Schritte zur Migration vom selbstverwalteten Elasticsearch auf Elastic Cloud auf AWS
Wir beobachten, dass On-Premises-Workloads zunehmend in die Cloud verlagert werden. Elasticsearch ist seit vielen Jahren aktiv und unsere Nutzer und Kunden verwalten ihre Workloads in der Regel „on-premises“. Elasticsearch Service auf Elastic Cloud ist unser verwalteter Elasticsearch-Dienst auf Amazon Web Services (AWS), Google Cloud und Microsoft Azure in vielen Regionen weltweit und die beste Möglichkeit, den Elastic Stack und unsere Lösungen für Enterprise Search, Observability und Security zu nutzen.
Wenn Sie Elasticsearch nicht mehr selbst verwalten möchten, nimmt Ihnen der Elasticsearch Service Folgendes von den Schultern:
- Bereitstellung und Verwaltung der zugrunde liegenden Infrastruktur
- Erstellung und Verwaltung Ihrer Elasticsearch-Cluster
- Skalierung Ihrer Cluster – nach oben oder unten
- Upgrades, Patching und Snapshot-Erstellung
Dadurch haben Sie mehr Zeit, sich auf die Lösung anderer Aufgaben zu konzentrieren.
In diesem Blogpost zeigen wir Ihnen, wie Sie auf Elasticsearch Service migrieren können, indem Sie einen Snapshot Ihres Elasticsearch-Clusters erstellen und diesen dann auf Elasticsearch Service wiederherstellen.
Erstellen eines Snapshots des Clusters
Wenn Sie von selbstverwaltetem Elasticsearch auf Elasticsearch Service umsteigen möchten, müssen Sie als Erstes entscheiden, welchen Cloud-Anbieter und welche Cloud-Region Sie nutzen möchten. Diese Entscheidung hängt in der Regel von Ihren bestehenden Workloads, Ihrer Cloud-Strategie und verschiedenen anderen Faktoren ab.
Im Folgenden sehen wir uns an, wie das Ganze für Elasticsearch Service auf AWS abläuft. Eine Erläuterung der Prozesse für Google Cloud und Azure folgt demnächst.
Die einfachste Möglichkeit, Daten aus einem Elasticsearch-Cluster in einen anderen Cluster zu verschieben, besteht darin, einen Snapshot des Clusters zu erstellen und diesen Snapshot dann zu nutzen, um die Daten im neuen Elasticsearch Service-Cluster wiederherzustellen.
Für das Erstellen eines Cluster-Snapshots gibt es mehrere Möglichkeiten. Die einfachste: Führen Sie eine einmalige Snapshot-Operation aus.
Sollte Ihr Elasticsearch fortlaufend Daten ingestieren, hat diese Form der Snapshot-Erstellung den Nachteil, dass die Daten verloren gehen, die zwischen dem Zeitpunkt, zu dem der Snapshot erstellt wird, und dem Zeitpunkt ingestiert werden, zu dem der Snapshot im neuen Cluster wiederhergestellt wird. Um dies weitestgehend zu verhindern, empfiehlt es sich, eine Snapshot-Lifecycle-Richtlinie zu erstellen. Wenn Ihr Elasticsearch-Cluster nicht fortlaufend Daten ingestiert, z. B. bei der Verwendung für die Suche, ist ein solcher Einmal-Snapshot okay.
Bevor Sie einen Snapshot Ihres lokalen Clusters erstellen, müssen Sie das AWS S3-Bucket konfigurieren, in dem dieser Snapshot gespeichert werden soll. Dies ist der Speicherort, aus dem der neue, auf AWS ausgeführte Elasticsearch Service-Cluster den Cluster-Status wiederherstellen wird.
Grob gesagt besteht dieser Prozess aus den folgenden Schritten:
- Konfigurieren des Cloud-Speichers (in diesem Fall des AWS S3-Buckets)
- Konfigurieren des lokalen Snapshot-Repositorys
- Erstellen Ihrer Snapshot-Richtlinie
- Bereitstellen des neuen Clusters auf Elasticsearch Service
- Konfigurieren des Snapshot-Repositorys des Elasticsearch Service-Clusters
- Wiederherstellen des Elasticsearch Service-Clusters aus einem lokalen Snapshot
Konfigurieren des Cloud-Speichers
- Erstellen Sie ein S3-Bucket. Das S3-Bucket sollte sich in derselben Region wie Ihr Elasticsearch Service-Cluster befinden:
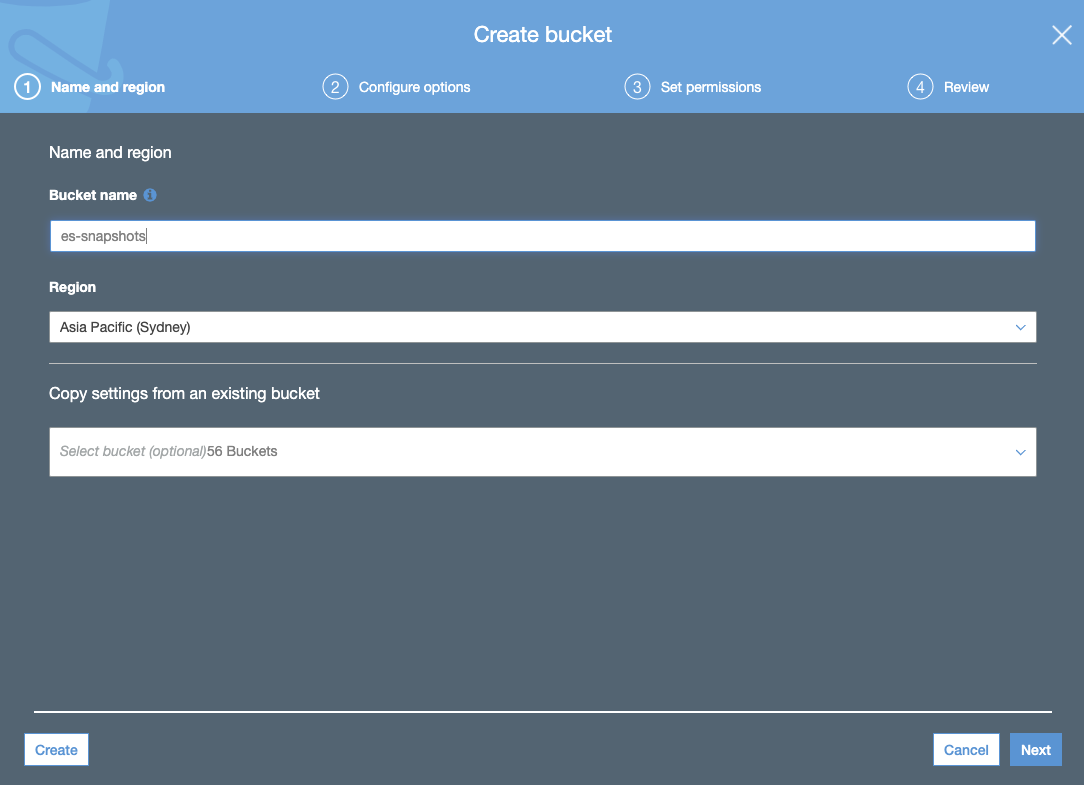
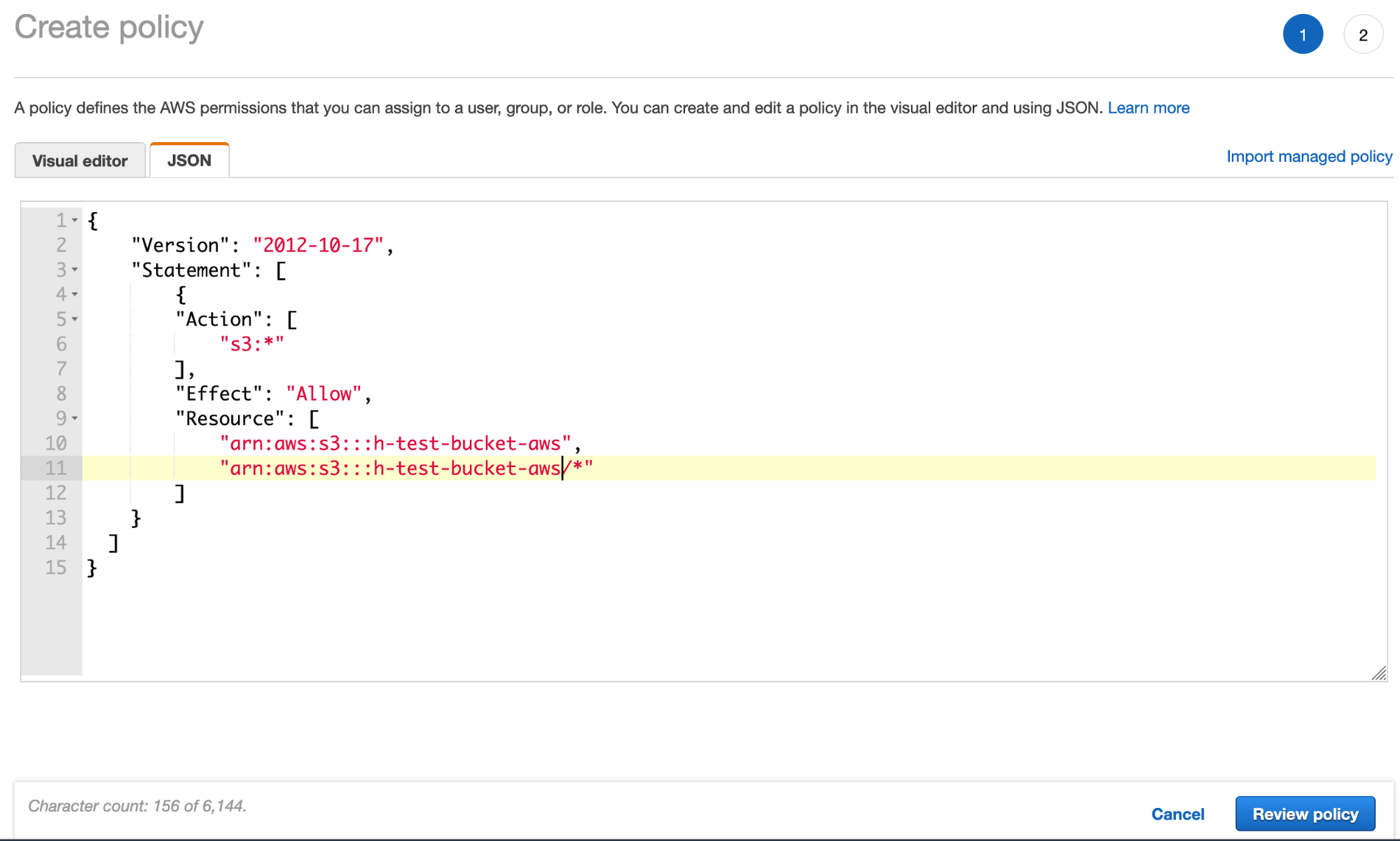
- Erstellen Sie über den Tab „JSON“ die S3-Bucket-Richtlinie und fügen Sie die JSON-Datei mit der Richtlinie für das S3-Bucket hinzu (unter Verwendung des Namens Ihres Buckets):
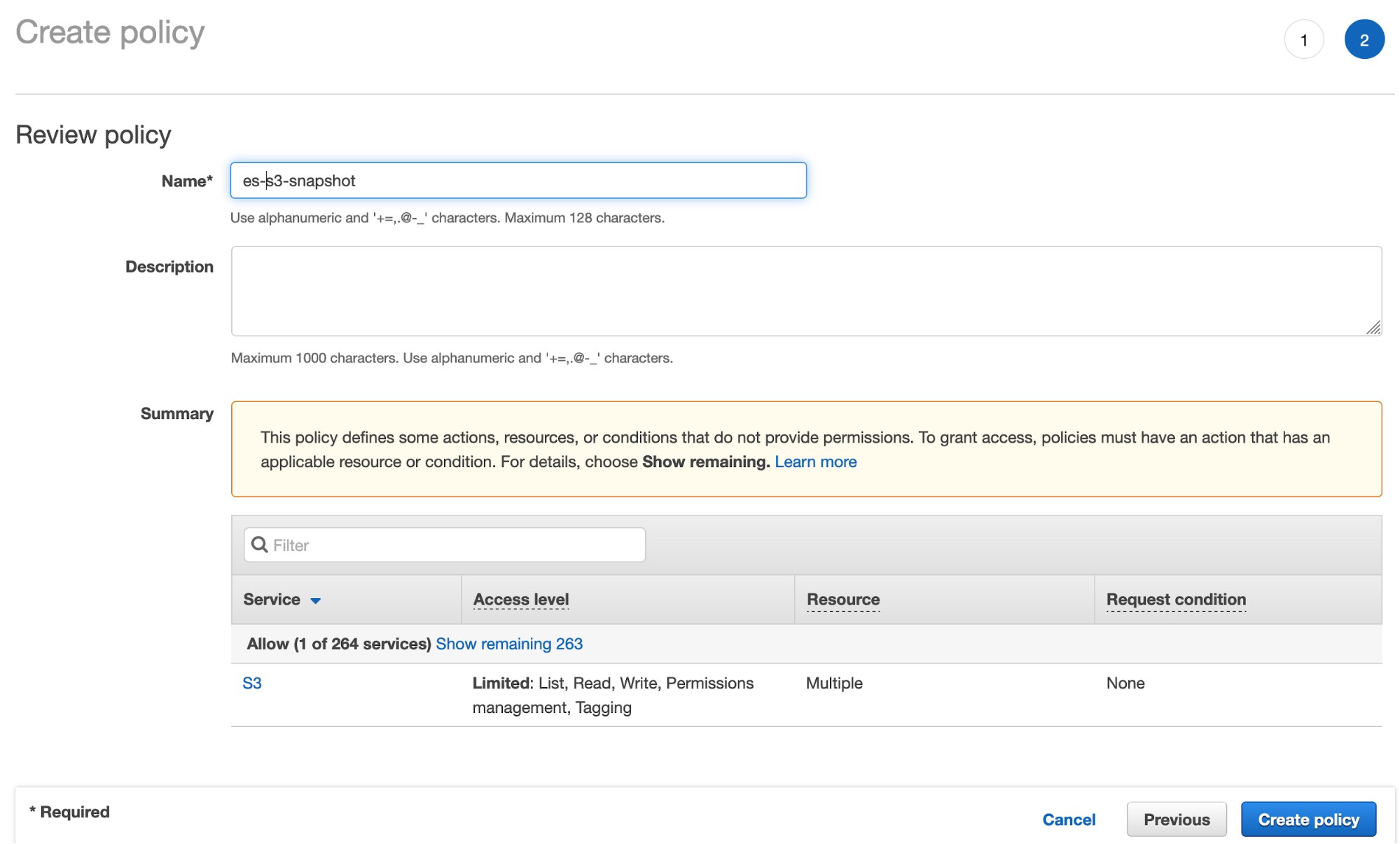
