Cómo migrar de Elasticsearch autogestionado a Elastic Cloud en AWS
Vemos que cada vez más cargas de trabajo en las instalaciones se migran al cloud. Elasticsearch ya lleva varios años con nuestros usuarios y clientes gestionándolo, en general, por su cuenta en las instalaciones. Elasticsearch Service en Elastic Cloud (nuestro servicio de Elasticsearch que se ejecuta en Amazon Web Services [AWS], Google Cloud y Microsoft Azure en varias regiones diferentes) es la mejor forma de consumir el Elastic Stack y nuestras soluciones para búsqueda empresarial, observabilidad y seguridad.
Si buscas migrar desde Elasticsearch autogestionado, Elasticsearch Service se encarga de lo siguiente:
- Provisionar y gestionar la infraestructura subyacente
- Crear y gestionar clusters de Elasticsearch
- Aumentar y reducir la escala de los clusters
- Actualizaciones, parches y snapshots
Esto te da más tiempo para enfocar tu tiempo y esfuerzo en resolver otros desafíos.
En este blog, exploramos cómo migrar a Elasticsearch Service tomando un snapshot de tu cluster de Elasticsearch y restaurándolo en Elasticsearch Service.
Tomar un snapshot del cluster
Lo primero que debemos tener en cuenta al migrar de Elasticsearch autogestionado a Elasticsearch Service es qué Proveedor Cloud y región te gustaría usar. Esto depende en general de tus cargas de trabajo existentes desplegadas, la estrategia del cloud y un rango de otros factores.
Aquí repasaremos el proceso para Elasticsearch Service en AWS. Pronto haremos lo mismo para Google Cloud y Azure.
