最大程度提高向集群添加节点后的 Elasticsearch 性能


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
通过向 Elasticsearch 集群添加节点,您能够扩展集群以完成大量工作负载。至为关键的一点是理解扩展 Elasticsearch 集群的最优方法,确保不会降低性能。
Elasticsearch 是一种快速且强大的搜索技术。随着数据量的增加,您需要充分利用 Elasticsearch 卓越的可扩展性。向集群添加更多节点后,您不仅能够增加集群可容纳的数据量,还能提高可同时处理的请求数量,并缩短返回结果所需的时间——通常情况下是如此。
如果整个周末都在努力调查为什么向 Elasticsearch 集群添加节点后,反而使得系统不稳定、宕机,人们越来越沮丧,而且公司营收减少,那可真有点糟糕。所以我们讨论一些常见配置,要是采用这些配置的话,扩展集群时可能会遇到巨大的性能瓶颈。
我们有一场特别棒的网络研讨会,叫做 Elasticsearch sizing and capacity planning(Elasticsearch 规模确定和容量规划)。其中定义了集群上的四大硬件资源:
- 计算 - 中央处理器 (CPU),集群能够以多快的速度完成工作。
- 存储 - 硬盘驱动器 (HDD) 或固态硬盘 (SSD),集群能够长期存储的数据量。
- 内存 - 随机存取存储器 (RAM),集群可同时完成的工作量。
- 网络 - 带宽,节点以多快的速度在彼此之间传输数据。
最常见的两个性能瓶颈是计算和存储。如果不够用,这会在极大程度上影响集群的数据节点。其他节点角色,例如主节点、采集节点或转换节点,是另一个单独的讨论主题。
注意:为简单起见,本文专注于扩展单个 Elasticsearch 集群。在共享硬件上运行多个集群会使复杂程度再上一个层级。
硬件资源的分配情况并不相同,具体取决于平台。例如,节点是硬件、虚拟机,还是基于容器的系统?
当添加 Elasticsearch 节点是增加容量时
添加专属的硬件节点
提高集群性能的最可靠方法是添加新硬件。添加新的专属硬件会增加所有四项主要资源。除了一种主要例外情况(稍后会讲解),添加新硬件节点都能提升集群性能。
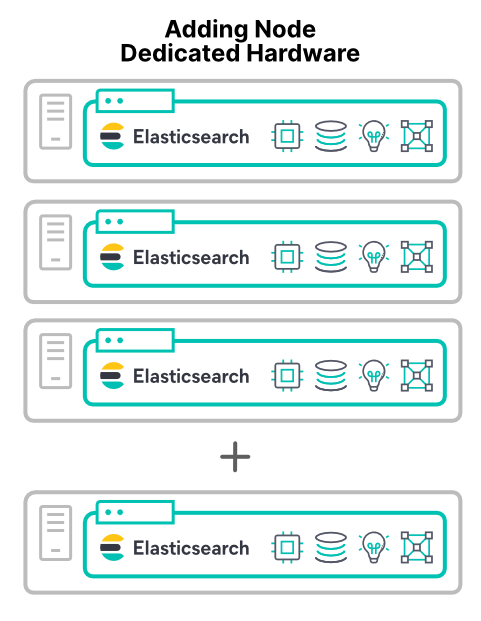
在新主机上的虚拟机或容器中添加节点
无论是以虚拟机 (VM) 还是容器的形式添加节点,都是另外一种情况。当将新主机上的新节点分配给集群时,系统会授予更多硬件资源。更多的 CPU 核心,更多的 RAM,更多的存储,更多的总带宽。
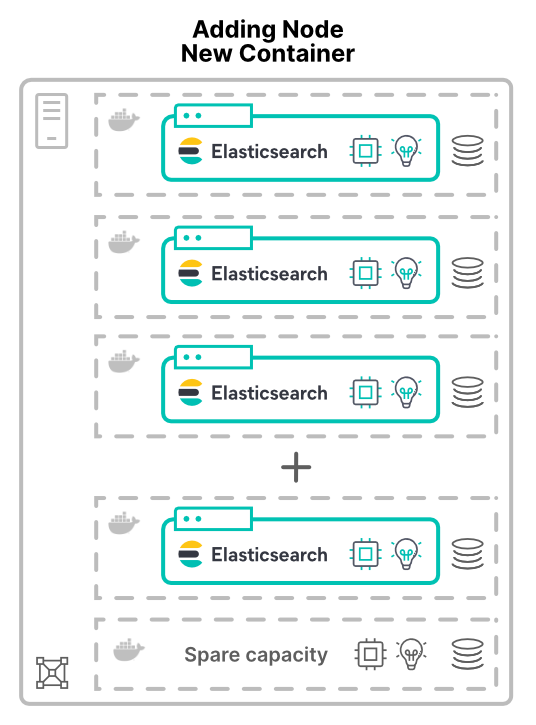
对应用程序进行虚拟化(或容器化)的原因之一就是提高硬件利用率。这时,添加节点只会增加可供集群使用的硬件数量。随之而来的性能提升状况取决于共享资源的限额。
当添加节点是分配容量时
无论是使用 VM 还是容器分配硬件,Elasticsearch 节点最终都要共享硬件。这些考量因素适应于所有部署模型,包括 Elastic Cloud Enterprise (ECE) 和 Elastic Cloud on Kubernetes (ECK)。
造成计算瓶颈
使用虚拟机分配 CPU 通常是一种可预测的做法:为每个 VM 分配要使用几个核心。使用容器的话,CPU 共享状况就没有这么简单。
诸如 Kubernetes 等容器系统会以千分之一 CPU(又称作毫核)为单位来衡量 CPU 资源。请求和限额之间存在巨大区别。只定义请求的 CPU 的话,会允许容器最高使用主机 CPU 的 100%。但是,对 CPU 限制太多的话,会让昂贵的资源闲置。
> 提示:threadpools 开始时会使用 CPU 核心。使用容器的话,建议验证您的 threadpool 配置是否按照预期的方式工作。
在 Kubernetes 中,全部容器的 CPU 限额可能会超过可用的总硬件。这是基于以下假设:并非所有容器的 CPU 利用率都同时处于 100%。
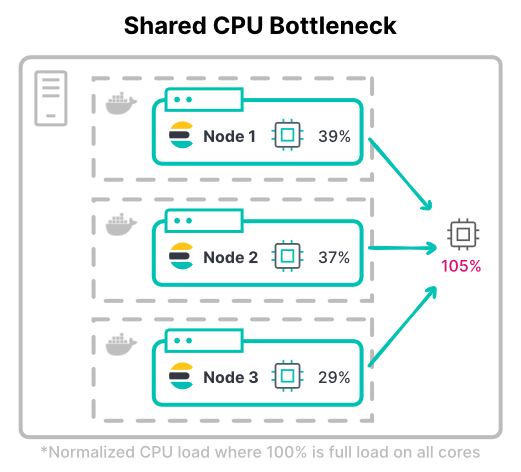
考虑集群的最大吞吐量。在计算密集型工作负载中,节点在索引时通常需要所分配的全部 CPU 限额。最常见的索引密集型工作负载是大数据量的日志集群。
> 提示:决定 CPU 限额时,要同时考虑 CPU 利用率的峰值和典型值。同时还要考虑多大的 CPU 限制是可接受的。
造成存储瓶颈
很难预防存储瓶颈。因为存储是按照空间(而不是按照吞吐量)来分配的。当 Elasticsearch 节点的存储空间不足时,节点会达到低磁盘水印,并且会停止分片分配。
无论是 VM 还是容器,大部分平台都没有一种简单的方式来限制存储设备的利用率。对于每秒的输入/输出操作 (IOPS) 或读取/写入吞吐量,大部分环境并没有可配置的限额。即使推荐的 XFS 文件系统也只允许基于磁盘空间的磁盘配额。
没有限额的话,具有存储密集型工作负载的任何容器都可能使存储硬件饱和。这会让共享此硬件的其他节点无法使用硬件。对于大型部署,其/数据目录会发生错误。当多个节点将其/数据目录挂载到同一个存储区域网络 (SAN) 硬件时,来自所有节点的总吞吐量会让设备无法应对。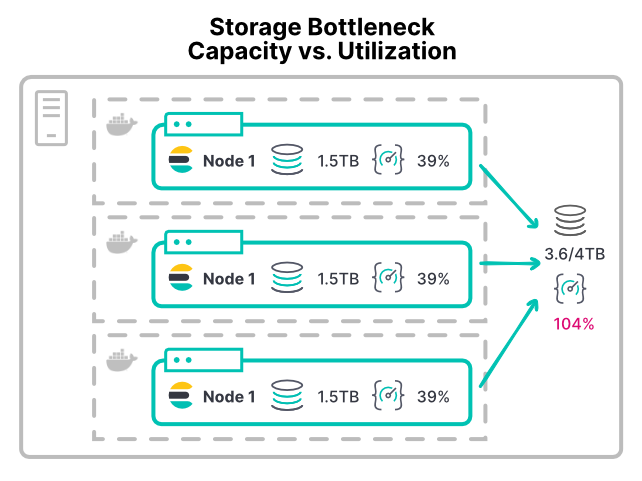
使用类似这样的容器配置,添加更多节点的确会向集群分配更多 CPU 和内存。但这会进一步分配既有的存储吞吐量。这会使得添加节点后,磁盘操作的时间变长,性能变差。
> 提示:当节点的存储吞吐量不够用时,一个早期预警信号是 CPU I/O 等待时间超过 10%。在 VM 或容器主机上可以找到这一指标,因为单独的容器并不会报告这一指标。
当添加节点毫无成效时
还有阻碍有效扩展的最后一个陷阱。即使添加实体硬件时,也会发生这一配置瓶颈。
由于分片数量不足,限制索引吞吐量
无论使用什么方法,添加节点都不会更改索引上的分片数量。如果某个索引有 2 个主分片和 1 个副本集,则总共有 4 个分片。在一个 4 节点集群上,为每个节点只设置一个分片是一种很好的方法,能够最大程度提高索引吞吐量。
随着入栈数据量的增加,我们向集群添加了另外 2 个节点。这表示集群总资源增加了 50%,但我们看到采集速率的提高百分比为 0%。为什么?
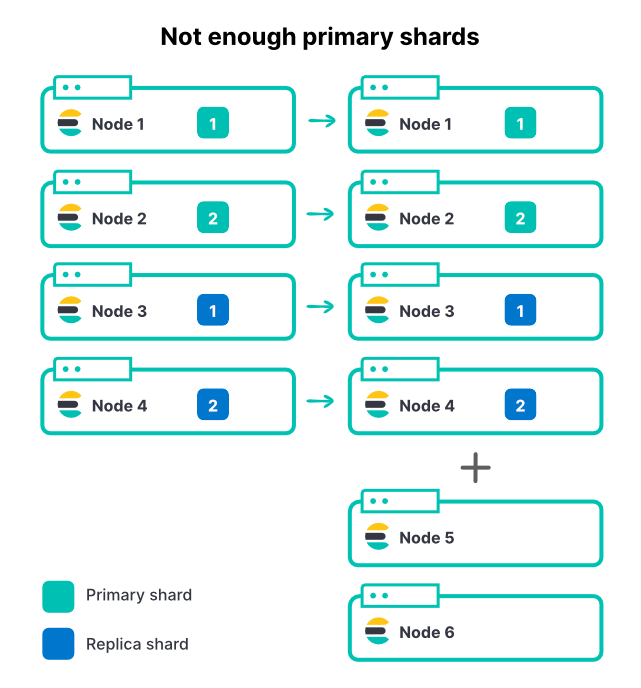
在这个例子中,新节点无法在索引时发挥作用,因为所有分片都已经分配完毕。如要让索引利用更多节点,则主节点数量也需要增加。如果您在单个集群内有多个活跃索引(这种情况很常见),则即使添加节点会增加集群的总吞吐量,但由于主分片数量有限,最活跃的索引仍然会受到限制。在规划容量时,为 Elasticsearch 选择正确的分片数量是很重要的一步。
所以,在上面的示例中,将主分片数量从 2 增加到 3,再考虑到每个分片 1 个副本,所以总分片数量为 6,可以在 6 个节点之间分配这些分片。
> 提示:设置 index.routing.allocation.total_shards_per_node [docs] 能够确保安全。然而,将这一限额设置过低会导致分片长期保持未分配状态。
结论
向 Elasticsearch 集群添加节点会改善性能吗?视情况而定。如果节点共享硬件,您需要注意共享资源瓶颈。两个常见的瓶颈是 CPU 和存储的利用率过高。您需要仔细规划,并采用良好的分片策略,这才能确保添加节点会提升性能。
在 Elastic Cloud 中运行的诸多优势之一是,我们的团队会专注于准确识别和解决这些类型的共享资源性能问题。欢迎立即开始试用云服务:https://www.elastic.co/cn/cloud/
同时,您可以观看 Elasticsearch sizing and capacity planning(Elasticsearch 规模确定和容量规划)网络研讨会,更深入地了解 Elasticsearch 的性能。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印