicate it to a remote cluster manually.
Data for searchable snapshot indices is stored in the snapshot repository. Cross-cluster replication won’t replicate these indices completely, even though they’re either partially or fully-cached on the Elasticsearch nodes. To achieve searchable snapshots in a remote cluster, configure snapshot repositories on the remote cluster and use the same index lifecycle management policy from the local cluster to move data into the cold or frozen tiers on the remote cluster.