WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Making Changes Persistentedit
Without an fsync to flush data in the filesystem cache to disk, we cannot
be sure that the data will still be there after a power failure, or even after
exiting the application normally. For Elasticsearch to be reliable, it needs
to ensure that changes are persisted to disk.
In Dynamically Updatable Indices, we said that a full commit flushes segments to disk and writes a commit point, which lists all known segments. Elasticsearch uses this commit point during startup or when reopening an index to decide which segments belong to the current shard.
While we refresh once every second to achieve near real-time search, we still need to do full commits regularly to make sure that we can recover from failure. But what about the document changes that happen between commits? We don’t want to lose those either.
Elasticsearch added a translog, or transaction log, which records every operation in Elasticsearch as it happens. With the translog, the process now looks like this:
-
When a document is indexed, it is added to the in-memory buffer and appended to the translog, as shown in Figure 21, “New documents are added to the in-memory buffer and appended to the transaction log”.
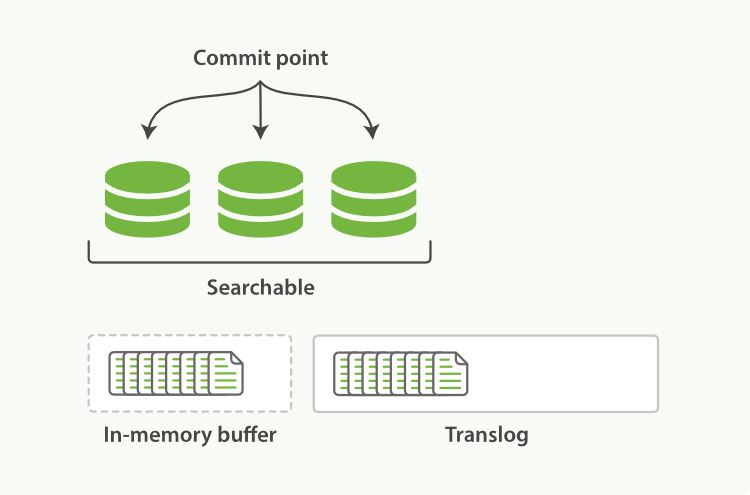 Figure 21. New documents are added to the in-memory buffer and appended to the transaction log
Figure 21. New documents are added to the in-memory buffer and appended to the transaction log -
The refresh leaves the shard in the state depicted in Figure 22, “After a refresh, the buffer is cleared but the transaction log is not”. Once every second, the shard is refreshed:
-
The docs in the in-memory buffer are written to a new segment,
without an
fsync. - The segment is opened to make it visible to search.
- The in-memory buffer is cleared.
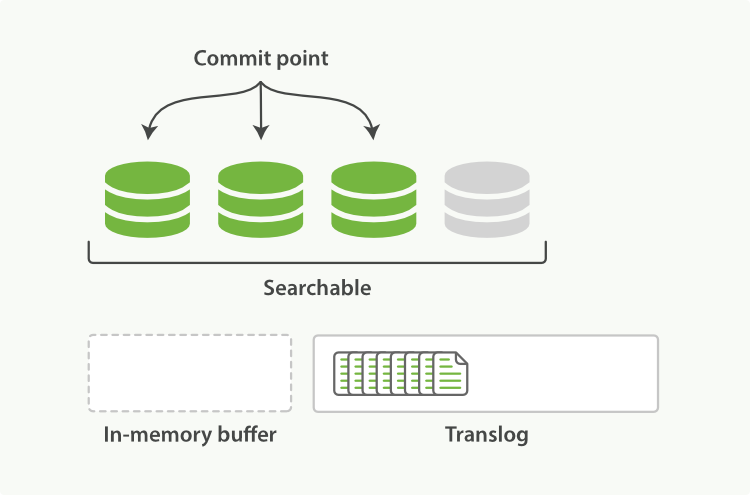 Figure 22. After a refresh, the buffer is cleared but the transaction log is not
Figure 22. After a refresh, the buffer is cleared but the transaction log is not -
The docs in the in-memory buffer are written to a new segment,
without an
-
This process continues with more documents being added to the in-memory buffer and appended to the transaction log (see Figure 23, “The transaction log keeps accumulating documents”).
