Wie KeyBank mithilfe des Elastic Stack eine Enterprise-Monitoring-Lösung auf die Beine gestellt hat
Dieser Blogpost ist eine Zusammenfassung eines Community Talks bei der Elastic{ON} Tour Chicago 2019. Sind Sie an ähnlichen Talks wie diesem interessiert? Sehen Sie sich im Konferenzarchiv um oder informieren Sie sich über anstehende Elastic{ON}-Termine in Ihrer Nähe.
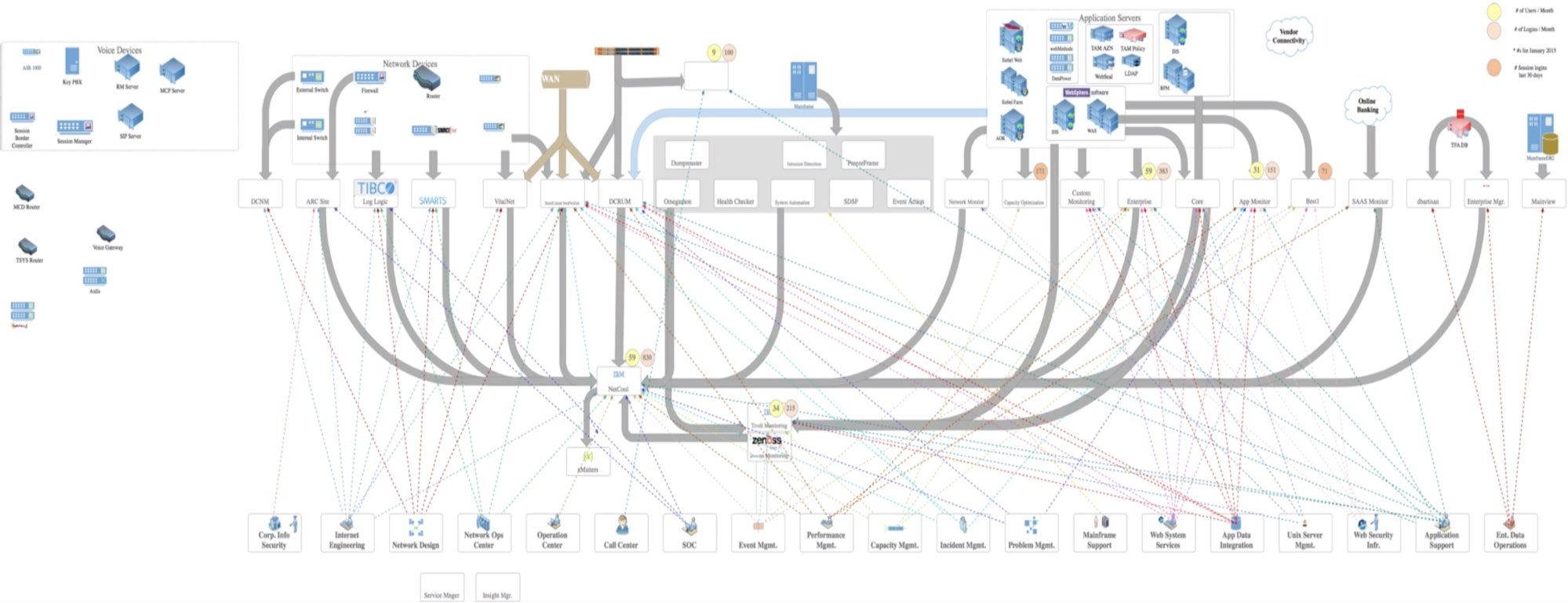
Die KeyBank ist eine der größten Banken in den USA. Und je größer die Bank geworden ist, desto größer ist auch ihr End-to-End-Monitoring-System geworden. Das Unternehmen betreibt über 1.100 Filialen und 1.400 Bankautomaten in 15 US-Bundesstaaten, und die dafür nötige Infrastruktur hat sich laut Mick Miller, Senior Product Manager, Cloud Native bei KeyBank, zu einer „Arche Noah des Designs“ entwickelt – von jeder Art gab es zwei. Das hat 21 verschiedene Dateninseln hervorgebracht. „Wir haben irgendwann festgestellt, dass bei uns die mittlere Zeit bis zur Problemlösung sehr viel länger war als die mittlere Zeit bis zur ersten Schuldzuweisung.“
Ran an die Wurzeln
Die schiere Menge an Systemen ohne eine einfache Möglichkeit, Daten siloübergreifend miteinander in Beziehung zu setzen, bedeutete, dass das Team keine Einblicke in die Wurzeln ihrer Probleme hatte. Aus den Filialen gab es zunehmend Beschwerden über die Langsamkeit der Workstations und auch die Bewertungen für die Mobile-Banking-App sanken immer weiter ab – aber ohne korrelierte Observability-Daten konnte man nicht wirklich etwas dagegen tun. Hinzu kam, dass der Speicherplatz für das Logging-System und das Metrikensystem immer knapper wurde, sodass an neue Monitoring-Initiativen gar nicht zu denken war. Gleichzeitig verlangte der Speicherplatzanbieter aber so viel für ein Lizenz-Upgrade, dass das von vornherein ausschied.