La forma más sencilla de migrar los datos del cluster de Elasticsearch a otro cluster es tomar un snapshot del cluster y luego usarlo para restaurarlos en el nuevo cluster de Elasticsearch Service.
Existen varias formas para tomar un snapshot de un cluster. La más sencilla es realizar una operación de snapshot excepcional.
Suponiendo que tu Elasticsearch ingesta datos de forma continua, la desventaja de la operación de snapshot excepcional es que hay un retraso y pérdida de datos entre el momento en que se toma el snapshot y cuando este se restaura en el cluster nuevo. A fin de minimizar esta demora, se recomienda crear una política de ciclo de vida de snapshots. Si tu cluster de Elasticsearch no ingesta datos de forma continua, como para un caso de uso de búsqueda, entonces un snapshot excepcional funcionará bien.
Antes de crear un snapshot de cluster local, debes configurar la cubeta de AWS S3 en la que se almacenará el snapshot de cluster local. Esta es la ubicación desde la cual el nuevo cluster de Elasticsearch Service que se ejecuta en AWS restaurará el estado del cluster.
Los pasos de alto nivel necesarios para hacer esto incluyen los siguientes:
- Configurar el almacenamiento en el cloud (en este caso, la cubeta de AWS S3)
- Configurar el repositorio de snapshots local
- Configurar tu política de snapshots
- Provisionar el cluster nuevo en Elasticsearch Service
- Configurar el repositorio de snapshots personalizado del cluster de Elasticsearch Service
- Restaurar el cluster de Elasticsearch Service desde un snapshot local
Configurar el almacenamiento en el cloud
