El recorrido de Elastic para desarrollar Elastic Cloud Serverless
Arquitectura sin estado que escala automáticamente sin importar tus necesidades de datos, uso y rendimiento


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
¿Cómo transformas un sistema con estado y de rendimiento crítico, como Elasticsearch, en uno sin servidor?
En Elastic, reimaginamos todo, desde el almacenamiento hasta la orquestación, para construir una plataforma verdaderamente sin servidores en la que los clientes puedan confiar.
Elastic Cloud Serverless es una plataforma nativa del cloud completamente gestionada, diseñada para llevar el poder de Elastic Stack a los desarrolladores sin la carga operativa. En esta publicación de blog, te explicaremos por qué la construimos, cómo abordamos la arquitectura y qué aprendimos en el camino.
¿Por qué sin servidor?
Con el correr de los años, las expectativas de los clientes han cambiado radicalmente. Los usuarios ya no quieren preocuparse por las complejidades de la gestión de la infraestructura, como el tamaño, el monitoreo y el escalado. En su lugar, buscan una experiencia fluida que les permita centrarse únicamente en sus cargas de trabajo. Esta demanda en evolución nos llevó a desarrollar una solución que reduce la sobrecarga operativa, ofrece una experiencia SaaS sin inconvenientes e introduce un modelo de precios por uso. Al eliminar la necesidad de que los clientes provisionen y mantengan los recursos de forma manual, creamos una plataforma que escala dinámicamente según la demanda mientras optimiza la eficiencia.
Hitos
Elastic Cloud Serverless se está expandiendo rápidamente para satisfacer la demanda de los clientes; logró estar disponible para el público en general (GA) en AWS en diciembre de 2024, GCP en abril de 2025, y Azure en junio de 2025. Desde entonces nos expandimos a cuatro regiones en AWS, tres regiones en GCP y una región en Azure, y tenemos regiones adicionales planificadas en los tres proveedores de servicios en el cloud (CSP).
Replantear la arquitectura: de un sistema con estado a uno sin estado
Elastic Cloud Hosted (ECH) se diseñó originalmente como un sistema con estado, que dependía del almacenamiento local basado en NVMe o de discos gestionados para garantizar la durabilidad de los datos. A medida que Elastic Cloud se expandía globalmente, vimos la oportunidad de evolucionar nuestra arquitectura para mejorar la eficiencia operativa y el crecimiento a largo plazo. Nuestro enfoque hospedado para gestionar el almacenamiento persistente en entornos distribuidos fue efectivo, pero introdujo complejidades operativas adicionales en cuanto a la sustitución de nodos, el mantenimiento, el aseguramiento de la redundancia entre zonas de disponibilidad y el escalado de cargas de trabajo intensivas en cómputo, como la indexación y la búsqueda.
Decidimos evolucionar nuestra arquitectura del sistema al adoptar un enfoque sin estado. El cambio clave fue trasladar el almacenamiento persistente de los nodos de computación a los almacenes de objetos nativos del cloud. Esto proporcionó múltiples beneficios: reducir la sobrecarga de infraestructura necesaria para indexar, permitir la separación de búsqueda/índice, eliminar la necesidad de replicación y mejorar la durabilidad de los datos al aprovechar los mecanismos de redundancia integrados de los CSP.
La transición al almacenamiento de objetos
Uno de los principales cambios en nuestra arquitectura fue usar el almacenamiento de objetos nativo del cloud como el almacén de datos principal. ECH fue diseñado para almacenar datos en SSD NVMe locales o en discos SSD gestionados. Sin embargo, a medida que crecían los volúmenes de datos, también crecían los desafíos de escalar el almacenamiento de manera eficiente. Luego introdujimos snapshots buscables en ECH, lo que nos permitió buscar datos directamente desde los almacenes de objetos, y reducir significativamente los costos de almacenamiento, pero necesitábamos ir más allá.
Un desafío clave era determinar si los almacenes de objetos podían manejar cargas de trabajo de alta ingesta mientras mantenían el nivel de rendimiento que esperan los usuarios de Elasticsearch. Mediante pruebas rigurosas e implementación, confirmamos que el almacenamiento de objetos podía cumplir con las exigencias de indexación a gran escala. El cambio al almacenamiento de objetos eliminó la necesidad de indexar la replicación, redujo los requisitos de infraestructura y proporcionó una mayor durabilidad al replicar datos en zonas de disponibilidad, lo que garantizó alta disponibilidad y resiliencia.
El siguiente diagrama ilustra la nueva arquitectura “sin estado” en comparación con la arquitectura “ECH” existente:

Optimizar la eficiencia del almacenamiento de objetos
Aunque el cambio al almacenamiento de objetos aportó beneficios operativos y de durabilidad, introdujo un nuevo desafío: los costos de la API del almacén de objetos. Las escrituras en Elasticsearch, en especial, las actualizaciones de translog, se traducen directamente en llamadas a la API del almacén de objetos, que pueden escalar de forma rápida e imprevisible, en especial bajo cargas de trabajo de alta ingesta o alta actualización.
Para abordar esto, implementamos un mecanismo de almacenamiento en búfer de translog por nodo que agrupa las escrituras antes de enviarlas al almacén de objetos, lo que reduce significativamente la amplificación de las escrituras. También desacoplamos las actualizaciones de las escrituras en el almacén de objetos, enviamos los segmentos actualizados directamente a los nodos de búsqueda mientras se aplaza la persistencia en el almacén de objetos. Este refinamiento arquitectónico redujo las llamadas a la API del almacén de objetos relacionadas con la actualización en dos órdenes de magnitud, sin comprometer la durabilidad de los datos. Para obtener más detalles, consulta esta publicación de blog.
