Signal Media: Optimizing for More Elasticsearch Power with Less Elasticsearch Cluster
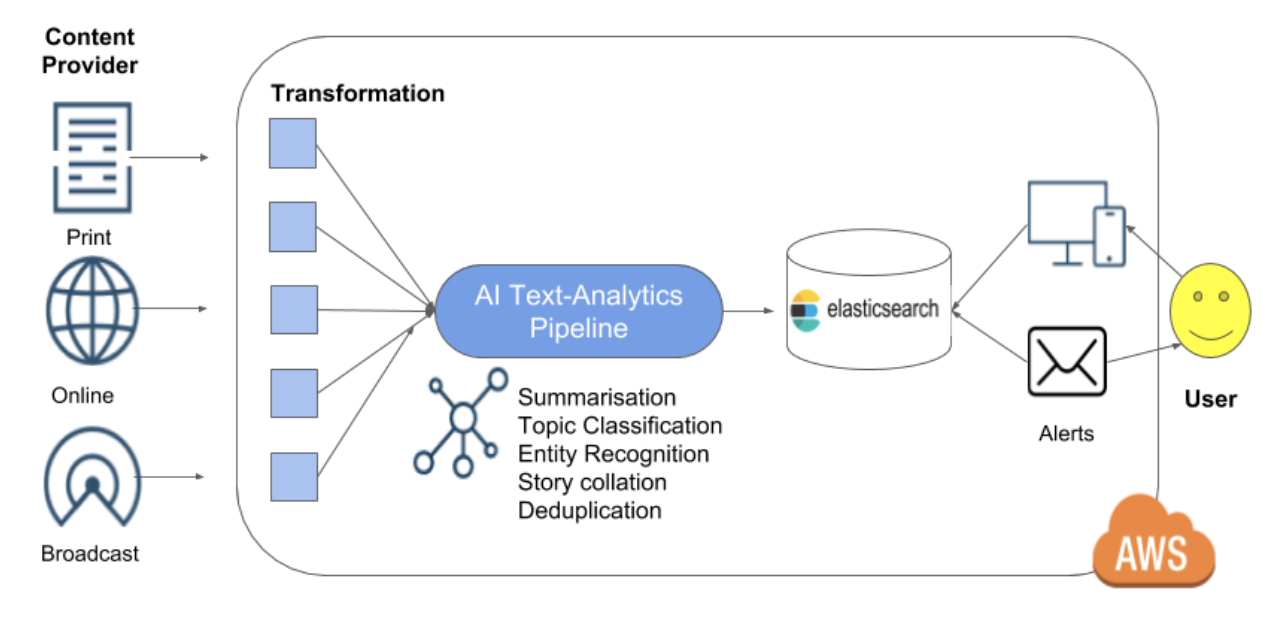
Elasticsearch is at the heart of Signal's products enabling our clients to stay on-top of the world's news and information. Every day, we ingest millions of documents from various sources, like newspapers and TV transcripts. Our AI-powered Text-Analytics Pipeline extracts and annotates entities (e.g companies, persons, etc.) and identifies topics (e.g.: tax, climate change, etc). All this data is indexed in Elasticsearch, enabling sophisticated searches and aggregations for our customers through a web application, a mobile app and tailored email alerts. In this blog post I am going to explain how we applied automation, monitoring and performance testing to evolve our Elasticsearch cluster to be performant, reliable and cost efficient in a 24/7 environment.
Learning how to scale
Since the start of our success story with Elastic in 2015, our platform has evolved tremendously and Elasticsearch has been crucial to build it. We have established a much larger customer base and the amount of content we index and store is many times higher. Yet we are currently running on the same number of data nodes (15) with the same CPU and memory resources as in 2015.
However, we haven't always been that lean and stable. Three years ago, as we were adding more content, we had to spin up more and more machines to keep afloat, which caused our AWS bill to increase steeply. At some point we had up to 60 memory optimised machines which would still run out of memory if we wouldn't manually clear caches. Despite the high number of nodes, we suffered from latency spikes that we couldn't explain.