- Klicken Sie auf Review policy und geben Sie einen Namen für Ihre Richtlinie ein:
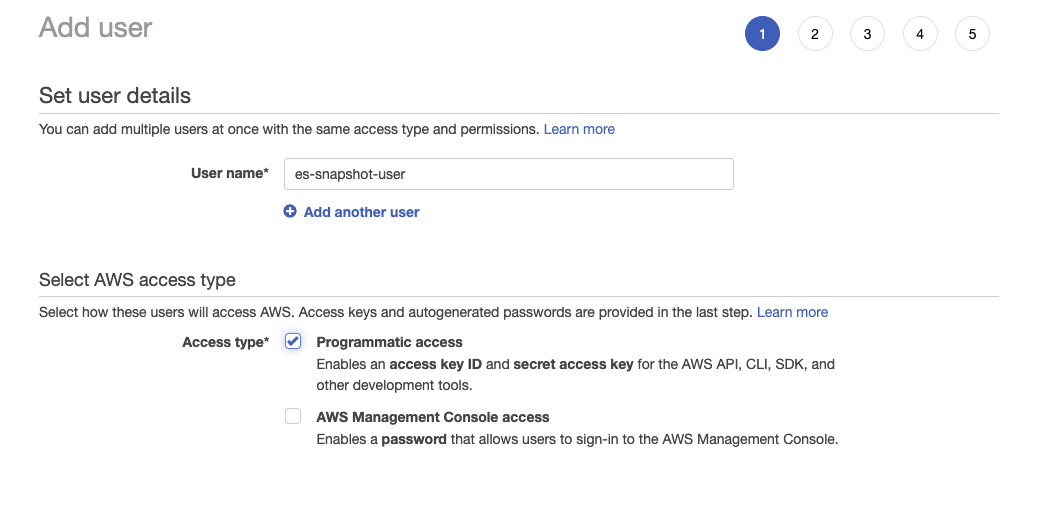
- Erstellen Sie den IAM-Nutzer und weisen Sie die oben erstellte S3-Bucket-Richtlinie zu:
- Klicken Sie auf Next: Permissions, wählen Sie Attach existing policies directly und suchen Sie nach der Richtlinie, die Sie im vorherigen Schritt erstellt haben:
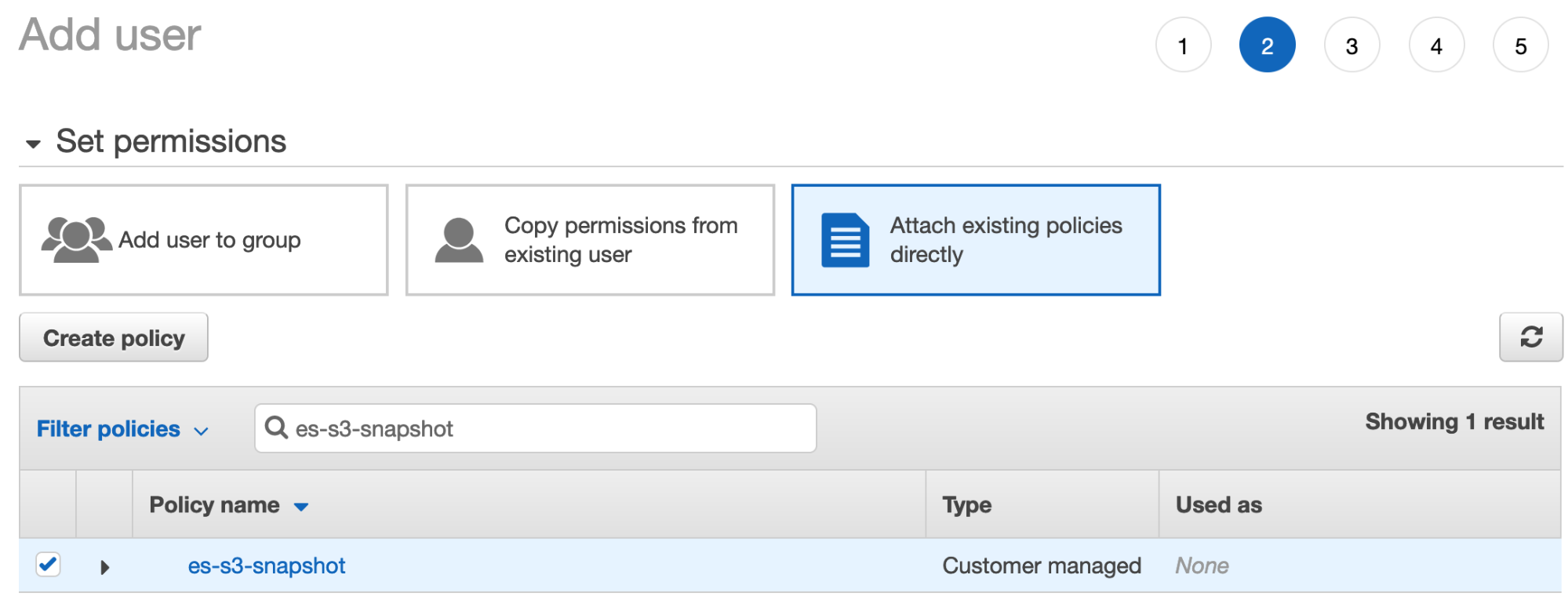
- Vergewissern Sie sich, dass diese Richtlinie markiert ist, und klicken Sie dann auf Next:tags. Das Hinzufügen von Tags können Sie überspringen. Klicken Sie einfach auf Create User.
- Laden Sie die Sicherheitszugangsdaten des Nutzers herunter.
Konfigurieren des lokalen Snapshot-Repositorys
1. Installieren des S3-Plugins
Installieren Sie das Elasticsearch-S3-Plugin in Ihrem On-Premises-Deployment. Führen Sie dazu in jedem lokalen Elasticsearch-Knoten von Ihrem Elasticsearch-Startverzeichnis aus den folgenden Befehl aus:
sudo bin/elasticsearch-plugin install repository-s3
Nach dem Ausführen dieses Befehls müssen Sie den Knoten neu starten.
2. Konfigurieren der S3-Client-Berechtigungen
Konfigurieren Sie die S3-Client-Berechtigungen für den On-Premises-Cluster. Führen Sie dazu die folgenden Befehle aus:
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
Dies ist nötig, damit der lokale Cluster über die Zugangsinformationen verfügt, die zum Schreiben der Snapshots in S3 erforderlich sind. „Access_key“ und „secret_key“ sind dem Eintrag für den IAM-Nutzer zu entnehmen, den Sie im vorherigen Schritt erstellt haben.
Einrichten Ihrer Snapshot-Richtlinie
1. Konfigurieren des Snapshot-Repositorys
Konfigurieren Sie das S3-Snapshot-Repository in Ihrem lokalen Cluster. Führen Sie dazu in Kibana Dev Tools Folgendes aus. Damit teilen wir dem lokalen Cluster mit, in welches S3-Bucket der Snapshot geschrieben werden soll. Der IAM-Nutzer, den Sie gerade erstellt haben, sollte Lese- und Schreibrechte für dieses S3-Bucket haben.
