Wir stellen vor: Machine Learning für den Elastic Stack
Einleitung
Wir sind stolz darauf, dir heute den ersten Release von den Machine-Learning-Funktionen für den Elastic Stack präsentieren zu können, die über X-Pack verfügbar sind. Die Entwicklungsgeschwindigkeit bei Elastic ist ungebremst und nach sieben Monaten freuen wir uns sehr, dass die Prelert Machine-Learning-Technologie jetzt vollständig in den Elastic Stack integriert ist. Wir sind sehr gespannt auf das Feedback von unseren Nutzern.
Bitte beachte: Wir sind genauso aufgeregt wie du, möchten dich aber daran erinnern, dass sich diese Funktionen in der Version 5.4.0 im Betastadium befinden.
Machine Learning
Unser Ziel besteht darin, Nutzern mithilfe der entsprechenden Tools die Möglichkeit zu geben, Mehrwert und Einblicke aus ihren Elasticsearch-Daten zu gewinnen. Machine Learning ist für uns eine logische Erweiterung der Such- und Analysefunktionen in Elasticsearch. Mit Elasticsearch kannst du z. B. in Echtzeit in riesigen Datenmengen nach Transaktionen für den Benutzer "Steve“ suchen oder mithilfe von Aggregationen und Visualisierungen die zehn meistverkauften Produkte oder Transaktionstrends im Zeitverlauf anzeigen. Mit Machine Learning kannst du jetzt noch tiefgreifendere Fragen beantworten, z. B. "Hat sich das Verhalten einer meiner Services verändert?“ oder "Laufen auf meinen Hosts ungewöhnliche oder auffällige Prozesse?“ Solche Fragen erfordern Verhaltensmodelle für Hosts oder Services, die mithilfe von Machine-Learning-Verfahren automatisch auf der Grundlage von Daten erstellt werden können.
Machine Learning ist jedoch aktuell einer der überladensten Begriffe in der Software-Branche. Er wird dazu verwendet, eine umfangreiche Palette an Algorithmen und Methoden für die datengestützte Vorhersage, Entscheidungsfindung und Modellierung zu beschreiben. Wir möchten deshalb Licht ins Dunkel bringen und konkret beschreiben, was genau wir tun.
Erkennung von Zeitreihen-Anomalien
Die Machine-Learning-Funktionen von X-Pack konzentrieren sich aktuell auf die Erkennung von Zeitreihen-Anomalien mithilfe von nicht überwachtem Machine Learning.
Mit der Zeit möchten wir weitere Machine-Learning-Funktionen hinzufügen. Aktuell konzentrieren wir uns jedoch darauf, solchen Nutzern einen Mehrwert zu bieten, die Zeitreihendaten wie Log-Dateien, Anwendungs- und Performance-Metriken, Netzwerk-Flows oder Finanz-/Transaktionsdaten auf Elasticsearch speichern.
Beispiel 1: Automatische Benachrichtigung bei auffälligen Veränderungen eines KPI-Werts (Key Performance Indicator)
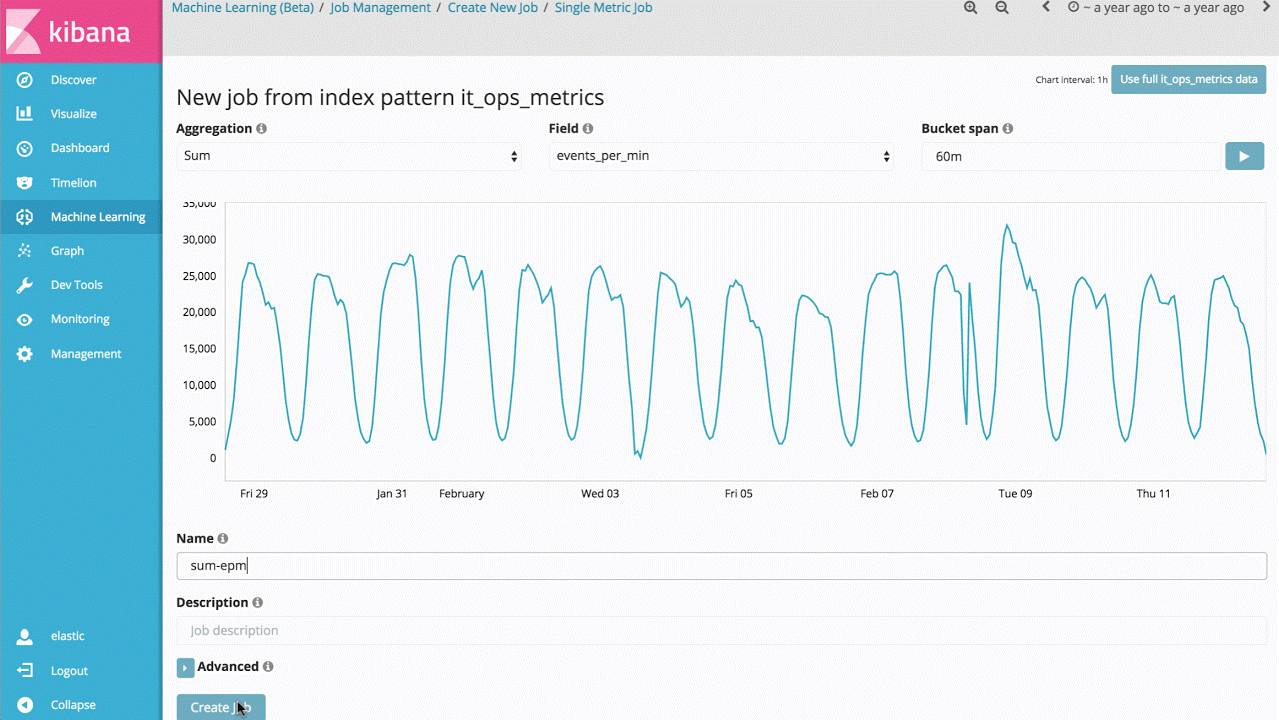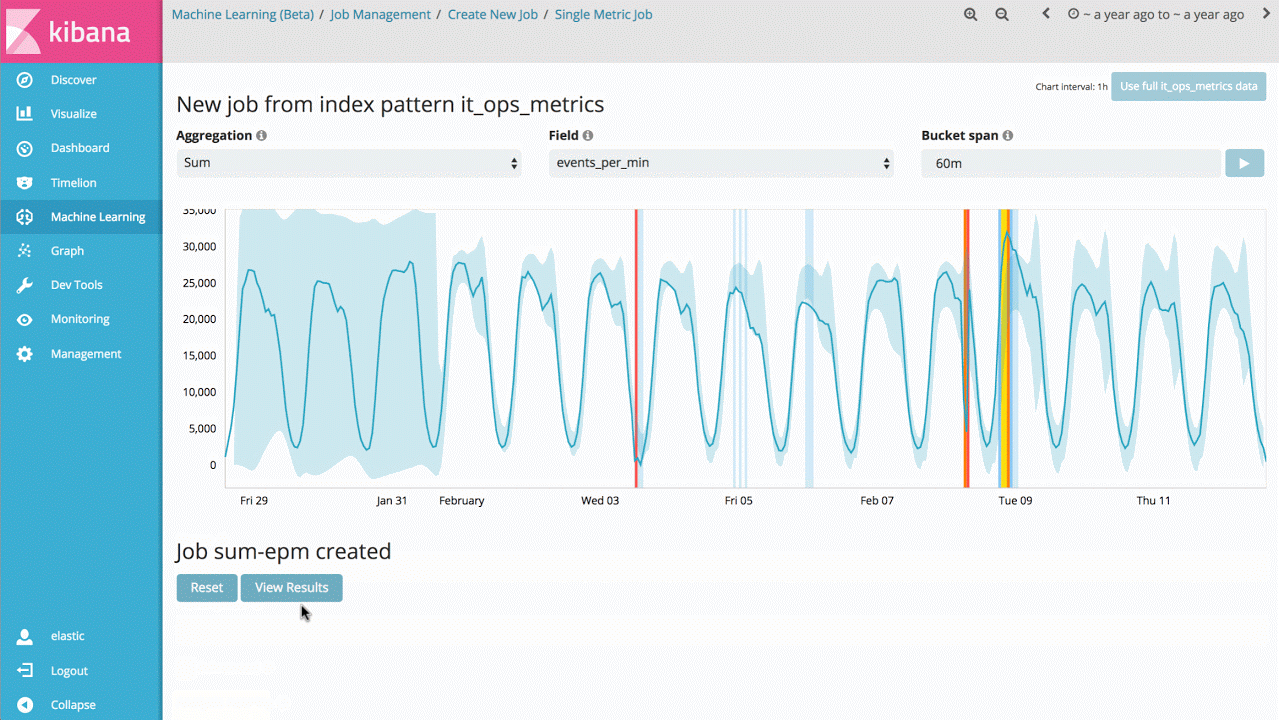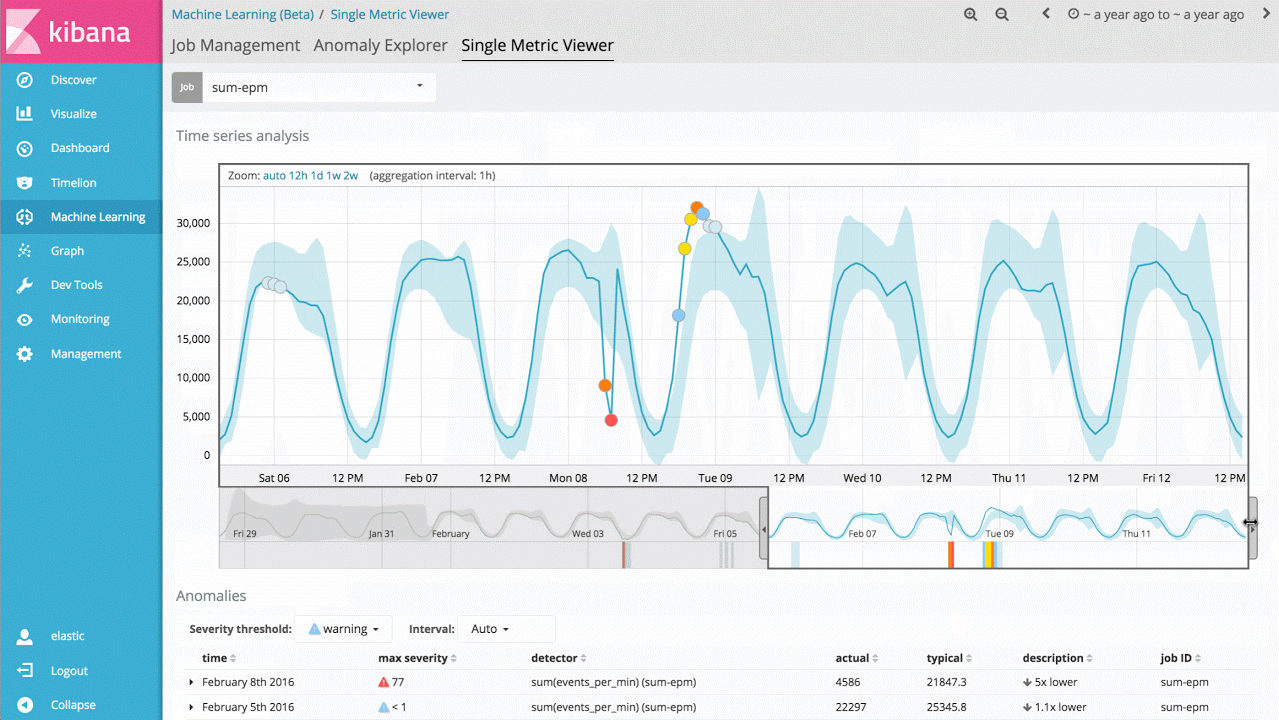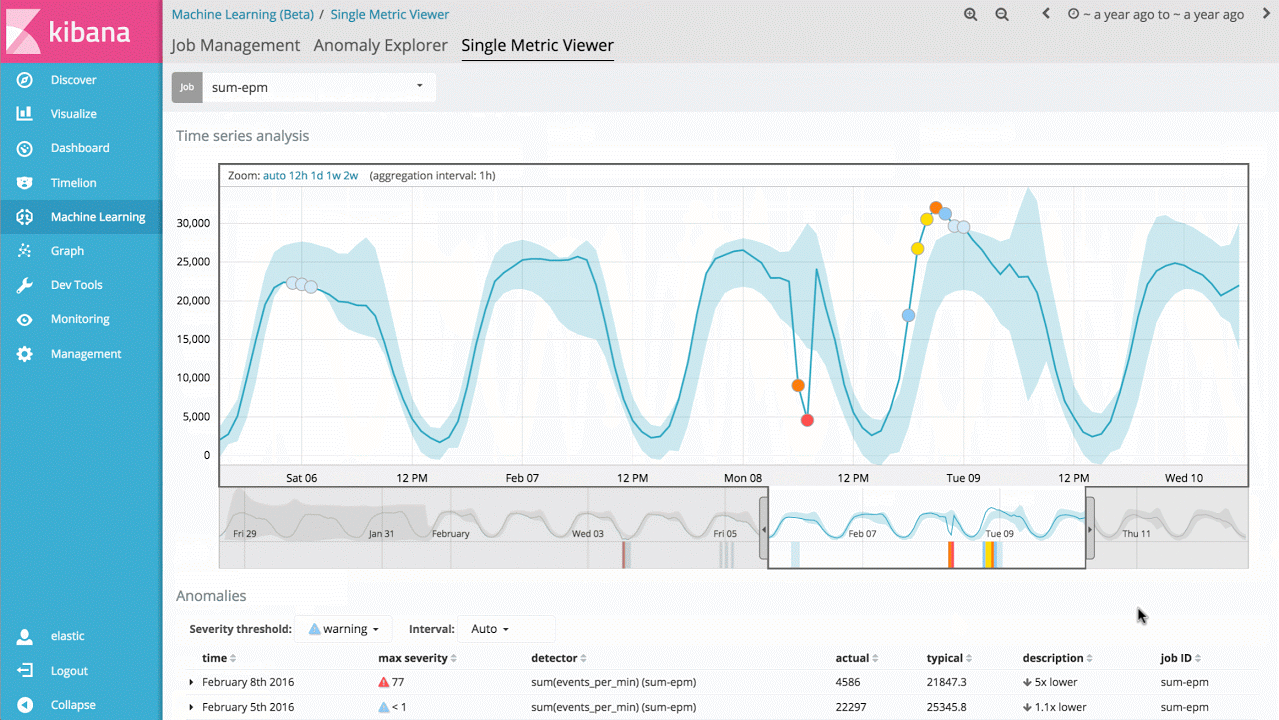
Der grundlegendste Anwendungsfall dieser Technologie besteht darin, festzustellen, wann der Wert einer Metrik oder die Rate eines Ereignisses von ihrem normalen Verhalten abweicht. Hat sich z. B. die Reaktionszeit meines Services drastisch erhöht oder unterscheidet sich die erwartete Besucherzahl der Website in wesentlichem Maße von dem normalen Wert für diese Tageszeit? Traditionell werden für solche Analysen Regeln, Schwellenwerte oder einfache statistische Methoden verwendet. Leider sind diese einfachen Verfahren für echte Daten nur selten effektiv, da sie oft auf falschen statistischen Annahmen beruhen (z. B. Gauß-Verteilungen), keine (Langzeit- oder regelmäßig wiederkehrenden) Trends berücksichtigen oder keinen Signalveränderungen standhalten.
Den Einstieg in die Machine-Learning-Funktionen bildet daher eine Aufgabe zu einer einzigen Metrik, mithilfe derer sich ermitteln lässt, wie das Produkt lernt, welche Werte als normal gelten, und wie es Anomalien bei univariaten Zeitreihendaten erkennt. Wenn die gefundenen Anomalien hilfreich für dich sind, kannst du diese Analyse fortlaufend in Echtzeit durchführen und dich benachrichtigen lassen, wenn eine Anomalie auftritt.
Dies scheint ein relativ einfacher Anwendungsfall zu sein, doch das Backend des Produktes enthält ein hohes Maß an komplexen Algorithmen für nicht überwachtes (unsupervised) Machine Learning und an statistischer Modellierung, um Stabilität und Genauigkeit bei beliebigen Signalen gewährleisten zu können.
Die Implementierung ist für einen nativen Betrieb in einem Elasticsearch-Cluster optimiert, sodass Millionen von Ereignissen in Sekundenschnelle analysiert werden können.
Beispiel 2: Automatisches Tracken von Tausenden von Metriken
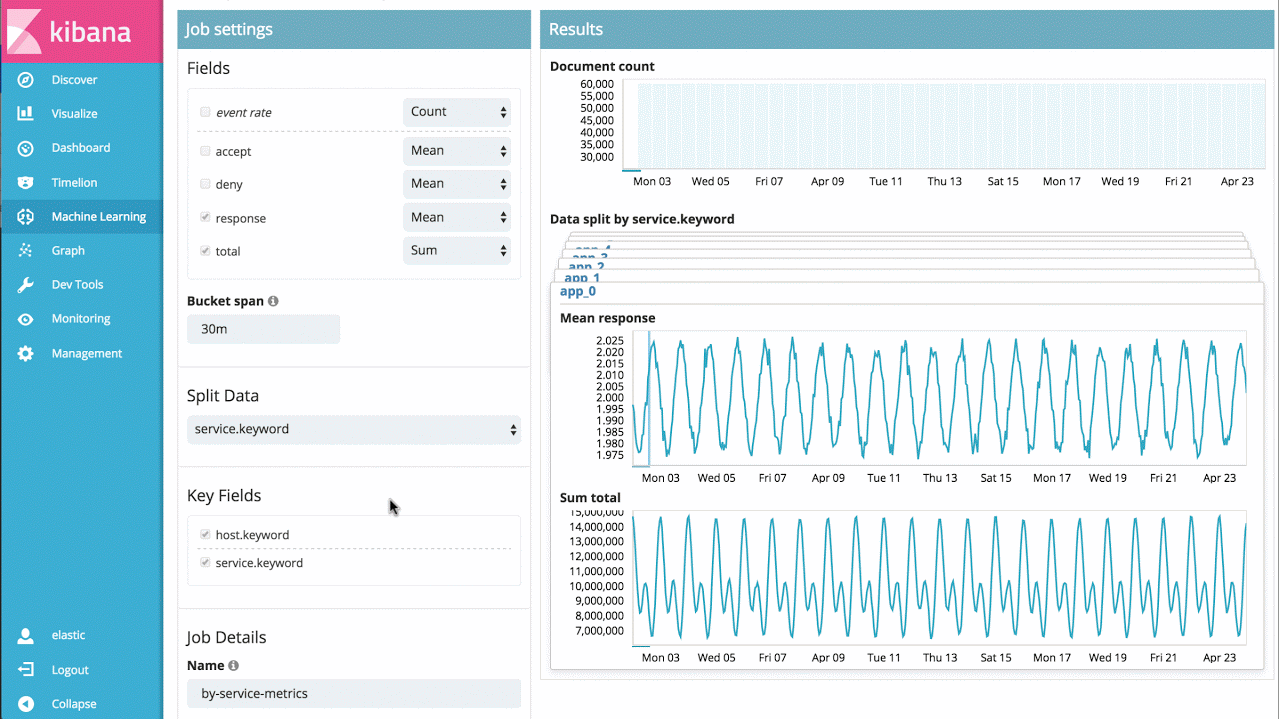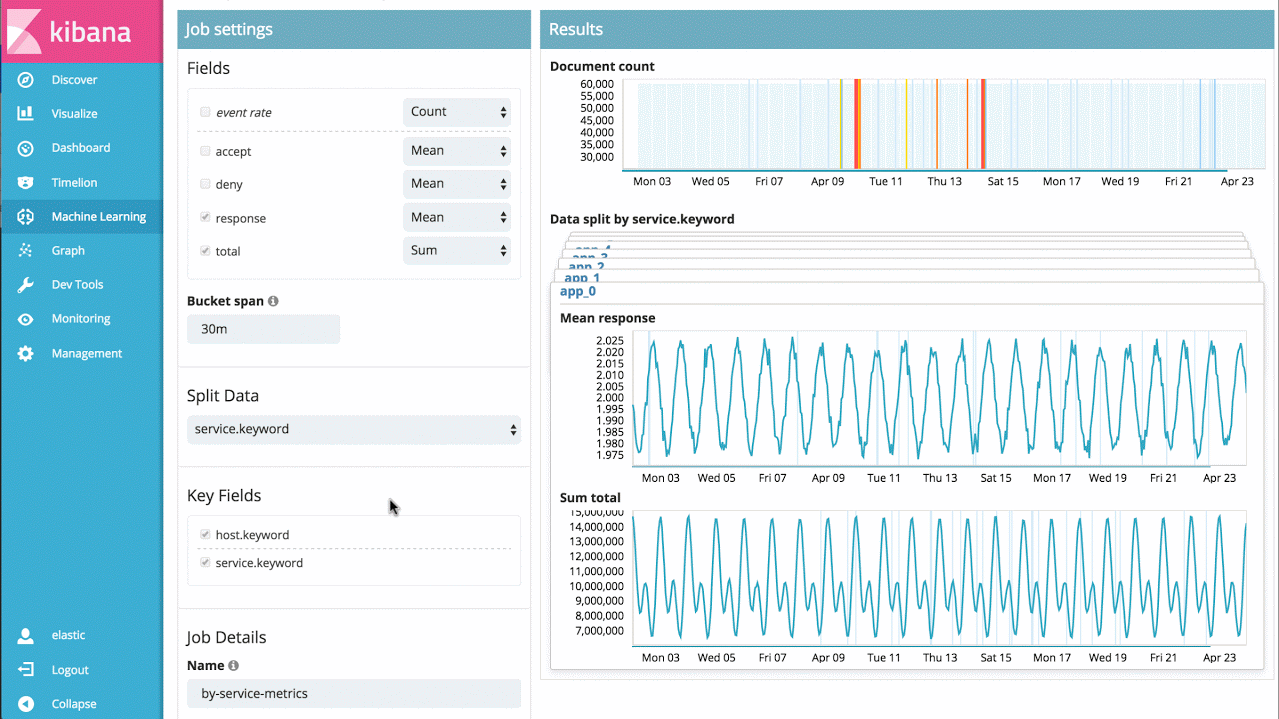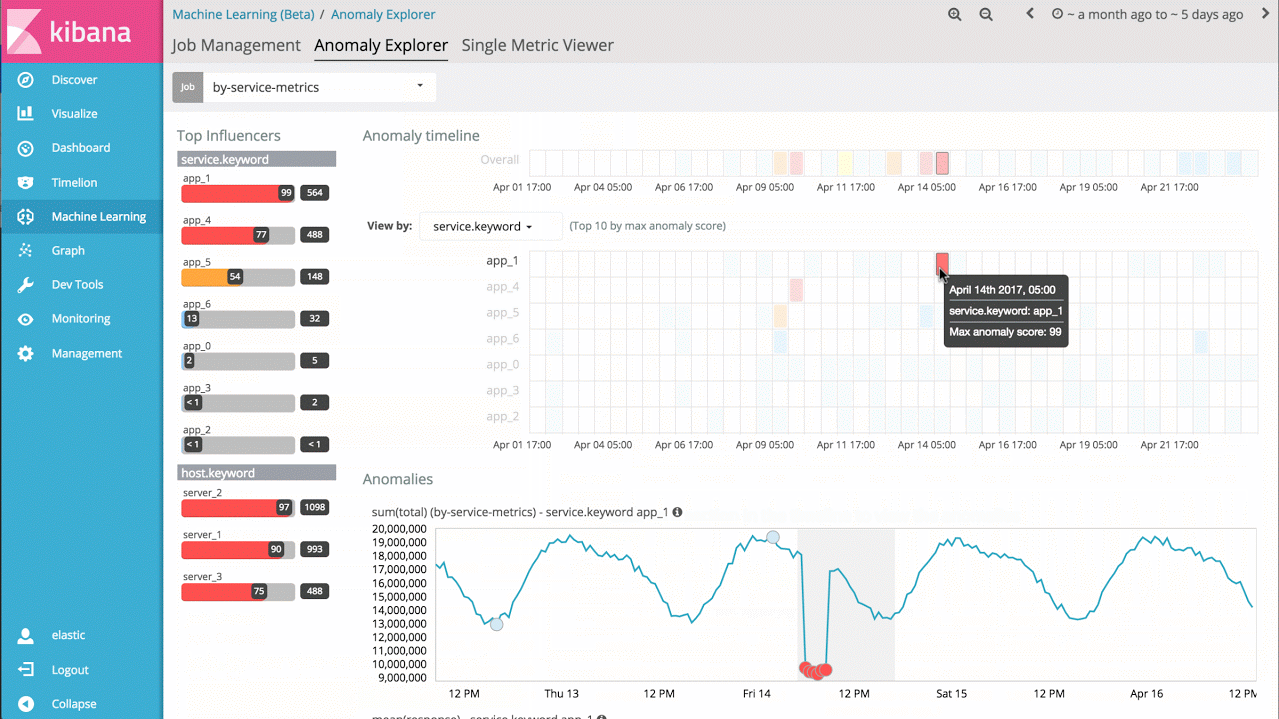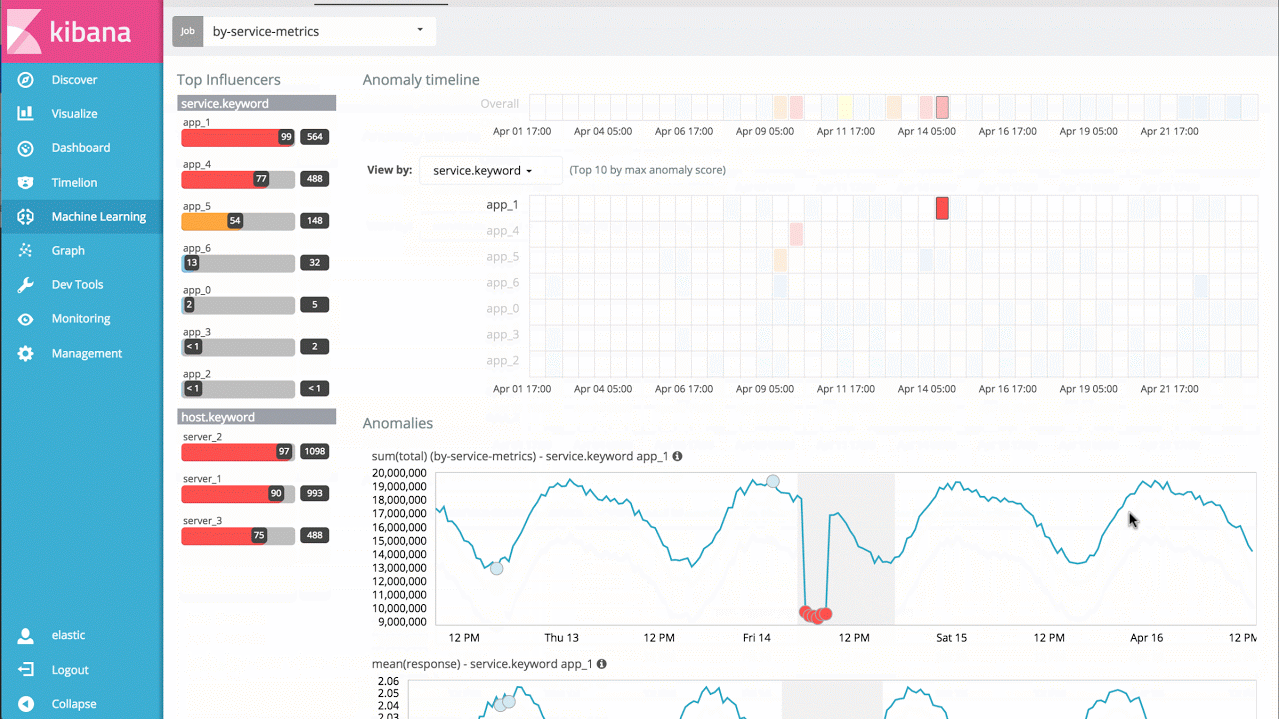
Machine-Learning kann für Hunderttausende von Metriken und Log-Dateien entsprechend skaliert werden. Der nächste Schritt besteht somit darin, mehrere Metriken zusammen zu analysieren. Dabei kann es sich um mehrere verwandte Metriken auf einem Host, Performance-Metriken aus einer Datenbank oder Anwendung sowie mehrere Log-Dateien von mehreren Hosts handeln. In diesem Fall können wir die Analyse einfach aufteilen und die Ergebnisse zu einer einzigen Übersicht aggregieren und Anomalien im gesamten System aufzeigen.
Wenn mir z. B. Reaktionszeiten von vielen verschiedenen Anwendungsservices vorliegen, kann ich einfach die Reaktionszeiten der einzelnen Services im Zeitverlauf betrachten, anomales Verhalten einzelner Leistungen erkennen sowie eine Übersicht über alle Systemanomalien erstellen.
Beispiel 3: Komplexere Aufgaben
Es gibt viele verschiedene Möglichkeiten, das Produkt auf komplexere Art und Weise zu nutzen. Wenn du z. B. Benutzer, die sich im Vergleich zur Allgemeinheit auffällig verhalten, ungewöhnlichen DNS-Traffic oder Staus auf den Straßen von Berlin ausfindig machen möchtest, bieten komplexere Aufgaben eine flexible Möglichkeit, auf Elasticsearch gespeicherte Zeitreihendaten zu analysieren.
Elastic Stack-Integration
Machine Learning ist als Funktion von X-Pack verfügbar. Das bedeutet, sobald X-Pack installiert ist, Machine-Learning-Funktionen zur Echtzeit-Analyse von Time-Series-Daten auf Elasticsearch genutzt werden können. Machine-Learning-Aufgaben werden ähnlich wie Indizes und Shards über den Elasticsearch-Cluster automatisch verteilt und verwaltet. Das bedeutet auch, dass Machine-Learning-Aufgaben Knotenausfällen standhalten können. Im Hinblick auf Performance bedeutet die enge Integration, dass Daten nie den Cluster verlassen müssen und wir mithilfe von Elasticsearch-Aggregationen die Performance für manche Aufgabentypen drastisch verbessern können. Ein weiterer Vorteil dieser engen Verbindung besteht darin, dass Aufgaben zur Erkennung von Anomalien sowie zur Anzeige von Ergebnissen direkt von Kibana aus erstellt werden können.
Da die Dateien direkt vor Ort analysiert werden und nie den Cluster verlassen, bietet dieser Ansatz einen wesentlichen Performance- und Betriebsvorteil gegenüber der Integration von Elasticsearch-Daten mit externen Datenanalyse-Tools. Je mehr Technologien wir in diesem Bereich entwickeln, desto mehr werden die Vorteile dieser Architektur zum Tragen kommen.
Überzeuge dich am besten selbst und teile uns mit, was du denkst.
Diese Machine-Learning-Funktionen befinden sich in der X-Pack Version 5.4, die jetzt verfügbar ist, im Betastadium. Wir sind gespannt darauf, von deinen Erfahrungen damit zu hören! Hier kannst du den Release 5.4 herunterladen. Installiere anschließend X-Pack und kontaktiere uns direkt oder über unser Diskussionsforum.