Je größer die Warteschlange der unerledigten Monitoring-Anfragen wurde und je weiter damit die Entwicklung eines neuen Systems in die Ferne rückte, desto größer wurde ein neues und noch größeres Problem: Kundenverlust wegen fehlender Leistung. So kam es beispielsweise vor, dass das System wiederholt zusammenbrach, wenn Kunden ein neues Konto eröffnen wollten, was lange Wartezeiten und ein negatives Kundenerlebnis zur Folge hatte. Und ein potenzieller Kunde, der nicht einfach ein neues Konto eröffnen kann, geht dann eben woanders hin.
Bessere Observability mit Elasticsearch
Da die Systeme der KeyBank nicht mehr in der Lage waren, die Logdaten und Metriken bereitzustellen, die für eine Untersuchung von Problemen jenseits sicherheitsrelevanter Belange nötig waren, hat sich das Unternehmen für den Elastic Stack entschieden. Mithilfe eines eigens zu Entwicklungszwecken eingerichteten Elasticsearch-Clusters wurden auf Tausenden von Workstations im gesamten Filialnetz Winlogbeat und Metricbeat bereitgestellt, um Log- und Metrikdaten indexieren zu können. Nur wenige Tage später traten durch die gewonnenen Einblicke die Ursachen für die Probleme zutage: die Datenträger waren durchgängig einer hohen E/A-Last ausgesetzt, es stand nur sehr wenig Hauptspeicher zur Verfügung und das Netzwerk war komplett gesättigt.
Dass immer mehr KeyBank-Mitarbeiter Visualisierungen der Reaktionszeiten in Kibana zu Gesicht bekamen, verschärfte die Dringlichkeit noch weiter. Das gesamte System bedurfte einer massiven Auffrischung, und die Geschäftsführung gab schließlich grünes Licht zur Bereitstellung des ersten Produktionsclusters. Durch den neuen Zustrom von Observability-Daten erhielt das Team endlich die Sichtbarkeit, die es so nötig brauchte. Allerdings tat sich ein neues Problem auf: Die Entwicklungsumgebung versank förmlich im Strom der eingehenden Daten. Es musste also ein Wachstumsplan her.
„Es gibt eine schlechte und eine gute Nachricht. Die schlechte: Eine genaue Vorhersage der Arbeitslast ist praktisch unmöglich. Die gute: Wir haben daraus gelernt, dass wir uns ändern mussten. Das hat uns dazu gebracht, die Architektur unseres Systems so zu gestalten, dass wir in der Lage waren, unsere Systeme umzukonfigurieren – ohne jede Downtime.“ – Mick Miller, KeyBank
Chirurgisches Skalieren
Um den wachsenden Monitoring-Anforderungen gerecht zu werden, entwickelt die KeyBank das Elasticsearch-Monitoring-System mithilfe eines iterativen Ansatzes weiter, um eine Skalierung ihres End-to-End-Systems zu ermöglichen. Nach ein wenig Feinjustierung folgt ihre Architektur jetzt ein paar Kernprinzipien, die es der Bank erlauben, „chirurgische“ Änderungen vorzunehmen, ohne den Betrieb des Gesamtsystems zu beeinträchtigen. Jede der logischen Schichten muss die folgenden Voraussetzungen erfüllen:
- unabhängige Skalierbarkeit
- hohe Verfügbarkeit
- Fehlertoleranz
Glücklicherweise sind das genau die Bereiche, in denen Elasticsearch mit seiner horizontalen Architektur zu glänzen vermag. Zwischen Ingestieren und indexierter Verfügbarkeit der Daten vergeht jetzt keine halbe Sekunde mehr, und wenn diese SLA-Kennzahl nicht erreicht wird, reicht ein einfaches Skalieren. „Alle Daten an einem zentralen Ort zu haben, hat eine Menge unerwarteter Vorteile – und Elasticsearch ist eine tolle Lösung dafür“, so Miller.
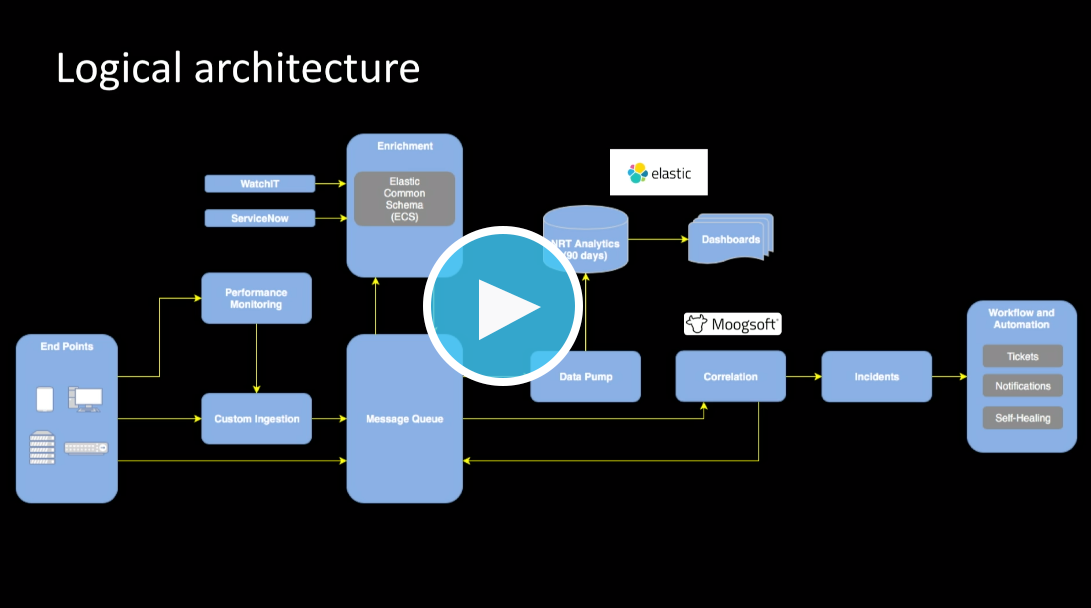
Wenn Sie mehr darüber erfahren möchten, wie (und wann) Sie Ihr Elasticsearch-System skalieren sollten, sehen Sie sich die Elastic{ON} Tour Chicago 2019-Präsentation dazu an, wie die KeyBank mithilfe von Elastic eine Enterprise-Monitoring-Lösung auf die Beine gestellt hat. In dieser Präsentation wird auch erläutert, wie die KeyBank Automatisierung und ausbalancierte Virtualisierung gegen physische Computing-Ressourcen implementiert und damit mehr als 5 Millionen US-Dollar gespart hat.