Was ist das Model Context Protocol (MCP)?
Warum wurde MCP erstellt? Die Notwendigkeit einer standardisierten Integrationsschicht
Das Model Context Protocol (MCP) wurde entwickelt, um eine grundlegende Herausforderung bei der Entwicklung agentischer KI-Anwendungen zu bewältigen: die Verbindung isolierter Large Language Models (LLMs) (LLMs) mit der Außenwelt. Standardmäßig sind LLMs leistungsstarke Denkmaschinen, aber ihr Wissen ist statisch und an einen Trainingsendtermin gebunden. Außerdem fehlt ihnen die native Fähigkeit, auf Live-Daten zuzugreifen oder Aktionen in externen Systemen auszuführen.
Die Verbindung von LLMs mit externen Systemen wurde traditionell durch direkte, benutzerdefinierte API-Integrationen hergestellt. Dieser Ansatz ist effektiv, aber er erfordert, dass jeder Anwendungsentwickler die spezifische API der jeweiligen Tools erlernt, Code schreibt, um Abfragen zu verarbeiten und Ergebnisse zu parsen, und diese Verbindung im Laufe der Zeit pflegt. Mit der zunehmenden Anzahl von KI-Anwendungen und verfügbaren Tools ergibt sich die Chance für eine standardisierte und effizientere Methode.
MCP bietet dieses standardisierte Protokoll und lässt sich dabei von bewährten Standards wie REST für Webdienste und dem Language Server Protocol (LSP) für Entwicklertools inspirieren. Anstatt jeden Anwendungsentwickler zu zwingen, Experte für die API jedes Tools zu werden, etabliert MCP eine gemeinsame Sprache für diese Konnektivitätsebene.
Dadurch wird eine klare Trennung der Verantwortlichkeiten erreicht. Dies eröffnet Platform- und Tool-Anbietern die Möglichkeit, ihre Dienste über einen einzigen, wiederverwendbaren MCP-Server bereitzustellen, der von Grund auf LLM-freundlich ist. Die Verantwortung für die Pflege der Integration kann dann vom einzelnen Entwickler der KI-Anwendung auf den Besitzer des externen Systems übergehen. Dies fördert ein robustes und interoperables Ökosystem, in dem sich jede konforme Anwendung mit jedem kompatiblen Tool verbinden kann, was die Entwicklung und Wartung erheblich vereinfacht.

So funktioniert MCP: Die Kernarchitektur
MCP-Architektur
MCP arbeitet mit einem Client-Server-Modell, das eine Reasoning Engine (das LLM) mit einer Reihe externer Fähigkeiten verbindet. Die Architektur beginnt mit dem LLM und legt nach und nach die Komponenten offen, die es in die Lage versetzen, mit der Außenwelt zu interagieren.
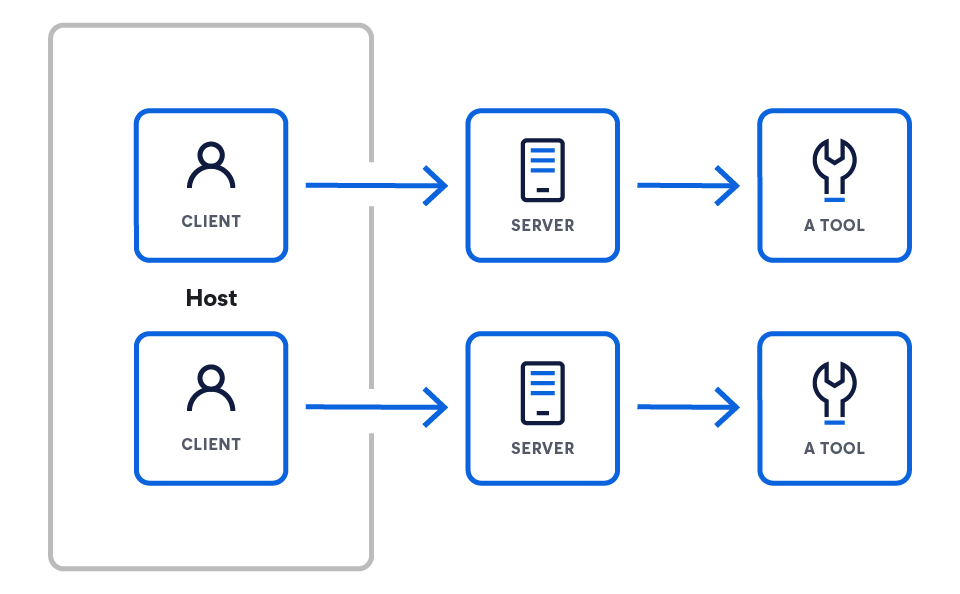
Diese Architektur besteht aus drei Hauptkomponenten:
- Hosts sind LLM-Anwendungen, die über MCP auf Daten zugreifen möchten (z. B. Claude Desktop, IDEs, KI-Agenten).
- Server sind leichtgewichtige Programme, die jeweils spezifische Funktionen über MCP bereitstellen.
- Clients pflegen 1:1-Verbindungen mit Servern innerhalb der Hostanwendung.
MCP-Clients oder Hosts

MCP-Clients oder -Hosts sind die Anwendungen, die die Interaktion zwischen LLMs und einem oder mehreren MCP-Servern orchestrieren. Der Client ist entscheidend – er enthält die app-spezifische Logik. Während Server die grundlegenden Funktionen bereitstellen, ist der Client für deren Nutzung verantwortlich. Dazu werden die folgenden Funktionen verwendet:
- Prompt-Zusammenstellung: Sammeln von Kontext von verschiedenen Servern, um die endgültige, effektive Eingabeaufforderung (Prompt) für das LLM zu erstellen
- Statusverwaltung: Pflege des Gesprächsverlaufs und Nutzerkontextes über mehrere Interaktionen hinweg
- Orchestrierung: Entscheidung dessen, welche Server für welche Informationen abgefragt werden sollen, und Ausführung der Logik, wenn ein LLM beschließt, ein Tool zu verwenden
MCP-Clients verbinden sich über Standard-Netzwerkanfragen (in der Regel über HTTPS) mit einem bekannten Endpoint. Die Stärke des Protokolls liegt darin, dass es den Kommunikationsvertrag zwischen ihnen standardisiert. Das Protokoll selbst ist sprachunabhängig und verfügt über ein JSON-basiertes Format. Somit kann jeder Client, unabhängig von der Sprache, in der er erstellt wurde, korrekt mit jedem Server kommunizieren.
Client-Beispiele aus der MCP-Spezifikation
MCP-Server
Ein MCP-Server ist ein Backend-Programm, das als standardisierter Wrapper für eine bestimmte Datenquelle oder ein bestimmtes Tool fungiert. Es implementiert die MCP-Spezifikation, um Funktionen – wie ausführbare Tools oder Datenressourcen – über das Netzwerk bereitzustellen. Im Wesentlichen übersetzt es das einzigartige Protokoll eines bestimmten Dienstes (wie eine Datenbankabfrage oder eine REST-API eines Drittanbieters) in die gemeinsame Sprache von MCP, wodurch es für jeden MCP-Client verständlich wird.
Serverbeispiele aus der MCP-Spezifikation
Hands on: Wie können Sie Ihren ersten MCP-Server erstellen?
Nehmen wir das Beispiel eines Servers, der Tools bereitstellt (mehr zu Tools weiter unten). Dieser Server muss zwei Hauptanforderungen vom Client verarbeiten:
- Installieren Sie das SDK.
# Python pip install mcp # Node.js npm install @modelcontextprotocol/sdk # Or explore the specification git clone https://github.com/modelcontextprotocol/specification
- Erstellen Sie Ihren ersten Server.
from mcp.server.fastmcp import FastMCP import asyncio mcp = FastMCP("weather-server") @mcp.tool() async def get_weather(city: str) -> str: """Wetter für eine Stadt abrufen.""" return f"Wetter in {city}: Sonnig, 22 °C" if __name__ == "__main__": mcp.run() - Verbinden Sie sich mit Claude Desktop.
{ "mcpServers": { "weather": { "command": "python", "args": ["/full/path/to/weather_server.py"], "env": {} } } }
Offizielle SDKs und Ressourcen
Sie können mit dem Aufbau Ihrer eigenen MCP-Clients und -Server beginnen, indem Sie die offiziellen Open-Source-SDKs verwenden:
MCP-Tools
Ein Tool ist eine spezifische, ausführbare Funktion, die ein MCP-Server einem Client zur Verfügung stellt. Im Gegensatz zu passiven Datenressourcen (wie einer Datei oder einem Dokument) stellen Tools Aktionen dar, die das LLM aufrufen kann, wie das Senden einer E-Mail, das Erstellen eines Projekttickets oder das Abfragen einer Live-Datenbank.
Tools interagieren mit Servern auf folgende Weise: Ein MCP-Server deklariert die Tools, die er anbietet. Beispielsweise würde ein Elastic-Server ein „list_indices“-Tool bereitstellen und dessen Namen, Zweck und erforderliche Parameter (z. B. „list_indices“, „get_mappings“, „get_shards“ und „suchen“) definieren.
Der Client stellt eine Verbindung mit dem Server her und entdeckt diese verfügbaren Tools. Der Client stellt dem LLM die verfügbaren Tools als Teil seiner Systemaufforderung oder seines Kontexts zur Verfügung. Wenn die Ausgabe des LLM auf die Absicht hindeutet, ein Tool zu verwenden, parst der Client dies und stellt eine formelle Anfrage an den entsprechenden Server, um dieses Tool mit den angegebenen Parametern auszuführen.
Beispiel für Werkzeugmuster aus der MCP-Spezifikation
Praktische Einführung: Eine Low-Level-MCP-Serverimplementierung
Das Low-Level-Beispiel ist zwar nützlich, um die Funktionsweise des Protokolls zu verstehen, jedoch verwenden die meisten Entwickler ein offizielles SDK zum Erstellen von Servern. SDKs übernehmen die Standardaufgaben des Protokolls, wie beispielsweise die Nachrichtenanalyse und die Weiterleitung von Anfragen, sodass Sie sich auf die Kernlogik Ihrer Tools konzentrieren können.
Das folgende Beispiel verwendet das offizielle MCP Python SDK, um einen einfachen Server zu erstellen, der ein get_current_time-Tool bereitstellt. Dieser Ansatz ist deutlich prägnanter und deklarativer als die Low-Level-Implementierung.
import asyncio
import datetime
from typing import AsyncIterator
from mcp.server import (
MCPServer,
Tool,
tool,
)
# --- Tool Implementation ---
# The @tool decorator from the SDK handles the registration and schema generation.
# We define a simple asynchronous function that will be exposed as an MCP tool.
@tool
async def get_current_time() -> AsyncIterator[str]:
"""
Returns the current UTC time and date as an ISO 8601 string.
This docstring is automatically used as the tool's description for the LLM.
"""
# The SDK expects an async iterator, so we yield the result.
yield datetime.datetime.now(datetime.timezone.utc).isoformat()
# --- Server Definition ---
# We create an instance of the MCPServer, passing it the tools we want to expose.
# The SDK automatically discovers any functions decorated with @tool.
SERVER = MCPServer(
tools=[
# The SDK automatically picks up our decorated function.
Tool.from_callable(get_current_time),
],
)
# --- Main execution block ---
# The SDK provides a main entry point to run the server.
# This handles all the underlying communication logic (stdio, HTTP, etc.).
async def main() -> None:
"""Runs the simple tool server."""
await SERVER.run()
if __name__ == "__main__":
asyncio.run(main())
Dieses praktische Beispiel demonstriert die mit Energie versorgen der Verwendung eines SDK zum Erstellen von MCP-Servern:
- @tool Decorator: Dieser Decorator registriert die Funktion get_current_time automatisch als MCP-Tool. Er überprüft die Signatur und den Docstring der Funktion, um das erforderliche Schema und die Beschreibung für das Protokoll zu generieren, sodass Sie diese nicht manuell schreiben müssen.
- MCPServer Instanz: Die MCPServer-Klasse ist der Kern des SDK. Sie geben ihm einfach eine Liste der Tools, die Sie verfügbar machen möchten, und es erledigt den Rest.
- SERVER.run(): Dieser einzelne Befehl startet den Server und verwaltet die gesamte Kommunikation auf niedriger Ebene, einschließlich der Handhabung verschiedener Transportmethoden wie stdio oder HTTP.
Wie Sie sehen können, abstrahiert das SDK nahezu alle Komplexitäten des Protokolls und ermöglicht es Ihnen, mit nur wenigen Zeilen Python-Code leistungsstarke Tools zu definieren.
Die 3 Kernprimitiven
MCP standardisiert, wie ein LLM mit der Außenwelt interagiert, indem es drei Kernprimitive definiert, die ein Server bereitstellen kann. Diese Primitiven bieten ein vollständiges System, um LLMs mit externer Funktionalität zu verbinden.
- Ressourcen: Kontext bereitstellen
- Funktion: Datenzugriff
- Analogie: GET-Endpoints
- Ressourcen sind der primäre Mechanismus für die Bereitstellung von Kontext an ein LLM. Sie stellen Datenquellen dar, die das Modell abrufen und zur Information seiner Reaktion verwenden kann, wie Dokumente, Datenbankeinträge oder die Ergebnisse einer Suchanfrage. Normalerweise handelt es sich um schreibgeschützte Vorgänge.
- Tools: Maßnahmen ermöglichen
- Funktion: Aktionen und Berechnungen
- Analogie: POST- oder PUT-Endpoints
- Tools sind ausführbare Funktionen, die es einem LLM ermöglichen, Aktionen auszuführen und direkten Einfluss auf externe Systeme zu nehmen. Dadurch kann ein Agent über den einfachen Datenabruf hinausgehen und beispielsweise eine E-Mail senden, ein Projektticket erstellen oder eine API eines Drittanbieters aufrufen.
- Eingabeaufforderungen: Interaktionen leiten
- Funktion: Interaktionsvorlagen
- Analogie: Workflow-Rezepte
- Prompts sind wiederverwendbare Vorlagen, die die Interaktion des LLM mit einem Nutzer oder einem System leiten. Sie ermöglichen es Entwicklern, gängige oder komplexe Gesprächsabläufe zu standardisieren und so ein konsistenteres und zuverlässigeres Verhalten des Modells zu gewährleisten.
Das Model Context Protocol selbst
Kernkonzepte
Das MCP bietet eine standardisierte Möglichkeit für LLM-Anwendungen (Hosts), sich mit externen Daten und Funktionen (Servern) zu integrieren. Die Spezifikation basiert auf dem JSON-RPC 2.0-Nachrichtenformat und definiert eine Reihe von erforderlichen und optionalen Komponenten, um umfangreiche, zustandsorientierte Interaktionen zu ermöglichen.
Kernprotokoll und Features
Im Kern standardisiert MCP die Kommunikationsschicht. Alle Implementierungen müssen das Basisprotokoll und das Lifecycle-Management unterstützen.
- Basisprotokoll: Sämtliche Kommunikation verwendet standardmäßige JSON-RPC-Nachrichten (Anfragen, Antworten und Benachrichtigungen).
- Server-Features: Server können Clients eine beliebige Kombination der folgenden Features bieten:
- Ressourcen: Kontextdaten, die der Nutzer oder das Modell nutzen kann
- Eingabeaufforderungen: Vorlagenbasierte Nachrichten und Workflows
- Werkzeuge: Ausführbare Funktionen, die das LLM aufrufen kann
- Clients-Features: Clients können diese Features Servern anbieten – für erweiterte, bidirektionale Workflows:
- Sampling: Ermöglicht es einem Server, agentisches Verhalten oder rekursive LLM-Interaktionen zu initiieren
- Anforderungserhebung (Elicitation): Ermöglicht es einem Server, zusätzliche Informationen vom Nutzer anzufordern
MCP-Basisprotokoll
Das MCP basiert auf der erforderlichen Grundlage eines Basisprotokolls und des Lifecycle-Managements. Die gesamte Kommunikation zwischen Clients und Servern muss der JSON-RPC 2.0-Spezifikation entsprechen, die drei Nachrichtentypen definiert:
- Anfragen: Werden gesendet, um einen Vorgang zu initiieren. Sie erfordern eine eindeutige Zeichenfolge oder eine ganzzahlige ID zur Nachverfolgung und dürfen eine ID innerhalb derselben Sitzung nicht wiederverwenden.
- Antworten: Werden als Antwort auf eine Anfrage gesendet. Sie müssen die ID der ursprünglichen Anfrage enthalten und entweder ein result-Objekt für erfolgreiche Vorgänge oder ein error-Objekt für Fehler beinhalten.
- Benachrichtigungen: Einweg-Nachrichten, die ohne ID gesendet werden und keine Antwort vom Empfänger erfordern.
Client-Features: Ermöglichen erweiterter Workflows
Für eine komplexere, bidirektionale Kommunikation können Clients den Servern auch Features anbieten:
- Sampling: Sampling ermöglicht es einem Server, über den Client eine Inferenz vom LLM anzufordern. Dies ist ein leistungsstarkes Feature für mehrstufige agentenbasierte Workflows, bei denen ein Tool möglicherweise „eine Frage an das LLM zurückstellen muss“, um weitere Informationen zu erhalten, bevor es seine Aufgabe abschließen kann.
- Anforderungserhebung (Elicitation): Die Anforderungserhebung stellt einen formellen Mechanismus dar, mit dem ein Server den Nutzer um weitere Informationen bitten kann. Dies ist entscheidend für interaktive Tools, die vor der Ausführung einer Aktion möglicherweise einer Klarstellung oder Bestätigung bedürfen.
Server-Features: Bereitstellen von Funktionen
Server stellen ihre Fähigkeiten den Clients über eine Reihe standardisierter Features zur Verfügung. Ein Server kann eine beliebige Kombination der folgenden Elemente implementieren:
- Tools: Tools sind der primäre Mechanismus, der es einem LLM ermöglicht, Aktionen auszuführen. Es handelt sich um ausführbare Funktionen, die ein Server bereitstellt, um dem LLM die Interaktion mit externen Systemen zu ermöglichen, wie z. B. das Aufrufen einer Drittanbieter-API, das Abfragen einer Datenbank oder das Ändern einer Datei.
- Ressourcen: Ressourcen stellen Quellen für Kontextdaten dar, die ein LLM abrufen kann. Im Gegensatz zu Tools, die Aktionen ausführen, dienen Ressourcen in erster Linie dem schreibgeschützten Abrufen von Daten. Sie sind der Mechanismus zur Verankerung eines LLM in Echtzeit- und externen Informationen und bilden einen wichtigen Bestandteil fortschrittlicher RAG-Pipelines.
- Eingabeaufforderungen: Server können vordefinierte Vorlagen für Eingabeaufforderungen bereitstellen, die ein Client verwenden kann. Dies ermöglicht die Standardisierung und gemeinsame Nutzung von gängigen, komplexen oder hochoptimierten Eingabeaufforderungen und gewährleistet konsistente Interaktionen.
Sicherheit und Vertrauen
Die Spezifikation legt einen starken Schwerpunkt auf die Sicherheit und umreißt die wichtigsten Prinzipien, die Implementierer sollten befolgen. Das Protokoll selbst kann diese Regeln nicht durchsetzen; die Verantwortung liegt beim Anwendungsentwickler.
- Zustimmung und Kontrolle durch den Nutzer: Nutzer müssen ausdrücklich ihre Zustimmung zu allen Datenzugriffen und Toolaufrufen geben und die Kontrolle darüber behalten. Klare Benutzeroberflächen für die Autorisierung sind unerlässlich.
- Datenschutz: Hosts dürfen ohne ausdrückliche Zustimmung keine Nutzerdaten an einen Server übertragen und müssen angemessene Zugriffskontrollen implementieren.
- Tool-Sicherheit: Der Aufruf eines Tools stellt die Ausführung von beliebigem Code dar und muss mit Vorsicht behandelt werden. Hosts müssen vor dem Aufrufen eines Tools die ausdrückliche Zustimmung des Nutzers einholen.
Warum ist MCP so wichtig?
Der Kernvorteil von MCP liegt in der Standardisierung der Kommunikations- und Interaktionsebene zwischen Modellen und Tools. Dies schafft ein vorhersehbares und zuverlässiges Ökosystem für Entwickler. Zu den wichtigsten Bereichen der Standardisierung gehören:
- Einheitliche Connector-API: Eine einzige, konsistente Schnittstelle für die Verbindung beliebiger externer Dienste
- Standardisierter Kontext: Ein universelles Nachrichtenformat zur Übermittlung kritischer Informationen wie Sitzungsverlauf, Einbettungen, Tool-Ausgabe und Langzeitspeicher
- Toolaufrufprotokoll: Vereinbarte Anforderungs- und Reaktionsmuster für den Aufruf externer Tools, um Vorhersagbarkeit zu gewährleisten
- Datenflusskontrolle: Integrierte Regeln für das Filtern, Priorisieren, Streamen und Batchen von Kontext zur Optimierung der Prompt-Erstellung
- Sicherheit und Authentifizierungsmuster: Allgemeine Hooks für API-Schlüssel oder OAuth-Authentifizierung, Ratenbegrenzung und Verschlüsselung zur Absicherung des Datenaustauschs
- Lebenszyklus- und Routing-Regeln: Konventionen, die festlegen, wann der Kontext abgerufen werden soll, wie lange er zwischengespeichert wird und wie Daten zwischen Systemen weitergeleitet werden sollen
- Metadaten und Beobachtbarkeit: Vereinheitlichte Metadatenfelder, die konsistentes Logging, Metriken und verteiltes Tracing über alle verbundenen Modelle und Tools hinweg ermöglichen
- Erweiterungspunkte: Definierte Hooks zum Hinzufügen von benutzerdefinierter Logik, wie Vor- und Nachbearbeitungsschritte, benutzerdefinierte Validierungsregeln und Plugin-Registrierung
Im großen Maßstab: Lösung des „M×N“-Integrationsalptraums oder des Alptraums der multiplikativen Skalierung
In der schnell wachsenden KI-Landschaft stehen Entwickler vor einer erheblichen Integrationsherausforderung. KI-Anwendungen (M) müssen auf zahlreiche externe Datenquellen und Tools (N) zugreifen, von Datenbanken und Suchmaschinen bis hin zu APIs und Code-Repositories. Ohne ein standardisiertes Protokoll sind Entwickler gezwungen, das „M×N-Problem“ zu lösen, indem sie für jedes Anwendung-zu-Quelle-Paar eine einzigartige, benutzerdefinierte Integration erstellen und pflegen.
Dieser Ansatz führt zu mehreren kritischen Problemen:
- Redundante Entwicklerarbeiten: Teams lösen bei jeder neuen KI-Anwendung wiederholt dieselben Integrationsprobleme, wodurch wertvolle Zeit und Ressourcen verschwendet werden.
- Überwältigende Komplexität: Verschiedene Datenquellen verarbeiten ähnliche Funktionen auf einzigartige Weise, wodurch eine komplexe und inkonsistente Integrationsebene entsteht.
- Übermäßiger Wartungsaufwand: Die fehlende Standardisierung führt zu einem instabilen Ökosystem aus benutzerdefinierten Integrationen. Eine geringfügige Aktualisierung oder Änderung der API eines einzelnen Tools kann Verbindungen unterbrechen, wodurch eine kontinuierliche, reaktive Wartung erforderlich wird.
MCP wandelt dieses M×N-Problem in eine viel einfachere M+N-Gleichung um. Durch die Schaffung eines universellen Standards müssen Entwickler nur M-Clients (für ihre Anwendungen) und N-Server (für ihre Tools) erstellen, wodurch die Komplexität und der Wartungsaufwand drastisch reduziert werden.
Vergleich von agentischen Ansätzen
MCP ist keine Alternative zu beliebten Mustern wie Retrieval-Augmented Generation (RAG) oder Frameworks wie LangChain: Es ist ein grundlegendes Konnektivitätsprotokoll, das sie leistungsfähiger, modularer und einfacher zu pflegen macht. Es löst das universelle Problem der Verbindung einer Anwendung mit einem externen Tool, indem es die „letzte Meile“ der Integration standardisiert.
So fügt sich MCP in den modernen KI-Stack ein:
Antrieb für fortschrittliches RAG
Standardmäßiges RAG ist leistungsfähig, wird aber häufig mit einer statischen Vektordatenbank verbunden. Für fortgeschrittene Anwendungsfälle müssen Sie dynamische Informationen aus aktiven, komplexen Systemen abrufen.
- Ohne MCP: Ein Entwickler muss benutzerdefinierten Code schreiben, um seine RAG-Anwendung direkt mit der spezifischen Abfragesprache einer Such-API wie Elasticsearch zu verbinden.
- Mit MCP: Das Suchsystem stellt seine Fähigkeiten über einen Standard-MCP-Server zur Verfügung.Die RAG-Anwendung kann diese Live-Datenquelle jetzt mit einem einfachen, wiederverwendbaren MCP-Client abfragen, ohne die spezifische API des zugrunde liegenden Systems kennen zu müssen.Dadurch wird die RAG-Implementierung übersichtlicher und lässt sich in Zukunft leichter durch andere Datenquellen ersetzen.
Integration mit agentischen Frameworks (z. B. LangChain, LangGraph)
Agentische Frameworks bieten hervorragende Tools zum Aufbau von Anwendungslogik, erfordern jedoch weiterhin eine Möglichkeit zur Verbindung mit externen Tools.
- Die Alternativen:
- Benutzerdefinierter Code: Eine direkte Integration von Grund auf zu schreiben, erfordert erheblichen technischen Aufwand und fortlaufende Wartung
- Framework-spezifische Toolkits: Die Verwendung eines vorgefertigten Connectors oder das Schreiben eines benutzerdefinierten Wrappers für ein bestimmtes Framework (Dies führt zu einer Abhängigkeit von der Architektur dieses Frameworks und bindet Sie an dessen Ökosystem.)
- Der MCP-Vorteil: MCP bietet einen offenen, universellen Standard. Ein Tool-Anbieter kann einen einzelnen MCP-Server für sein Produkt erstellen. Jetzt kann jedes Framework – LangChain, LangGraph oder eine benutzerdefinierte Lösung – über einen generischen MCP-Client mit diesem Server interagieren. Dieser Ansatz ist effizienter und verhindert eine Anbieterbindung.
Warum ein Protokoll alles vereinfacht
Letztendlich liegt der Wert von MCP darin, eine offene, standardisierte Alternative zu den beiden Extremen der Integration bereitzustellen:
- Benutzerdefinierten Code zu schreiben ist fehleranfällig und verursacht hohe Wartungskosten.
- Die Verwendung von Framework-spezifischen Wrappern führt zu einem halbgeschlossenen Ökosystem und einer Abhängigkeit vom Anbieter.
MCP überträgt das Eigentum an der Integration an den Besitzer des externen Systems, sodass dieser einen einzigen, stabilen MCP-Endpoint bereitstellen kann. Anwendungsentwickler können diese Endpoints dann einfach nutzen, was den Arbeitsaufwand für die Erstellung, Skalierung und Pflege leistungsstarker, kontextsensitiver KI-Anwendungen drastisch vereinfacht.
Erste Schritte mit dem Elasticsearch-MCP-Server
Elasticsearch bietet jetzt einen vollständig verwalteten, gehosteten MCP-Server an. Dadurch entfällt die Notwendigkeit eigenständiger Docker-Container oder lokaler Node.js-Umgebungen und bietet ein persistentes und sicheres Gateway für jeden MCP-konformen Host.
Zugriff auf den gehosteten Endpunkt
Ab Version 9.3 und serverless ist der MCP-Server standardmäßig für Suchprojekte aktiviert. Für Benutzer von Observability und Security kann der MCP-Server durch Aktivierung des Agent Builders über die Konfiguration des AI Assistant zugänglich gemacht werden.
Für vollständige Implementierungsdetails und plattformspezifische Anleitungen siehe die offizielle Agent Builder-Dokumentation.
Konfigurieren Sie Ihren MCP-Client
Nach der Aktivierung müssen Sie lediglich Ihren MCP-Host (wie Claude Desktop, VS Code oder Cursor) auf Ihren eindeutigen Elastic-Endpunkt richten.
Beispielkonfiguration für Claude Desktop:
JSON
{
"mcpServers": {
"elastic": {
"command": "npx",
"args": [
"-y",
"@elastic/mcp-server-elasticsearch",
"--hosted-url",
"https://YOUR_KIBANA_URL/api/agent_builder/mcp"
],
"env": {
"ES_API_KEY": "YOUR_ELASTIC_API_KEY"
}
}
}
}
Wenn Sie die gehostete Version verwenden, nutzen Sie die nativen Sicherheitsschichten von Elastic und stellen Sie sicher, dass Ihre kontextbezogenen Agenten rund um die Uhr Zugriff auf Ihre Daten haben, ohne dass eine lokale Prozessverwaltung erforderlich ist.
Sprechen Sie mit uns über MCP und KI
Mit Elastic tiefer in die Entwicklung eintauchen
Bleiben Sie über alles, was mit KI und intelligenten Suchanwendungen zu tun hat, auf dem Laufenden. Erkunden Sie unsere Ressourcen, um mehr über das Entwickeln mit Elastic zu erfahren.
- LLM-Funktionen mit Elasticsearch für intelligente Abfrageumwandlung
- KI-Agenten und das Elastic AI SDK für Python
- Modellkontextprotokoll für Elasticsearch
Entwickeln Sie jetzt los mit dem kostenlosen, praktischen Workshop: Einführung in MCP mit Elasticsearch MCP Server.