WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Dynamically Updatable Indices
editDynamically Updatable Indicesedit
The next problem that needed to be solved was how to make an inverted index updatable without losing the benefits of immutability? The answer turned out to be: use more than one index.
Instead of rewriting the whole inverted index, add new supplementary indices to reflect more-recent changes. Each inverted index can be queried in turn—starting with the oldest—and the results combined.
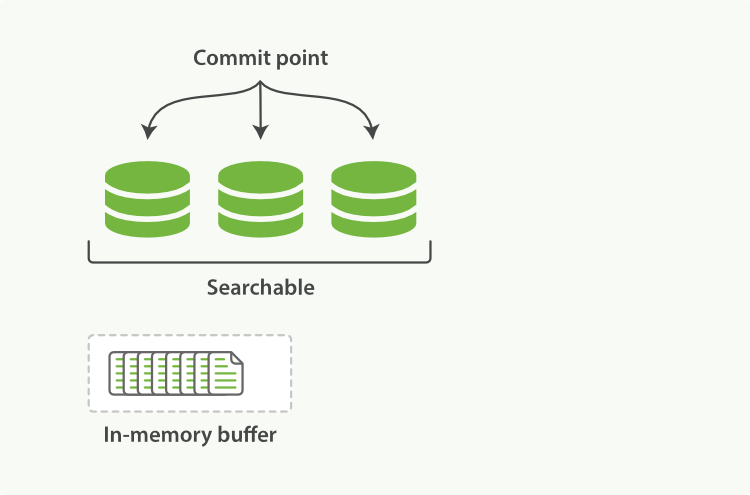
Lucene, the Java libraries on which Elasticsearch is based, introduced the concept of per-segment search. A segment is an inverted index in its own right, but now the word index in Lucene came to mean a collection of segments plus a commit point—a file that lists all known segments, as depicted in Figure 16, “A Lucene index with a commit point and three segments”. New documents are first added to an in-memory indexing buffer, as shown in Figure 17, “A Lucene index with new documents in the in-memory buffer, ready to commit”, before being written to an on-disk segment, as in Figure 18, “After a commit, a new segment is added to the commit point and the buffer is cleared”
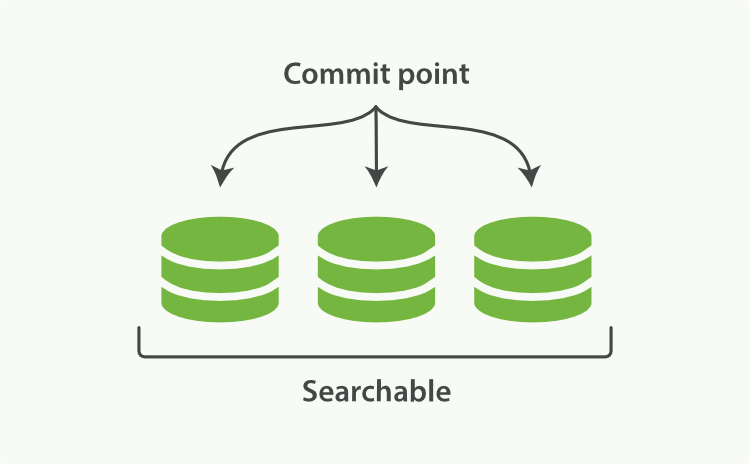
A per-segment search works as follows:
- New documents are collected in an in-memory indexing buffer. See Figure 17, “A Lucene index with new documents in the in-memory buffer, ready to commit”.
-
Every so often, the buffer is commited:
- A new segment—a supplementary inverted index—is written to disk.
- A new commit point is written to disk, which includes the name of the new segment.
- The disk is fsync’ed—all writes waiting in the filesystem cache are flushed to disk, to ensure that they have been physically written.
- The new segment is opened, making the documents it contains visible to search.
- The in-memory buffer is cleared, and is ready to accept new documents.
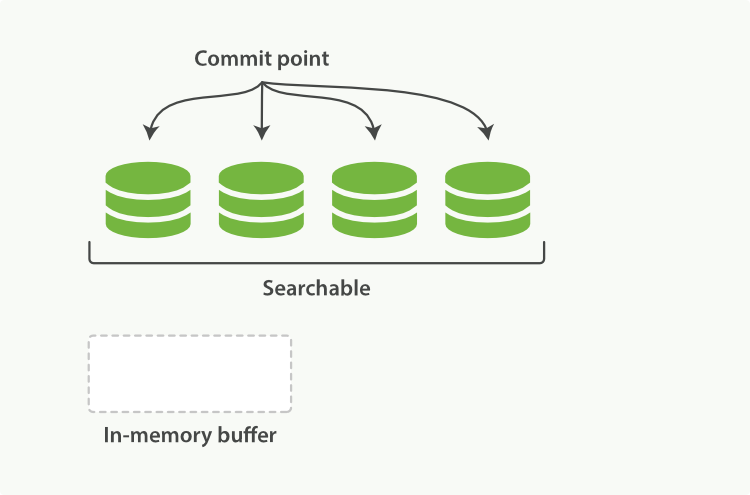
When a query is issued, all known segments are queried in turn. Term statistics are aggregated across all segments to ensure that the relevance of each term and each document is calculated accurately. In this way, new documents can be added to the index relatively cheaply.
Deletes and Updatesedit
Segments are immutable, so documents cannot be removed from older segments,
nor can older segments be updated to reflect a newer version of a document.
Instead, every commit point includes a .del file that lists which documents
in which segments have been deleted.
When a document is “deleted,” it is actually just marked as deleted in the
.del file. A document that has been marked as deleted can still match a
query, but it is removed from the results list before the final query results
are returned.
Document updates work in a similar way: when a document is updated, the old version of the document is marked as deleted, and the new version of the document is indexed in a new segment. Perhaps both versions of the document will match a query, but the older deleted version is removed before the query results are returned.
In Segment Merging, we show how deleted documents are purged from the filesystem.