Elegir Kubernetes para la orquestación
ECH utiliza un orquestador de contenedores desarrollado internamente que también da poder a Elastic Cloud Enterprise (ECE). Dado que el desarrollo de ECE se inició antes de que existiera Kubernetes (K8s), nos enfrentamos a la disyuntiva de extender ECE para soportar la arquitectura sin servidor o de utilizar K8s para este fin. Ante la rápida adopción de K8s en toda la industria y el creciente ecosistema que lo rodea, optamos por implementar servicios de Kubernetes gestionados a través de los diversos CSP en Elastic Cloud Serverless, en los casos en que se alineen con nuestros objetivos operativos y de escalabilidad.
Al adoptar Kubernetes, reducimos la complejidad operativa, estandarizamos las API para mejorar la escalabilidad y posicionamos Elastic Cloud para la innovación a largo plazo. Kubernetes nos permitió enfocarnos en características de mayor valor en lugar de reinventar la orquestación de contenedores.
Kubernetes gestionado por CSP vs. Kubernetes autogestionado
Durante la transición a Kubernetes, nos enfrentamos a la decisión de gestionar nosotros mismos los clusters de Kubernetes o usar los servicios gestionados de Kubernetes proporcionados por los CSP. Las implementaciones de Kubernetes varían significativamente entre los CSP, pero para acelerar nuestros plazos de despliegue y reducir la sobrecarga operativa, optamos por los servicios de Kubernetes gestionados por CSP en AWS, GCP y Azure. Este enfoque nos permitió centrarnos en crear aplicaciones y adoptar las mejores prácticas del sector, en lugar de ocuparnos de las complejidades de la gestión de clusters de Kubernetes.
Nuestros requisitos clave incluían la capacidad de provisionar y gestionar clusters de Kubernetes de forma coherente en varios CSP; una API independiente del cloud para gestionar el cómputo, el almacenamiento y las bases de datos; y operaciones simplificadas que fueran rentables. Además, al elegir Kubernetes gestionado por CSP, pudimos contribuir a proyectos open source como Crossplane, lo que mejoró el ecosistema general de Kubernetes al tiempo que nos beneficiábamos de sus capacidades en evolución.
Desafíos de la creación de redes y la elección de Cilium
Operar Kubernetes a escala con decenas de miles de pods por cluster de Kubernetes requiere una solución de red que sea independiente del cloud, que ofrezca un alto rendimiento con una latencia mínima y que admita políticas de seguridad avanzadas. Seleccionamos Cilium, una solución moderna basada en eBPF, para abordar estos requisitos. Inicialmente, nuestro objetivo era implementar una solución Cilium autogestionada uniforme en todos los CSP. Sin embargo, las diferencias en las implementaciones en el cloud nos llevaron a adoptar un enfoque híbrido, utilizando soluciones Cilium nativas de CSP donde estén disponibles mientras mantenemos un despliegue autogestionado en AWS. Esta flexibilidad aseguró que pudiéramos satisfacer nuestras necesidades de rendimiento y seguridad sin una complejidad innecesaria.
Tráfico entrante
Para la entrada, elegimos adaptarnos y continuar usando nuestro proxy existente y puesto a prueba de ECH. La evaluación no era simplemente si podíamos reemplazar el proxy con una solución estándar, sino si debíamos hacerlo.
Aunque un proxy reverso estándar proporcionaría una funcionalidad básica, carecería de las características diferenciadoras que el proxy ECH ya maneja. Habríamos necesitado crear extensiones para los filtros de tráfico de entrada, soporte para AWS PrivateLink y Google Cloud Private Service Connect, y terminación TLS compatible con FIPS. El proxy existente ya ha pasado todas las auditorías de cumplimiento y pruebas de penetración pertinentes.
Comenzar con una nueva solución habría requerido un esfuerzo significativo sin ningún valor adicional para el cliente. Adaptar nuestro proxy para Kubernetes implicó principalmente actualizar la forma en que distribuimos el conocimiento de los endpoints de servicio, al dejar intacta la funcionalidad central y bien probada. Este enfoque proporciona varias ventajas:
Garantiza que el comportamiento visible para el cliente se mantenga consistente entre ECH y Kubernetes.
Los equipos pueden trabajar más eficientemente con una base de código familiar y bien comprendida, especialmente al implementar nuevas características que requerirían scripts o extensiones en una solución estándar.
Podemos mejorar tanto nuestras plataformas de ECH como de Kubernetes con una única base de código; por lo tanto, las mejoras en un entorno se traducen en mejoras en el otro.
Los equipos de soporte pueden aprovechar sus conocimientos existentes, lo que reduce la curva de aprendizaje para la nueva plataforma.
