Elastic: Die Entwicklung von Elastic Cloud Serverless
Zustandslose Architektur, die sich unabhängig von Ihren Daten-, Nutzungs- und Leistungsanforderungen automatisch skaliert


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Wie machen Sie ein zustandsbehaftetes, leistungskritisches System wie Elasticsearch serverlos?
Bei Elastic haben wir alles neu konzipiert – vom Speicher bis zur Orchestrierung –, um eine wirklich serverlose Elastic Platform zu erstellen, der die Kunden vertrauen können.
Elastic Cloud Serverless ist eine vollständig verwaltete, cloudnative Platform, die Entwicklern die Leistungsfähigkeit des Elastic Stack ohne den operativen Aufwand zur Verfügung stellt. In diesem Blogbeitrag erklären wir, warum wir es entwickelt haben, wie wir die Architektur angegangen sind und was wir dabei gelernt haben.
Warum serverless?
Im Laufe der Jahre haben sich die Kundenerwartungen dramatisch verändert. Die Nutzer möchten sich nicht mehr mit der Komplexität des Infrastrukturmanagements wie Dimensionierung, Monitoring und Skalierung befassen. Stattdessen suchen sie nach einer nahtlosen Erfahrung, bei der sie sich ausschließlich auf ihre Arbeitslasten konzentrieren können. Diese sich entwickelnde Nachfrage hat uns dazu veranlasst, eine Lösung zu entwickeln, die den Betriebsaufwand reduziert, ein reibungsloses SaaS-Erlebnis bietet und ein Pay-per-Use-Preismodell einführt. Indem wir die Notwendigkeit für Kunden beseitigen, Ressourcen manuell bereitzustellen und zu pflegen, haben wir eine Platform geschaffen, die dynamisch je nach Bedarf skaliert und gleichzeitig die Effizienz optimiert.
Meilensteine
Elastic Cloud Serverless expandiert schnell, um der Kundennachfrage gerecht zu werden und hat die allgemeine Verfügbarkeit (GA) auf AWS im Dezember 2024, GCP im April 2025 und Azure im Juni 2025 erreicht. Seitdem haben wir auf vier Regionen auf AWS, drei Regionen auf GCP und eine Region auf Azure erweitert, wobei zusätzliche Regionen für alle drei Cloud-Service-Provider (CSPs) geplant sind.
Architektur neu denken: Von zustandsbehaftet zu zustandslos
Elastic Cloud Hosted (ECH) wurde ursprünglich als zustandsbehaftetes System entwickelt, das auf lokalem NVMe-basiertem Speicher oder verwalteten Festplatten beruht, um die Datenbeständigkeit sicherzustellen. Als Elastic Cloud weltweit skalierte, sahen wir eine Gelegenheit, unsere Architektur weiterzuentwickeln, um die betriebliche Effizienz und das langfristige Wachstum besser zu unterstützen. Unser gehosteter Ansatz zur Verwaltung des persistenten Zustands in verteilten Umgebungen erwies sich als effektiv, führte jedoch zu zusätzlicher betrieblicher Komplexität in Bezug auf den Austausch von Knoten, die Wartung, die Sicherstellung von Redundanz in Verfügbarkeitszonen und die Skalierung rechenintensiver Workloads wie Indexieren und Suchen.
Wir haben uns entschieden, unsere Systemarchitektur weiterzuentwickeln, indem wir einen zustandslosen Ansatz verfolgen. Die entscheidende Veränderung bestand darin, den persistenten Speicher von Rechenknoten in cloudnative Objektspeicher auszulagern. Dies brachte mehrere Vorteile: Reduzierung des für das Indexieren erforderlichen Infrastrukturaufwands, Ermöglichung der Trennung von Suchen und Indexierung, Beseitigung der Notwendigkeit der Replikation und Verbesserung der Datenbeständigkeit durch Nutzung der integrierten Redundanzmechanismen der CSPs.
Der Wechsel zum Objektspeicher
Eine der größten Veränderungen in unserer Architektur war die Nutzung von cloudnativem Objektspeicher als primäre Datenablage. ECH wurde entwickelt, um Daten auf lokalen NVMe-SSDs oder verwalteten SSD-Festplatten zu speichern. Mit dem Wachstum der Datenmengen wuchsen jedoch auch die Herausforderungen, den Speicher effizient zu skalieren. Anschließend führten wir durchsuchbare Snapshots in ECH ein, die es uns ermöglichten, Daten direkt aus Objektspeichern zu suchen und so die Speicherkosten erheblich zu senken, aber wir mussten noch weiter gehen.
Eine der wichtigsten Herausforderungen bestand darin, festzustellen, ob Objektspeicher hohe Ingestion-Arbeitslasten bewältigen können, während sie das Leistungsniveau beibehalten, das Elasticsearch-Nutzer erwarten. Durch rigorose Tests und Implementierung konnten wir bestätigen, dass Objektspeicher den Anforderungen des groß angelegten Indexierens gerecht werden können. Der Wechsel zum Objektspeicher eliminierte die Notwendigkeit des Indexierens und der Replikation, reduzierte die Infrastrukturanforderungen und bot durch die Replikation von Daten über Verfügbarkeitszonen hinweg eine verbesserte Haltbarkeit, wodurch hohe Verfügbarkeit und Ausfallsicherheit sichergestellt wurden.
Das untenstehende Diagramm veranschaulicht die neue „zustandslose“ Architektur im Vergleich zur bestehenden „ECH“-Architektur:

Optimierung der Objekteffizienz speichern
Die Umstellung auf Objektspeicher brachte zwar betriebliche und dauerhafte Vorteile, führte jedoch zu einer neuen Herausforderung: den Kosten für die Objektspeicher-API. Schreibvorgänge in Elasticsearch – insbesondere Translog-Aktualisierungen und -Auffrischungen – werden direkt in Objektspeicher-API-Aufrufe übersetzt, die schnell und unvorhersehbar ansteigen können, insbesondere bei hoher Ingestion oder hohen Aktualisierungsraten.
