The Observability AI Assistant helps users explore and analyze observability data using a natural language interface, by leveraging automatic function calling to request, analyze, and visualize your data to transform it into actionable observability. The Assistant can also set up a Knowledge Base, powered by Elastic Learned Sparse EncodeR (ELSER) to provide additional context and recommendations from private data, alongside the large language models (LLMs) using RAG (Retrieval Augmented Generation). Elastic’s Stack — as a vector database with out-of-the-box semantic search and connectors to LLM integrations and the Observability solution — is the perfect toolkit to extract the maximum value of combining your company's unique observability knowledge with generative AI.
Enhanced troubleshooting for SREs
Site reliability engineers (SRE) in large organizations often face challenges in locating necessary information for troubleshooting alerts, monitoring systems, or deriving insights due to scattered and potentially outdated resources. This issue is particularly significant for less experienced SREs who may require assistance even with the presence of a runbook. Recurring incidents pose another problem, as the on-call individual may lack knowledge about previous resolutions and subsequent steps. Mature SRE teams often invest considerable time in system improvements to minimize "fire-fighting," utilizing extensive automation and documentation to support on-call personnel.
Elastic® addresses these challenges by combining generative AI models with relevant search results from your internal data using RAG. The Observability AI Assistant's internal Knowledge Base, powered by our semantic search retrieval model ELSER, can recall information at any point during a conversation, providing RAG responses based on internal knowledge.
This Knowledge Base can be enriched with your organization's information, such as runbooks, GitHub issues, internal documentation, and Slack messages, allowing the AI Assistant to provide specific assistance. The Assistant can also document and store specific information from an ongoing conversation with an SRE while troubleshooting issues, effectively creating runbooks for future reference. Furthermore, the Assistant can generate summaries of incidents, system status, runbooks, post-mortems, or public announcements.
This ability to retrieve, summarize, and present contextually relevant information is a game-changer for SRE teams, transforming the work from chasing documents and data to an intuitive, contextually sensitive user experience.The Knowledge Base (see requirements) serves as a central repository of Observability knowledge, breaking documentation silos and integrating tribal knowledge, making this information accessible to SREs enhanced with the power of LLMs.
Your LLM provider may collect query telemetry when using the AI Assistant. If your data is confidential or has sensitive details, we recommend you verify the data treatment policy of the LLM connector you provided to the AI Assistant.
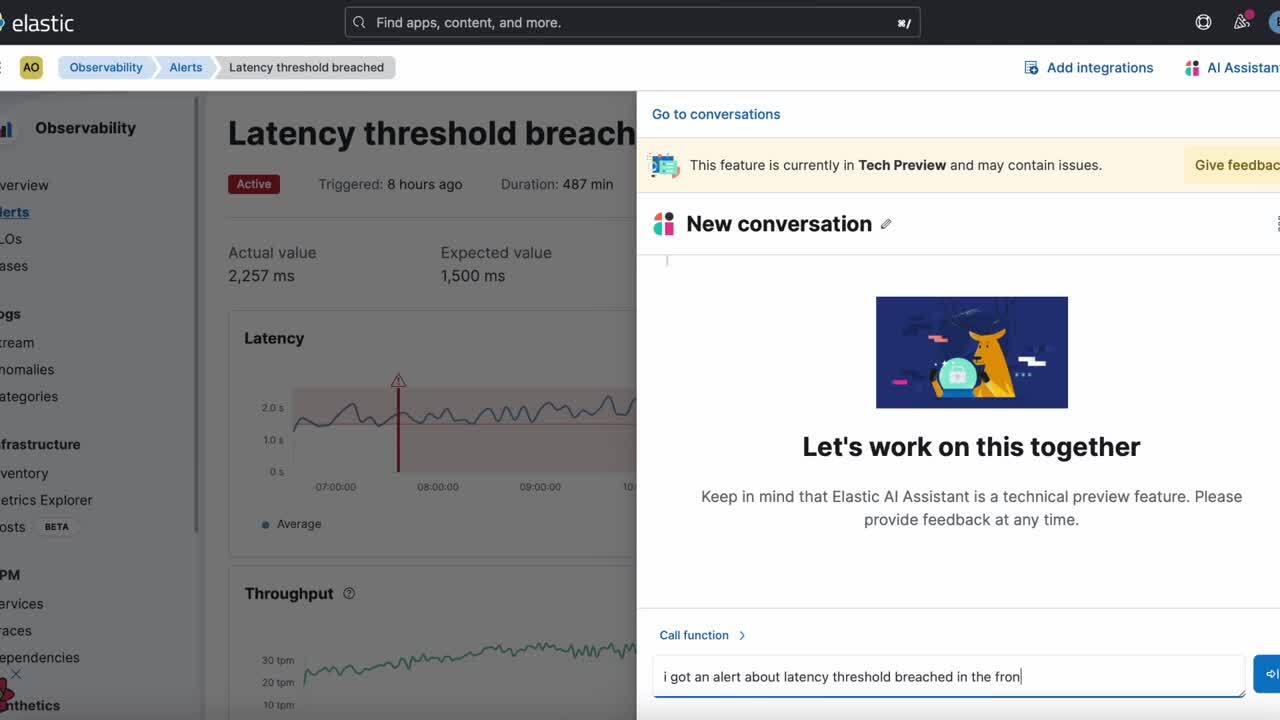
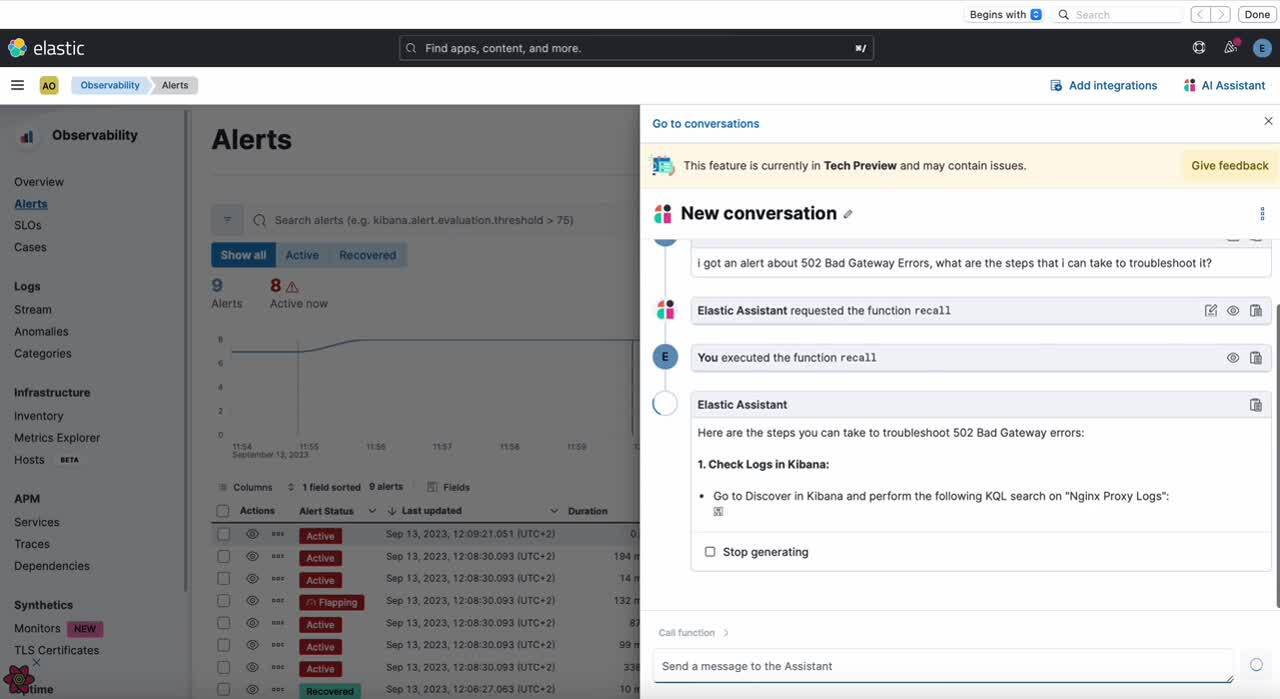
In this blog post, we will cover different ways to enrich your Knowledge Base (KB) with internal information. We will focus on a specific alert, indicating that there was an increase in logs with “502 Bad Gateway” errors that has surpassed the alert’s threshold.
How to troubleshoot an alert with the Knowledge Base
Before the KB has been enriched with internal information, when the SRE asks the AI Assistant about how to troubleshoot an alert, the response from the LLM will be based on the data it learned during training; however, the LLM is not able to answer questions related to private, recent, or emerging knowledge. In this case, when asking for the steps to troubleshoot the alert, the response will be based on generic information.
However, once the KB has been enriched with your runbooks, when your team receives a new alert on “502 Bad Gateway” Errors, they can use AI Assistant to access the internal knowledge to troubleshoot it, using semantic search to find the appropriate runbook in the Knowledge Base.
In this blog, we will cover different ways to add internal information on how to troubleshoot an alert to the Knowledge Base:
-
Ask the assistant to remember the content of an existing runbook.
-
Ask the Assistant to summarize and store in the Knowledge Base the steps taken during a conversation and store it as a runbook.
-
Import your runbooks from GitHub or another external source to the Knowledge Base using our Connector and APIs.
After the runbooks have been added to the KB, the AI Assistant is now able to recall the internal and specific information in the runbooks. By leveraging the retrieved information, the LLM could provide more accurate and relevant recommendations for troubleshooting the alert. This could include suggesting potential causes for the alert, steps to resolve the issue, preventative measures for future incidents, or asking the assistant to help execute the steps mentioned in the runbook using functions. With more accurate and relevant information at hand, the SRE could potentially resolve the alert more quickly, reducing downtime and improving service reliability.
Your Knowledge Base documents will be stored in the indices .kibana-observability-ai-assistant-kb-*. Have in mind that LLMs have restrictions on the amount of information the model can read and write at once, called token limit. Imagine you're reading a book, but you can only remember a certain number of words at a time. Once you've reached that limit, you start to forget the earlier words you've read. That's similar to how a token limit works in an LLM.
To keep runbooks within the token limit for Retrieval Augmented Generation (RAG) models, ensure the information is concise and relevant. Use bullet points for clarity, avoid repetition, and use links for additional information. Regularly review and update the runbooks to remove outdated or irrelevant information. The goal is to provide clear, concise, and effective troubleshooting information without compromising the quality due to token limit constraints. LLMs are great for summarization, so you could ask the AI Assistant to help you make the runbooks more concise.
Ask the assistant to remember the content of an existing runbook
The easiest way to store a runbook into the Knowledge Base is to just ask the AI Assistant to do it! Open a new conversation and ask “Can you store this runbook in the KB for future reference?” followed by pasting the content of the runbook in plain text.
The AI Assistant will then store it in the Knowledge Base for you automatically, as simple as that.
Ask the Assistant to summarize and store the steps taken during a conversation in the Knowledge Base
You can also ask the AI Assistant to remember something while having a conversation — for example, after you have troubleshooted an alert using the AI Assistant, you could ask to "remember how to troubleshoot this alert for next time." The AI Assistant will create a summary of the steps taken to troubleshoot the alert and add it to the Knowledge Base, effectively creating runbooks for future reference. Next time you are faced with a similar situation, the AI Assistant will recall this information and use it to assist you.
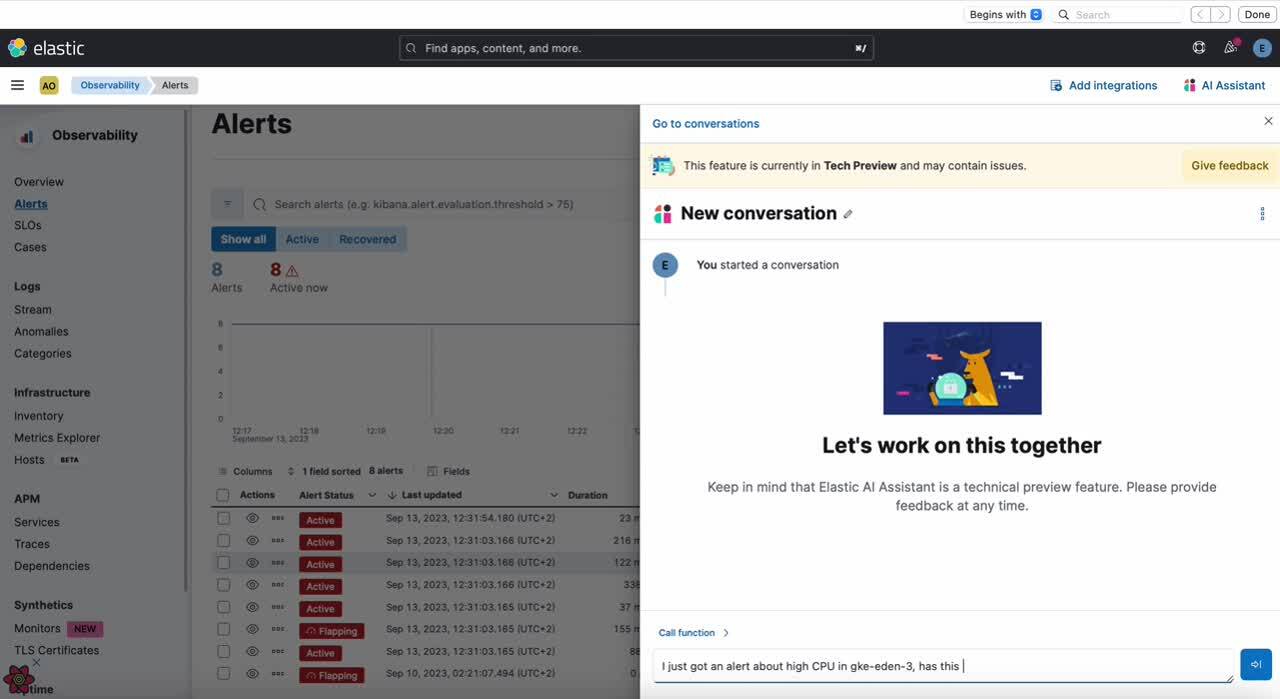
In the following demo, the user asks the Assistant to remember the steps that have been followed to troubleshoot the root cause of an alert, and also to ping the Slack channel when this happens again. In a later conversation with the Assistant, the user asks what can be done about a similar problem, and the AI Assistant is able to remember the steps and also reminds the user to ping the Slack channel.
After receiving the alert, you can open the AI Assistant chat and test troubleshooting the alert. After investigating an alert, ask the AI Assistant to summarize the analysis and the steps taken to root cause. To remember them for the next time, we have a similar alert and add extra instruction like to warn the Slack channel.
The Assistant will use the built-in functions to summarize the steps and store them into your Knowledge Base, so they can be recalled in future conversations.
Open a new conversation, and ask what are the steps to take when troubleshooting a similar alert to the one we just investigated. The Assistant will be able to recall the information stored in the KB that is related to the specific alert, using semantic search based on ELSER, and provide a summary of the steps taken to troubleshoot it, including the last indication of informing the Slack channel.
Import your runbooks stored in GitHub to the Knowledge Base using APIs or our GitHub Connector
You can also add proprietary data into the Knowledge Base programmatically by ingesting it (e.g., GitHub Issues, Markdown files, Jira tickets, text files) into Elastic.
If your organization has created runbooks that are stored in Markdown documents in GitHub, follow the steps in the next section of this blog post to index the runbook documents into your Knowledge Base.
The steps to ingest documents into the Knowledge Base are the following:
Ingest your organization’s knowledge into Elasticsearch
Option 1: Use the Elastic web crawler . Use the web crawler to programmatically discover, extract, and index searchable content from websites and knowledge bases. When you ingest data with the web crawler, a search-optimized Elasticsearch® index is created to hold and sync webpage content.
Option 2: Use Elasticsearch's Index API . Watch tutorials that demonstrate how you can use the Elasticsearch language clients to ingest data from an application.
Option 3: Build your own connector. Follow the steps described in this blog: How to create customized connectors for Elasticsearch.
Option 4: Use Elasticsearch Workplace Search connectors . For example, the GitHub connector can automatically capture, sync, and index issues, Markdown files, pull requests, and repos.
- Follow the steps to configure the GitHub Connector in GitHub to create an OAuth App from the GitHub platform.
- Now you can connect a GitHub instance to your organization. Head to your organization’s Search > Workplace Search administrative dashboard, and locate the Sources tab.
- Select GitHub (or GitHub Enterprise) in the Configured Sources list, and follow the GitHub authentication flow as presented. Upon the successful authentication flow, you will be redirected to Workplace Search and will be prompted to select the Organization you would like to synchronize.
- After configuring the connector and selecting the organization, the content should be synchronized and you will be able to see it in Sources. If you don’t need to index all the available content, you can specify the indexing rules via the API. This will help shorten indexing times and limit the size of the index. See Customizing indexing.
- The source has created an index in Elastic with the content (Issues, Markdown Files…) from your organization. You can find the index name by navigating to Stack Management > Index Management , activating the Include hidden Indices button on the right, and searching for “GitHub.”
- You can explore the documents you have indexed by creating a Data View and exploring it in Discover. Go to Stack Management > Kibana > Data Views > Create data view and introduce the data view Name, Index pattern (make sure you activate “Allow hidden and system indices” in advanced options), and Timestamp field:
- You can now explore the documents in Discover using the data view:
Reindex your internal runbooks into the AI Assistant’s Knowledge Base Index, using it's semantic search pipeline
Your Knowledge Base documents are stored in the indices .kibana-observability-ai-assistant-kb-*. To add your internal runbooks imported from GitHub to the KB, you just need to reindex the documents from the index you created in the previous step to the KB’s index. To add the semantic search capabilities to the documents in the KB, the reindex should also use the ELSER pipeline preconfigured for the KB, .kibana-observability-ai-assistant-kb-ingest-pipeline.
By creating a Data View with the KB index, you can explore the content in Discover.
You execute the query below in Management > Dev Tools , making sure to replace the following, both on “_source” and “inline”:
- InternalDocsIndex : name of the index where your internal docs are stored
- text_field : name of the field with the text of your internal docs
- timestamp : name of the field of the timestamp in your internal docs
- public : (true or false) if true, makes a document available to all users in the defined Kibana Space (if is defined) or in all spaces (if is not defined); if false, document will be restricted to the user indicated in
- (optional) space : if defined, restricts the internal document to be available in a specific Kibana Space
- (optional) user.name : if defined, restricts the internal document to be available for a specific user
- (optional) "query" filter to index only certain docs (see below)
POST _reindex
{
"source": {
"index": "<InternalDocsIndex>",
"_source": [
"<text_field>",
"<timestamp>",
"namespace",
"is_correction",
"public",
"confidence"
]
},
"dest": {
"index": ".kibana-observability-ai-assistant-kb-000001",
"pipeline": ".kibana-observability-ai-assistant-kb-ingest-pipeline"
},
"script": {
"inline": "ctx._source.text=ctx._source.remove(\"<text_field>\");ctx._source.namespace=\"<space>\";ctx._source.is_correction=false;ctx._source.public=<public>;ctx._source.confidence=\"high\";ctx._source['@timestamp']=ctx._source.remove(\"<timestamp>\");ctx._source['user.name'] = \"<user.name>\""
}
}
You may want to specify the type of documents that you reindex in the KB — for example, you may only want to reindex Markdown documents (like Runbooks). You can add a “query” filter to the documents in the source. In the case of GitHub, runbooks are identified with the “type” field containing the string “file,” and you could add that to the reindex query like indicated below. To add also GitHub Issues, you can also include in the query “type” field containing the string “issues”:
"source": {
"index": "<InternalDocsIndex>",
"_source": [
"<text_field>",
"<timestamp>",
"namespace",
"is_correction",
"public",
"confidence"
],
"query": {
"terms": {
"type": ["file"]
}
}
Great! Now that the data is stored in your Knowledge Base, you can ask the Observability AI Assistant any questions about it:
Conclusion
In conclusion, leveraging internal Observability knowledge and adding it to the Elastic Knowledge Base can greatly enhance the capabilities of the AI Assistant. By manually inputting information or programmatically ingesting documents, SREs can create a central repository of knowledge accessible through the power of Elastic and LLMs. The AI Assistant can recall this information, assist with incidents, and provide tailored observability to specific contexts using Retrieval Augmented Generation. By following the steps outlined in this article, organizations can unlock the full potential of their Elastic AI Assistant.
Start enriching your Knowledge Base with the Elastic AI Assistant today and empower your SRE team with the tools they need to excel. Follow the steps outlined in this article and take your incident management and alert remediation processes to the next level. Your journey toward a more efficient and effective SRE operation begins now.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.