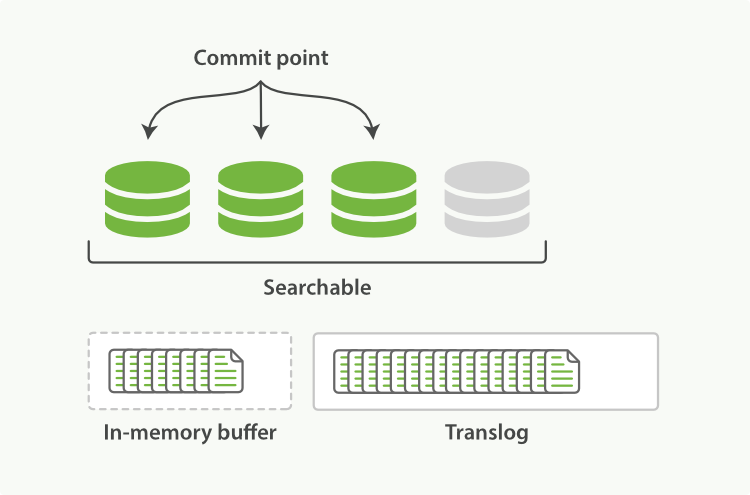 Figure 23. The transaction log keeps accumulating documents
Figure 23. The transaction log keeps accumulating documents -
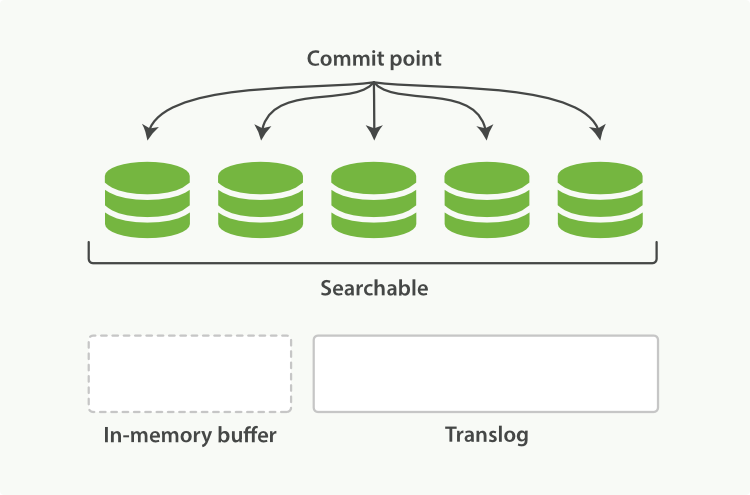
Every so often—such as when the translog is getting too big—the index is flushed; a new translog is created, and a full commit is performed (see Figure 24, “After a flush, the segments are fully commited and the transaction log is cleared”):
- Any docs in the in-memory buffer are written to a new segment.
- The buffer is cleared.
- A commit point is written to disk.
-
The filesystem cache is flushed with an
fsync. - The old translog is deleted.
The translog provides a persistent record of all operations that have not yet been flushed to disk. When starting up, Elasticsearch will use the last commit point to recover known segments from disk, and will then replay all operations in the translog to add the changes that happened after the last commit.
The translog is also used to provide real-time CRUD. When you try to retrieve, update, or delete a document by ID, it first checks the translog for any recent changes before trying to retrieve the document from the relevant segment. This means that it always has access to the latest known version of the document, in real-time.
flush APIedit
The action of performing a commit and truncating the translog is known in
Elasticsearch as a flush. Shards are flushed automatically every 30
minutes, or when the translog becomes too big. See the
translog documentation for settings
that can be used to control these thresholds:
The flush API can be used to perform a manual flush:
|
Flush the |
|
|
Flush all indices and wait until all flushes have completed before returning. |
You seldom need to issue a manual flush yourself; usually, automatic
flushing is all that is required.
That said, it is beneficial to flush your indices before restarting a node or closing an index. When Elasticsearch tries to recover or reopen an index, it has to replay all of the operations in the translog, so the shorter the log, the faster the recovery.