Um dieses Problem zu lösen, haben wir einen Translog-Puffermechanismus pro Node implementiert, der Schreibvorgänge zusammenfasst, bevor sie in den Objektspeicher übertragen werden, wodurch die Schreibverstärkung erheblich reduziert wird. Außerdem haben wir die Auffrischungen von den Schreibvorgängen im Objektspeicher entkoppelt und stattdessen aufgefrischte Segmente direkt an die Such-Nodes gesendet, während die Persistenz des Objektspeichers aufgeschoben wurde. Diese architektonische Verfeinerung reduzierte die mit der Aktualisierung verbundenen Objektspeicher-API-Aufrufe um zwei Größenordnungen, ohne die Haltbarkeit der Daten zu beeinträchtigen. Weitere Einzelheiten finden Sie in diesem Blogbeitrag.
Kubernetes für die Orchestrierung wählen
ECH nutzt einen intern entwickelten Container-Orchestrator, der auch Elastic Cloud Enterprise (ECE) betreibt. Da die Entwicklung von ECE begann, bevor Kubernetes (K8s) existierte, hatten wir die Wahl, ECE für Serverless zu erweitern oder K8s für Serverless zu nutzen. Angesichts der rasanten branchenweiten Verbreitung von Kubernetes und des wachsenden Ökosystems haben wir uns entschieden, verwaltete Kubernetes-Dienste über CSPs hinweg in Elastic Cloud Serverless zu übernehmen, wo es mit unseren Betriebs- und Skalierungszielen übereinstimmt.
Durch die Einführung von Kubernetes haben wir die betriebliche Komplexität reduziert, die APIs für eine verbesserte Skalierbarkeit standardisiert und Elastic Cloud für langfristige Innovation positioniert. Kubernetes ermöglichte es uns, uns auf höherwertige Features zu konzentrieren, anstatt die Container-Orchestrierung neu zu erfinden.
CSP-verwaltetes vs. selbstverwaltetes Kubernetes
Bei der Umstellung auf Kubernetes standen wir vor der Entscheidung, ob wir Kubernetes-Cluster selbst verwalten oder verwaltete Kubernetes-Services von CSPs nutzen sollten. Die Implementierungen von Kubernetes variieren je nach CSP erheblich, aber um unsere Bereitstellungszeitpläne zu beschleunigen und den Betriebsaufwand zu reduzieren, haben wir uns für CSP-verwaltete Kubernetes-Services auf AWS, GCP und Azure entschieden. Dieser Ansatz ermöglichte es uns, uns auf die Entwicklung von Anwendungen und die Übernahme von Best Practices der Branche zu konzentrieren, anstatt uns mit den Feinheiten des Kubernetes-Cluster-Managements auseinanderzusetzen.
Zu unseren wichtigsten Anforderungen gehörte die Fähigkeit, Kubernetes-Cluster konsistent über mehrere CSPs hinweg bereitzustellen und zu verwalten; eine Cloud-agnostische API für die Verwaltung von Rechenleistung, Speicher und Datenbanken; und vereinfachte Abläufe, die kosteneffizient waren. Darüber hinaus konnten wir durch die Entscheidung für CSP-verwaltetes Kubernetes einen Upstream-Beitrag zu Open-Source-Projekten wie Crossplane leisten, das gesamte Kubernetes-Ökosystem verbessern und gleichzeitig von den sich entwickelnden Funktionen profitieren.
Netzwerkprobleme und die Wahl von Cilium
Der Betrieb von Kubernetes im großen Maßstab mit Zehntausenden von Pods pro Kubernetes-Cluster erfordert eine Netzwerklösung, die cloudunabhängig ist, hohe Leistung bei minimaler Latenz bietet und fortschrittliche Sicherheitsrichtlinien unterstützt. Wir haben Cilium, eine moderne Lösung auf eBPF-Basis, ausgewählt, um diese Anforderungen zu erfüllen. Ursprünglich beabsichtigten wir, eine einheitliche, selbstverwaltete Cilium-Lösung für alle CSPs zu implementieren. Unterschiede in den Cloud-Implementierungen führten jedoch zu einem hybriden Ansatz, bei dem wir CSP-eigene Cilium-Lösungen, wo verfügbar, einsetzten und gleichzeitig ein selbstverwaltetes Deployment auf AWS pflegten. Diese Flexibilität stellte sicher, dass wir unsere Leistungs- und Sicherheitsanforderungen ohne unnötige Komplexität erfüllen konnten.
Eingehender Traffic
Für den Eingangsverkehr haben wir uns entschieden, unseren bestehenden, bewährten Proxy von ECH anzupassen und weiter zu verwenden. Bei der Bewertung ging es nicht nur darum, ob wir den Proxy durch eine Standardlösung ersetzen könnten, sondern ob wir das sollten.
Ein standardmäßiger Reverse Proxy würde zwar grundlegende Funktionen bieten, ihm würden jedoch die Unterscheidungsmerkmale fehlen, die der ECH-Proxy bereits beherrscht. Wir hätten Erweiterungen für Filter für eingehenden Datenverkehr, Unterstützung für AWS PrivateLink und Google Cloud Private Service Connect sowie FIPS-konforme TLS-Terminierung entwickeln müssen. Der vorhandene Proxy hat auch bereits alle relevanten Compliance-Audits und Penetrationstests bestanden.
Der Beginn mit einer neuen Lösung hätte erheblichen Aufwand erfordert, ohne zusätzlichen Kundennutzen zu bieten. Die Anpassung unseres Proxys für Kubernetes bestand hauptsächlich darin, die Verteilung der Bekanntheit von Service-Endpoints zu aktualisieren, während die bewährte Kernfunktionalität unverändert blieb. Dieser Ansatz bietet mehrere Vorteile:
Es wird sichergestellt, dass das für Kunden sichtbare Verhalten zwischen ECH und Kubernetes konsistent bleibt.
Teams können mit einer vertrauten, gut verständlichen Codebasis effizienter arbeiten, insbesondere bei der Implementierung neuer Features, die in einer Standardlösung Skripting oder Erweiterungen erfordern würden.
Wir können sowohl unsere ECH- als auch unsere Kubernetes-Plattformen mit einer einzigen Codebasis weiterentwickeln; daher führen Verbesserungen in einer Umgebung zu Verbesserungen in der anderen.