- Crea una cubeta de S3. La cubeta de S3 debería estar en la misma región seleccionada para tu cluster de Elasticsearch Service:
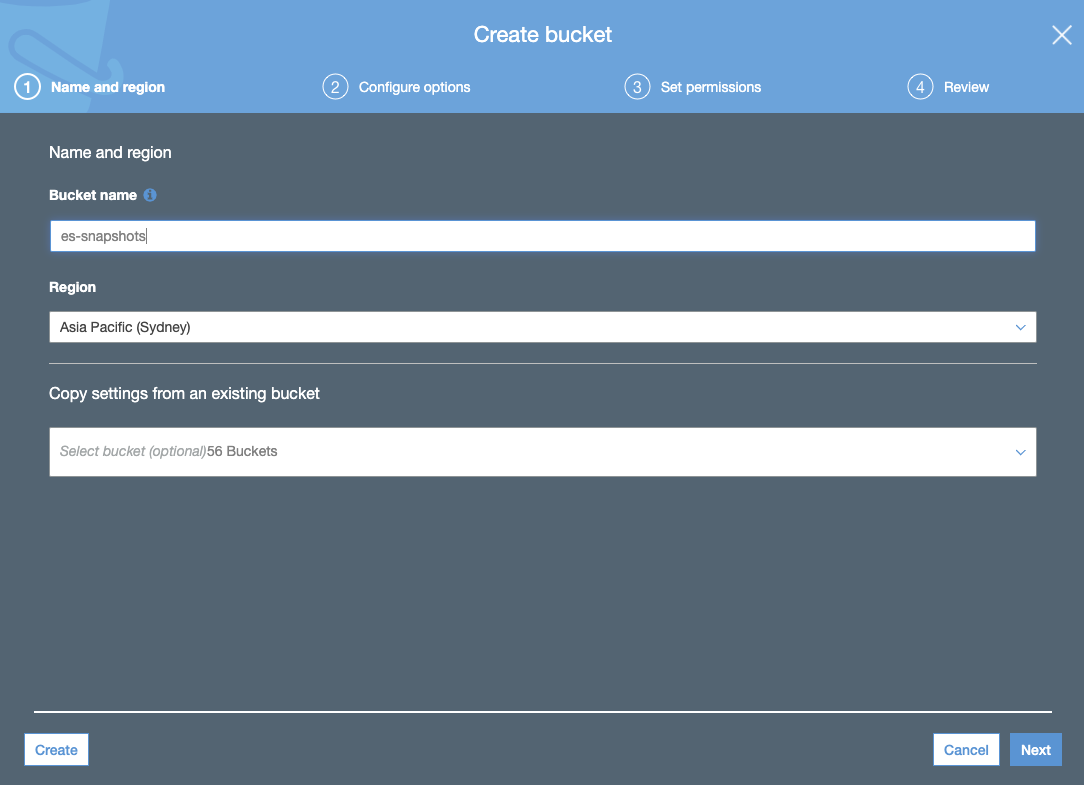
- Crea la política de cubeta de S3 a través de la pestaña JSON y agrega el JSON de política de cubeta de S3 (con tu nombre de cubeta):
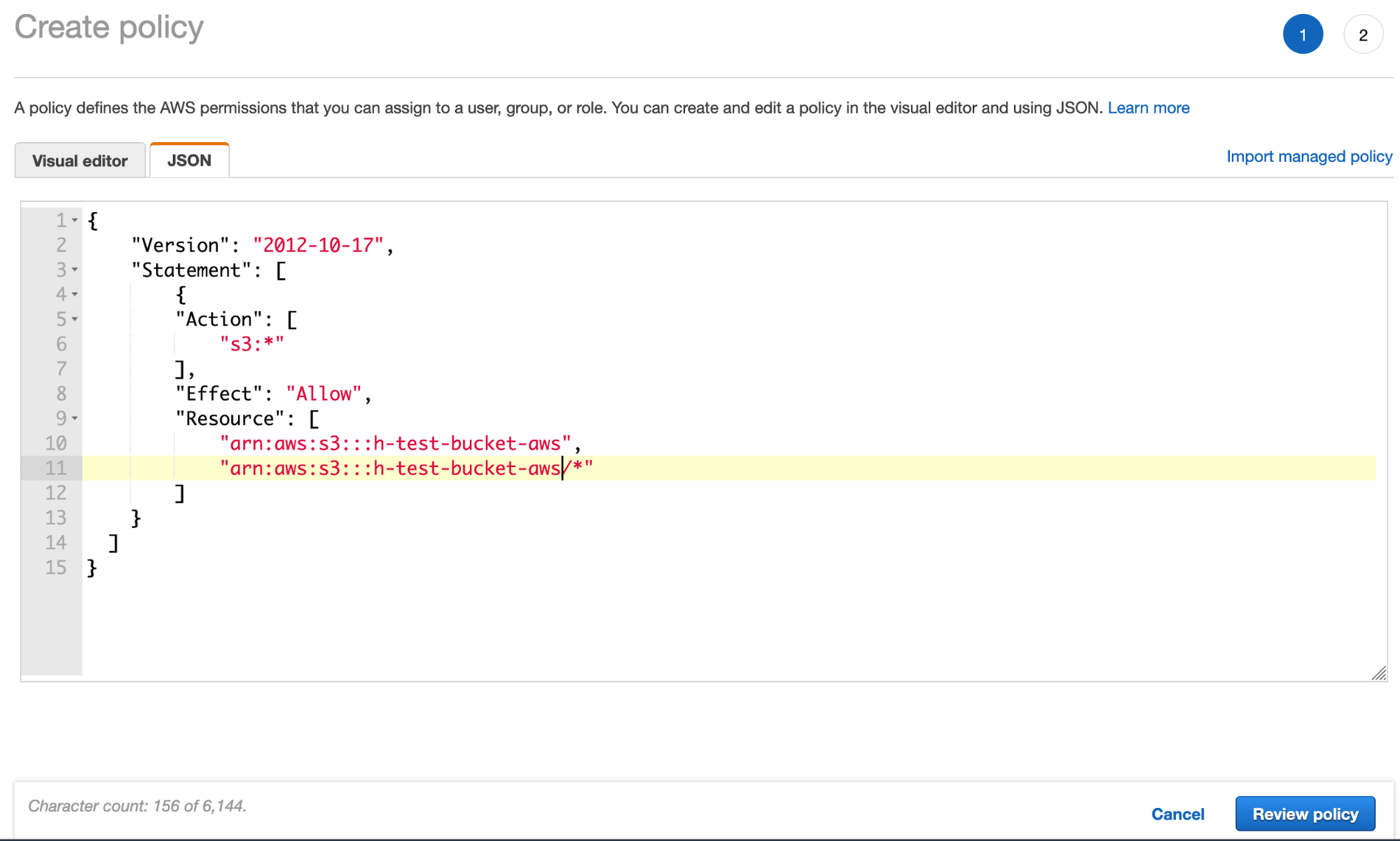
- Haz clic en Review policy (Revisar política) y asigna un nombre a la política:
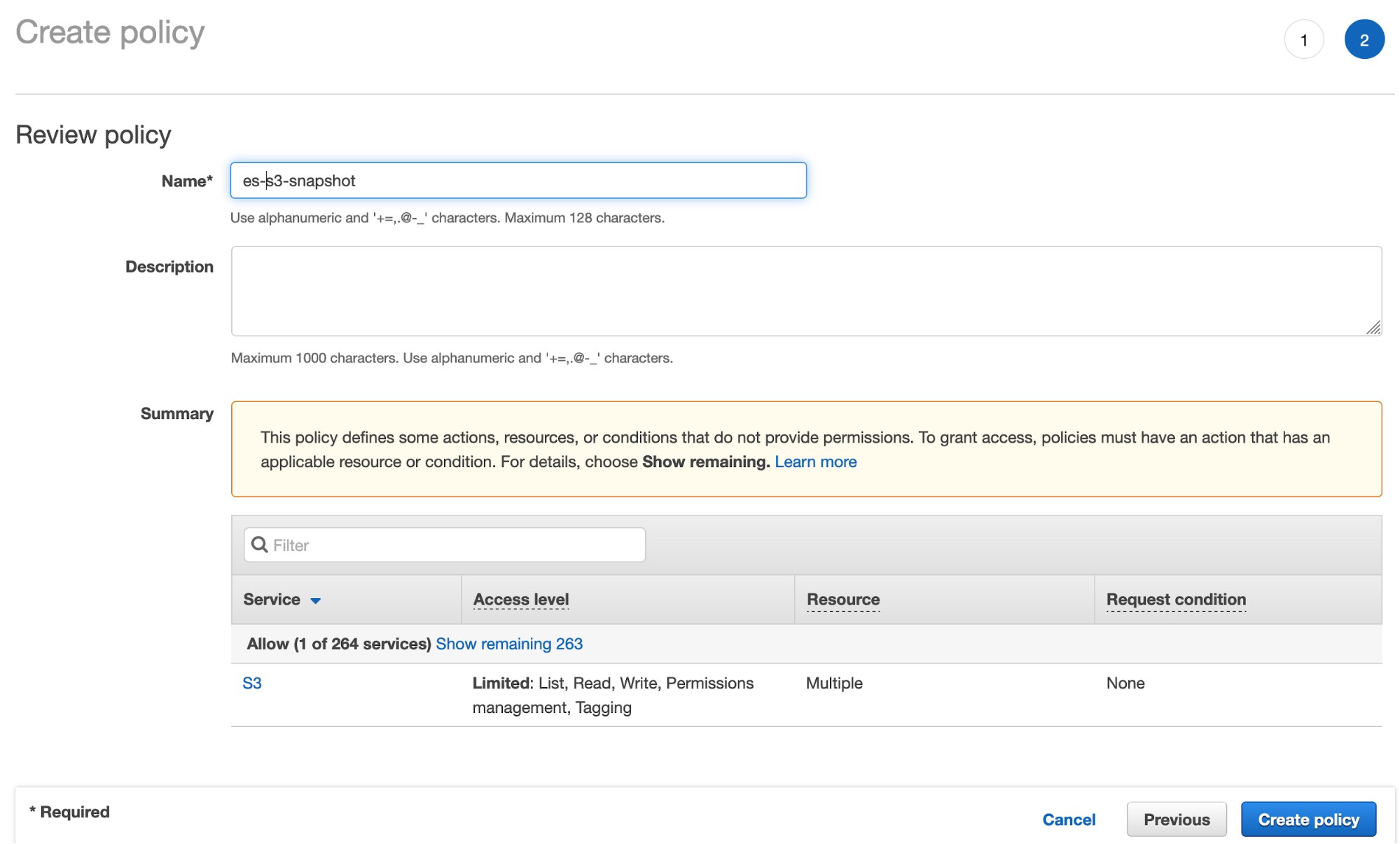
- Crea el usuario de IAM y asigna la política de cubeta de S3 que creaste antes:
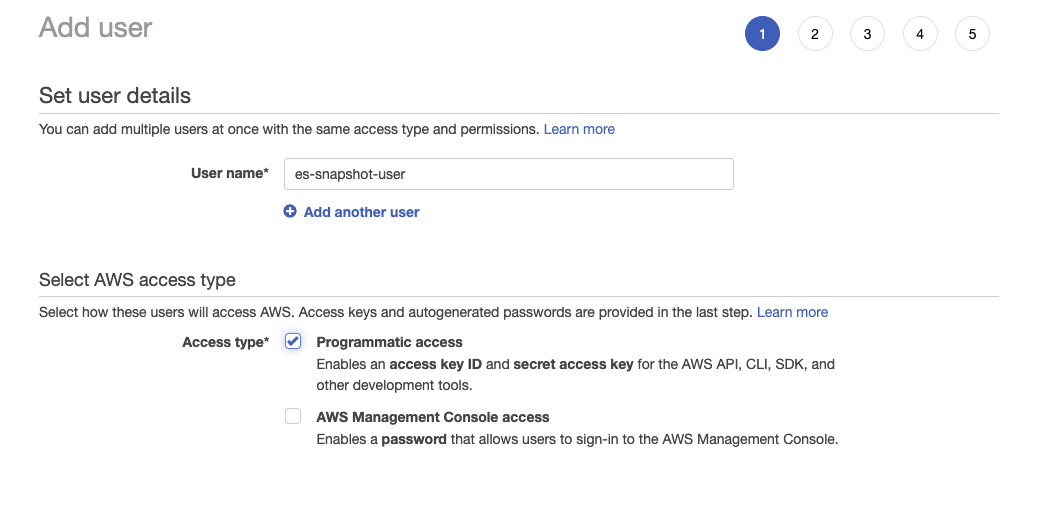
- Haz clic en Next: Permissions (Siguiente: Permisos), selecciona Attach existing policies directly (Adjuntar políticas existentes directamente) y busca la política que creaste en el paso anterior:
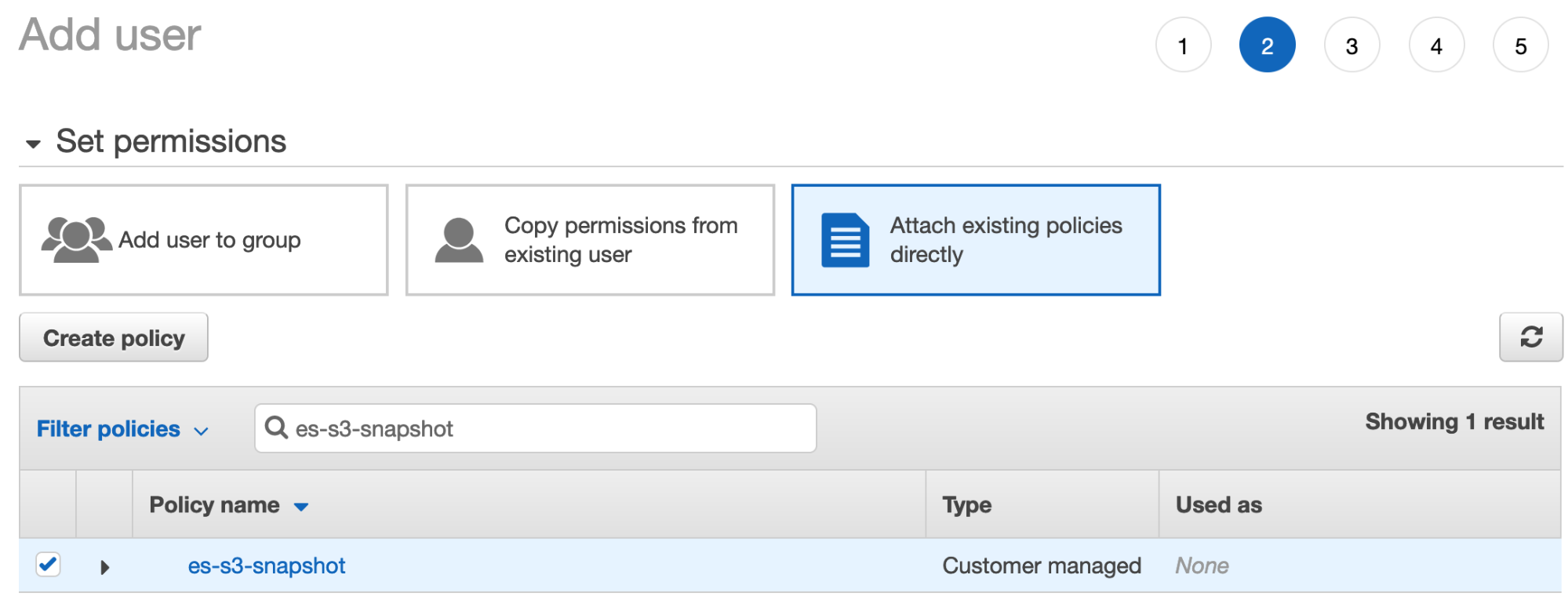
- Asegúrate de que esta política esté marcada, luego haz clic en Next:tags (Siguiente:etiquetas). Puedes omitir la creación de etiquetas y hacer clic en Create User (Crear usuario).
- Descarga las credenciales de seguridad del usuario.
Configurar el repositorio de snapshots local
1. Instalar el plugin de S3
Instala el plugin de Elasticsearch S3 en tu despliegue en las instalaciones, para hacerlo, ejecuta el comando siguiente en cada nodo de Elasticsearch local desde tu directorio de inicio de Elasticsearch:
sudo bin/elasticsearch-plugin install repository-s3
Tendrás que reiniciar el nodo tras ejecutar este comando.
2. Configurar los permisos de cliente de S3
Configura los permisos de cliente de S3 del cluster en las instalaciones, para hacerlo, ejecuta los comandos siguientes:
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
Esto es necesario para que el cluster local tenga las credenciales necesarias para escribir los snapshots en S3. Access_key y secret_key están disponibles desde el usuario de IAM creado en el paso anterior.
Configurar tu política de snapshots
1. Configurar el repositorio de snapshots
Configura el repositorio de snapshots de S3 en tu cluster local, para hacerlo, ejecuta lo siguiente en Kibana Dev Tools (Herramientas de desarrollo de Kibana). Aquí le indicamos al cluster local en qué cubeta de S3 escribir el snapshot. El usuario de IAM que acabas de crear debería tener los permisos para escribir y leer en esta cubeta de S3.
PUT _snapshot/{ "type": "s3", "settings": { "bucket": " " } }
2. Crear una política de snapshots
A continuación, crearás una política de snapshots en tu cluster local que almacenará el snapshot en la cubeta de S3 nueva:
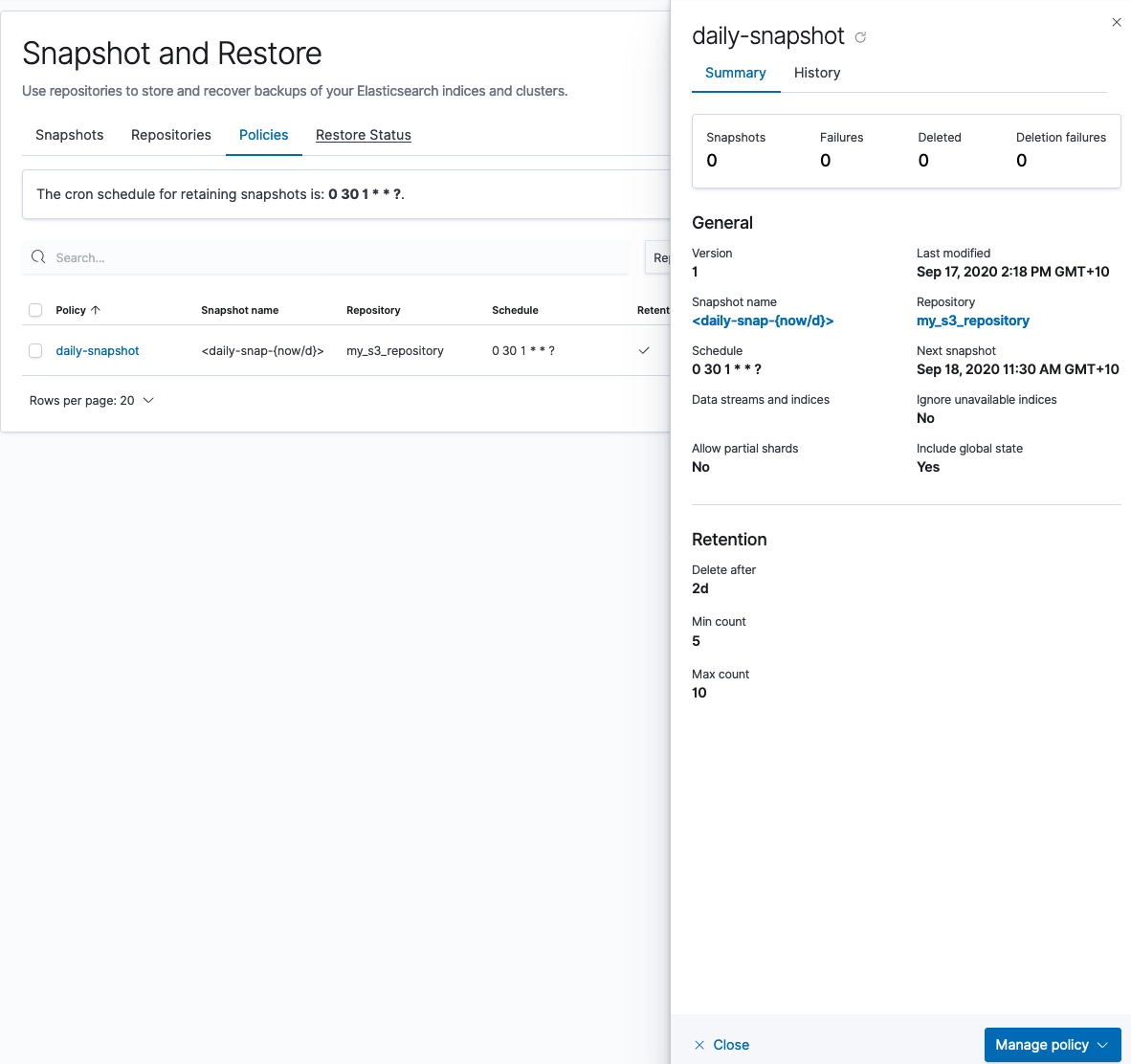
También puedes crear un snapshot excepcional en Kibana Dev Tools (Herramientas de desarrollo de Kibana):
PUT /_snapshot// ?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false }
Verifica que los snapshots estén funcionando, para hacerlo, ejecuta el comando siguiente en Dev Tools (Herramientas de desarrollo):
GET _snapshot//_all
Provisionar el cluster nuevo en Elasticsearch Service
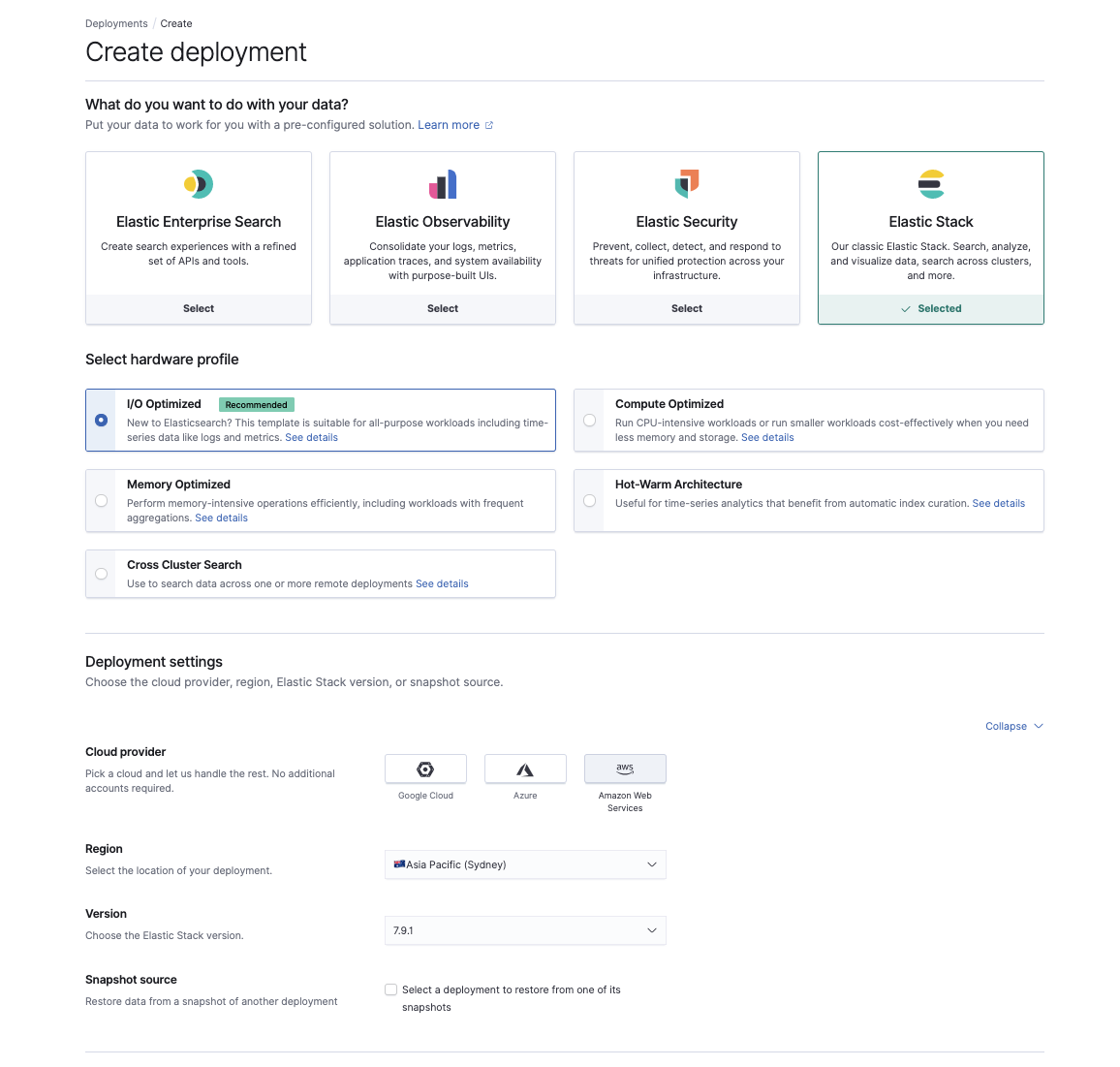
Una vez que los snapshots funcionen en S3, es momento de provisionar un cluster nuevo en Elasticsearch Service en cloud.elastic.co. Aquí puedes elegir el caso de uso que refleje mejor tu carga de trabajo existente, la región de AWS y tu versión de Elasticsearch.
En la consola de Elasticsearch Service, configura los ajustes del keystore del cluster:
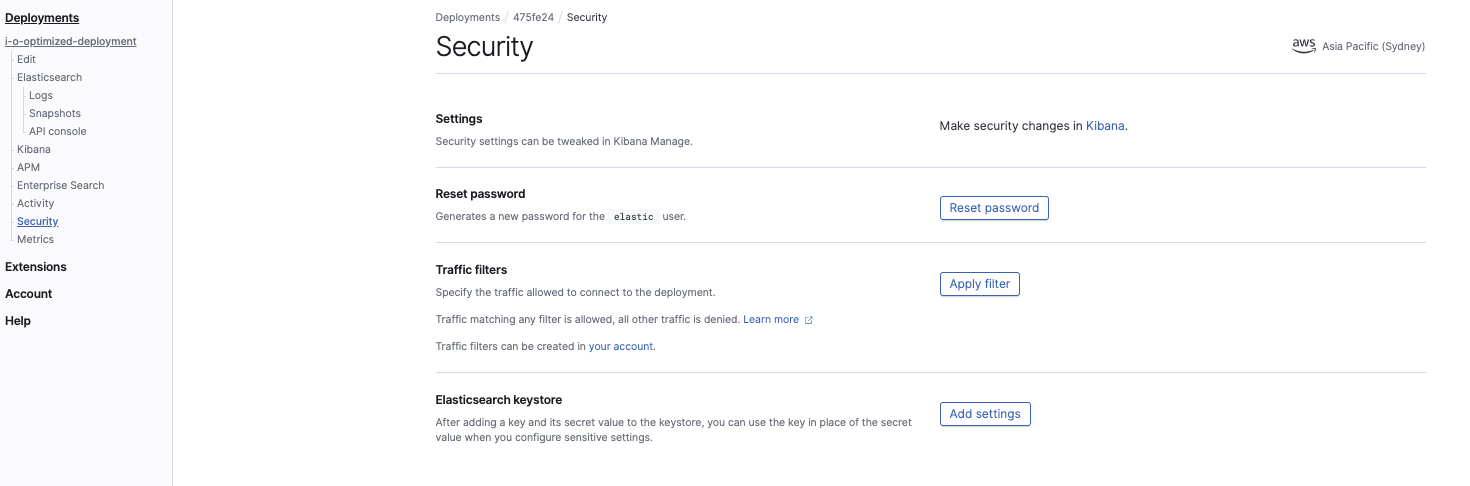
Estos son los dos ajustes que debemos configurar:
s3.client.default.access_key s3.client.default.secret_key
Esto es necesario para que el cluster de Elasticsearch Service tenga permiso para leer el snapshot desde la cubeta de S3. Será igual a las credenciales de seguridad del usuario de IAM.
Configurar el repositorio de snapshots personalizado del cluster de Elasticsearch Service
Ahora debemos crear un nuevo repositorio de snapshots en el cluster de Elasticsearch Service. Esto le indica a Elasticsearch Service dónde se encuentra en S3 el snapshot desde el cual deseamos restaurar. Para hacerlo, inicia sesión en Kibana, selecciona Stack Management (Gestión del stack) y navega a las configuraciones de Snapshot and Restore (Snapshot y restauración). Selecciona Register a repository (Registrar un repositorio):
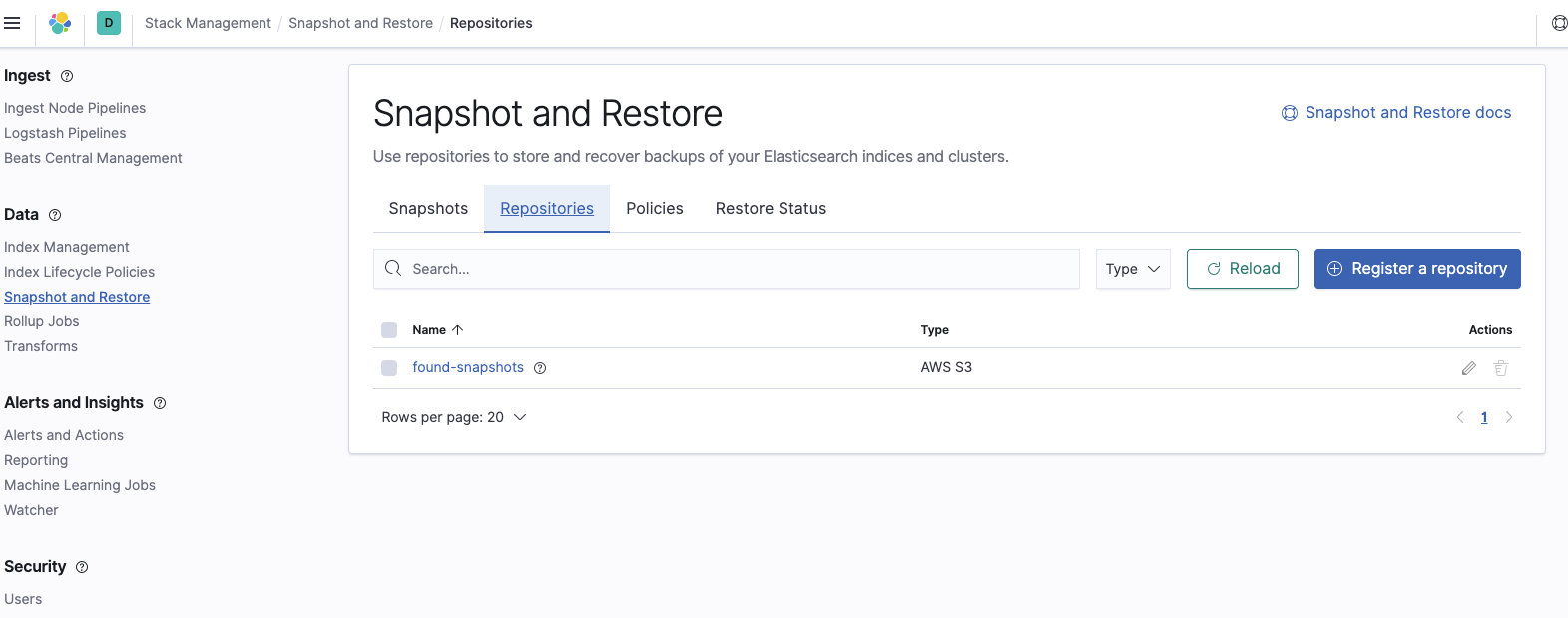
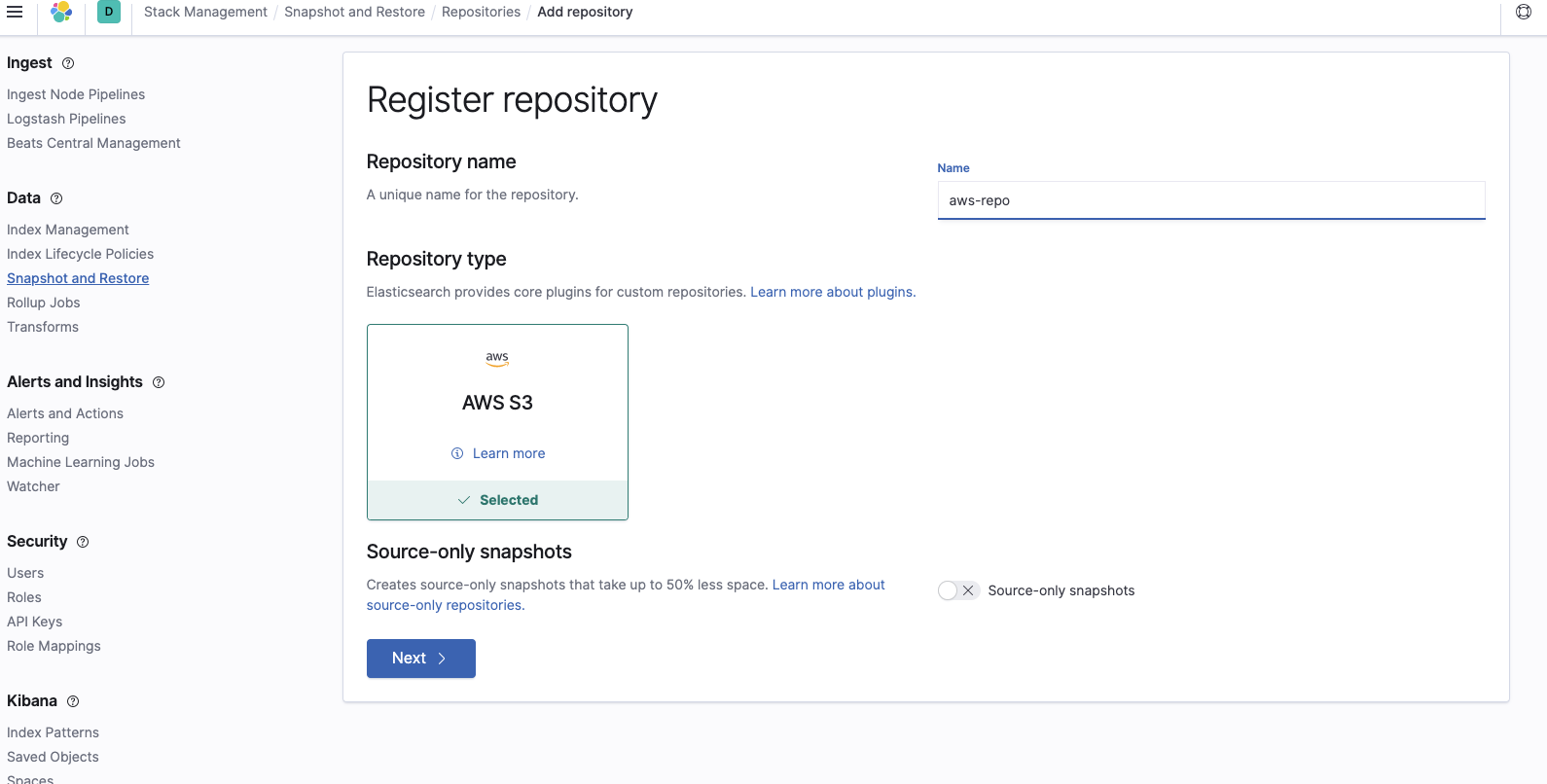
Agrega el nombre de la cubeta en la que se encuentran los snapshots:
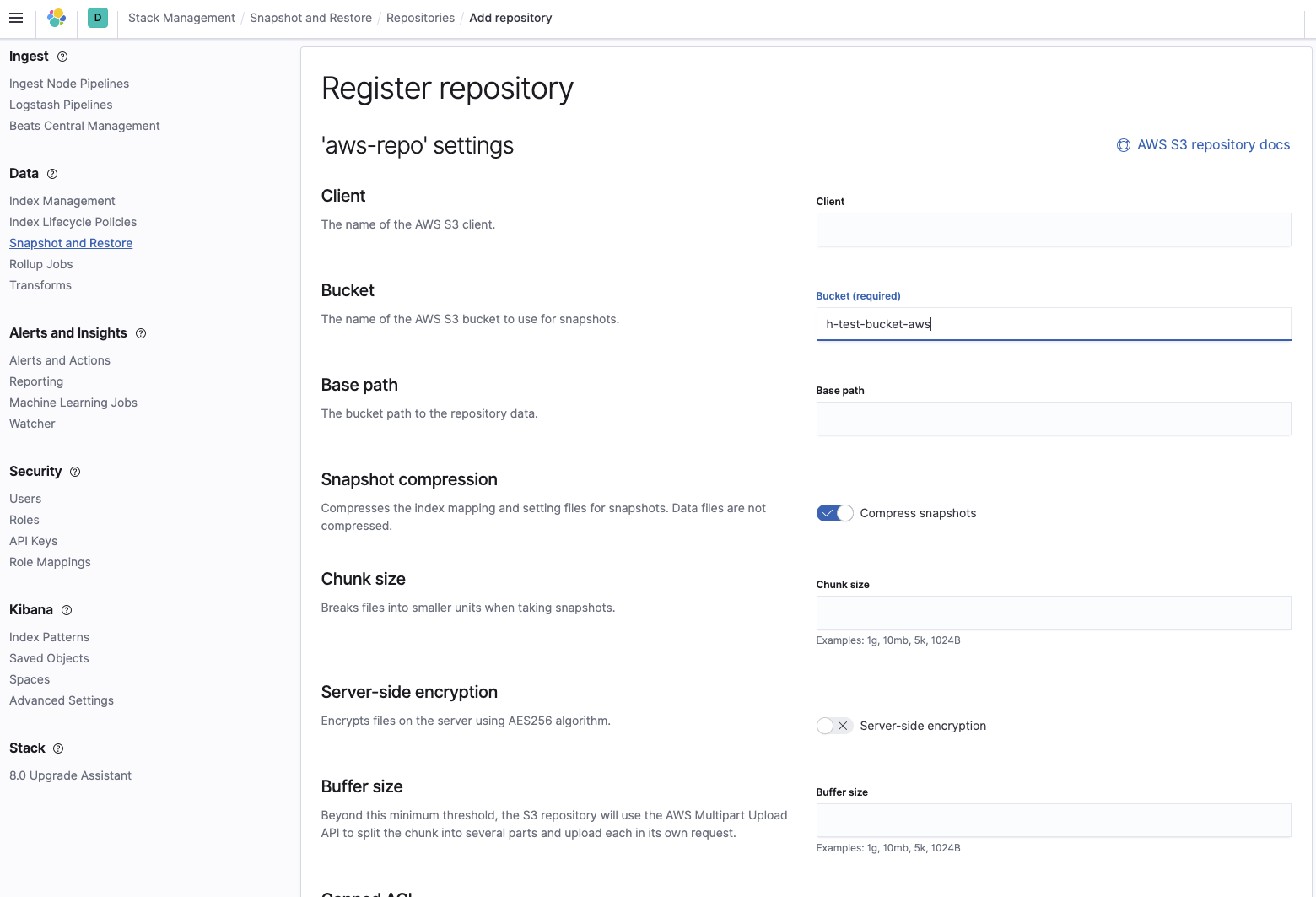
Luego verifica que el repositorio se haya configurado correctamente:
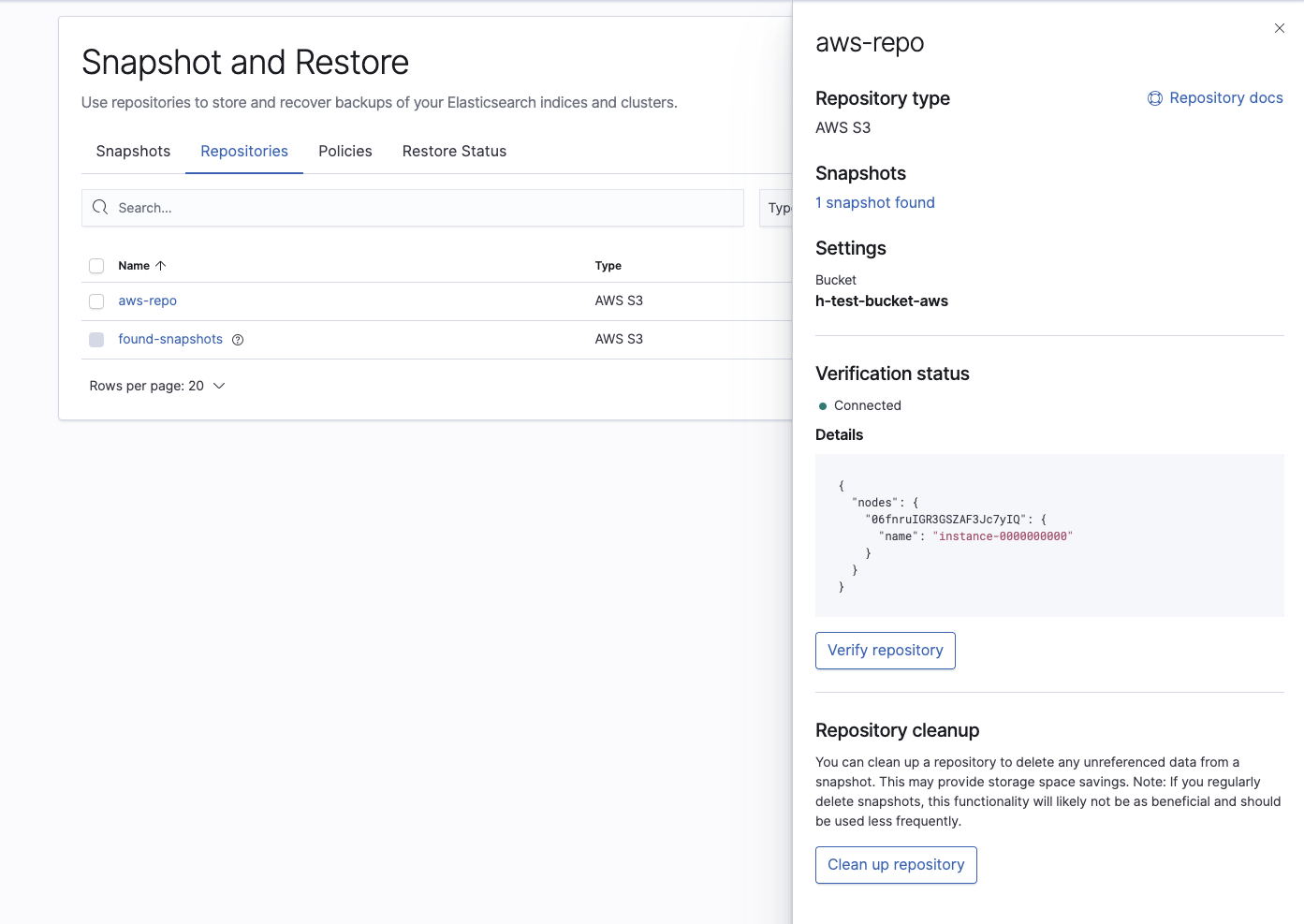
Por último, confirma que el cluster de Elasticsearch Service pueda ver el snapshot que deseamos restaurar:
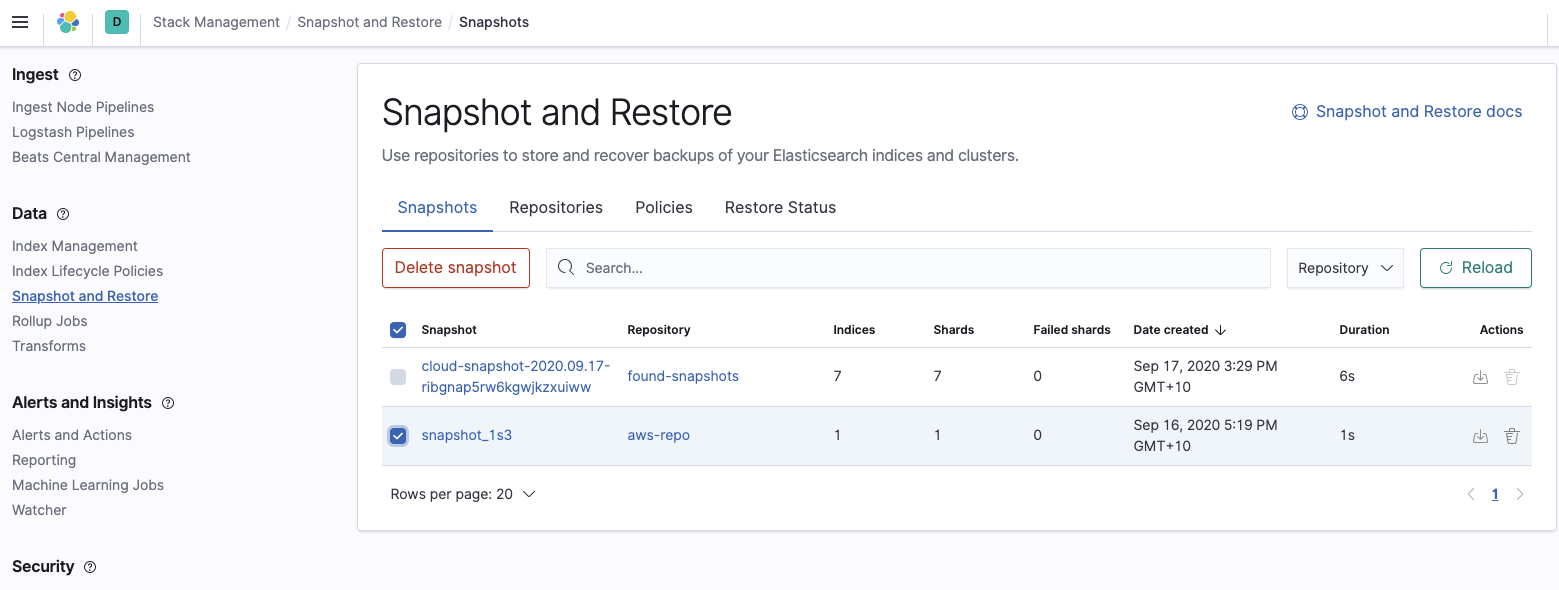
Restaurar el cluster de Elasticsearch Service desde el snapshot
Para restaurar el snapshot, ve a la consola de API del cluster de Elasticsearch Service en la consola de Elasticsearch Service y ejecuta los tres comandos siguientes. Ten en cuenta que los tres comandos se ejecutan como POST en la consola de API.
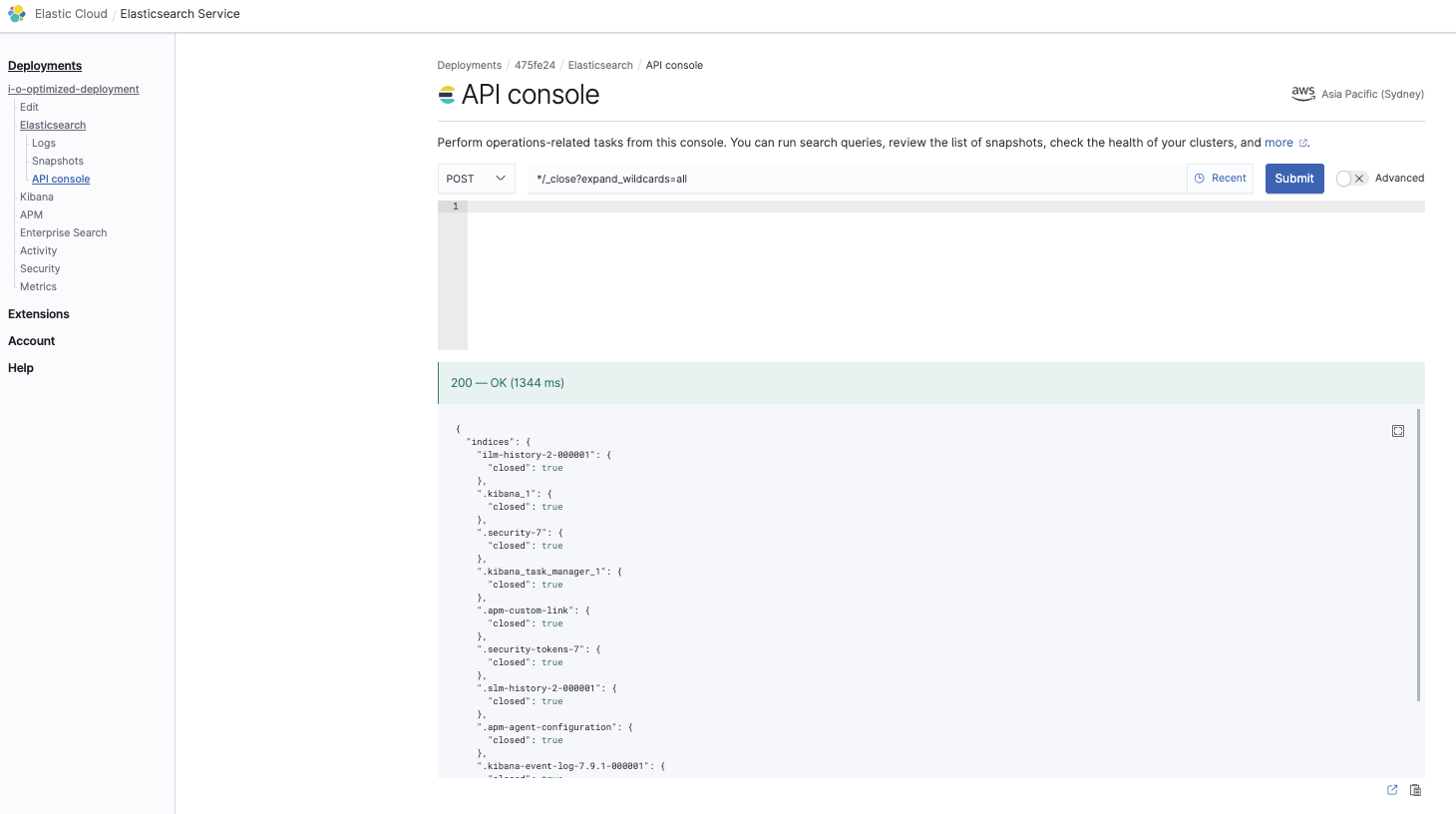
Cerrar todos los índices
*/_close?expand_wildcards=all
Esto permite asegurarnos de cerrar todos los índices primero, para que no haya conflictos durante la fase de restauración:
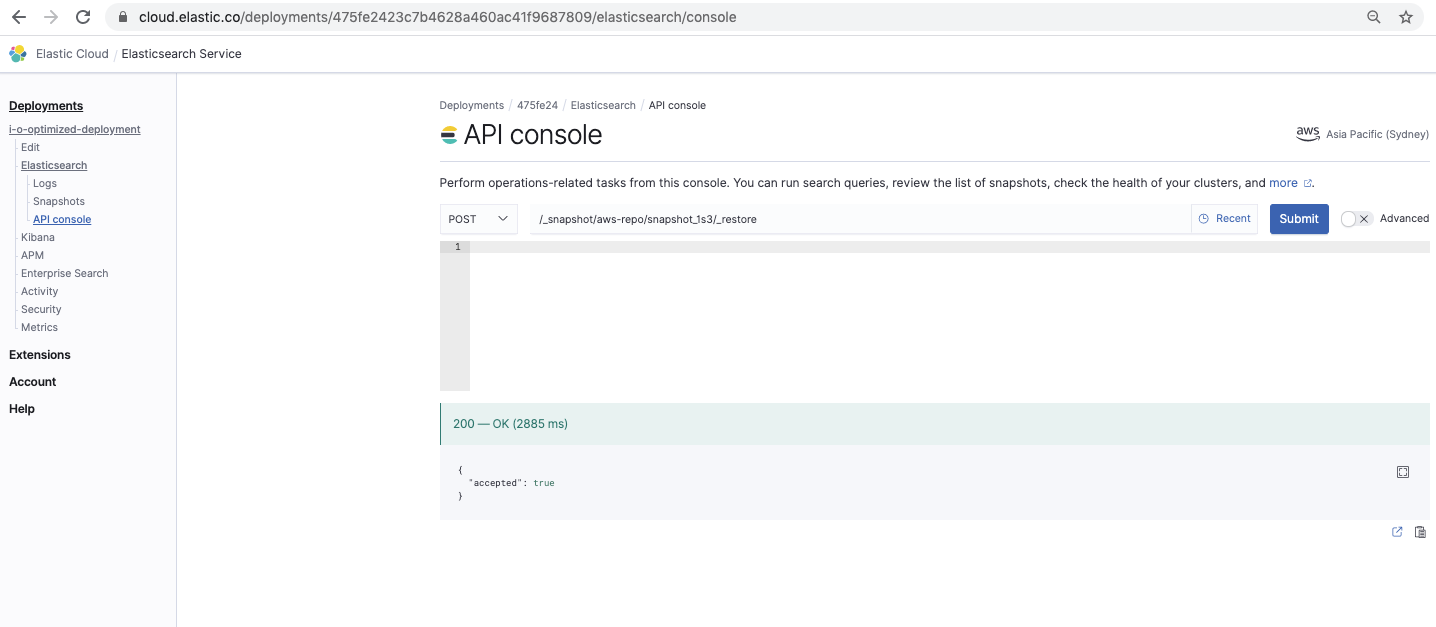
Restaurar el snapshot
/_snapshot// /_restore
Este comando restaura el snapshot:
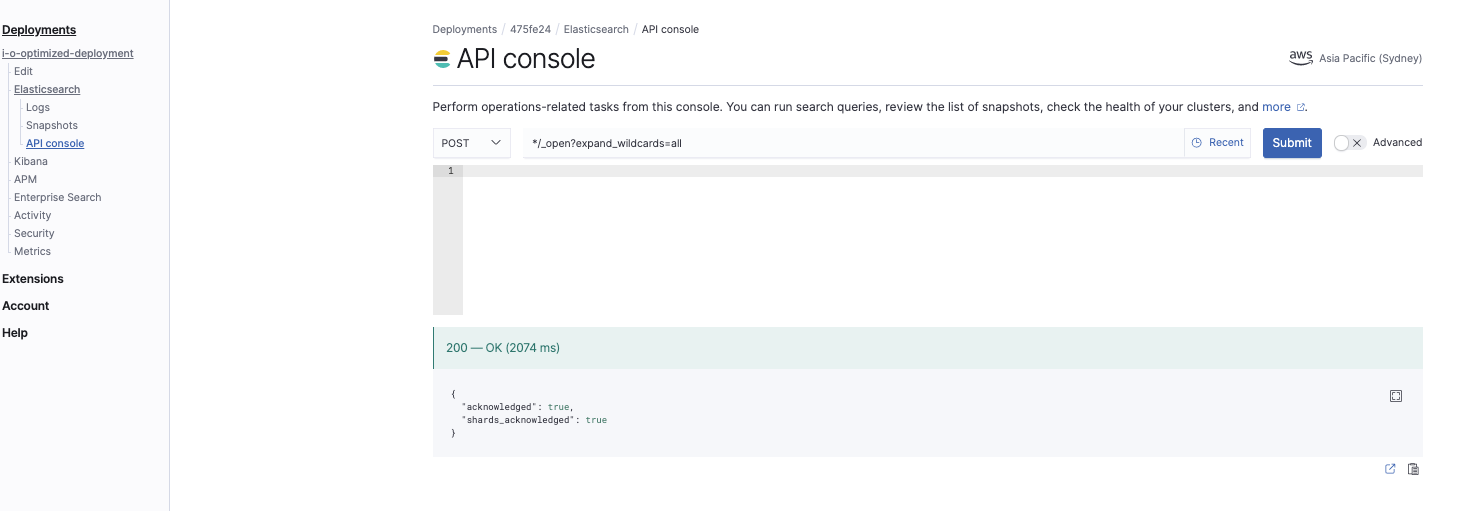
Abrir todos los índices
*/_open?expand_wildcards=all
Este comando abre todos los índices:
Verificar la restauración del snapshot
Verifica que hayas restaurado el snapshot con todos los índices. Ve a Kibana y ejecuta el comando siguiente en Dev Tools (Herramientas de desarrollo):
GET _cat/indices
En este punto, deberías tener el cluster nuevo ejecutándose en Elasticsearch Service con los mismos datos que el cluster autogestionado del cual tomaste el snapshot. Ahora puedes redirigir tus fuentes de ingesta, como Beats o Logstash, al nuevo endpoint de Elasticsearch Service, que puedes encontrar en la consola de Elastic Cloud.