WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Segment Mergingedit
With the automatic refresh process creating a new segment every second, it doesn’t take long for the number of segments to explode. Having too many segments is a problem. Each segment consumes file handles, memory, and CPU cycles. More important, every search request has to check every segment in turn; the more segments there are, the slower the search will be.
Elasticsearch solves this problem by merging segments in the background. Small segments are merged into bigger segments, which, in turn, are merged into even bigger segments.
This is the moment when those old deleted documents are purged from the filesystem. Deleted documents (or old versions of updated documents) are not copied over to the new bigger segment.
There is nothing you need to do to enable merging. It happens automatically while you are indexing and searching. The process works like as depicted in Figure 25, “Two commited segments and one uncommited segment in the process of being merged into a bigger segment”:
- While indexing, the refresh process creates new segments and opens them for search.
-
The merge process selects a few segments of similar size and merges them into a new bigger segment in the background. This does not interrupt indexing and searching.
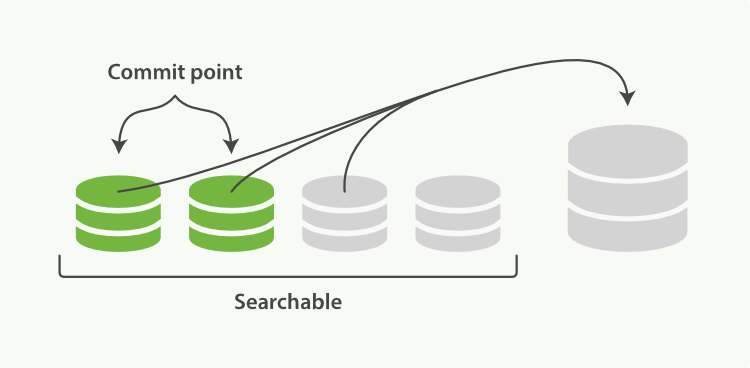 Figure 25. Two commited segments and one uncommited segment in the process of being merged into a bigger segment
Figure 25. Two commited segments and one uncommited segment in the process of being merged into a bigger segment -
Figure 26, “Once merging has finished, the old segments are deleted” illustrates activity as the merge completes:
- The new segment is flushed to disk.
- A new commit point is written that includes the new segment and excludes the old, smaller segments.
- The new segment is opened for search.
- The old segments are deleted.
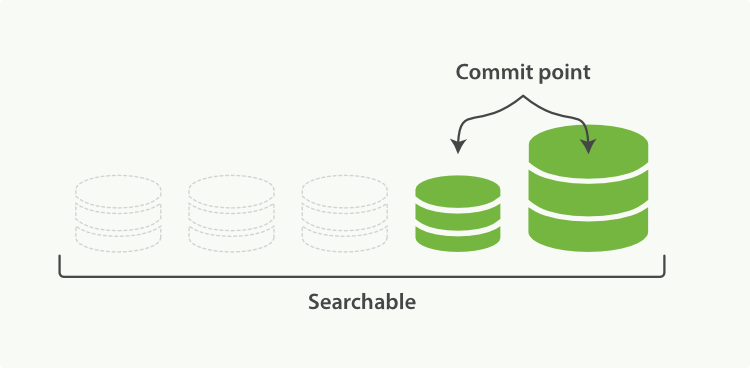 Figure 26. Once merging has finished, the old segments are deleted
Figure 26. Once merging has finished, the old segments are deleted
The merging of big segments can use a lot of I/O and CPU, which can hurt search performance if left unchecked. By default, Elasticsearch throttles the merge process so that search still has enough resources available to perform well.
See Segments and Merging for advice about tuning merging for your use case.
optimize APIedit
The optimize API is best described as the forced merge API. It forces a
shard to be merged down to the number of segments specified in the
max_num_segments parameter. The intention is to reduce the number of
segments (usually to one) in order to speed up search performance.
The optimize API should not be used on a dynamic index—an
index that is being actively updated. The background merge process does a
very good job, and optimizing will hinder the process. Don’t interfere!
In certain specific circumstances, the optimize API can be beneficial.
The typical use case is for logging, where logs are stored in an index per
day, week, or month. Older indices are essentially read-only; they are
unlikely to change.
In this case, it can be useful to optimize the shards of an old index down to a single segment each; it will use fewer resources and searches will be quicker:
Be aware that merges triggered by the optimize API are not
throttled at all. They can consume all of the I/O on your nodes, leaving
nothing for search and potentially making your cluster unresponsive. If you
plan on optimizing an index, you should use shard allocation (see
Migrate Old Indices) to first move the index to a node where it is safe to
run.