Die Support-Teams können ihr vorhandenes Wissen nutzen, um die Lernkurve für die neue Plattform zu verkürzen.
Kubernetes-Bereitstellungsschicht
Nachdem wir Kubernetes für Elastic Cloud Serverless gewählt hatten, entschieden wir uns für Crossplane als Infrastrukturmanagement-Tool. Crossplane ist ein Open-Source-Projekt, das die Kubernetes-API erweitert, um die Bereitstellung und Verwaltung von Cloud-Infrastrukturen und -Diensten mit Kubernetes-nativen Tools und Praktiken zu ermöglichen. Es erlaubt Nutzern, Cloud-Ressourcen über mehrere CSPs hinweg innerhalb eines Kubernetes-Clusters bereitzustellen, zu verwalten und zu orchestrieren. Dies wird durch die Nutzung von Custom Resource Definitions (CRDs) erreicht, um Cloud-Ressourcen und Controller zu definieren, um den gewünschten Zustand, der in Kubernetes Manifesten angegeben ist, mit dem tatsächlichen Zustand von Cloud-Ressourcen über mehrere CSPs hinweg abzugleichen. Durch die Nutzung der deklarativen Konfigurations- und Steuerungsmechanismen von Kubernetes bietet es eine konsistente und skalierbare Möglichkeit, Infrastruktur als Code zu verwalten.
Crossplane ermöglicht die Verwaltung und Bereitstellung von Infrastruktur mit denselben Tools und Methoden, die für das Deployment von Diensten verwendet werden. Dies umfasst die Nutzung von Kubernetes-Ressourcen, einer konsistenten GitOps-Architektur und einheitlichen Beobachtbarkeitstools. Darüber hinaus können Entwickler eine vollständige Kubernetes-basierte Entwicklungsumgebung einrichten, einschließlich der zugehörigen Infrastruktur, die Produktionsumgebungen nachbildet. Dies wird erreicht, indem Sie einfach eine Kubernetes-Ressource erstellen, da beide Umgebungen aus demselben zugrunde liegenden Code generiert werden.
Verwaltung der Infrastruktur
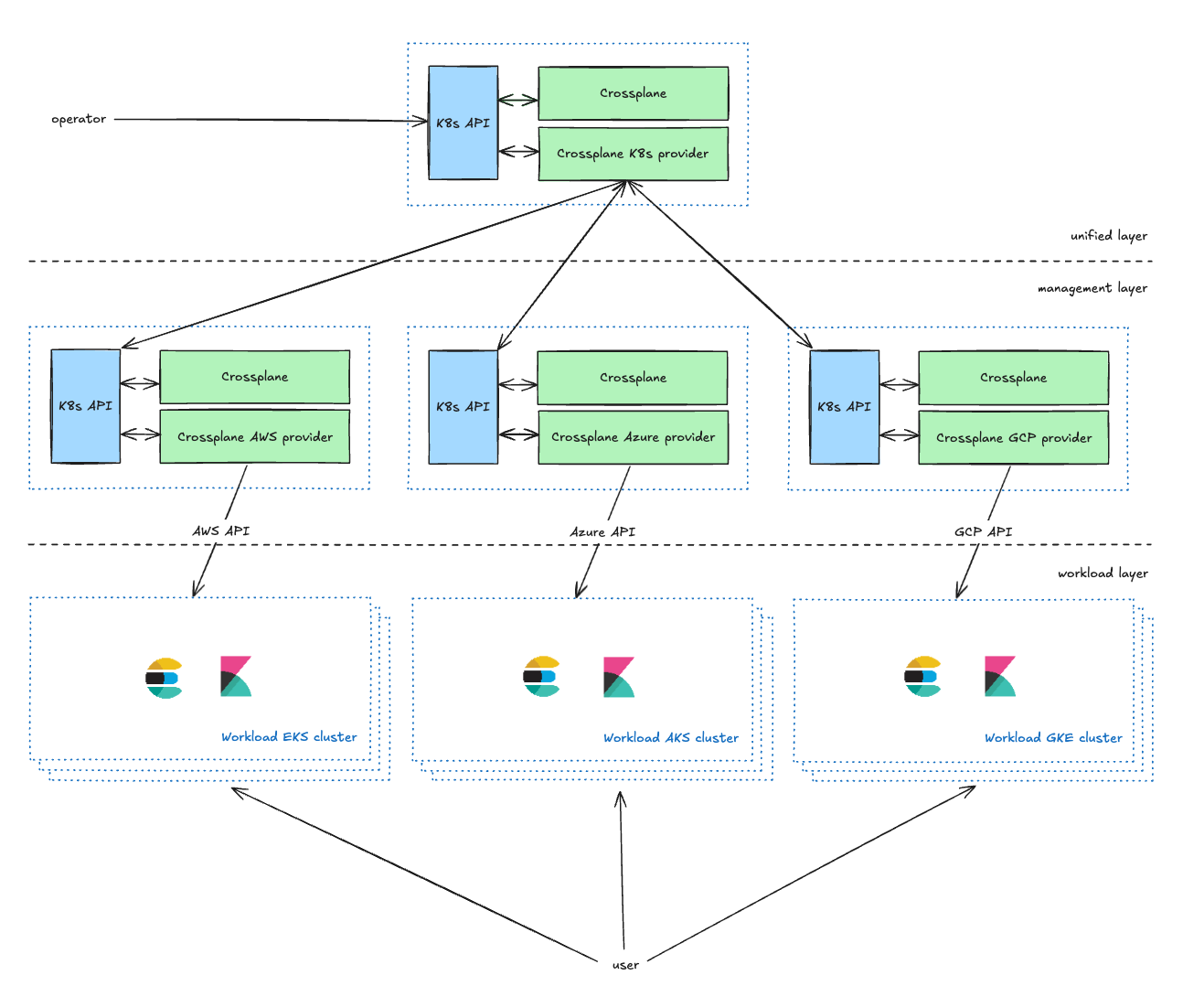
Die Unified-Schicht ist die betreiberorientierte Verwaltungsschicht, die Kubernetes-CRDs für Dienstinhaber bereitstellt, um ihre Kubernetes-Cluster zu verwalten. Sie können Parameter wie den CSP, die Region und den Typ definieren (im nächsten Abschnitt erläutert). Sie bereichert die Anfragen der Betreiber und leitet sie an die Verwaltungsschicht weiter.
Die Management-Schicht fungiert als Proxy zwischen der Unified-Schicht und den CSP-APIs, indem sie Anfragen von der Unified-Schicht in CSP-Ressourcenanfragen umwandelt und den Status zurück an die Unified-Schicht meldet.
In unserem aktuellen Setup pflegen wir zwei Management-Kubernetes-Cluster für jeden CSP in jeder Umgebung. Dieser Dual-Cluster-Ansatz dient in erster Linie zwei Hauptzwecken. Erstens ermöglicht er uns, potenzielle Skalierbarkeitsprobleme, die bei Crossplane auftreten können, effektiv zu lösen. Zweitens, und das ist noch wichtiger, ermöglicht er uns, einen der Cluster als Canary-Umgebung zu verwenden. Diese Canary-Bereitstellungsstrategie ermöglicht eine schrittweise Einführung unserer Änderungen, beginnend mit einer kleineren, kontrollierten Teilmenge jeder Umgebung, um das Risiko zu minimieren.
Die Workload-Schicht enthält alle Kubernetes-Workload-Cluster, die Anwendungen ausführen, mit denen Nutzer interagieren (Elasticsearch, Kibana, MIS usw.).
Verwaltung der Cloud-Kapazität: Vermeidung von „Kapazitätsengpass“-Fehlern
Eine gängige Annahme ist, dass die Cloud-Kapazität unendlich ist, aber in Wirklichkeit legen CSPs Beschränkungen auf, die zu „Kapazitätsengpass“-Fehlern führen können. Wenn ein Instanztyp nicht verfügbar ist, müssen wir es kontinuierlich erneut versuchen oder auf einen alternativen Instanztyp umsteigen.
Um dies in Elastic Cloud Serverless zu mildern, haben wir prioritätsbasierte Kapazitätspools implementiert, die es Workloads ermöglichen, bei Bedarf auf neue/andere Kapazitätspools umzusteigen. Darüber hinaus haben wir in eine proaktive Kapazitätsplanung investiert, bei der Rechenressourcen im Vorfeld von Nachfragespitzen reserviert werden. Diese Mechanismen gewährleisten eine hohe Verfügbarkeit und optimieren gleichzeitig die Ressourcenauslastung.
Auf dem Laufenden bleiben
Kubernetes-Cluster-Upgrades sind zeitaufwendig. Um dies zu optimieren, verwenden wir einen vollautomatischen End-to-End-Prozess, der nur bei Problemen, die nicht automatisch gelöst werden können, manuelle Eingriffe erfordert. Sobald die internen Tests abgeschlossen sind und eine neue Kubernetes-Version genehmigt ist, konfigurieren wir diese zentral. Ein automatisiertes System initiiert dann das Kubernetes-Steuerungsebenen-Upgrade für jeden Cluster mit kontrollierter Parallelität und einer bestimmten Reihenfolge. Anschließend führen benutzerdefinierte Kubernetes-Controller Blue-Green-Deployments durch, um die Knotenpools (Nodepools) zu aktualisieren. Trotz der Tatsache, dass Kunden-Pods während dieses Prozesses auf verschiedene Kubernetes-Nodes migrieren, bleiben die Projektverfügbarkeit und -leistung davon unberührt.
Ausfallsicherheit der Architektur
Wir verwenden eine zellbasierte Architektur, die es uns ermöglicht, sowohl skalierbare als auch belastbare Dienste anzubieten. Jeder Kubernetes-Cluster wird zusammen mit seiner peripheren Infrastruktur in einem separaten CSP-Konto bereitgestellt, um eine ordnungsgemäße Skalierung zu ermöglichen, ohne von CSP-Grenzwerten betroffen zu sein, und um maximale Sicherheit und Isolierung zu bieten. Einzelne Workloads, jede in einer separaten Zelle, verwalten bestimmte Aspekte des Systems. Diese Zellen arbeiten unabhängig voneinander und ermöglichen eine isolierte Skalierung und Verwaltung. Dieser modulare Aufbau minimiert die Reichweite von Ausfällen und ermöglicht eine gezielte Skalierung, wodurch systemweite Auswirkungen vermieden werden. Um die potenziellen Auswirkungen von Problemen weiter zu minimieren, setzen wir Canary-Bereitstellungen sowohl für unsere Anwendungen als auch für die zugrunde liegende Infrastruktur ein.
Steuerungs- vs. Datenebene: Das Push-Modell
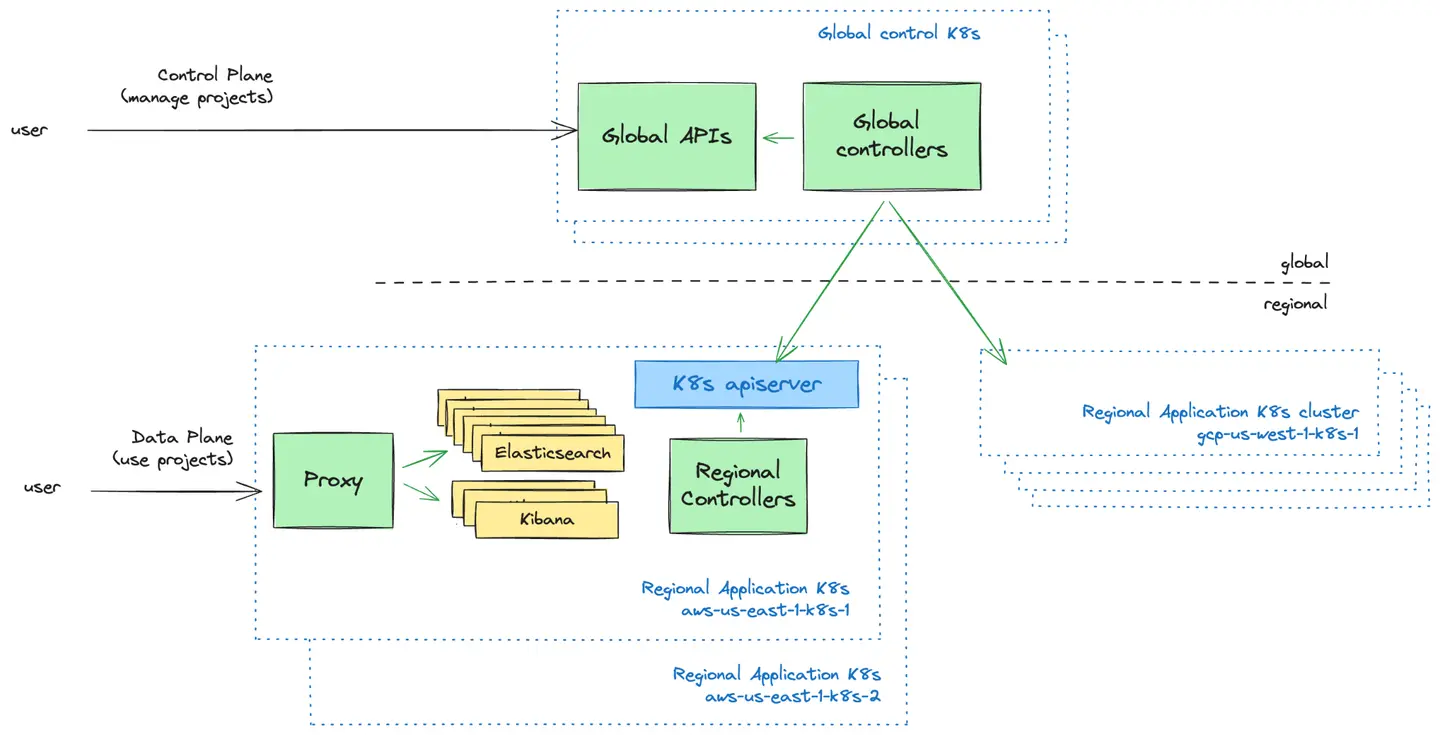
Die Steuerungsebene ist die nutzerorientierte Verwaltungsebene. Wir bieten Benutzeroberflächen und APIs an, mit denen Nutzer ihre Elastic Cloud Serverless-Projekte verwalten können. Hier können Nutzer neue Projekte erstellen, steuern, wer Zugriff auf ihre Projekte hat, und sich einen Überblick über ihre Projekte verschaffen.
Die Datenebene ist die Infrastrukturebene, die die Elastic Cloud Serverless-Projekte betreibt und mit der Nutzer interagieren, wenn sie ihre Projekte nutzen möchten.
Eine grundlegende Designentscheidung, der wir uns stellen mussten, war, wie die globale Steuerebene mit Kubernetes-Clustern in der Datenebene kommunizieren sollte. Wir haben zwei Modelle untersucht:
Push-Modell: Die Steuerungsebene überträgt Konfigurationen proaktiv an regionale Kubernetes-Cluster.
Pull Model: Regionale Kubernetes-Cluster rufen regelmäßig Konfigurationen von der Steuerungsebene ab.
Nach der Evaluierung beider Ansätze haben wir uns aufgrund der Einfachheit, des unidirektionalen Datenflusses und der Fähigkeit, Kubernetes-Cluster bei Ausfällen unabhängig von der Steuerungsebene zu betreiben, für das Push-Modell entschieden. Dieses Modell ermöglichte es uns, eine einfache Planungslogik zu pflegen und gleichzeitig den operativen Overhead und die Komplexität der Fehlerbehebung zu reduzieren.
Autoscaling: Über horizontales und vertikales Skalieren hinaus
Um ein wirklich serverloses Erlebnis zu bieten, benötigten wir einen intelligenten Mechanismus zur automatischen Skalierung, der die Ressourcen dynamisch an die Anforderungen der Arbeitslast anpasst. Unsere Reise begann mit einfachem horizontalen Skalieren, aber wir erkannten schnell, dass verschiedene Dienste einzigartige Skalierungsanforderungen hatten. Einige erforderten zusätzliche Rechenressourcen, während andere eine höhere Speicherzuweisung verlangten.
Wir haben unseren Ansatz weiterentwickelt, indem wir benutzerdefinierte Autoscaling-Controller entwickelt haben, die arbeitslastspezifische Metriken in Echtzeit analysieren und eine dynamische Skalierung ermöglichen, die sowohl reaktionsschnell als auch ressourceneffizient ist. Dadurch können wir sowohl das Indexieren als auch die Suchoperationen der Elasticsearch-Tier nahtlos skalieren, ohne Elasticsearch zu überdimensionieren. Diese Strategie ermöglicht die Nutzung der mehrdimensionalen Pod-Autoskalierung, die eine horizontale und vertikale Skalierung von Arbeitslasten auf der Grundlage von CPU, Arbeitsspeicher und benutzerdefinierten, von der Arbeitslast generierten Metriken ermöglicht.
Für unsere Elasticsearch-Workloads verwenden wir eine serverlose Elasticsearch-API, die bestimmte Schlüsselmetriken über den Cluster zurückgibt. So funktioniert es: Empfehlungsgeber schlagen die erforderlichen Rechenressourcen (Replikate, Arbeitsspeicher und CPU) sowie den Speicherplatz für eine bestimmte Ebene vor. Diese Empfehlungen werden dann von Mappern in konkrete Rechen- und Speicherkonfigurationen umgewandelt, die auf Container anwendbar sind. Um schnelle Skalierungsschwankungen zu verhindern, filtern Stabilisatoren diese Empfehlungen. Dann kommen Begrenzungen ins Spiel, die sowohl minimale als auch maximale Ressourcenbeschränkungen durchsetzen. Der Ausgang des Limiters wird verwendet, um das Kubernetes-Deployment zu patchen, nachdem einige optionale Beschränkungsrichtlinien berücksichtigt wurden.
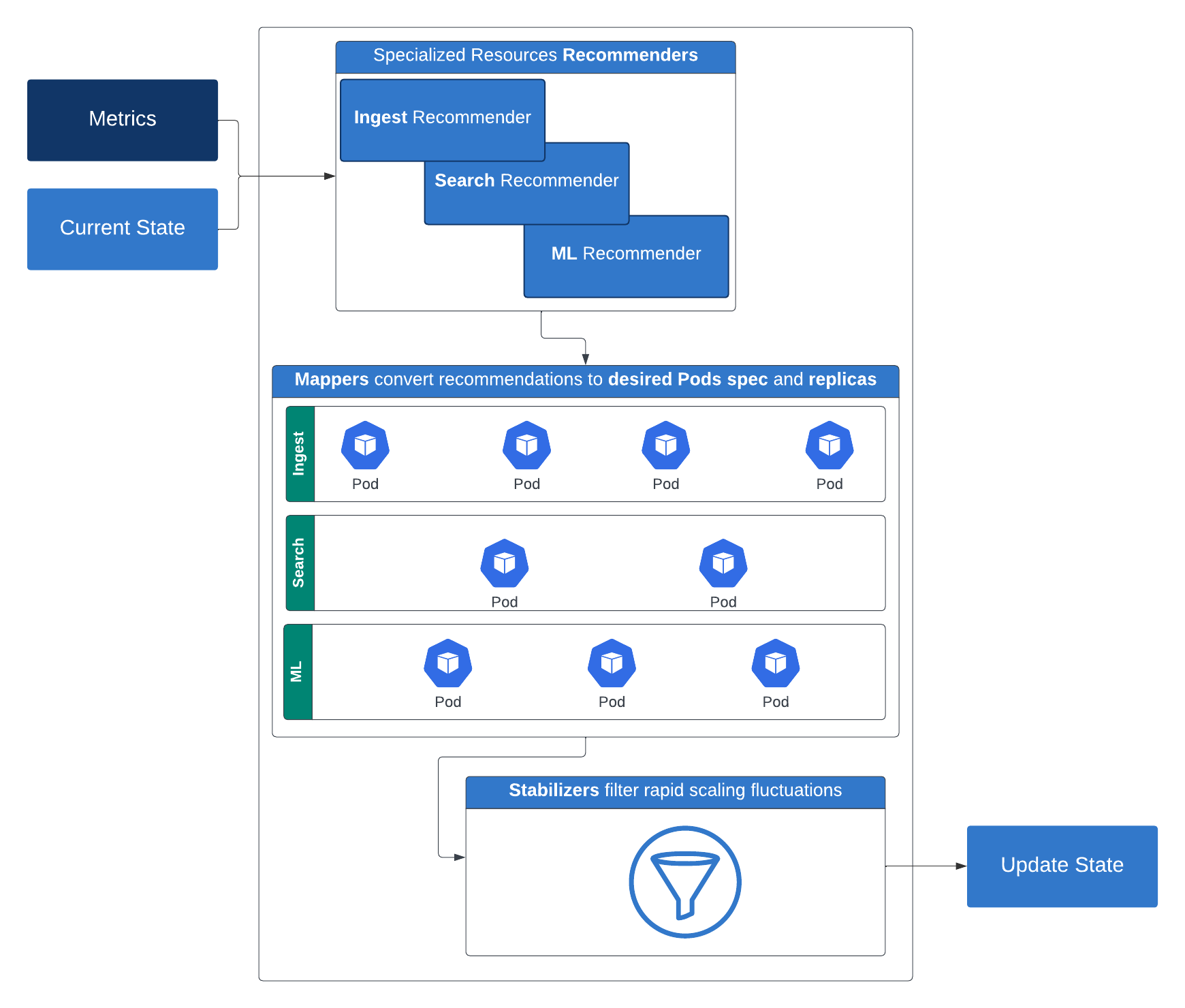
Diese mehrschichtige, intelligente Skalierungsstrategie gewährleistet Leistung und Effizienz bei unterschiedlichen Arbeitslasten und ist ein großer Schritt in Richtung einer wirklich serverlosen
Plattform. Elastic Cloud Serverless führt nuancierte Autoskalierungsfunktionen ein, die speziell auf die Suchschicht zugeschnitten sind und Inputs wie verstärkte Datenfenster, Suchleistungseinstellungen und Suchlastmesswerte (einschließlich Thread Pool-Last und Warteschlangenlast) nutzen. Diese Signale arbeiten zusammen, um Basiskonfigurationen zu definieren und dynamische Skalierungsentscheidungen basierend auf den Suchnutzungsmustern der Kunden auszulösen. Einen tieferen Einblick in die Autoskalierung der Suchschicht erhalten Sie in diesem Blogbeitrag. Um mehr darüber zu erfahren, wie die Autoskalierung der Indizierungsebene funktioniert, lesen Sie diesen Blogbeitrag.
Erstellung eines flexiblen Preismodells
Ein Schlüsselprinzip des serverlosen Computings besteht darin, die Kosten an die tatsächliche Nutzung anzupassen. Wir wollten ein Preismodell, das einfach, flexibel und transparent ist. Nach der Evaluierung verschiedener Ansätze haben wir ein Modell entwickelt, das unterschiedliche Arbeitslasten über unsere Kernlösungen hinweg ausgleicht:
Observability und Security: Die Abrechnung erfolgt auf der Grundlage der aufgenommenen und gespeicherten Daten mit einem gestaffelten Preismodell
Elasticsearch (Search): Die Preisgestaltung basiert auf virtuellen Recheneinheiten, einschließlich Ingest, Suche, Machine Learning und Datenaufbewahrung
Dieser Ansatz bietet Kunden eine Preisgestaltung nach Nutzung, was mehr Flexibilität und Kostenvorhersehbarkeit bietet.
Wir wussten, dass wir, um dieses Preismodell zu implementieren (das während der Entwicklungsphase viele Iterationen durchlief), eine skalierbare und flexible Architektur benötigten. Letztendlich haben wir eine Pipeline entwickelt, die ein verteiltes Eigentümermodell unterstützt, wobei verschiedene Teams für unterschiedliche Komponenten des End-to-End-Prozesses verantwortlich sind. Im Folgenden beschreiben wir die beiden Hauptsegmente dieser Pipeline: die Erfassung der gemessenen Nutzung über die Nutzungspipeline und die Abrechnungsberechnungen über die Abrechnungspipeline.
Nutzungspipeline
Nutzerorientierte Komponenten wie Elasticsearch und Kibana senden gemessene Daten an den Nutzungs-API-Service, der in jedem Workload-Cluster ausgeführt wird. Dieser Dienst reichert die Daten an und stellt sie dann in eine Warteschlange. Der Übermittler-Dienst ruft diese Daten dann aus der Warteschlange ab und leitet sie an den Objektspeicher weiter. Diese entkoppelte Pipeline ist notwendig, um die Pipeline beim Versenden von Daten über Regionen und CSPs hinweg widerstandsfähig zu machen, da wir der Bereitstellung Vorrang vor der Latenz einräumen. Sobald die Daten den Objektspeicher erreicht haben, stehen sie anderen Prozessen schreibgeschützt für weitere Transformationen oder Aggregationen zur Verfügung (z. B. für die Abrechnung oder Analysen).
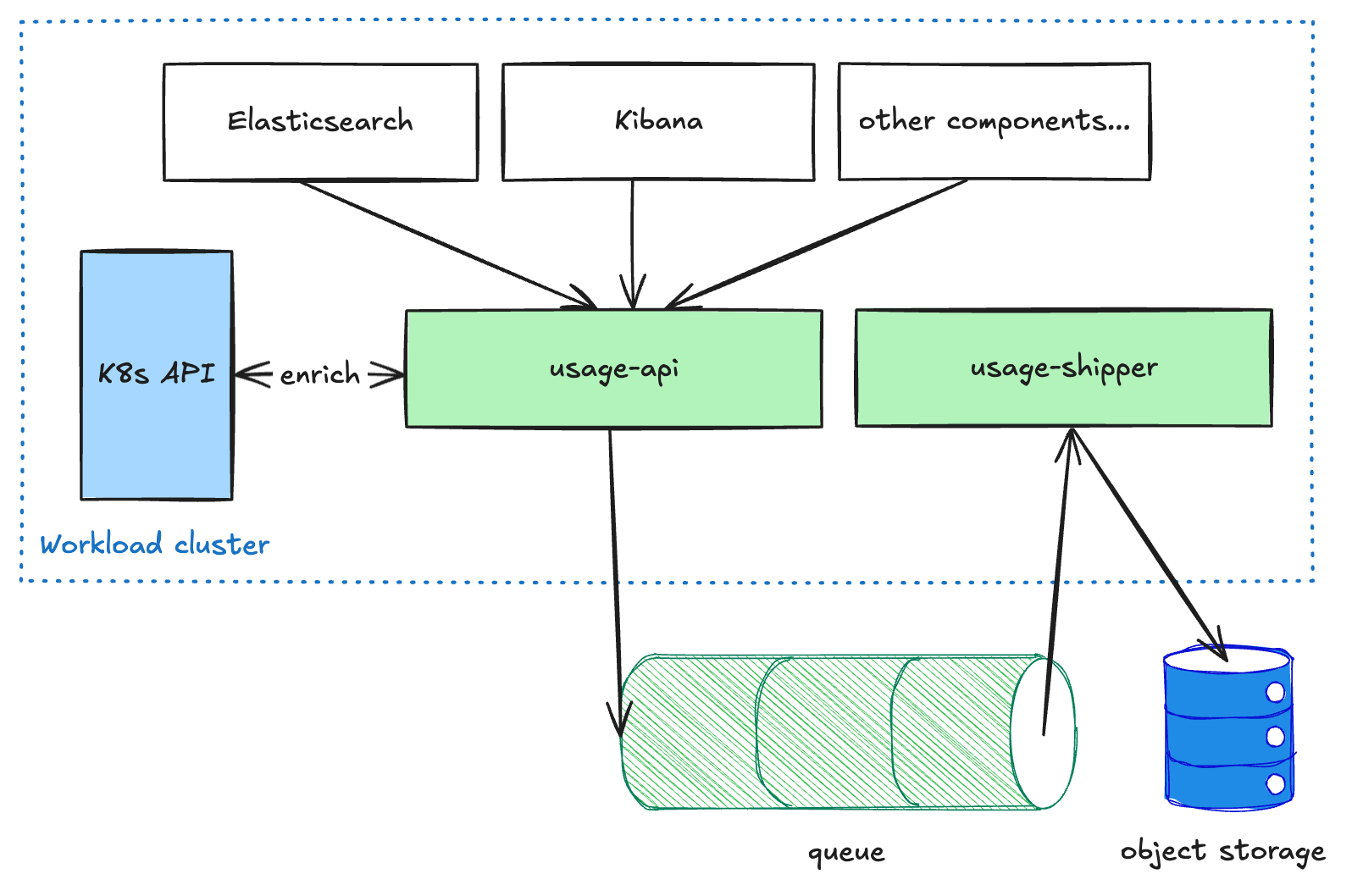
Abrechnungspipeline
Sobald Nutzungsdatensätze im Objektspeicher abgelegt sind, erfasst die Abrechnungspipeline die Daten und wandelt sie in Mengen von ECU (Elastic Consumption Units, unsere währungsunabhängige Abrechnungseinheit) um, die wir in Rechnung stellen. Der grundlegende Prozess sieht folgendermaßen aus:
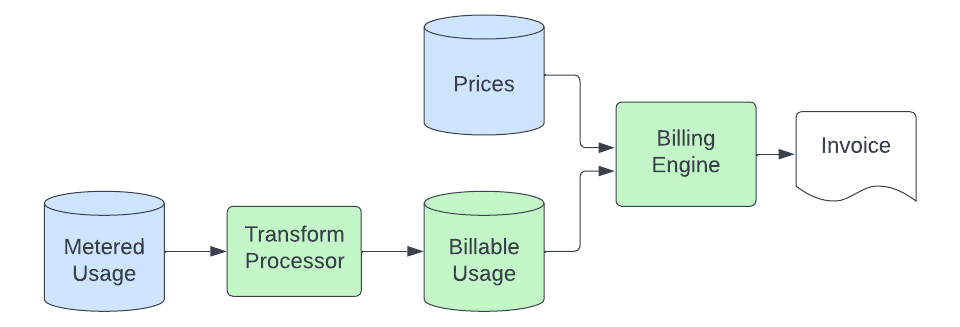
Ein Transformationsprozess verarbeitet die gemessenen Nutzungsdatensätze aus dem Objektspeicher und wandelt sie in abrechenbare Datensätze um. Dieser Prozess umfasst die Umrechnung von Einheiten (die gemessene Anwendung misst den Speicher möglicherweise in Bytes, wir rechnen jedoch eventuell in GB ab), das Herausfiltern von Nutzungsquellen, die wir nicht in Rechnung stellen, das Mapping des Datensatzes zu einem bestimmten Produkt (dazu gehört das Parsen von Metadaten in den Nutzungsdatensätzen, um die Nutzung einem produktspezifischen Preis zuzuordnen) und das Senden dieser Daten an einen Elasticsearch-Cluster, der von unserer Abrechnungs-Engine abgefragt wird. Der Zweck dieser Transformationsphase besteht darin, einen zentralen Ort bereitzustellen, an dem die Logik zur Umwandlung der allgemeinen gezählten Verbrauchsdaten in produktspezifische Mengen, die bepreist werden können, gespeichert wird. Dies ermöglicht es uns, diese spezialisierte Logik aus den Zähleranwendungen und der Abrechnungs-Engine herauszuhalten, die wir einfach und produktunabhängig halten möchten.
Die Abrechnungs-Engine bewertet dann diese abrechnungsfähigen Nutzungsdatensätze, die nun eine Kennung enthalten, die einem Produkt in unserer Preisdatenbank zugeordnet ist. Dieser Prozess umfasst mindestens die Summierung der Nutzung über einen bestimmten Zeitraum und die Multiplikation der Menge mit dem Preis des Produkts, um die ECUs zu berechnen. In einigen Fällen muss die Nutzung zusätzlich in Stufen unterteilt werden, die auf der kumulativen Nutzung im Laufe des Monats basieren, und diese Stufen müssen den einzelnen Produktpreisen zugeordnet werden. Um Verzögerungen im vorgelagerten Prozess zu tolerieren, ohne dass Datensätze fehlen, wird die Nutzung zu dem Zeitpunkt abgerechnet, zu dem sie im abrechnungsfähigen Nutzungsdatenspeicher eintrifft, aber der Preis richtet sich nach dem Zeitpunkt, zu dem sie stattgefunden hat (um sicherzustellen, dass wir nicht den falschen Preis für eine Nutzung anwenden, die „spät eingetroffen ist“). Dies bietet eine „selbstheilende“ Fähigkeit für unseren Abrechnungsprozess.
Sobald die ECUs berechnet sind, bewerten wir alle zusätzlichen Kosten (z. B. für den Support) und lassen diese in die Abrechnungsberechnungen einfließen, die schließlich zu einer Rechnung führen (die von uns oder einem unserer Cloud-Marktplatzpartner verschickt wird). Dieser letzte Teil des Prozesses ist nicht neu oder einzigartig für Serverless und wird von denselben Systemen abgewickelt, die auch unser gehostetes Produkt abrechnen.
Erkenntnisse
Der Aufbau einer Infrastrukturplattform, die ähnliche Funktionalitäten über mehrere CSPs hinweg bietet, ist eine komplexe Herausforderung. Das Gleichgewicht zwischen Zuverlässigkeit, Skalierbarkeit und Kosteneffizienz erfordert kontinuierliche Iterationen und Kompromisse. Kubernetes-Implementierungen variieren zwischen den Cloud-Dienstanbietern erheblich, und um eine konsistente Erfahrung über alle Anbieter hinweg sicherzustellen, sind umfangreiche Tests und Anpassungen erforderlich.
Darüber hinaus ist die Einführung einer serverlosen Architektur nicht nur eine technische Transformation, sondern auch ein kultureller Wandel. Sie erfordert den Übergang von reaktiver Fehlerbehebung zu proaktiver Systemoptimierung und die Priorisierung der Automatisierung, um die betriebliche Belastung zu minimieren. Im Verlauf der Entwicklung haben wir gelernt, dass der Aufbau einer erfolgreichen serverlosen Platform ebenso viel mit architektonischen Entscheidungen zu tun hat wie mit der Förderung einer Denkweise, die kontinuierliche Innovation und Verbesserung fördert.
Blick in die Zukunft
Der Erfolg in der serverlosen Welt hängt davon ab, dass Sie ein außergewöhnliches Kundenerlebnis bieten, den Betrieb proaktiv optimieren und Zuverlässigkeit, Skalierbarkeit und Kosteneffizienz kontinuierlich ausgleichen. Mit Blick auf die Zukunft konzentrieren wir uns weiter darauf, neue Features für unsere Kunden auf Elastic Cloud Serverless zu entwickeln und Serverless zum besten Ort zu machen, um Elasticsearch für alle auszuführen.
Die Zukunft der Suche, Sicherheit und Beobachtbarkeit ist schon da, ohne Kompromisse bei Geschwindigkeit, Skalierbarkeit oder Kosten. Erleben Sie Elastic Cloud Serverless und Search KI Lake, um neue Möglichkeiten mit Ihren Daten zu erschließen. Erfahren Sie mehr über die Möglichkeiten von Serverless oder starten Sie Ihre kostenlose Testversion jetzt.
Die Entscheidung über die Veröffentlichung der in diesem Blogeintrag beschriebenen Leistungsmerkmale und Features sowie deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass noch nicht verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit persönlichen, sensiblen oder vertraulichen Daten verwenden. Alle Daten, die Sie eingeben, können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass Informationen, die Sie bereitstellen, sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch und zugehörige Marken sind Marken, Logos oder eingetragene Marken von Elasticsearch N.V. in den Vereinigten Staaten und anderen Ländern. Alle anderen Unternehmens- und Produktnamen sind Marken, Logos oder eingetragene Marken ihrer jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken