Logstash Persistent Queue
In Logstash 5.1, Persistent Queue was introduced as a beta feature, adding disk-based resiliency to Logstash pipelines. In Logstash 5.4 it was officially promoted to General Availability as a production-ready alternative to the in-memory queue. This blog post aims to explain how its performance- and risk-characteristics differ from the default in-memory queue. Additional info on PQs is available in the documentation.
NOTE: In subsequent Logstash releases, the PQ has seen a number of reliability and performance improvements; please be sure to use the latest 6.x or 5.6.x release available to improve your experience.
Design
What is PQ
By default, Logstash uses in-memory queuing between the input and filter+output pipeline stages. This allows it to absorb small spikes in load without holding up the connections that are pushing events into Logstash, but the buffer is limited to memory capacity. If Logstash experiences a failure, the in-flight and in-memory data being processed will be lost.
In order to provide a buffer that is not limited to memory capacity and protects against data loss during abnormal termination, Logstash introduced the persistent queue feature. It stores input data on disk as an adaptive buffer, and uses pipeline acknowledgement back to the persistent queue upon processing completion. Any unacknowledged data (not fully processed and outputted) will be replayed upon restarting Logstash.
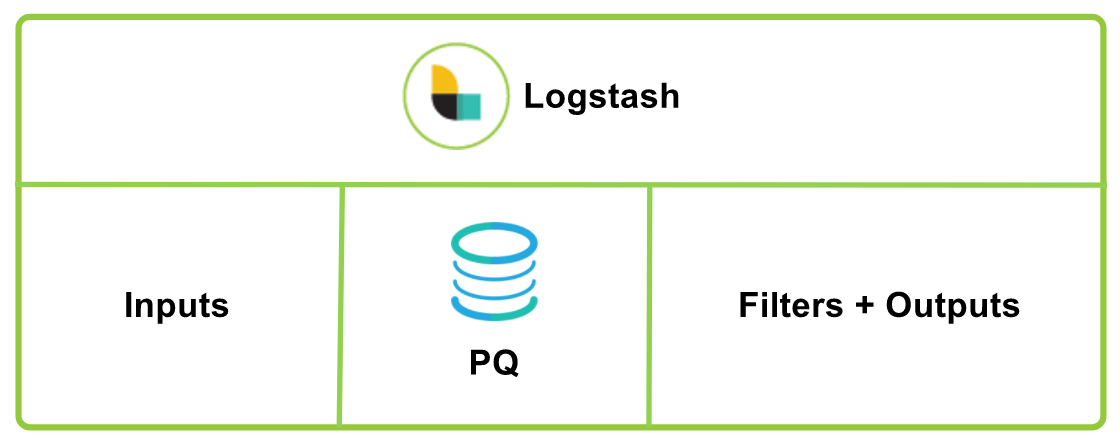
Initial design goals
- At-Least-Once delivery: The primary goal of the PQ design is to avoid data loss in case of abnormal failures and aim at providing At-Least-Once delivery guarantees. At-Least-Once delivery means that upon a failure, any unacknowledged data will be replayed when restarting Logstash. Depending on the failure conditions, At-Least-Once also means that already processed but unacknowledged data could be replayed and result in duplicate processing. This is the tradeoff of At-Least-Once; to aim for no-data-loss upon failures at the possible cost of having duplicate data. For more information about handing duplicates, see Suyog Rao's blog post.
- Spooling: The PQ can also grow in size on disk and help handle data ingestion spikes or output slowdowns without applying back-pressure on the inputs. In both these cases, the input or ingestion side processes faster than the filtering and output side of Logstash. Using the PQ, the incoming data will be buffered locally on disk until the filtering and output stages are able to catch up. For existing users using an external queuing layer for handling throughput spikes and mitigating backpressure, PQ is now capable of satisfying these requirements natively. Therefore, users can elect to remove this external queuing layer with the benefit of simplifying overall ingestion architectures. Below is an example of a logging architecture with Logstash and PQ; for additional deployment and scaling guidance, please consult the documentation.
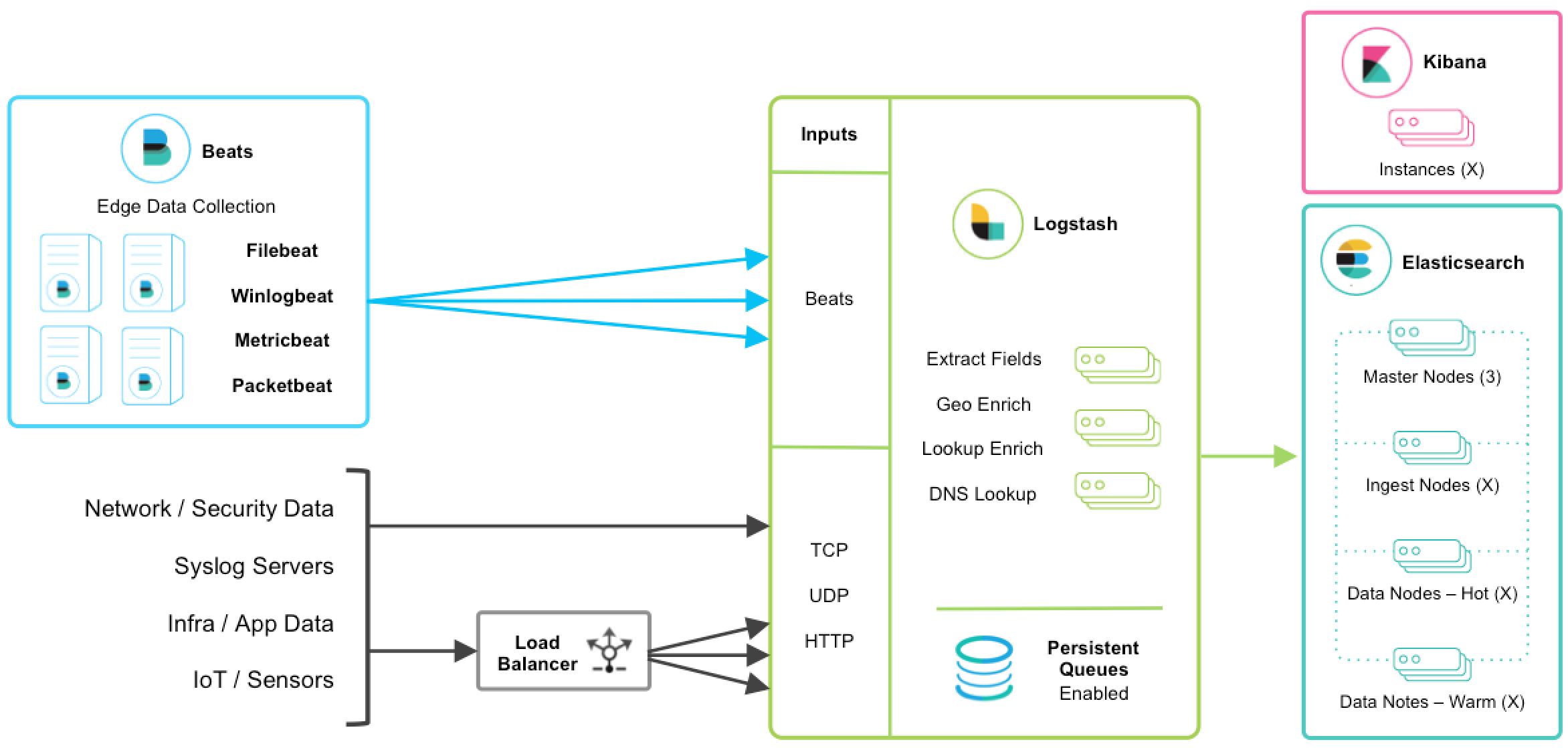
Resiliency and Durability
Failure Scenarios
There are 3 types of failure that can affect Logstash.
- Application / process level crash / interrupted shutdown. This is the most common cause of potential data loss that PQ helps solve. This happens when Logstash crashes with an exception or is killed at the process level or is generally interrupted in a way which prevents a safe shutdown. This would typically result in data loss when using in-memory queuing. With PQ, no data will be lost, regardless of the durability setting (see the queue.checkpoint.writes setting) and any unacknowledged data will be replayed upon restarting Logstash.
- OS level crash: kernel panic or machine restart. Using the PQ default settings, there is a possibility for losing data which was not safely written to disk (fsync) between the last fsync and the OS level crash. It is possible to change this behaviour and configure PQ for maximum durability where every incoming event will be force written to disk (fsync). see the Durability section and the queue.checkpoint.writes setting.
- Storage hardware failure. PQ does not provide replication to help with storage hardware failures. The only way to prevent data loss upon disk failure is to use external replication technology like RAID or an equivalent redundant disk option in cloud environments.
Durability
PQ uses page files of size queue.page_capacity (by default 250mb) to write the input data. The latest page is called the head page and is where the data is written in an append-only way. When the head page reaches queue.page_capacity it becomes a tail page which is immutable and a new head page is created to write new data.The durability characteristic of the head page is controlled using the queue.checkpoint.writes setting. By default, PQ will force write data to disk at every 1024 received input events to reduce potential data loss upon OS level crash. Note that application and process level crashes or interrupted shutdowns should never result in data loss, regardless of the queue.checkpoint.writes setting. If you want to protect against potential data loss for OS level crash you can set PQ for maximum durability using the queue.checkpoint.writes:1 setting, but note that this will result in a significant IO performance reduction.
Performance
Because the PQ writes all events to disk and keeps files on disk updatated with checkpoints, it's important to note that the performance profile is quite different than that of the memory queue; some pipeline configurations will see negligible performance impact while others will be greatly affected, so it's important to validate the trade-offs with your specific data before enabling the PQ in production.
The primary goal for these benchmarks is to show the impact of PQ on Logstash performance running on server-class high performance hardware using the default settings which we believe should be reasonable defaults for a majority of users. Obviously there are many tuning knobs in Logstash which can directly impact its performance so these benchmarks will vary depending on your specific configuration, settings and the hardware you run on.
Persistent queue performance impact was measured using a custom script which polls and collects the Logstash stats API every second. The tests below were performed on Logstash 5.4.1 on an AWS EC2 c3.4xlarge instance using a typical Apache access logs processing configuration and a large enough sample logs file. The total runtime was 5 minutes with the first 30 seconds on each test ignored to account for the JVM warmup.
The stats collecting script, config and logs file can be found on Github so you can run the benchmarks on your hardware and with your configuration and data.
Apache configuration
input {
stdin {
codec => line
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
useragent {
source => "agent"
target => "ua"
}
}
output {
stdout { codec => dots }
}
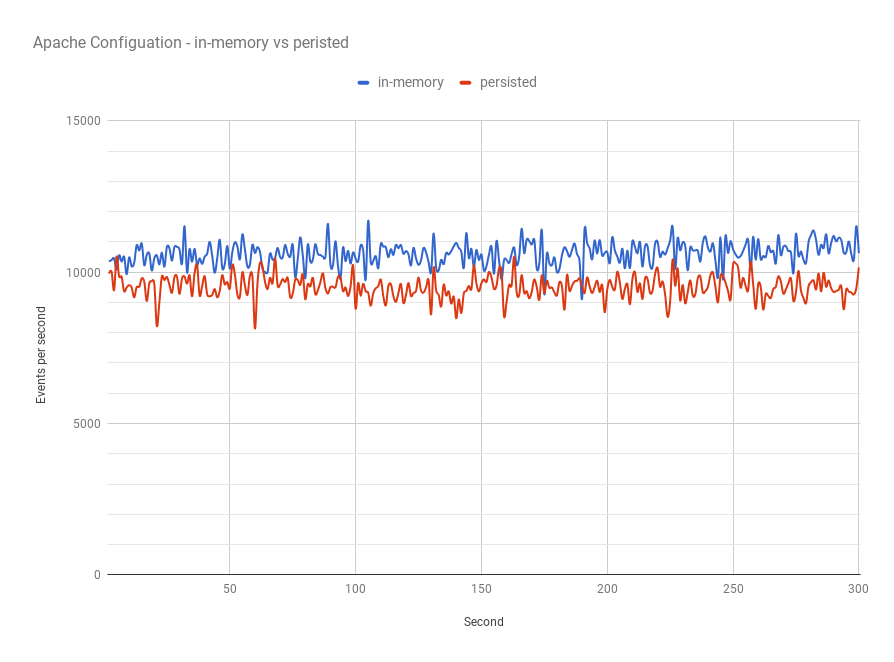
The benchmarks results show an approximately 10% performance penalty when using persistent queue in this configuration. Using in-memory queuing yielded an average of approximately 10600 events per seconds while using persistent queue approximately 9500 events per second.
Usage
Settings
queue.type: Specify persisted to enable persistent queues. By default, persistent queues are disabled (default: queue.type: memory).
path.queue: The directory path where the data files will be stored. By default, the files are stored in path.data/queue.
queue.page_capacity: The maximum size of a queue page in bytes. The queue data consists of append-only files called "pages". The default size is 250mb.
queue.max_events: The maximum number of events that are allowed in the queue. The default is 0 (unlimited).
queue.max_bytes: The total capacity of the queue in number of bytes. The default is 1024mb (1gb). Make sure the capacity of your disk drive is greater than the value you specify here.
If both queue.max_events and queue.max_bytes are specified, Logstash uses whichever criteria is reached first.
Checkpoints
There are two other settings that relate to checkpointing. For background, each data page file has an associated checkpoint file. A checkpoint file contains meta information about its associated data page.
A checkpoint file associated with an immutable and read-only tail page will be updated in relation with the action of acking fully read and processed events from that page.
A checkpoint file associated with the head page receiving writes will be updated in relation with the action of writing new events. When the head page is also the page being read from, its checkpoint will also be updated in relation with the action of acking fully read and processed events. Updating the checkpoint of the head page normally forces safely writing data to disk (fsync).
queue.checkpoint.acks: Logstash will update checkpoint(s) after this many events are acknowledged. Default is 1024, 0 for unlimited
queue.checkpoint.writes: Logstash will update the head page checkpoint after this many writes into the queue. Default is 1024, 0 for unlimited
Changing these two settings will impact performance. The default values offers a good reliability vs performance tradeoff.
Changing queue.checkpoint.acks will increase or decrease the potential number of duplicate events replayed when restarting after an abnormal failure.
Changing queue.checkpoint.writes will increase or decrease the potential number of lost events in the case of an OS level crash: kernel panic or machine restart. See Failure Scenarios section.
Stopping and starting LS
When Logstash is running, it will enter a normal shutdown sequence if it receives a SIGINT (like a Control-C in the running terminal) or SIGTERM signals. When Logstash shuts down normally with persistent queue enabled, the inputs will be closed and only the current in-flight data will complete its processing (filter+output stage). All accumulated and unprocessed data will be kept on disk in the persistent queue and Logstash will exit. No data will be lost and no data duplication will happen in a normal shutdown when restarting Logstash.
If Logstash is abnormally terminated by crashing or by being terminated with a SIGKILL for example, all persisted and unacknowledged in-flight data will be replayed when restarting Logstash. Since an abnormal termination can happen at any time, any partially processed data but yet unacknowledged will be replayed and reprocessed when Logstash restarts, potentially generating duplicate data.
Conclusion
We hope you find the Persistent Queue feature useful and get to use it. As always, your feedback is very important to us. You can provide us feedback on GitHub or open a discussion thread on our forum.