Fortunately, we haven't been alone in our endeavour to learn how to configure and use Elasticsearch. We engaged early on with London's Elastic community, and from there went on to purchase a subscription from Elastic. With that subscription, all of Elastic's tools and products became available to us, as well as the valuable guidance of their Support team. Our two biggest boosts came from upgrading our version and rethinking sharding — both of which were recommendations directly from Elastic Support.
Upgrade for Performance
The first advice we got from Elastic's experts was upgrading our outdated version of Elasticsearch 1.5 to the latest version which was 2.3 at the time. The upgrade gave us instant improvements of stability and efficiency. Instead of running 60 nodes we could then run with 30 of them which cut our costs by half.
We've since moved to Elasticsearch 6, and have seen even more improvements. Upgrades can be a lot of work, but they really are a great way to boost performance. Here are a few things we did to make the upgrade process run smoothly.
Automation is key
Without automation any update to a production cluster can be a risky odyssey. Manual changes to individual nodes are hard to track and can lead to nasty surprises. To upgrade the cluster we had to catch up with automation first.
We started with defining all required AWS cloud infrastructure with Terraform. Instead of manually updating machine images (AMIs) for master and data nodes, we automated the creation of images with Packer. This allowed us to create, update and destroy cluster infrastructure without much effort.
Even more important is the ability to automatically roll out minor updates and changes to all nodes. In a rolling upgrade, one node at a time is shut down, upgraded and brought up again.
Thanks to Elasticsearch's replication the cluster stays operational when a single node is missing, so that a rolling upgrades can be performed without causing interruption. We also developed a Cluster Control Tool to safely perform minor upgrades.
Zero Downtime Blue Green Upgrades
However, upgrading an only half-automated, 60 node version 1.5 cluster in-place still seemed to be scary. We decided to take a blue-green approach instead - a battle-tested pattern to reduce risk. The idea is to setup a cluster with the new version (green) next to the production cluster (blue).
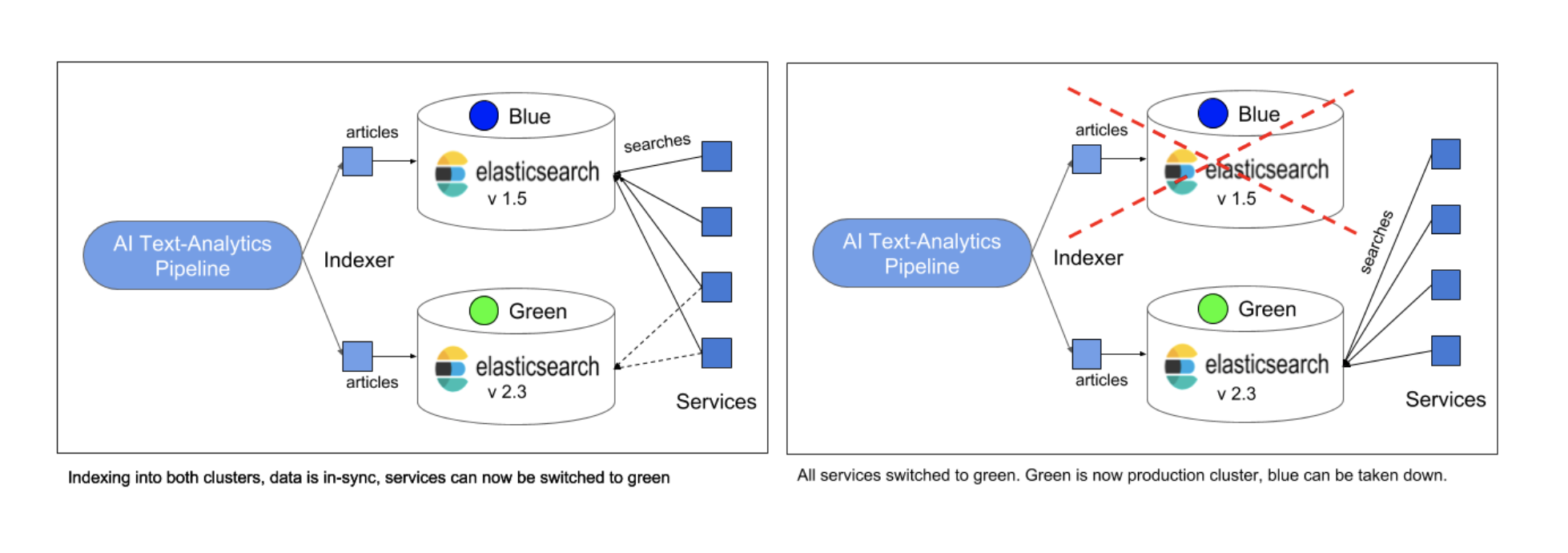
First, we indexed everything into both clusters in parallel. Then, we restored the whole dataset from snapshots bringing blue and green in-sync. At this point we were able to run performance tests on the new cluster with the actual data set. Finally, to take the green cluster into full action, we switched one service over at a time by pointing it to the new cluster, observing carefully if any issues would occur. In case of any problems, we would have quickly rolled back the respective service to the blue cluster. Finally, after everything was switched to the new cluster, we took the blue cluster down. This approach allowed us to minimise risk and to upgrade during business hours without any interruption. We used the blue-green approach again when we upgraded from 2.4 to 5. With Elasticsearch 6 major upgrades became much easier, because a full cluster restart is not required anymore. We could simply upgrade from version 5 to 6 one node at a time using our Cluster Control Tool.
Fewer Shards for More Performance
We benefited a lot from upgrading to Elasticsearch 2 and later to version 5 in terms of stability and efficiency. Being able to reduce the number of nodes from 60 to 30 nodes was a big costsaver and made operations easier. However, we still occasionally suffered from latency spikes which could cause a sub-optimal user experience in our app. We used the Elastic Stack monitoring feature and our own metrics to get to the bottom of the problem. Performance tests showed that we were facing two problems: Aggregations over a large dataset hit a bottleneck on I/O bandwidth and searches that contain a lot of terms were causing spikes in Garbage Collection and CPU.
To solve the performance problems we investigated a recommendation that Elastic Support made to us early on: Reducing the number of shards. If you store time based events, be it news articles or log events, it is a common pattern to use date based indices. We started of with daily indices so that for example all news articles that have been published on the 29th of April 2018 would be stored in an index named articles-20180429. This means that, when you search over one year of data and you are using the default of 5 shards per index, Elasticsearch would have to search over 1825 shards. We learned that searching over a lot of shards is quite expensive. Indeed, up to some point, the cost for searching a fixed number of documents went up linearly with the number of shards involved. How to split up data across indices and shards most efficiently depends on many factors.
For our use case it made sense to make shards as big as possible. We reduced the number of shards per year from 1825 to 60 reducing query cost and latency on average by 90%. While we were experimenting with bigger shards, we were also looking at different AWS EC2 instance types. Amazon's new storage-optimised i3 instance type with high I/O throughput, high IOPS and high network throughput, turned out to be the last missing piece to solve our performance problems. As a matter of fact, i3's I/O performance is able to support bigger shards and allows us to aggregate over long time spans of data, without causing any performance issues.
Conclusion
Elasticsearch is incredible scalable, very reliable and constantly evolving. To get the most out of it, learning how it fits your use case and staying on top the latest improvements is key. Elastic's support offer great advice to guide you on your journey. Automating processes for maintaining our cluster, learning to interpret the right metrics and constant experimentation enabled us to fulfill our needs.
Now, with reducing the number shards and switching to machines with high I/O performance, we not only wiped out all performance bottlenecks, we could also cut the number of data nodes and costs by half another time. Back to 15 nodes, like in 2015.
Jo Draeger (@joachimdraeger) is a Lead Software Engineer at Signal Media (@SignalHQ) currently developing full-stack on Signal's products. When he joined Signal he was terraforming AWS cloud infrastructure and evolved the core Elasticsearch cluster. Jo is a speaker at Elastic London User Group meetups and is a contributor to Elasticsearch's snapshot repository code.