如何从自管型 Elasticsearch 迁移至 AWS 上的 Elastic Cloud
我们看到越来越多的客户将本地部署工作负载迁移到云端。Elasticsearch 已经有好几年的历史,我们的用户和客户通常都在本地部署中自行管理。Elastic Cloud 上的 Elasticsearch Service(我们的托管型 Elasticsearch 服务)运行于许多不同地区的 Amazon Web Services (AWS)、Google Cloud 和 Microsoft Azure 上,是使用 Elastic Stack 和我们的企业搜索、可观测性和安全解决方案的最佳方式。
如果您想改变自行管理 Elasticsearch 的现状,Elasticsearch Service 将负责以下事项:
- 配置和管理底层基础架构
- 创建和管理 Elasticsearch 集群
- 扩展和缩减集群
- 升级、打补丁和创建快照
这会让您有更多的时间和精力去解决其他的挑战。
这篇博文探讨了迁移到 Elasticsearch Service 的方法,即通过为 Elasticsearch 集群创建快照,然后在 Elasticsearch Service 上还原快照来完成迁移。
创建集群快照
从自管型 Elasticsearch 迁移到 Elasticsearch Service 时,首先要考虑的是您希望使用哪个云服务提供商以及要部署到的区域。这通常取决于您部署的现有工作负载、云策略以及一系列其他因素。
下面我们将介绍适用于迁移到 AWS 上的 Elasticsearch Service 的过程。之后,针对 Google Cloud 和 Azure 的迁移过程也将很快发布。
将 Elasticsearch 集群数据移动到另一个集群的最简单方法是:创建集群的快照,然后使用该快照将数据还原到新的 Elasticsearch Service 集群中。
执行集群快照的方法有多种。最简单的是执行一次性快照操作。
假设您的 Elasticsearch 不断地采集数据,一次性快照操作的缺点是,在创建快照和在新集群中还原快照之间存在时间延迟,这可能会造成数据丢失。为了最大限度地减少这种滞后,建议创建快照生命周期策略。如果您的 Elasticsearch 集群不经常采集数据,例如用于搜索用例,那么一次性快照完全可以胜任。
在创建本地集群快照之前,您需要配置将存储本地集群快照的 AWS S3 存储桶。在 AWS 上运行的新 Elasticsearch Service 集群将从该存储桶还原集群状态。
为此,需要完成以下几大步骤:
- 配置云存储(在本例中为 AWS S3 存储桶)
- 配置本地快照存储库
- 设置快照策略
- 在 Elasticsearch Service 上配置新集群
- 配置 Elasticsearch Service 集群自定义快照存储库
- 从本地快照还原 Elasticsearch Service 集群
配置云存储
- 创建 S3 存储桶。S3 存储桶应位于为您的 Elasticsearch Service 集群所选的同一区域中:
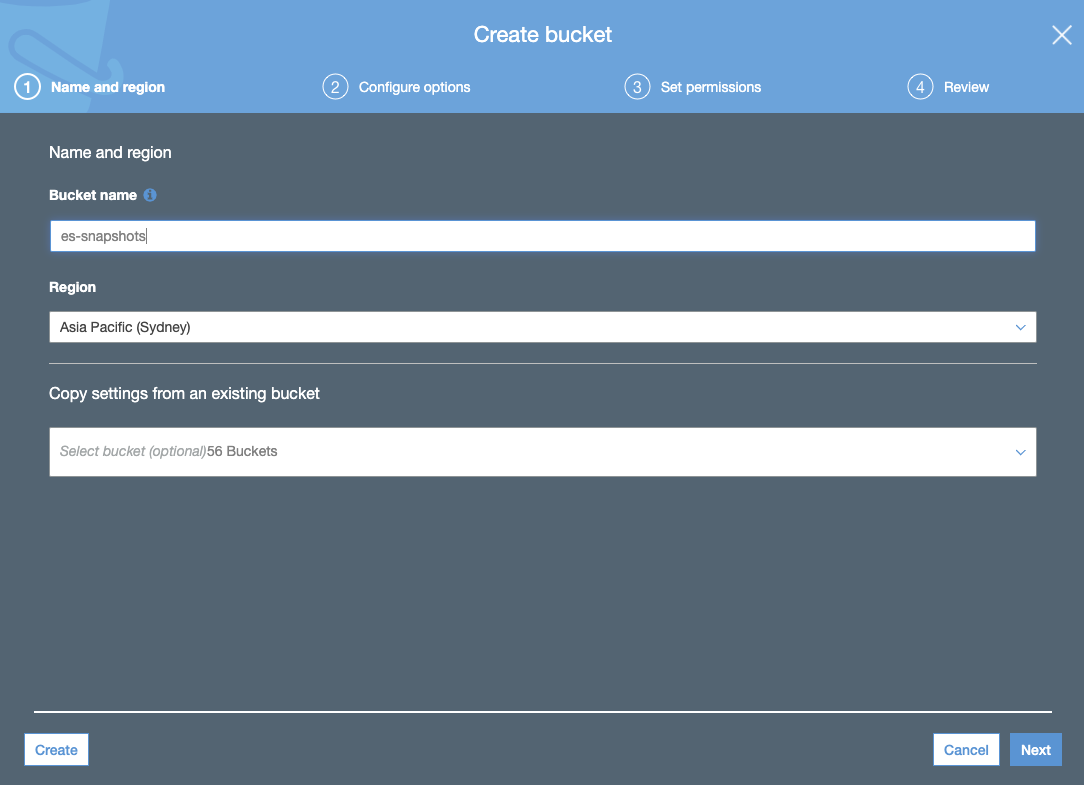
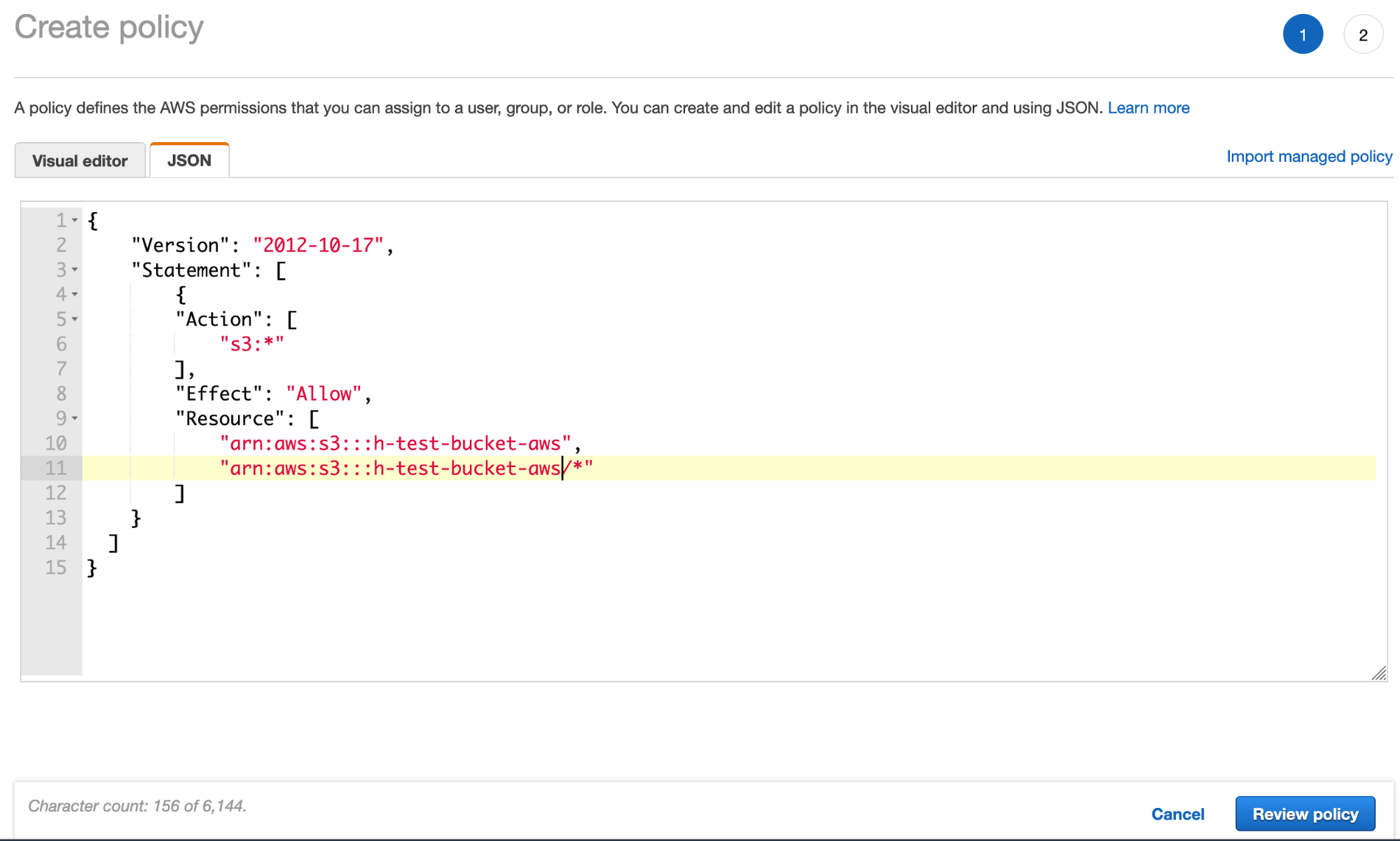
- 通过 JSON 选项卡创建 S3 存储桶策略并添加 S3 存储桶策略 JSON(使用您的存储桶名称):
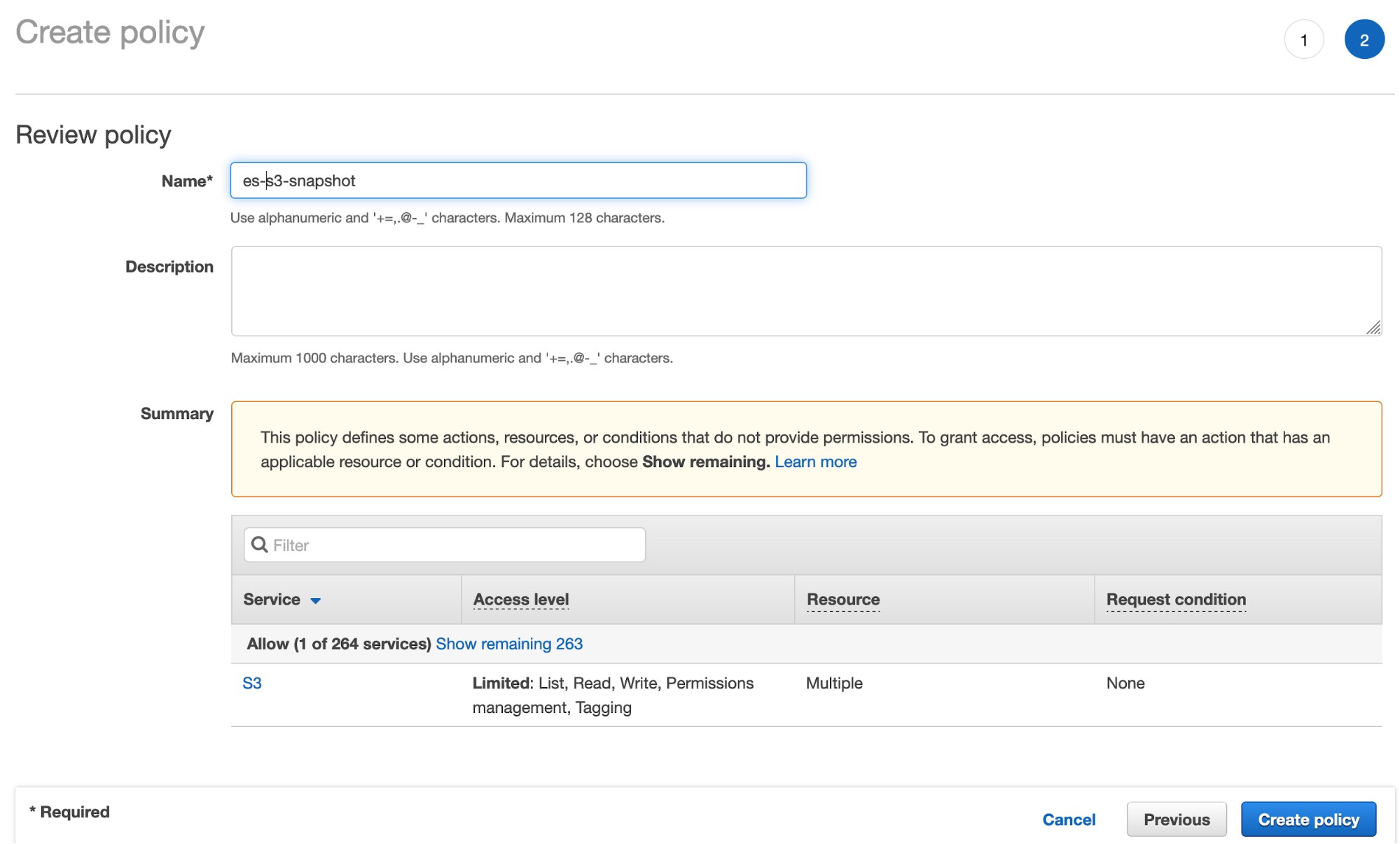
- 单击复查策略并为您的策略命名:
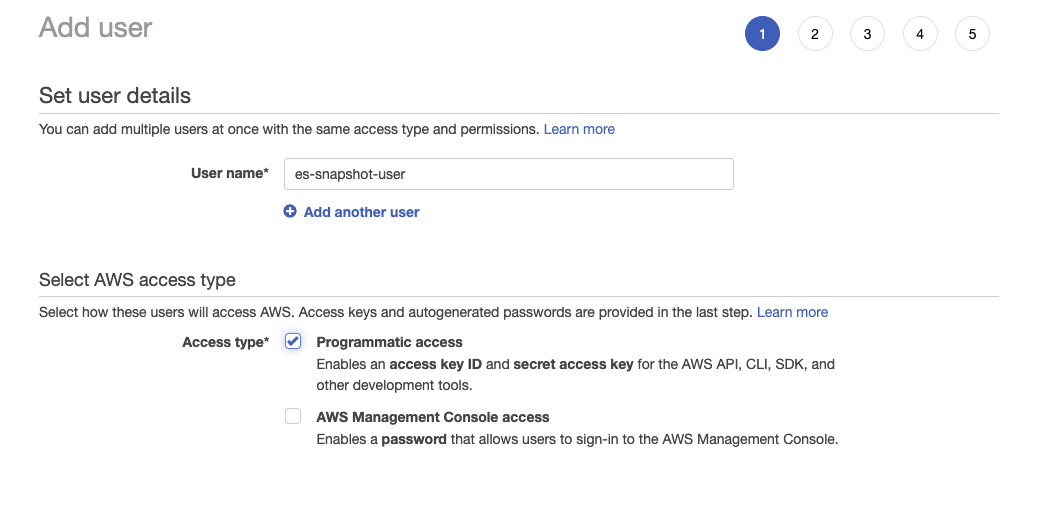
- 创建 IAM 用户并指定上面创建的 S3 存储桶策略:
- 单击下一步:权限,选择直接附加现有策略,然后查找您在上一步中创建的策略:
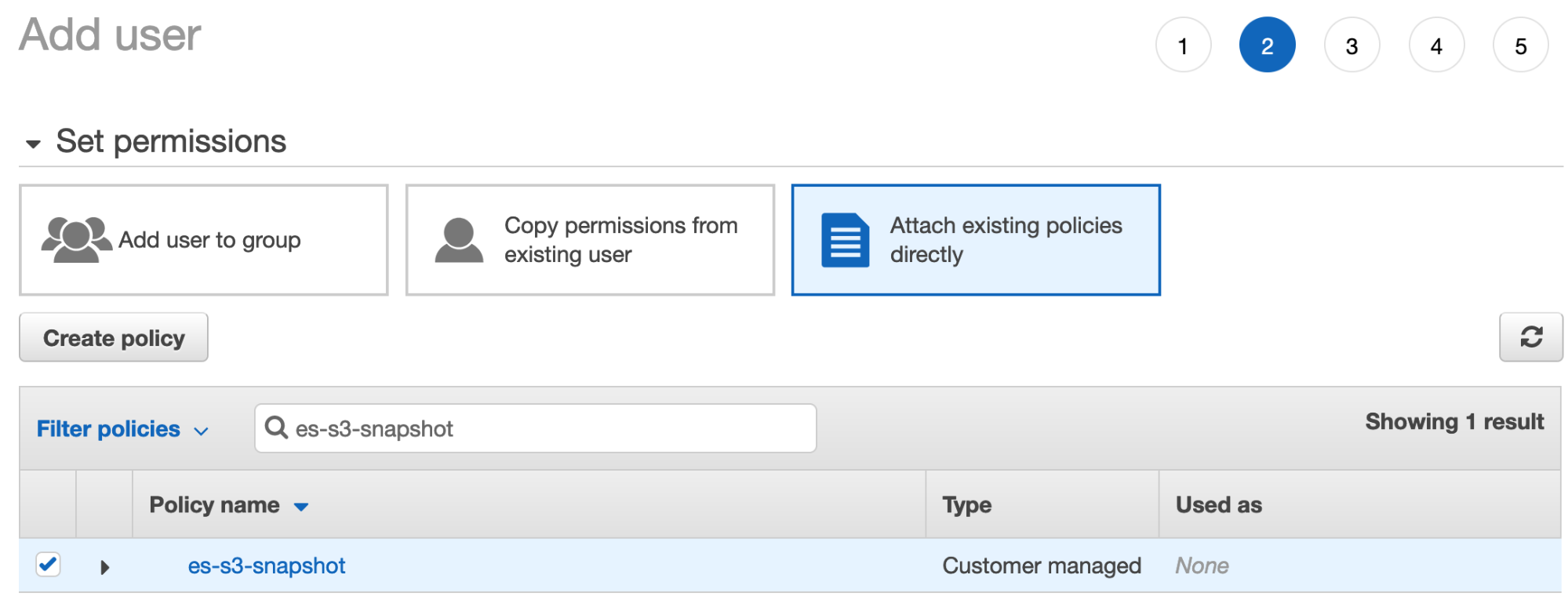
- 确保勾选这个策略,然后单击下一步:标签。 您可以跳过添加标签这一步并单击创建用户。
- 下载用户安全凭证。
配置本地快照存储库
1. 安装 S3 插件
通过在 Elasticsearch 主目录中的每个本地 Elasticsearch 节点上运行以下命令,在您的本地部署中安装 Elasticsearch S3 插件:
sudo bin/elasticsearch-plugin install repository-s3
运行此命令后,您必须重新启动节点。
2. 配置 S3 客户端权限
通过运行以下命令配置本地部署集群 S3 客户端权限:
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
这一步是必需的,这样本地集群才能获得将快照写入 S3 所需的凭证。Access_key 和 secret_key 可从上一步中创建的 IAM 用户处获得。
设置快照策略
1. 配置快照存储库
通过在 Kibana 开发工具中运行以下命令,在本地集群中配置 S3 快照存储库。我们在这里告诉本地集群要将快照写入哪个 S3 存储桶。您刚刚创建的 IAM 用户应具有读写这个 S3 存储桶的权限。
PUT _snapshot/{ "type": "s3", "settings": { "bucket": " " } }
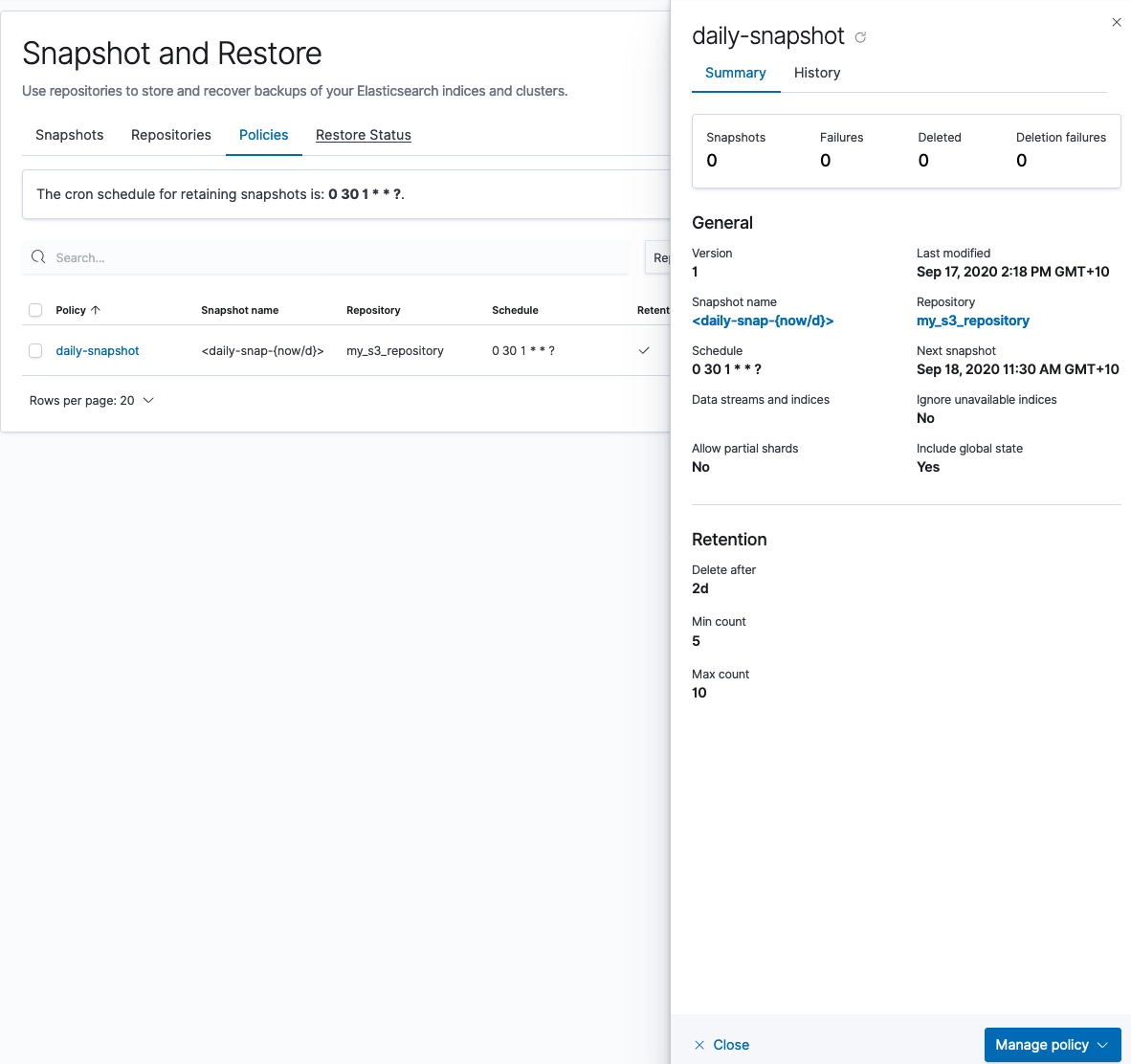
2. 创建快照策略
接下来,您将在本地集群中创建快照策略,将快照存储在新创建的 S3 存储桶中:
您也可以在 Kibana 开发工具中创建一次性快照:
PUT /_snapshot// ?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false }
通过在开发工具中运行以下命令,验证快照是否正常运行:
GET _snapshot//_all
在 Elasticsearch Service 上配置新集群
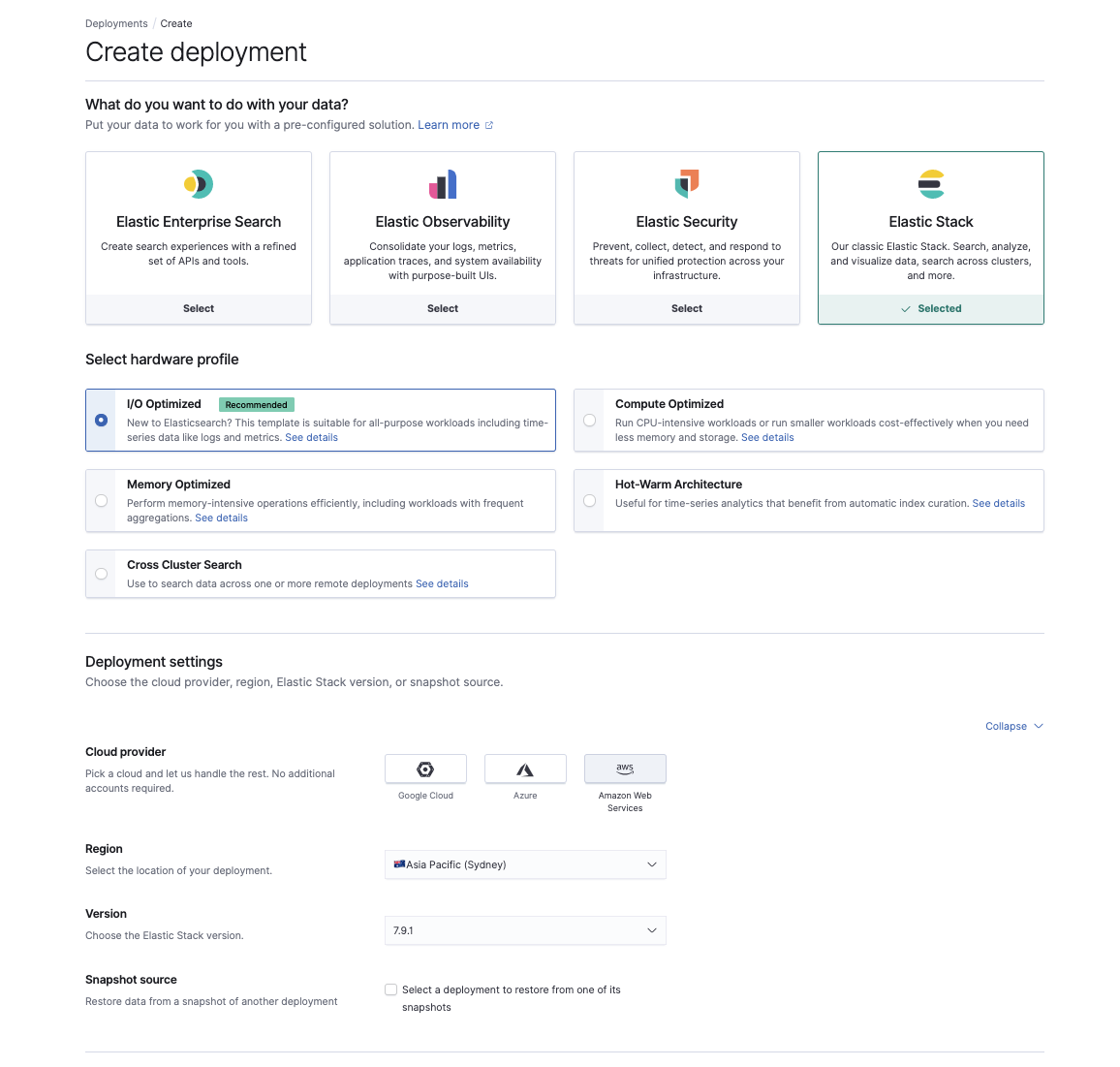
一旦我们在 S3 上存储了快照,就可以在 Elasticsearch Service (cloud.elastic.co) 上配置新集群了。您可以在此处选择最能反映您的现有工作负载、AWS 区域和 Elasticsearch 版本的用例。
在 Elasticsearch Service 控制台中,配置集群密钥库设置:
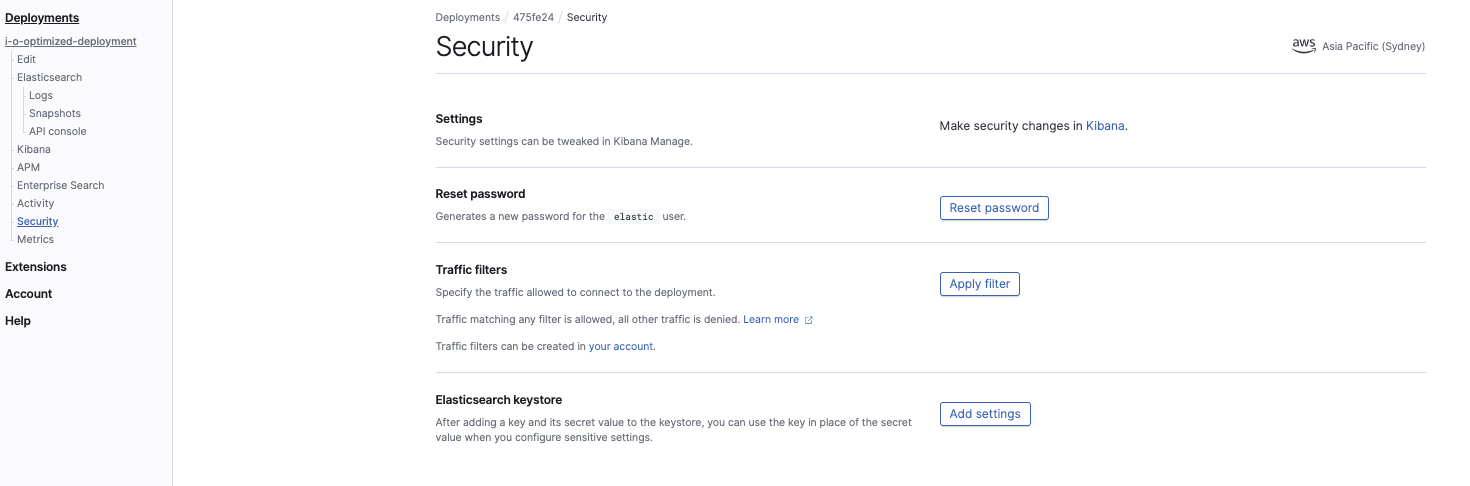
我们需要配置以下两个设置:
s3.client.default.access_key s3.client.default.secret_key
这一步是必需的,这样 Elasticsearch Service 集群才能获得从 S3 存储桶读取快照的权限。这些密钥将与 IAM 用户安全凭证的作用相同。
配置 Elasticsearch Service 集群自定义快照存储库
现在,我们必须在 Elasticsearch Service 集群上创建一个新的快照存储库。这会告诉 Elasticsearch Service 我们要还原的快照位于 S3 中的哪个位置。为此,请登录 Kibana,选择堆栈管理,然后导览到“快照和还原”设置。选择注册存储库:
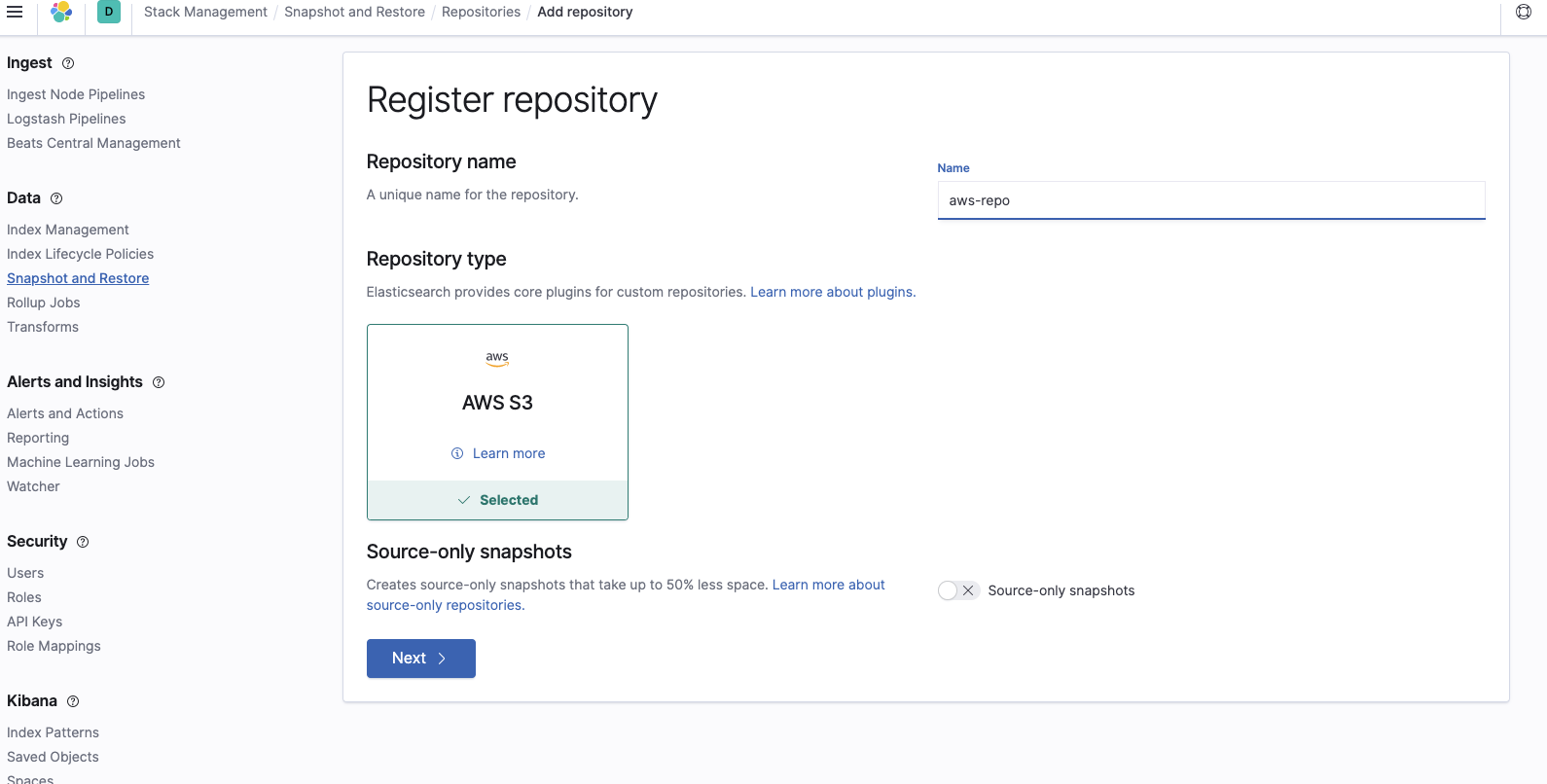
添加快照所在的存储桶名称:
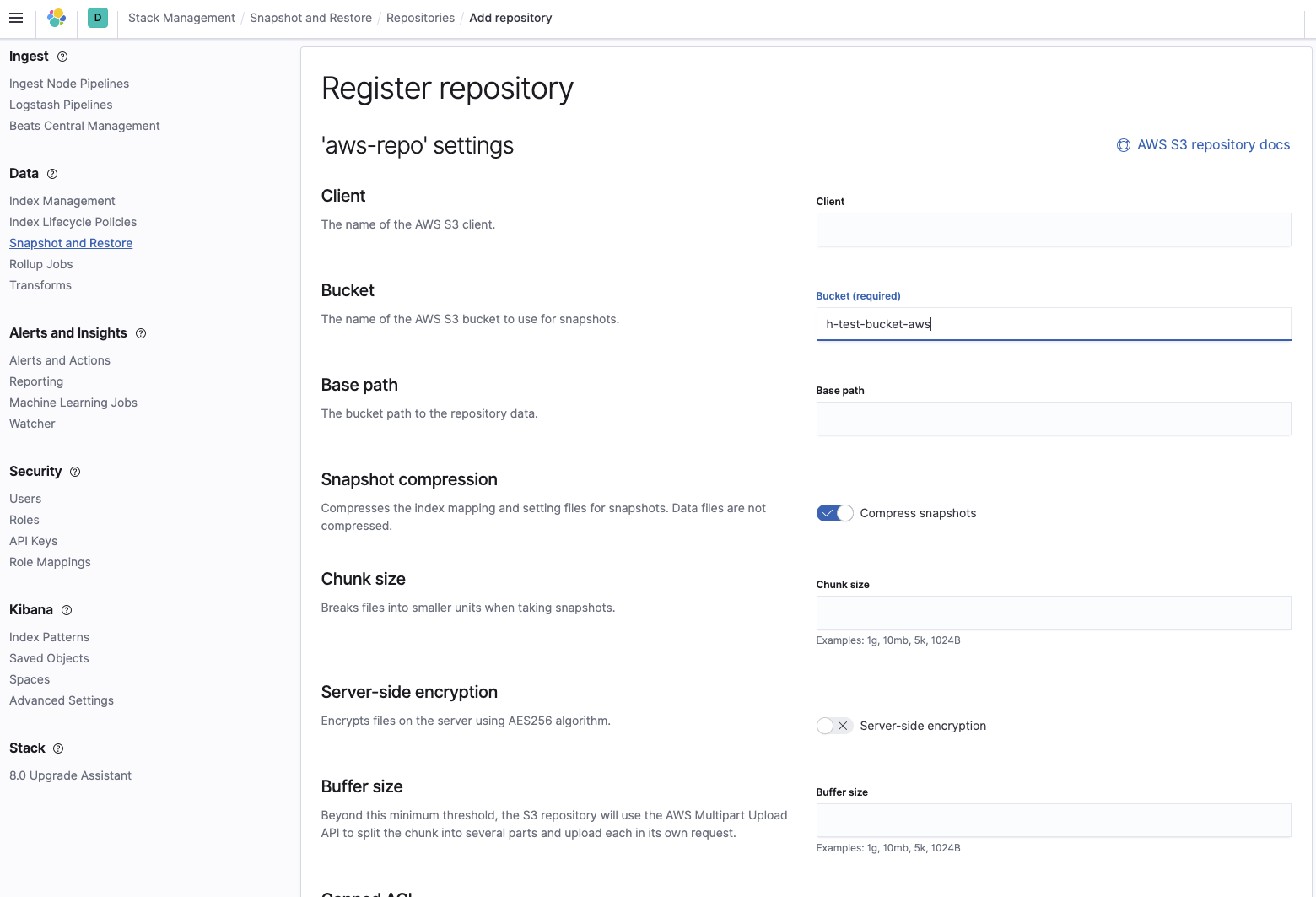
然后验证存储库是否已正确配置:
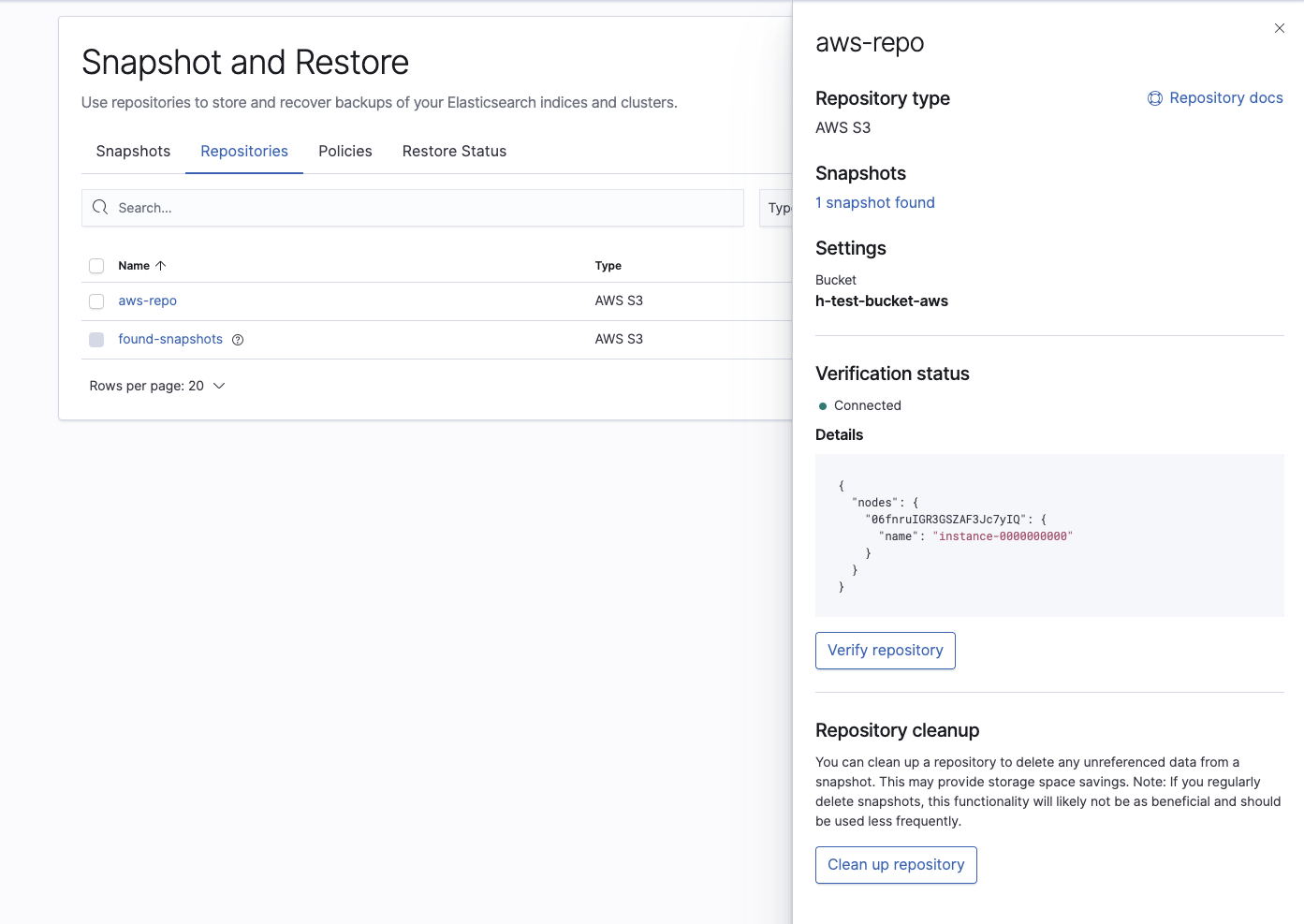
最后,确认 Elasticsearch Service 集群可以看到我们要还原的快照:
从快照还原 Elasticsearch Service 集群
要还原快照,请在 Elasticsearch Service 控制台中前往 Elasticsearch Service 集群 API 控制台,执行以下三个命令。请注意,所有三个命令都在 API 控制台中以 POST 的形式执行。
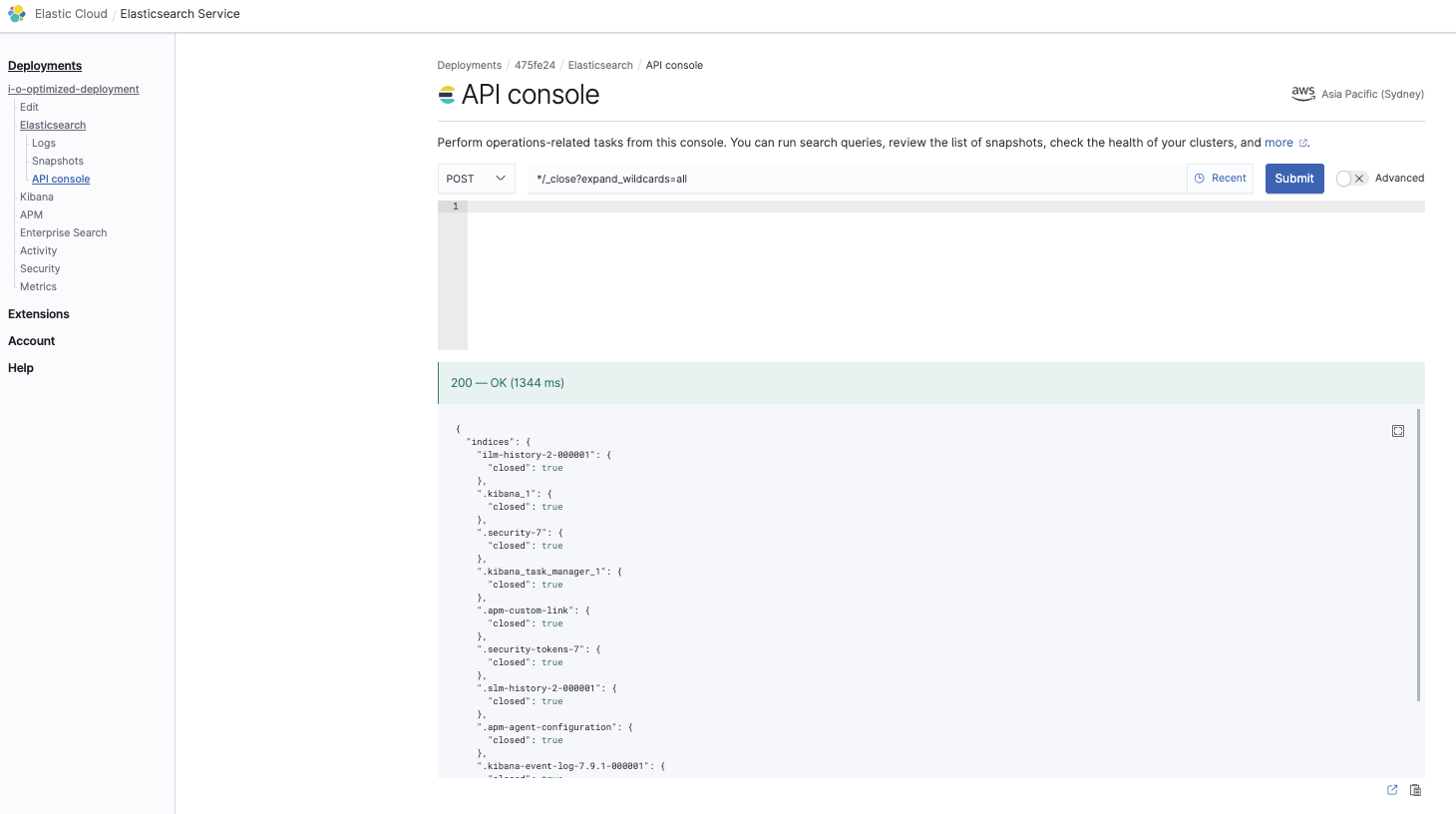
关闭所有索引
*/_close?expand_wildcards=all
这一步是为了确保先关闭所有索引,这样在还原阶段就不会发生冲突:
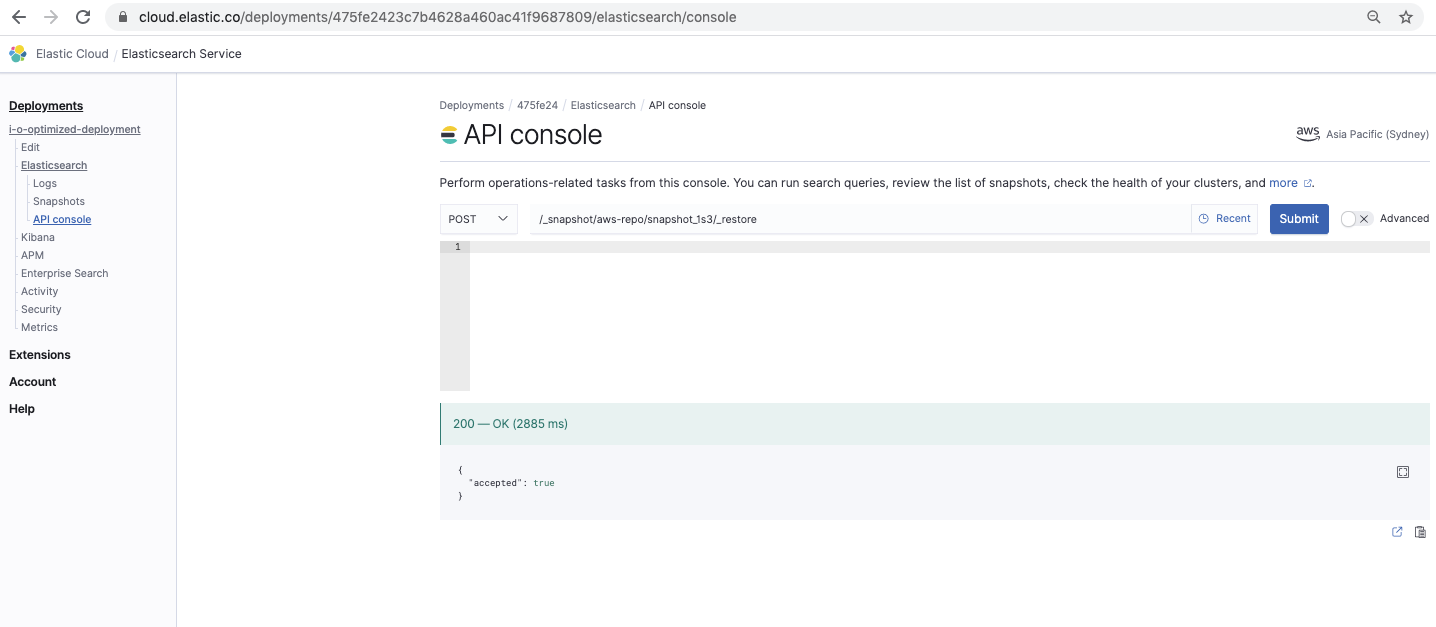
还原快照
/_snapshot// /_restore
这个命令会还原快照:
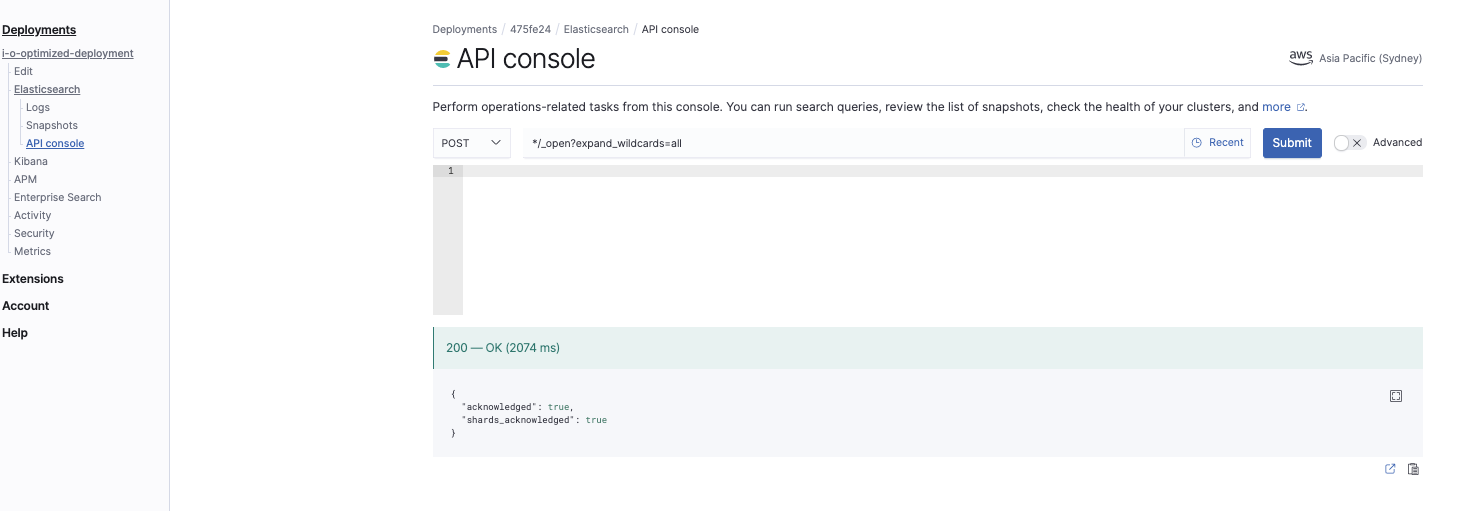
打开所有索引
*/_open?expand_wildcards=all
这个命令会打开所有索引:
验证快照还原
验证您是否已使用所有索引还原了快照。进入 Kibana 并在开发工具中运行以下命令:
GET _cat/indices
此时,您的新集群应该已经在 Elasticsearch Service 上运行,其中的数据与您从中创建快照的自管型集群中的数据相同。现在,您可以将 Beats 或 Logstash 等采集源重新指向新的 Elasticsearch Service 终端,并且可以在 Elastic Cloud 控制台中找到该终端。