PUT _snapshot/{ "type": "s3", "settings": { "bucket": " " } }
2. Erstellen einer Snapshot-Richtlinie
Als Nächstes erstellen Sie in Ihrem lokalen Cluster eine Snapshot-Richtlinie, die den Snapshot im neu erstellten S3-Bucket speichert:
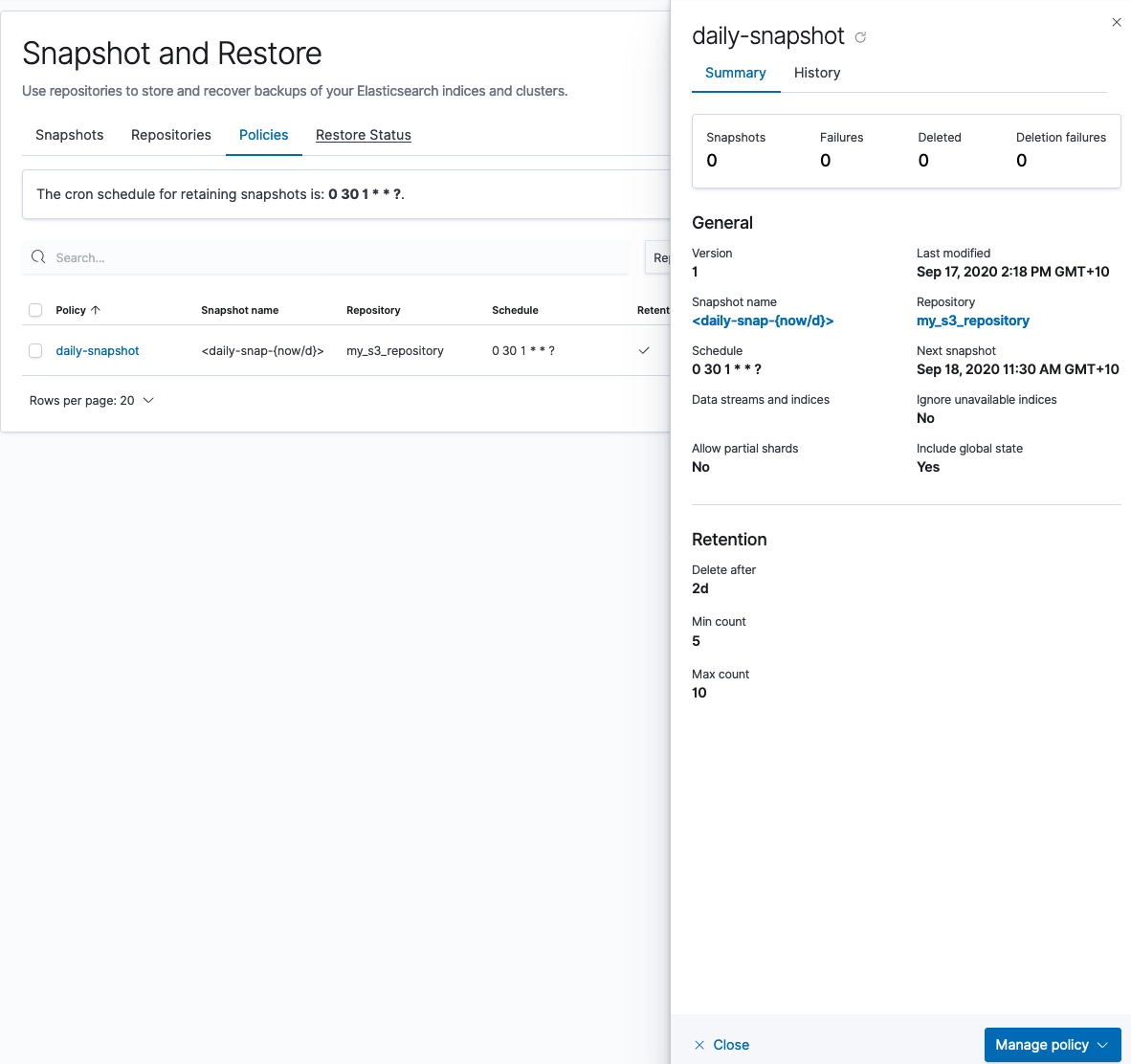
Sie können in Kibana Dev Tools auch einen Einmal-Snapshot erstellen:
PUT /_snapshot// ?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false }
Überprüfen Sie, dass die Snapshots funktionieren. Führen Sie dazu in Dev Tools den folgenden Befehl aus:
GET _snapshot//_all
Bereitstellen des neuen Clusters auf Elasticsearch Service
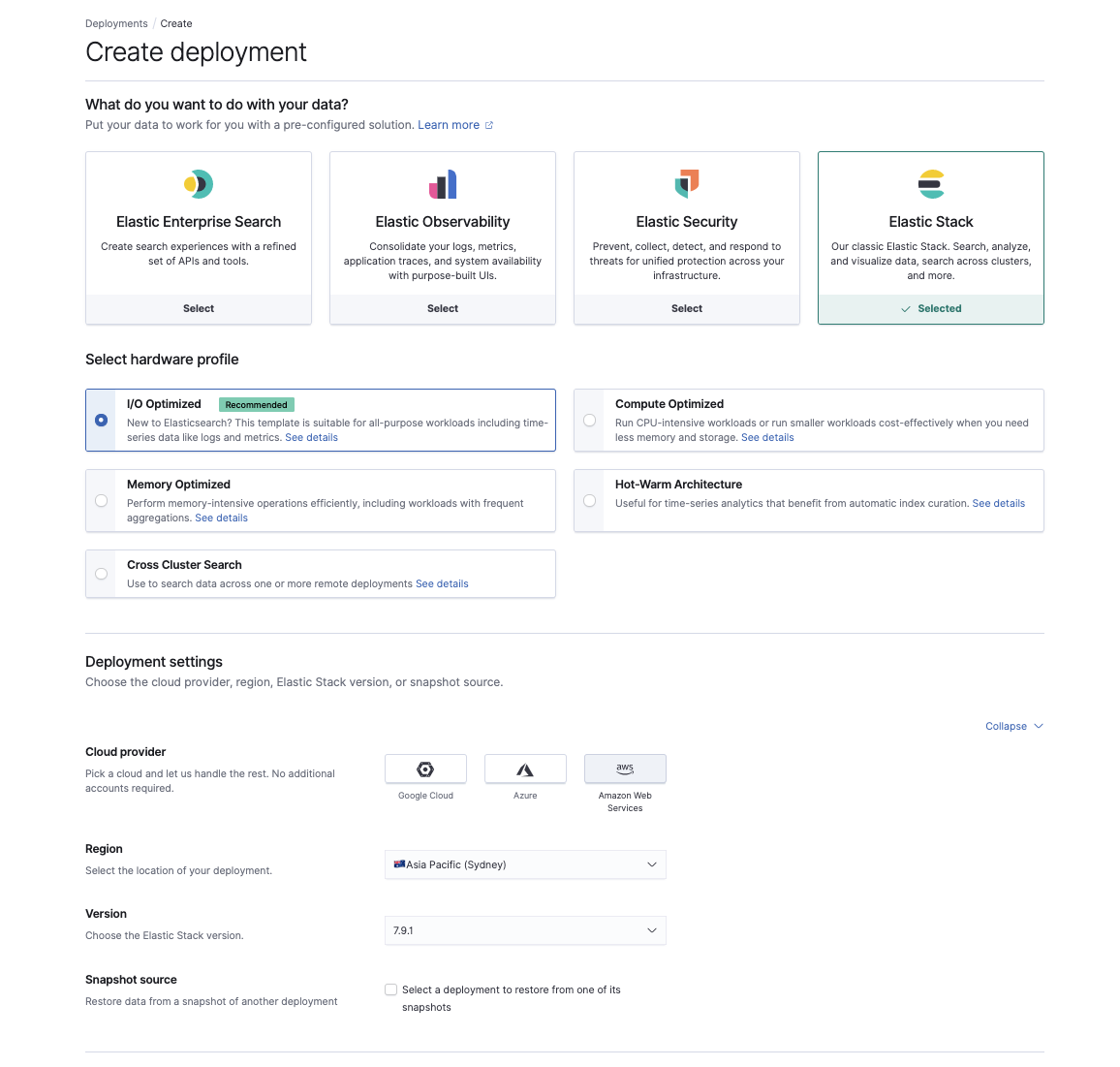
Nachdem wir uns vergewissert haben, dass die Snapshots in S3 funktionieren, ist es nun an der Zeit, unter cloud.elastic.co einen neuen Cluster auf Elasticsearch Service bereitzustellen. Sie können hier den Anwendungsfall auswählen, der am besten zu Ihrer bestehenden Workload, der AWS-Region und Ihrer Elasticsearch-Version passt.
Konfigurieren Sie in der Elasticsearch Service-Konsole die Einstellungen für den Cluster-Schlüsselspeicher:
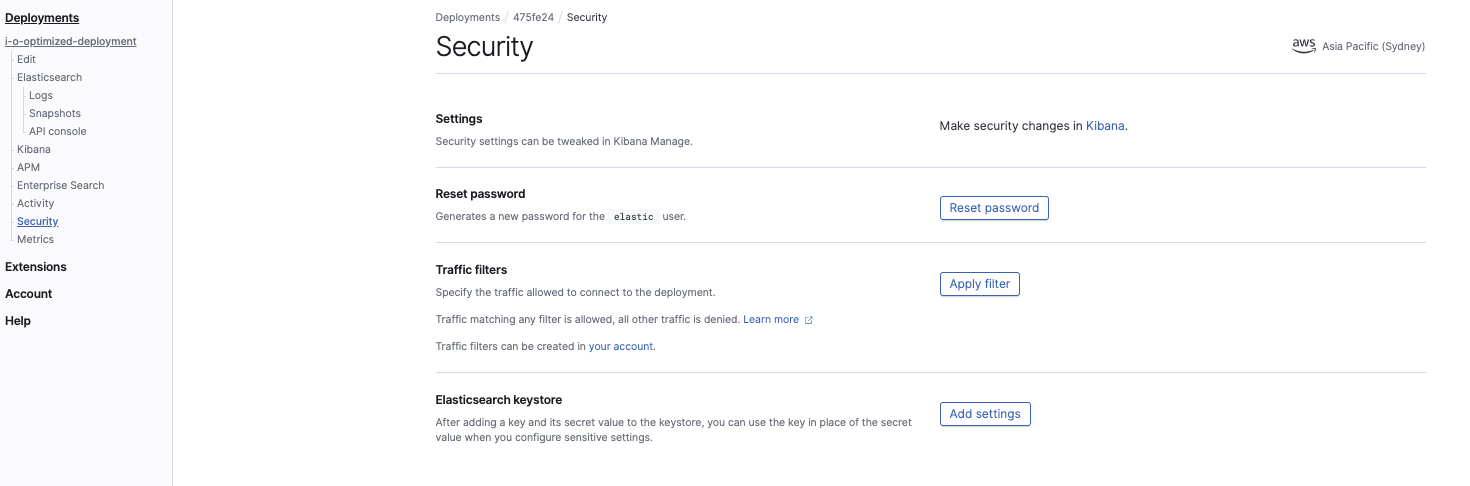
Die folgenden beiden Einstellungen müssen konfiguriert werden:
s3.client.default.access_key s3.client.default.secret_key
Das ist nötig, damit der Elasticsearch Service-Cluster die Berechtigung hat, den Snapshot aus dem S3-Bucket zu lesen. Diese Einstellungen sind dieselben wie die Sicherheitszugangsinformationen für den IAM-Nutzer.
Konfigurieren des Snapshot-Repositorys des Elasticsearch Service-Clusters
Als Nächstes müssen wir auf dem Elasticsearch Service-Cluster ein neues Snapshot-Repository erstellen. Damit teilen wir Elasticsearch Service mit, wo in S3 sich der Snapshot befindet, der für die Wiederherstellung verwendet werden soll. Melden Sie sich dazu bei Kibana an, wählen Sie Stack Management aus und navigieren Sie zu „Snapshot and Restore“. Klicken Sie auf Register a repository:
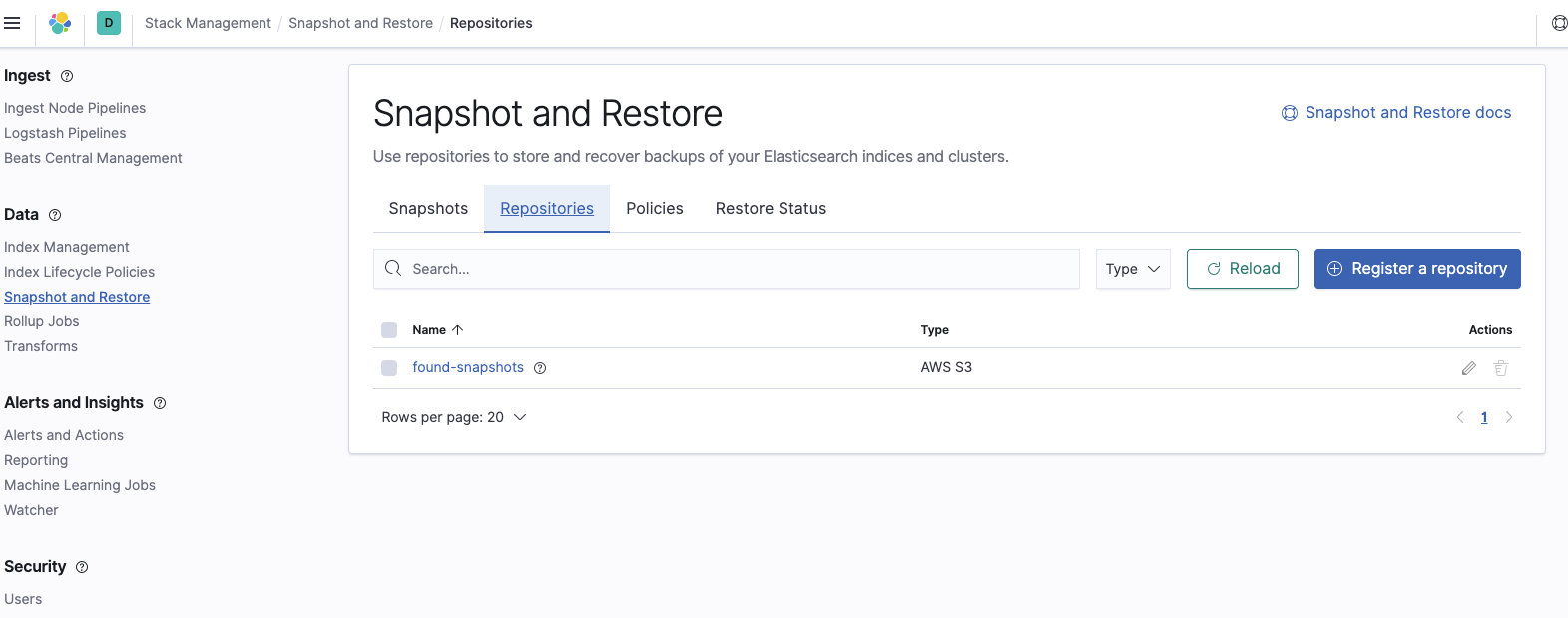
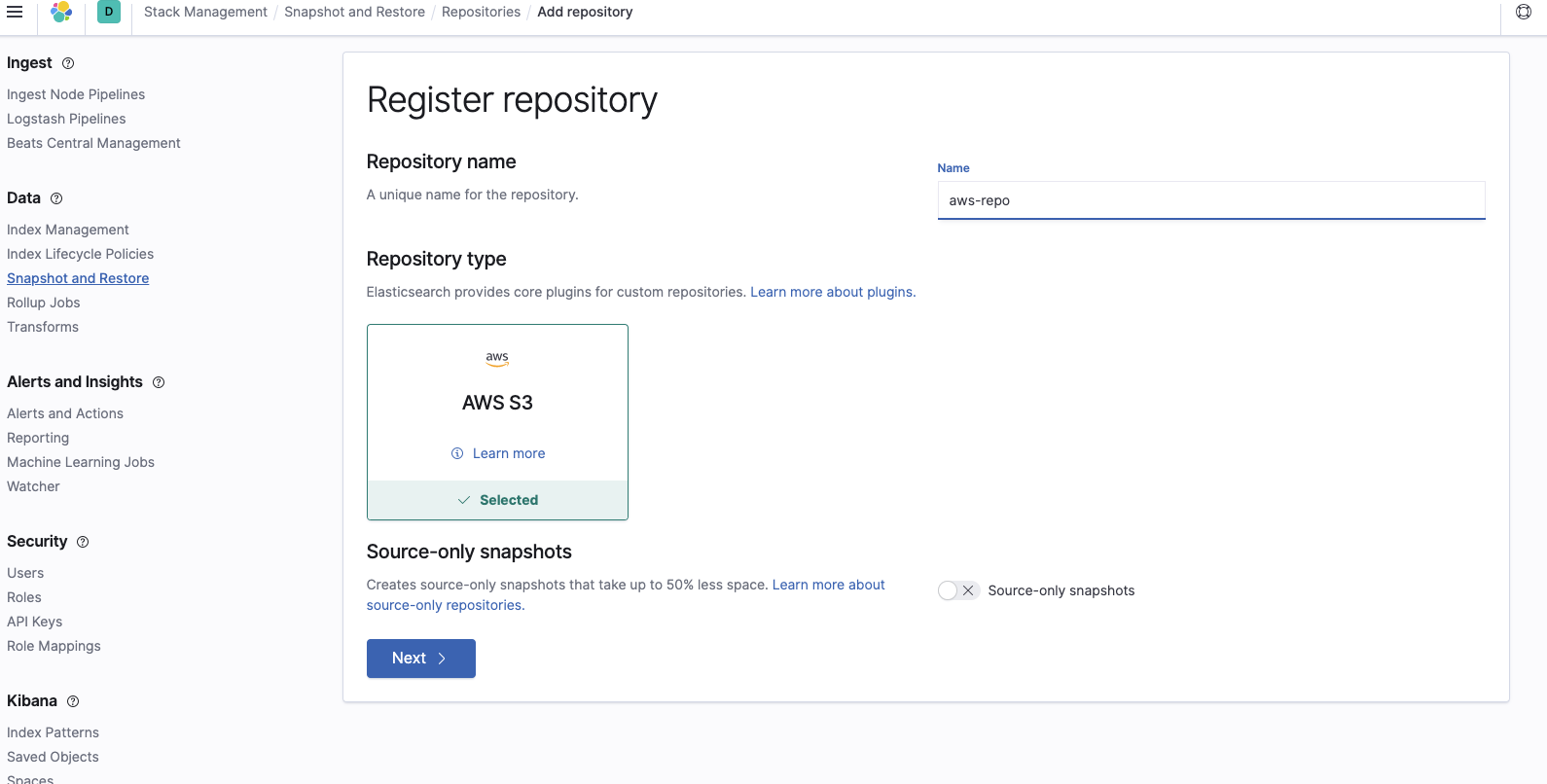
Fügen Sie den Namen des Buckets hinzu, in dem sich die Snapshots befindet:
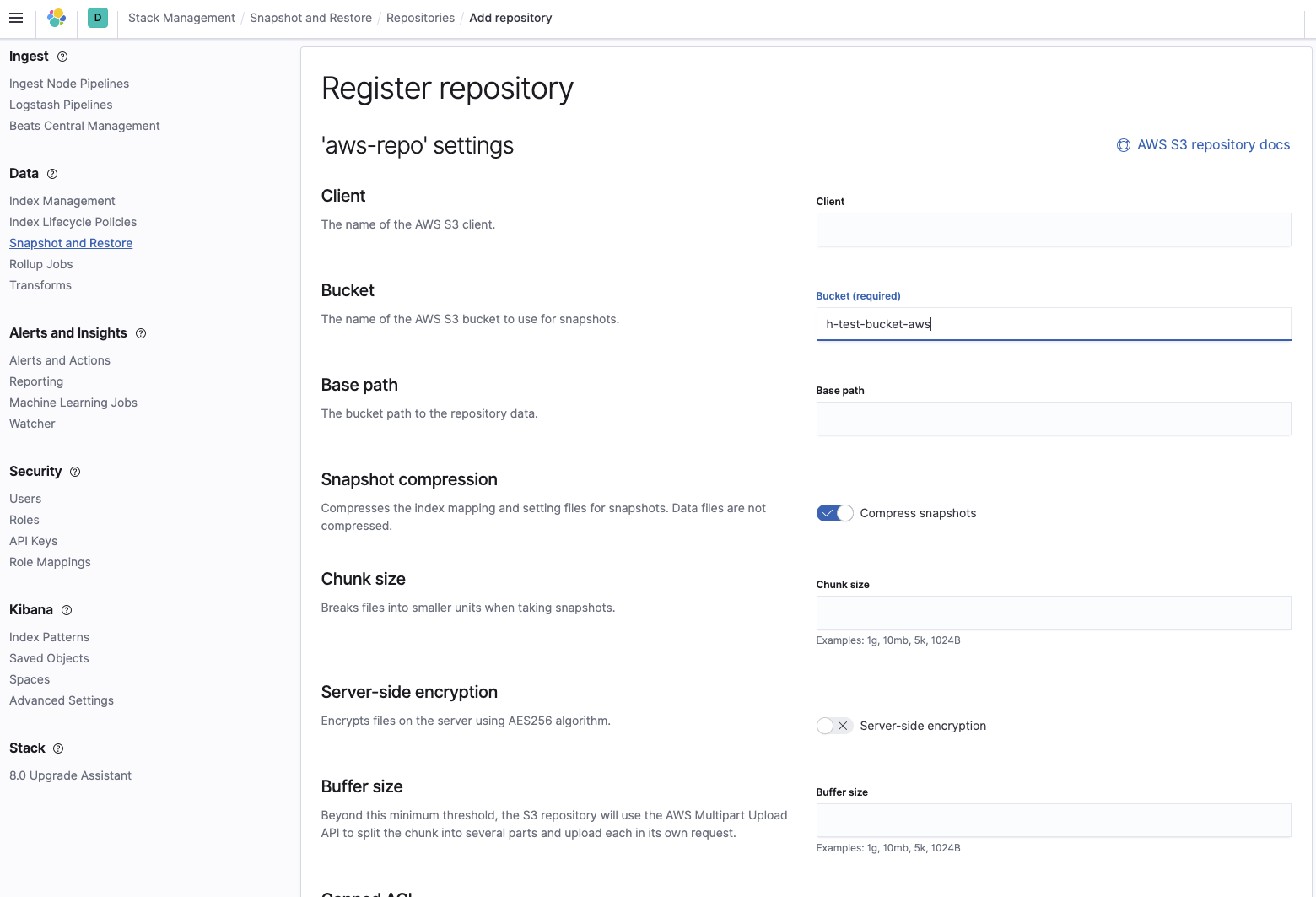
Vergewissern Sie sich anschließend, dass das Repository richtig konfiguriert wurde:
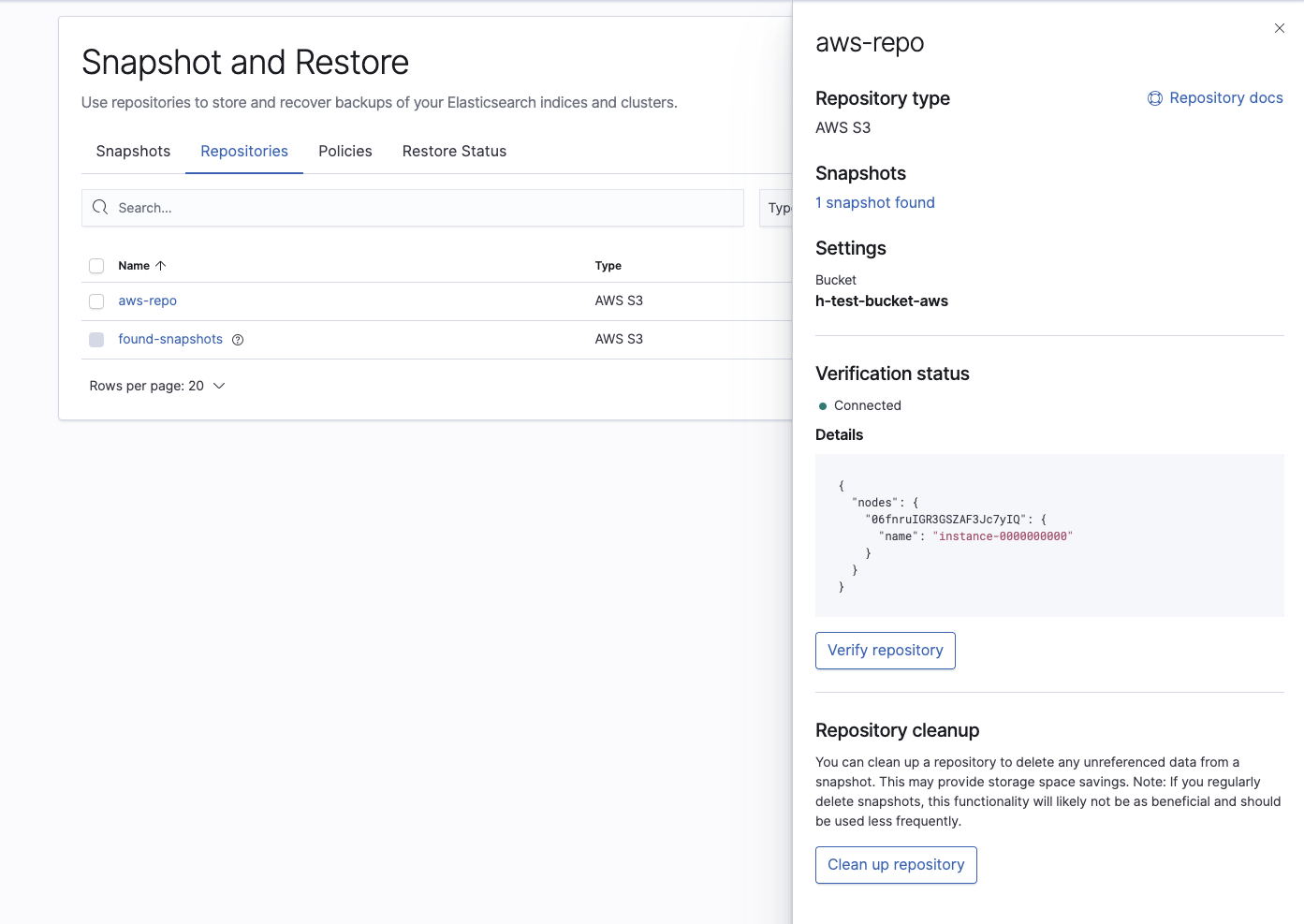
Kontrollieren Sie zum Schluss, ob der Elasticsearch Service-Cluster den Snapshot, den wir für die Wiederherstellung verwenden möchten, tatsächlich sehen kann:
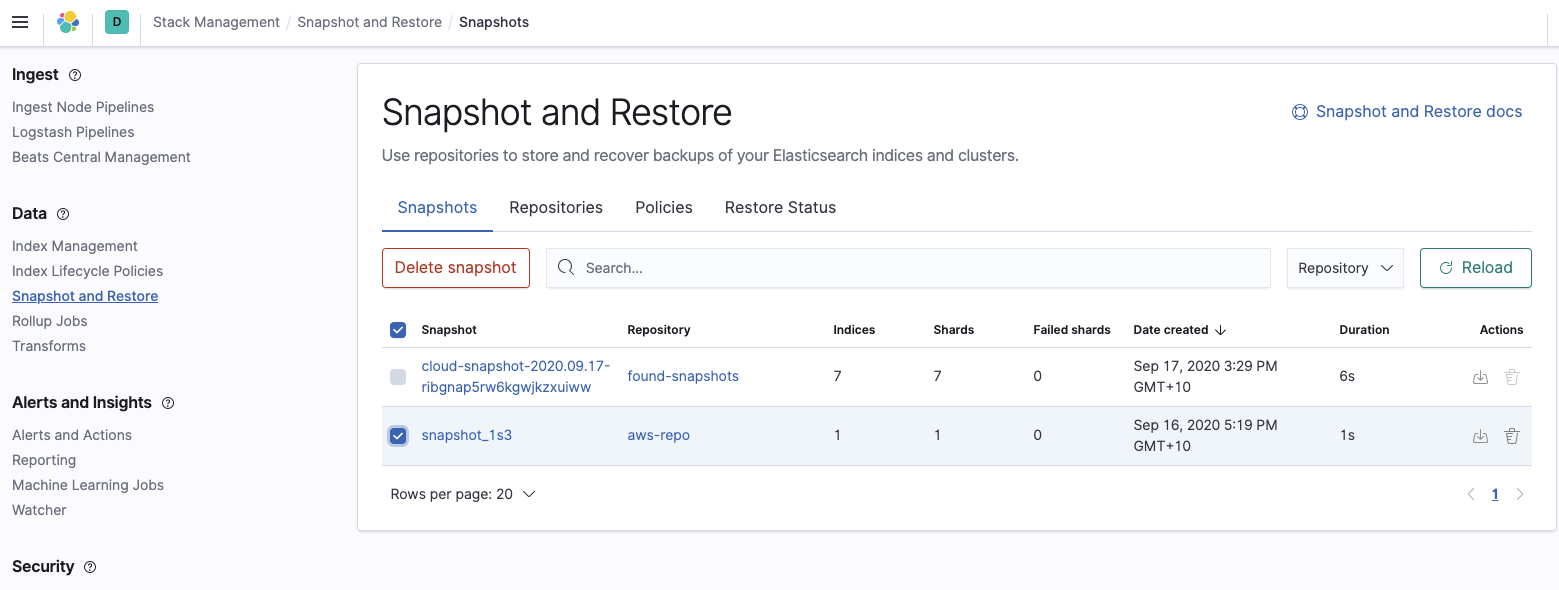
Wiederherstellen des Elasticsearch Service-Clusters aus dem Snapshot
Gehen Sie zum Wiederherstellen der Snapshot-Daten in der Elasticsearch Service-Konsole zur API-Konsole des Elasticsearch Service-Clusters und führen Sie die folgenden drei Befehle aus. Alle drei Befehle werden in der API-Konsole als POST ausgeführt.
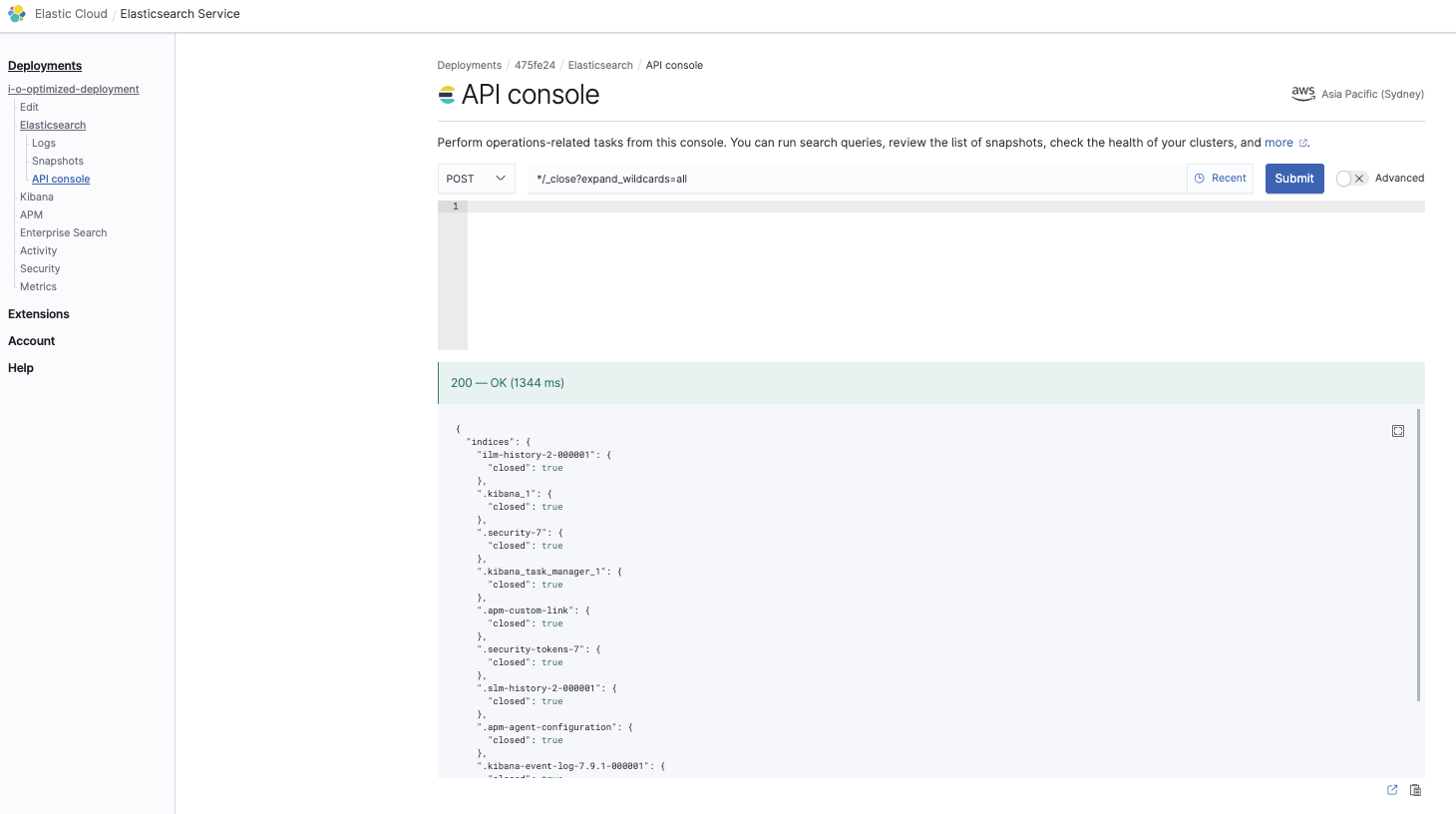
Schließen aller Indizes
*/_close?expand_wildcards=all
Damit sorgen wir dafür, dass als Erstes alle Indizes geschlossen werden, damit es bei der Wiederherstellung nicht zu Konflikten kommt:
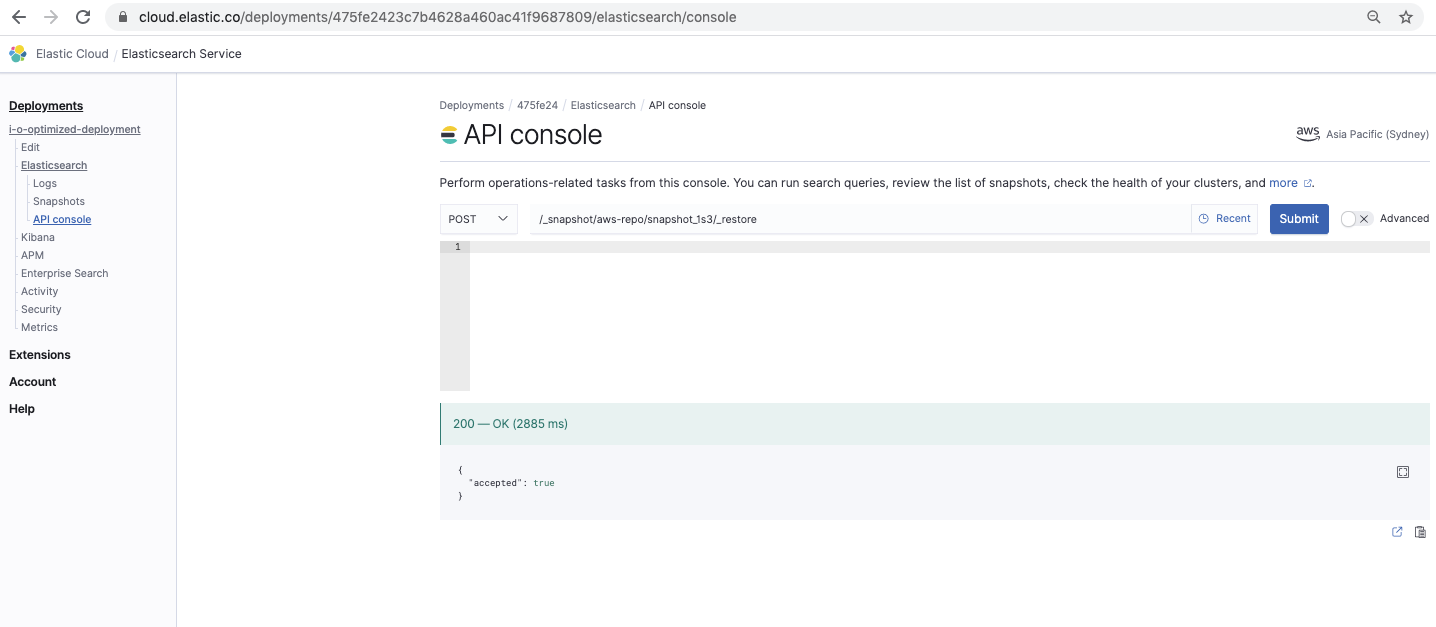
Wiederherstellen der Snapshot-Daten
/_snapshot// /_restore
Mit diesem Befehl stellen wir die Daten im Snapshot wieder her:
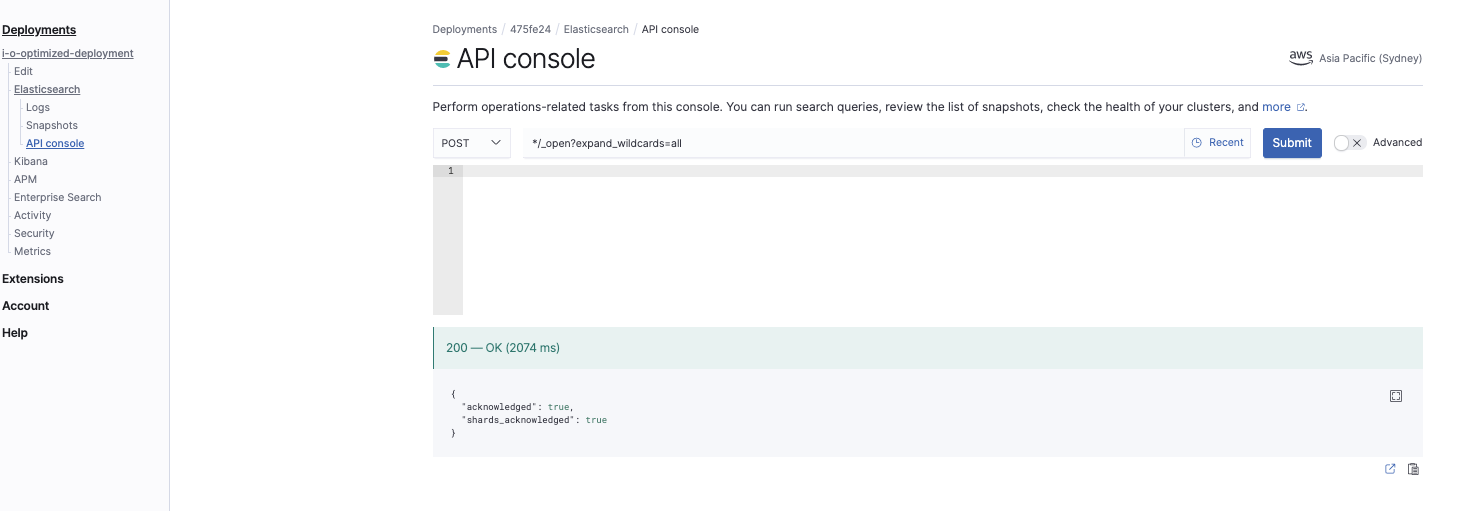
Öffnen aller Indizes
*/_open?expand_wildcards=all
Mit diesem Befehl öffnen wir alle Indizes:
Überprüfen der Wiederherstellung der Snapshot-Daten
Vergewissern Sie sich, dass alle Daten aus dem Snapshot mit allen Indizes wiederhergestellt wurden. Gehen Sie dazu zu Kibana und führen Sie in Dev Tools den folgenden Befehl aus:
GET _cat/indices
Jetzt sollte der neue Cluster auf Elasticsearch Service mit denselben Daten wie in dem selbstverwalteten Cluster ausgeführt werden, das als Basis für den Snapshot gedient hat. Sie können nun als Ingestionsziel für die Quellen, aus denen Daten ingestiert werden sollen, wie Beats oder Logstash, den neuen Elasticsearch Service-Endpoint festlegen, den Sie in der Elastic Cloud-Konsole finden.