Capa de aprovisionamiento de Kubernetes
Después de elegir Kubernetes para Elastic Cloud Serverless, seleccionamos Crossplane como la herramienta de gestión de infraestructura. Crossplane es un proyecto open source que extiende la API de Kubernetes para permitir el aprovisionamiento y la gestión de infraestructura y servicios en el cloud mediante herramientas y prácticas nativas de Kubernetes. Permite a los usuarios provisionar, orquestar y gestionar recursos en la cloud a través de múltiples CSP desde dentro de un cluster de Kubernetes. Esto se logra al aprovechar las definiciones de recursos personalizados (CRD) para definir recursos en el cloud y controladores para conciliar el estado deseado especificado en los manifiestos de Kubernetes con el estado real de los recursos en el cloud a través de múltiples CSP. Al utilizar la configuración declarativa y los mecanismos de control de Kubernetes, proporciona una manera consistente y escalable de gestionar la infraestructura como código.
Crossplane permite la gestión y el aprovisionamiento de la infraestructura utilizando las mismas herramientas y métodos utilizados para el despliegue de servicios. Esto implica aprovechar los recursos de Kubernetes, una arquitectura GitOps consistente y herramientas de observabilidad unificadas. Además, los desarrolladores pueden establecer un entorno de desarrollo completo basado en Kubernetes, lo que incluye su infraestructura periférica, que refleja los entornos de producción. Esto se logra simplemente al crear un recurso de Kubernetes, ya que ambos entornos se generan a partir del mismo código subyacente.
Gestión de infraestructura
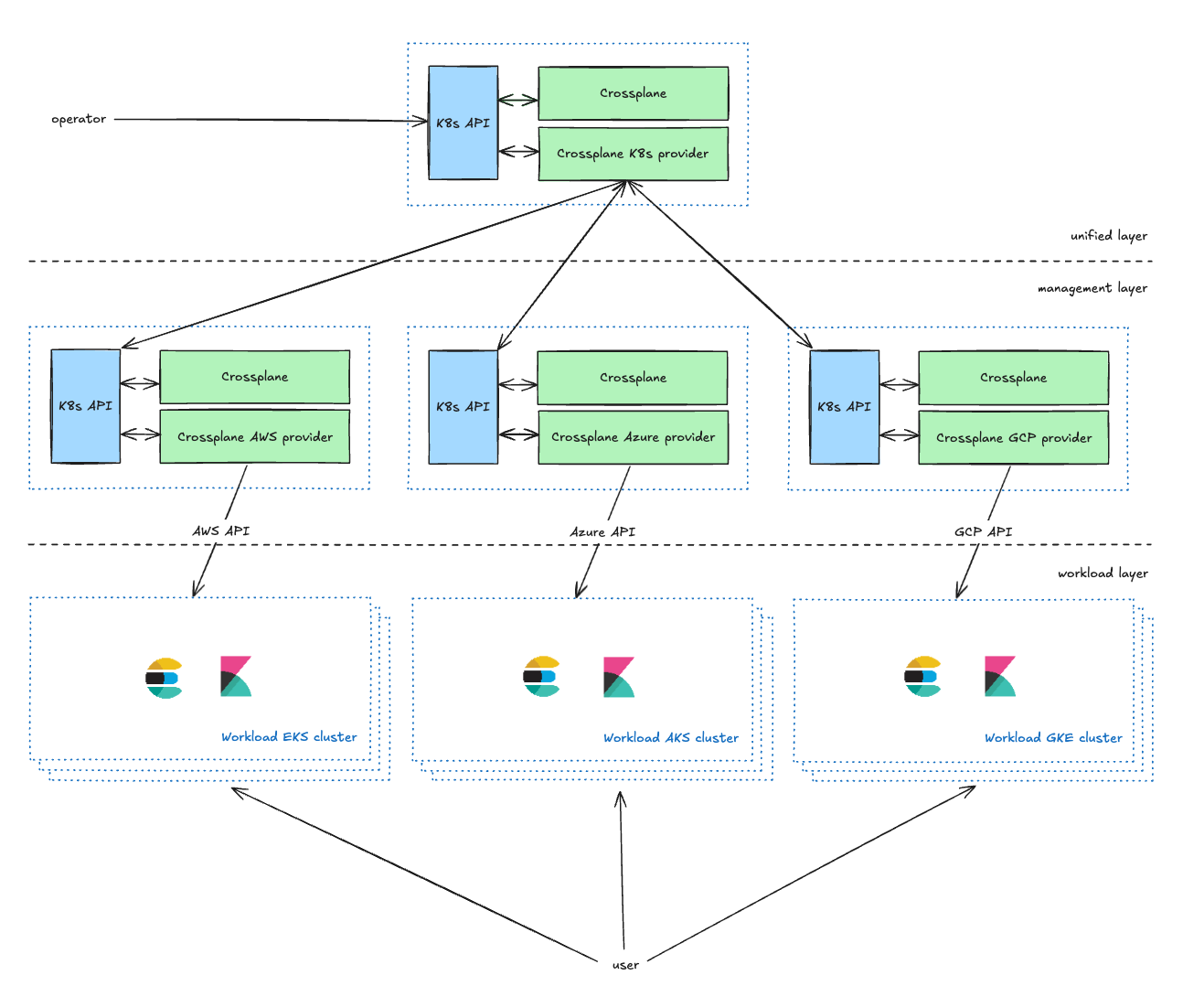
La capa unificada es la capa de administración orientada al operador, que proporciona CRD de Kubernetes para que los propietarios de servicios gestionen sus clusters de Kubernetes. Pueden definir parámetros, incluidos el CSP, la región y el tipo (que se explica en la siguiente sección). Enriquece las solicitudes de los operadores y las reenvía a la capa de gestión.
La capa de gestión actúa como un proxy entre la capa unificada y las API de CSP, ya que transforma las solicitudes de la capa unificada en solicitudes de recursos de CSP y reporta el estado a la capa unificada.
En nuestra configuración actual, mantenemos dos clusters de Kubernetes de gestión para cada CSP dentro de cada entorno. Este enfoque de doble cluster sirve principalmente para dos propósitos clave. En primer lugar, nos permite abordar eficazmente los posibles problemas de escalabilidad que puedan surgir con Crossplane. En segundo lugar, y más importante, nos permite usar uno de los clusters como entorno canary. Esta estrategia de despliegue canary facilita un despliegue por fases de nuestros cambios, comenzando por un subconjunto más pequeño y controlado de cada entorno, lo que minimiza el riesgo.
La capa de carga de trabajo contiene todos los clusters de carga de trabajo de Kubernetes que ejecutan aplicaciones con las que interactúan los usuarios (Elasticsearch, Kibana, MIS, etc.).
Gestión de la capacidad en el cloud: evitar errores de “falta de capacidad”
Una suposición común es que la capacidad del cloud es infinita, pero en realidad, los CSP imponen restricciones que pueden llevar a “errores de falta de capacidad”. Si un tipo de instancia no está disponible, tenemos que reintentarlo continuamente o cambiar a un tipo de instancia alternativo.
Para mitigar esto en Elastic Cloud Serverless, implementamos pools de capacidad basados en prioridades, lo que permite que las cargas de trabajo migren para usar nuevos/otros pools de capacidad cuando sea necesario. Además, invertimos en planificación proactiva de capacidad, lo que reserva recursos informáticos antes de que se produzcan picos de demanda. Estos mecanismos garantizan una alta disponibilidad al tiempo que optimizan la utilización de los recursos.
Estar actualizado
Las actualizaciones de clusters de Kubernetes son lentas. Para optimizar esto, utilizamos un proceso completamente automatizado de principio a fin, que requiere intervención manual solo para problemas que no se pueden resolver automáticamente. Una vez que se completan las pruebas internas y se aprueba una nueva versión de Kubernetes, la configuramos de manera centralizada. Un sistema automatizado luego inicia la actualización del plano de control para cada cluster, con concurrencia controlada y un orden específico. Posteriormente, los controladores personalizados de Kubernetes realizan despliegues azul-verde para actualizar los pools de nodos. Aunque los pods de los clientes migran a diferentes nodos de K8s durante este proceso, la disponibilidad y el rendimiento del proyecto no se ven afectados.
Resiliencia de la arquitectura
Utilizamos una arquitectura basada en celdas, que nos permite ofrecer servicios escalables y resilientes. Cada cluster de Kubernetes, junto con su infraestructura periférica, se despliega en una cuenta de CSP separada para permitir un escalado adecuado sin verse afectado por los límites del CSP y para proporcionar la máxima seguridad y aislamiento. Las cargas de trabajo individuales, que cada una es una célula separada, gestionan aspectos específicos del sistema. Estas celdas operan de manera independiente, lo que permite un escalado y una gestión aislados. Este diseño modular minimiza el alcance de las fallas y facilita el escalado selectivo, lo que evita impactos en todo el sistema. Para minimizar aún más el impacto potencial de los problemas, utilizamos despliegues canary tanto para nuestras aplicaciones como para la infraestructura subyacente.
Plano de control vs. plano de datos: el modelo push
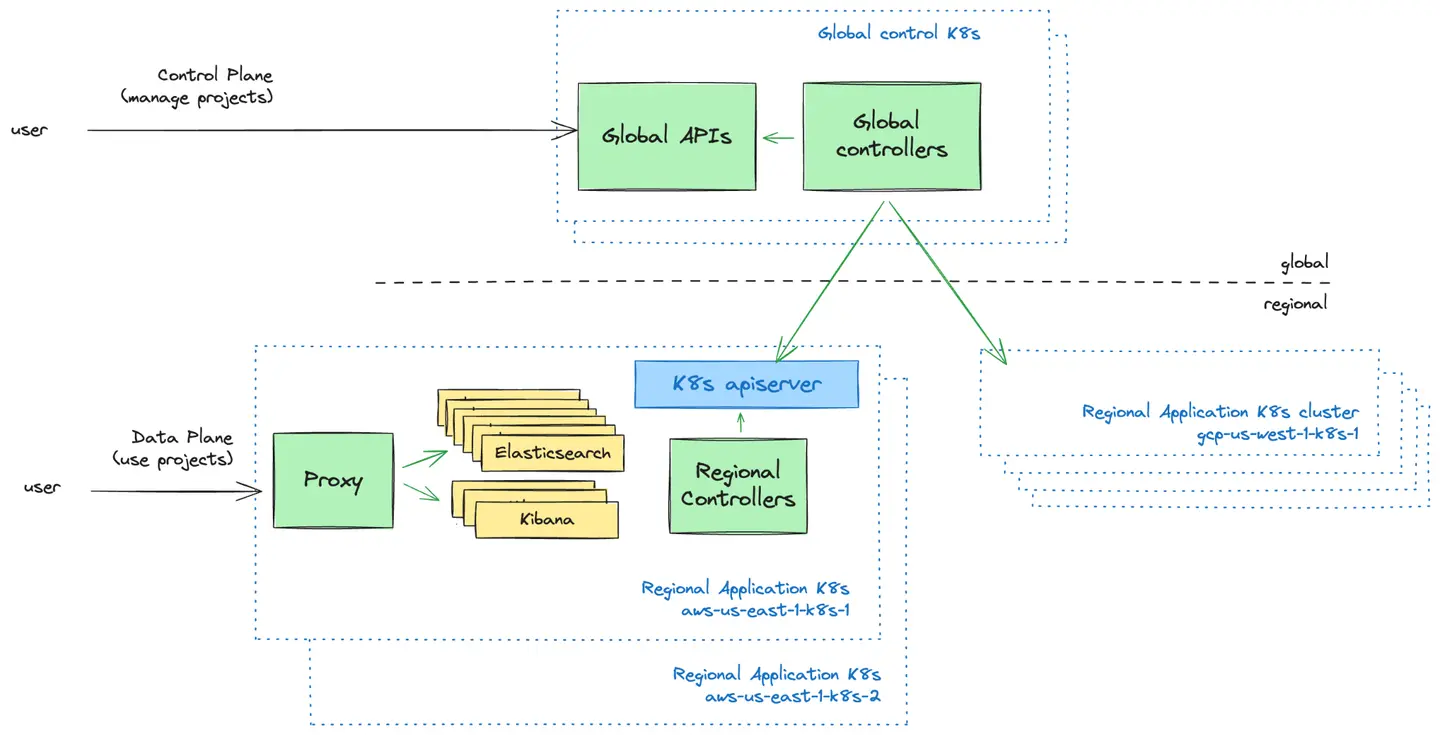
El plano de control es la capa de administración orientada al usuario. Proporcionamos UI y API para que los usuarios gestionen sus proyectos de Elastic Cloud Serverless. Aquí es donde pueden crear nuevos proyectos, controlar quién tiene acceso a tus proyectos y obtener una visión general de sus proyectos.
El plano de datos es la capa de infraestructura que impulsa los proyectos de Elastic Cloud Serverless y con la que interactúan cuando quieren usar sus proyectos.
Una decisión de diseño fundamental a la que nos enfrentamos fue cómo el plano de control global debería comunicarse con los clusters de Kubernetes en el plano de datos. Exploramos dos modelos:
Modelo push: el plano de control envía de forma proactiva las configuraciones a clusters regionales de Kubernetes.
Modelo pull: los clusters regionales de Kubernetes obtienen periódicamente configuraciones del plano de control.
Tras evaluar ambos enfoques, adoptamos el Modelo push debido a su simplicidad, flujo de datos unidireccional y capacidad para operar los clusters de Kubernetes independientemente del plano de control durante las fallas. Este modelo nos permitió mantener una lógica de programación sencilla, lo que reduce al mismo tiempo la sobrecarga operativa y las complejidades de la recuperación ante fallas.
Autoescalado: más allá del escalado horizontal y vertical
Para ofrecer una experiencia verdaderamente sin servidor, necesitábamos un mecanismo de autoescalado inteligente que ajustara de forma dinámica los recursos según las demandas de la carga de trabajo. Nuestro recorrido comenzó con un escalado horizontal básico, pero pronto nos dimos cuenta de que los distintos servicios tenían necesidades de escalado únicas. Algunos requerían recursos de cómputo adicionales, mientras que otros exigían una mayor asignación de memoria.
Evolucionamos nuestro enfoque al desarrollar controladores de autoescalado personalizados que analizan en tiempo real las métricas específicas de la carga de trabajo, lo que permite un escalado dinámico que es tanto sensible como eficiente en recursos. Como consecuencia, podemos escalar sin problemas tanto las operaciones de indexación como las del nivel de búsqueda de Elasticsearch sin sobreprovisionar Elasticsearch. Esta estrategia permite el uso de autoescalado de pods multidimensionales, lo que permite que las cargas de trabajo se escalen horizontal y verticalmente en función de la CPU, la memoria y las métricas personalizadas generadas por la carga de trabajo.
Para nuestras cargas de trabajo de Elasticsearch, utilizamos una API de Elasticsearch específica para entornos sin servidor que devuelve ciertas métricas clave sobre el cluster. Así es como funciona: quienes hacen las recomendaciones sugieren los recursos de cómputo (réplicas, memoria y CPU) y de almacenamiento necesarios para un nivel determinado. Luego, quienes se encargan del mapping convierten estas recomendaciones en configuraciones concretas de cómputo y almacenamiento aplicables a los contenedores. Para prevenir rápidas fluctuaciones en el escalado, los estabilizadores filtran estas recomendaciones. Luego entran en juego los limitadores, que aplican restricciones de recursos mínimas y máximas. La salida del limitador se utiliza para ajustar el despliegue de Kubernetes tras considerar algunas políticas de restricción opcionales.
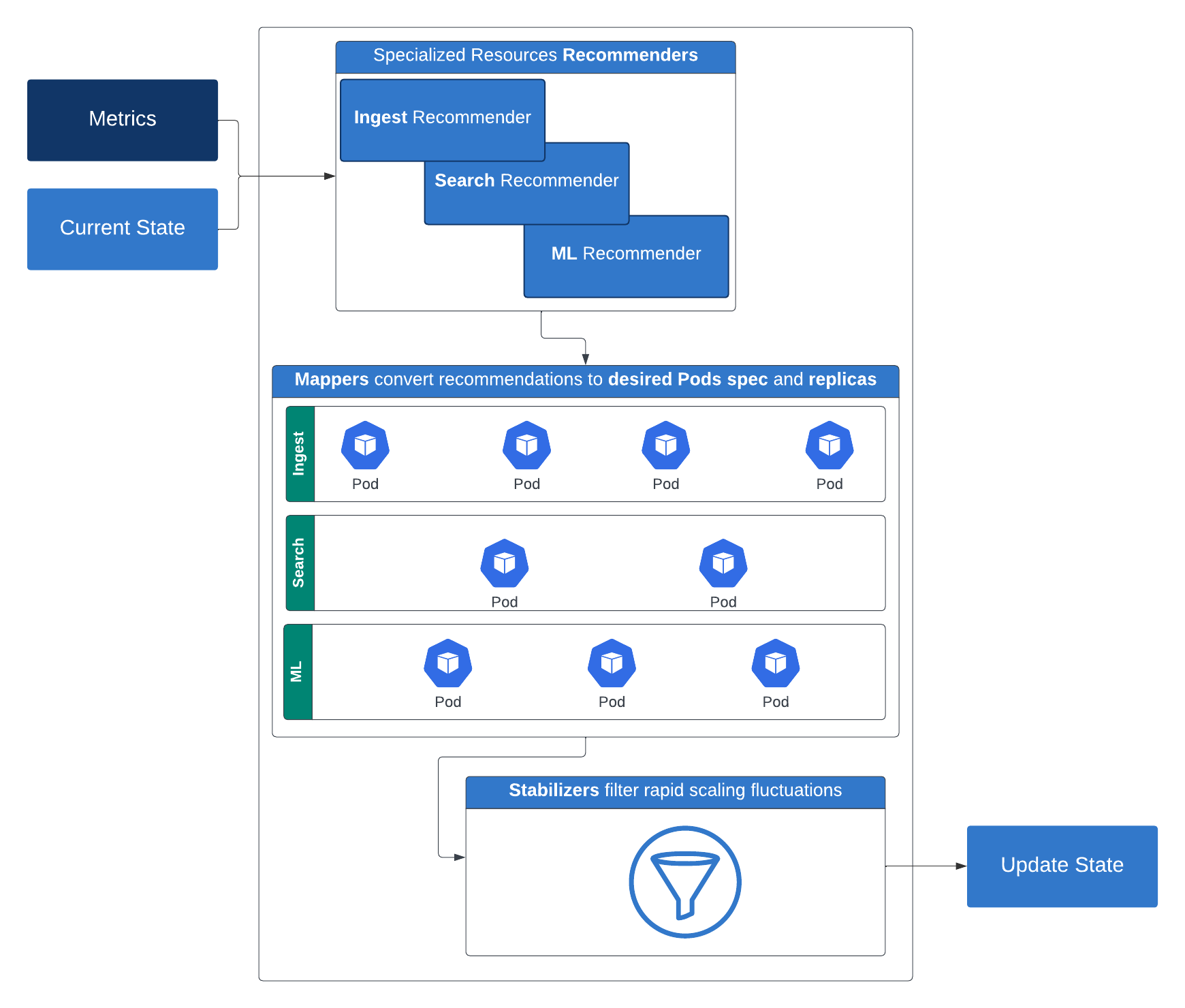
Esta estrategia de escalado inteligente por capas garantiza el rendimiento y la eficiencia en diversas cargas de trabajo, y es un gran paso hacia una plataforma verdaderamente sin servidor.
Elastic Cloud Serverless incorpora capacidades de autoescalado matizadas adaptadas al nivel de búsqueda, aprovechando entradas como ventanas de datos mejoradas, configuraciones de poder de búsqueda y métricas de carga de búsqueda (lo que incluye la carga del thread pool y la carga de la cola). Estas señales trabajan juntas para definir configuraciones base y activar decisiones de escalado dinámico basadas en los patrones de uso de búsqueda del cliente. Para profundizar en el autoescalado del nivel de búsqueda, lee esta publicación de blog. Para aprender más sobre cómo funciona el autoescalado de niveles de indexación, consulta esta publicación de blog.
Desarrollar un modelo de precios flexible
Un principio clave de la computación sin servidor es alinear los costos con el uso real. Queríamos un modelo de precios que fuese simple, flexible y transparente. Después de evaluar varios enfoques, diseñamos un modelo que equilibra diferentes cargas de trabajo en nuestras soluciones principales:
Observability y Security: se cobra en función de la ingesta y retención de datos, con precios escalonados.
Elasticsearch (Search): los precios se basan en unidades de cómputo virtuales, lo que incluye la ingesta, la búsqueda, el machine learning y la retención de datos.
Este enfoque proporciona a los clientes precios de pago por uso, lo que ofrece mayor flexibilidad y previsibilidad de costos.
Para implementar este modelo de precios (que pasó por muchas iteraciones durante la fase de desarrollo), sabíamos que necesitábamos una arquitectura con escalabilidad y flexibilidad. Finalmente, construimos un pipeline que admite un modelo de propiedad distribuida, en donde diferentes equipos son responsables de distintos componentes del proceso de extremo a extremo. A continuación, describimos los dos segmentos principales de este pipeline: la recopilación de uso medido a través del pipeline de uso y los cálculos de facturación a través del pipeline de facturación.
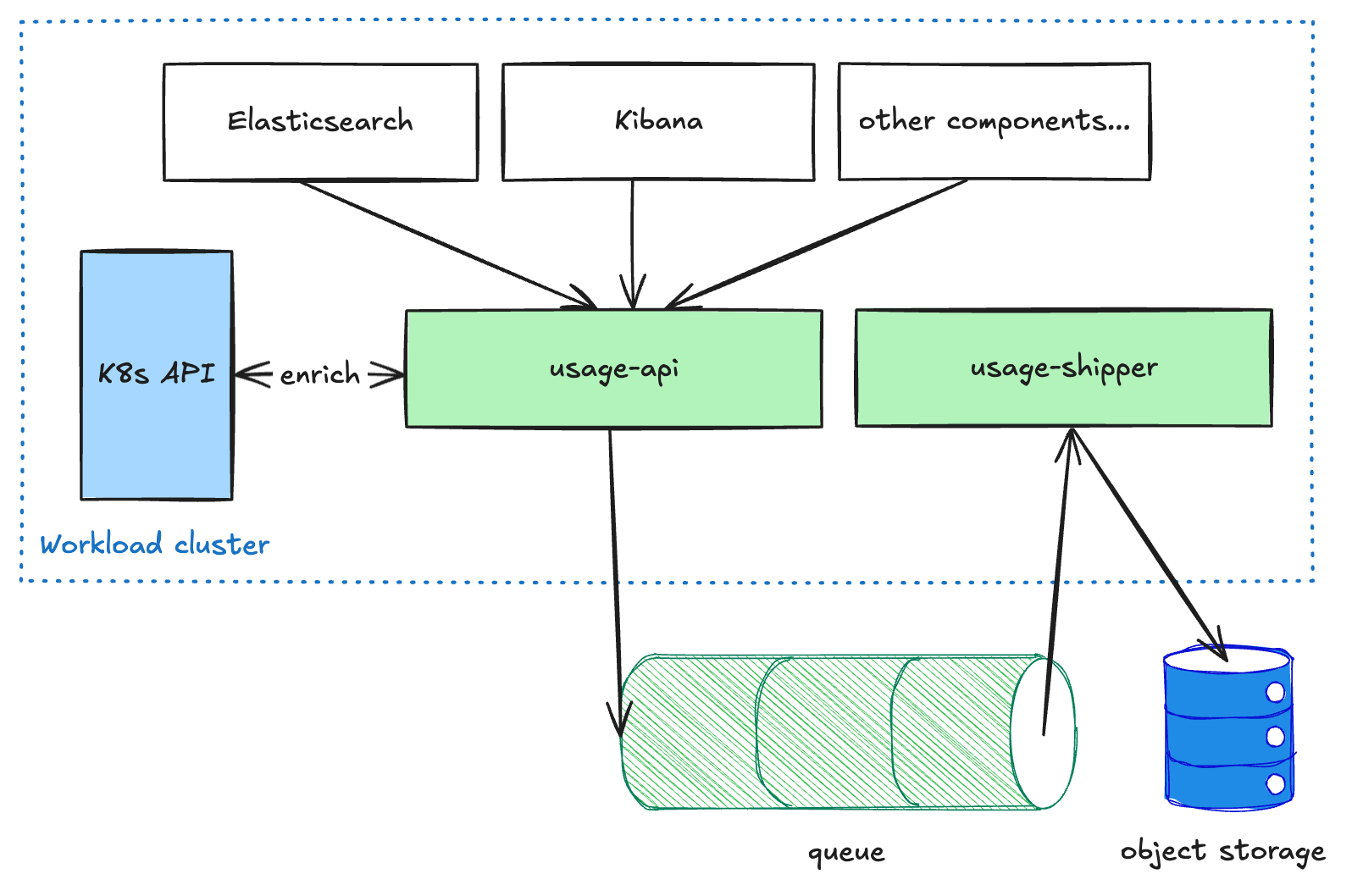
Pipeline de uso
Los componentes orientados al usuario, como Elasticsearch y Kibana, envían datos de uso medido al servicio usage-api, que se ejecuta en cada cluster de carga de trabajo. Este servicio realiza algún enriquecimiento en los datos y luego los coloca en una cola. El servicio usage-shipper luego extrae estos datos de la cola y los reenvía al almacenamiento de objetos. Esta arquitectura desacoplada es necesaria para que el pipeline sea resistente al enviar datos entre regiones y CSP, ya que priorizamos la entrega sobre la latencia. Una vez que los datos llegan al almacenamiento de objetos, están disponibles para otros procesos de solo lectura para posteriores transformaciones o agregaciones (por ejemplo, para facturación o analíticas).
Pipeline de facturación
Una vez que los registros de uso se depositan en el almacenamiento de objetos, el pipeline de facturación recoge los datos y los convierte en cantidades de ECU (unidades de consumo de Elastic, nuestra unidad de facturación independiente de la moneda) que facturamos. El proceso básico se ve de la siguiente manera:
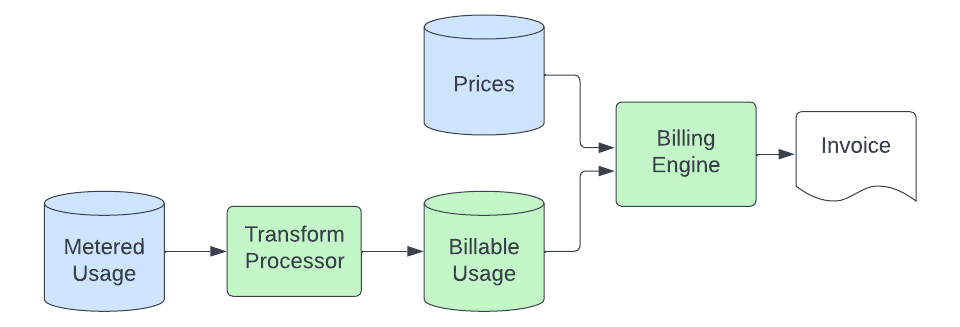
Un proceso de transformación consume los registros de uso medidos del almacenamiento de objetos y los convierte en registros que se pueden facturar. Este proceso implica la conversión de unidades (la aplicación de uso medido puede medir el almacenamiento en bytes, pero podemos facturar en GB), el filtrado de las fuentes de uso que no facturamos, el mapeo del registro a un producto específico (esto implica el análisis de metadatos en los registros de uso para vincular el uso a un producto específico de una solución que tiene un precio único), y el envío de estos datos a un cluster de Elasticsearch que es consultado por nuestro motor de facturación. El propósito de esta etapa de transformación es proporcionar un lugar centralizado donde reside la lógica para convertir los registros de uso medidos genéricos en cantidades específicas del producto que están listas para ser valoradas. Esto nos permite mantener esta lógica especializada fuera de las aplicaciones medidas y del motor de facturación, los cuales queremos que sigan siendo simples e independientes del producto.
A continuación, el motor de facturación establece un precio para estos registros de uso facturables, que ahora contienen un identificador que se mapea a un producto en nuestra base de datos de precios. Como mínimo, este proceso implica sumar el uso durante un período determinado y multiplicar la cantidad por el precio del producto para calcular las ECU. En algunos casos, además, debe segmentar el uso en niveles basados en el uso acumulado a lo largo del mes y asignarlos a niveles de productos con precios individuales. Para tolerar demoras en el proceso de origen sin perder registros, el uso se factura en el momento en que llega a la base de datos de uso facturable, pero su precio se determina según la fecha en que ocurrió (para garantizar que no se aplique un precio incorrecto a un uso con llegada “tardía”). Así, nuestro proceso de facturación adquiere la habilidad de corregirse automáticamente.
Por último, una vez calculadas las ECU, evaluamos los costos adicionales (como el soporte) y luego los incorporamos a los cálculos de facturación, que finalmente dan lugar a una factura (que enviamos nosotros o uno de nuestros socios del marketplace de cloud). Esta parte final del proceso no es nueva ni exclusiva de Serverless y es gestionada por los mismos sistemas que facturan nuestro producto hospedado.
Conclusiones
Desarrollar una plataforma de infraestructura que ofrezca una funcionalidad similar en varios CSP es un desafío complejo. Equilibrar la confiabilidad, escalabilidad y rentabilidad requiere iteración continua y concesiones. Las implementaciones de Kubernetes varían significativamente entre los proveedores de servicios en el cloud, y garantizar una experiencia consistente en todos ellos requiere pruebas y personalización exhaustivas.
Además, adoptar una arquitectura sin servidor no es solo una transformación técnica, sino también un cambio cultural. Requiere pasar de la solución de problemas reactiva a la optimización proactiva del sistema y priorizar la automatización para minimizar la carga operativa. A lo largo de nuestro recorrido, hemos aprendido que desarrollar una plataforma sin servidor exitosa tiene tanto que ver con las decisiones arquitectónicas como con fomentar una mentalidad que adopte la innovación y mejora continuas.
Con la mirada en el futuro
El éxito en el mundo sin servidor depende de ofrecer una experiencia excepcional al cliente, optimizar proactivamente las operaciones y equilibrar continuamente la fiabilidad, la escalabilidad y la eficiencia de costos. De cara al futuro, nuestro enfoque sigue siendo desarrollar nuevas características para nuestros clientes en Elastic Cloud Serverless, al hacer que este sea el mejor lugar para ejecutar Elasticsearch para todos.
El futuro de la búsqueda, la seguridad y la observabilidad ya está aquí sin comprometer la velocidad, la escala ni el costo. Experimenta Elastic Cloud Serverless y Search AI Lake para desbloquear nuevas oportunidades con tus datos. Obtén más información sobre las posibilidades de la tecnología sin servidor o comienza tu prueba gratuita ahora.
El lanzamiento y el momento de cualquier característica o funcionalidad descrita en esta publicación quedan a exclusivo criterio de Elastic. Es posible que cualquier característica o funcionalidad que no esté disponible en este momento no se lance a tiempo o no se lance en absoluto.
En esta publicación del blog, es posible que hayamos usado o nos hayamos referido a herramientas de AI generativa de terceros, que son propiedad de sus respectivos propietarios y están gestionadas por ellos. Elastic no tiene ningún control sobre las herramientas de terceros y no tenemos ninguna responsabilidad por su contenido, operación o uso, ni por ninguna pérdida o daño que pueda surgir de tu uso de dichas herramientas. Ten cuidado al usar herramientas de AI con información personal, sensible o confidencial. Cualquier dato que envíes puede usarse para el entrenamiento de AI u otros fines. No se garantiza que la información que proporciones se mantenga segura o confidencial. Debes familiarizarte con las prácticas de privacidad y los términos de uso de cualquier herramienta de AI generativa antes de usarla.
Elastic, Elasticsearch y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en los Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos propietarios.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime