RAG & RBAC integration: Protect data and boost AI capabilities
Discover how Retrieval Augmented Generation (RAG) & Role-Based Access Control (RBAC) integrate to protect data and boost AI capabilities.
Retrieval Augmented Generation (RAG) enhances the knowledge of large language models (LLMs) by providing additional context or information, improving response quality. Despite their impressive capabilities, LLMs have limitations, such as the inability to retain new information post-training and the tendency to produce incorrect answers on unfamiliar topics. To counter these limitations, proprietary, relevant, and updated data can be combined with prompts, thus grounding the LLM and leading to more accurate and user-friendly responses.
For details on RAG, check out our Search-Labs blog about RAG.
Role-Based Access Control (RBAC) ensures that access to sensitive data is meticulously controlled, maintaining the integrity and confidentiality of your company's information.
This blog explores how RAG and RBAC can team up to supercharge AI capabilities while ensuring your data stays under lock and key.
Data protection in LLMs
Protecting private information should be a top priority for any company. The damage done by leaking sensitive information can come with financial penalties, damage to reputation, loss of competitive advantage, and even harm to individuals when personal information is leaked. Because of these and many other reasons, it is essential to consider what data you are sending to an LLM.
Today, users have options when integrating an LLM into an application. The easiest way is to use a public LLM provider. While this removes all management concerns by simply connecting to an API, users must be mindful of how the data they send to one of these providers may be used. An LLM won’t retain information immediately, but that doesn’t mean all prompts sent to the service can’t be recorded and used for future training interactions. With these public services, users should only send information they are not concerned about that could be used for future training iterations, making that knowledge available to any other user.
Some services offer commercial plans, which can come with legal contracts prohibiting the LLM provider from retaining and training off the data sent to its service. Hyperscalers provide options to deploy one of these generative LLMs to a customer’s tenant with the promise that customer data will be isolated. These options provide more comprehensive protection for data privacy than a public service. Still, users and companies must trust that the LLM provider will adhere to their promises.
Today's most secure way to integrate with an LLM is for a company to run one themselves. This should ensure no prompt information will be retained, and no data is sent externally without their knowledge. This added protection comes with added complexity and management responsibility. Companies must know how to deploy and scale an LLM. They must be able to monitor whether it continues to respond within the required response times. Running a model yourself doesn’t mean it will be more cost-effective, but it does move control back to the operator.
Regardless of the deployment type, grounding the model by augmenting the LLM’s knowledge remains equally important.
Types of data companies need to consider protecting
The following won’t be an extensive list, but it is worth pointing out a few types of data companies must consider when integrating with an LLM.
Internal vs. public data
As mentioned, every company has information that is not publicly accessible. Non-public data should stay non-public if the end application is to be used by internal employees. If the end users are external, care must be taken when deciding if the internal information is acceptable to be shared externally. Public data is already public, so sending it to an LLM should pose no additional risk.
PII
Personal Identifiable Data (PII) is the type of data that makes the news when a company loses control of it. This is generally information that is unique to an individual. While all PII should be protected, some are more critical than others. Using a first name is often not an issue. But sending a first name, last name, and social security number to a public LLM isn’t a great idea.
Customer-specific data
Similar to PII in that it is unique to a customer, this data is often less sensitive. Examples include past order information, travel type preferences, and app settings.
Securing these and other data types is where role-based access control comes in.
RAG without RBAC
Let's start by looking at how a RAG app with only one user level of access works. If you are creating a chatbot that will run on a public website and answer documentation questions, it will likely be connected to only one dataset: your documentation. Having every user at the same access level in this setup is fine. Everyone can access the documentation, and anyone can see an answer.
But what if you are creating an internal chatbot with access to HR data where employees can ask questions instead? Some HR data should be available to everyone, but some will remain restricted to particular roles, such as Managers or HR staff.
Below, a user asks, "What is our work from home policy?”
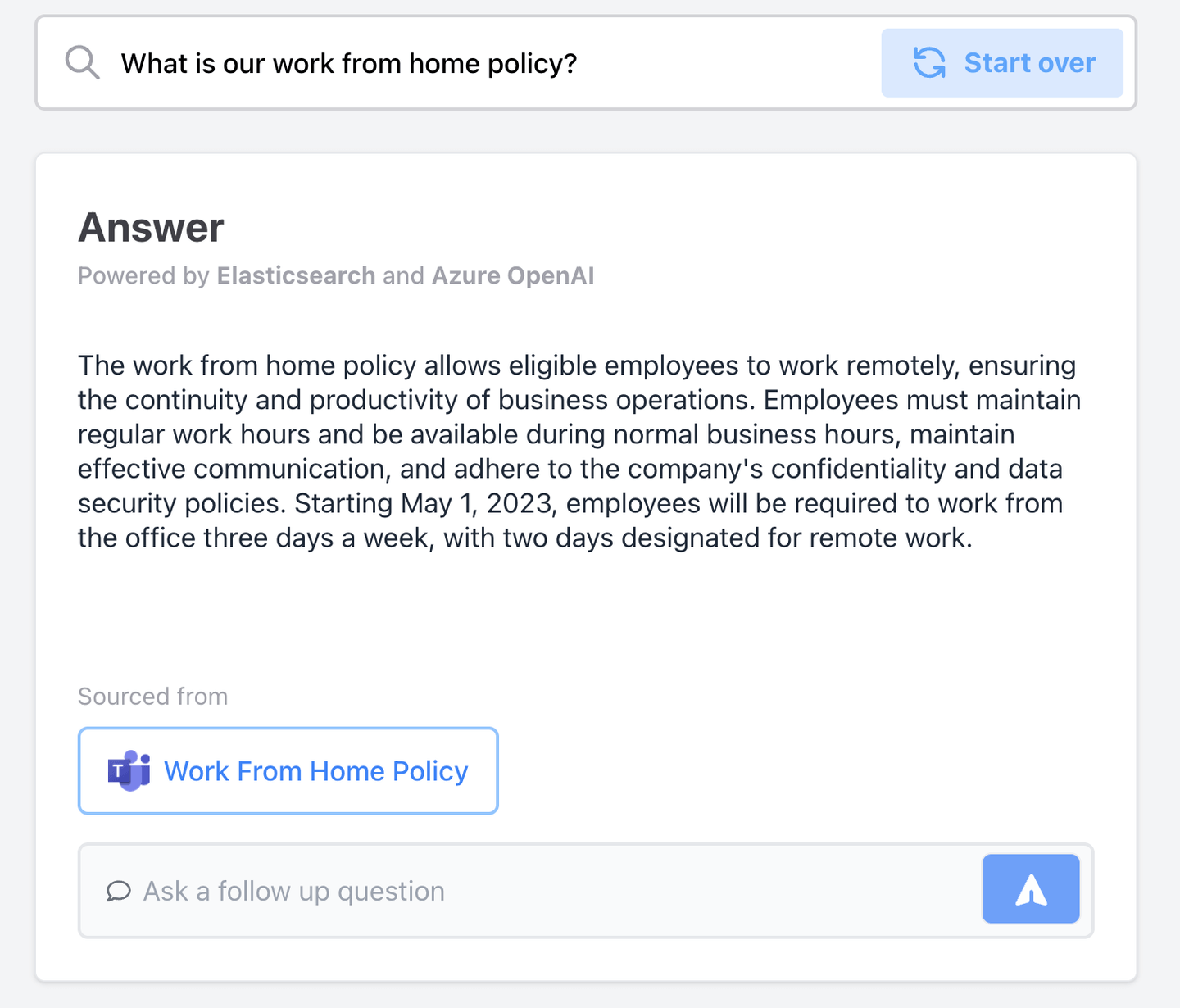
WFH Policy
This is a general question any employee should have access to, so as long as they have access to the app, they can ask and get an answer. Note that we could implement RBAC here by requiring users to log in, but for simplicity, we will assume they can only access this chatbot when they are inside the work network.
Now, let’s assume only Managers should have access to information about employee compensation. What happens when a non-manager or engineer asks a question about compensation when RBAC is not implemented?
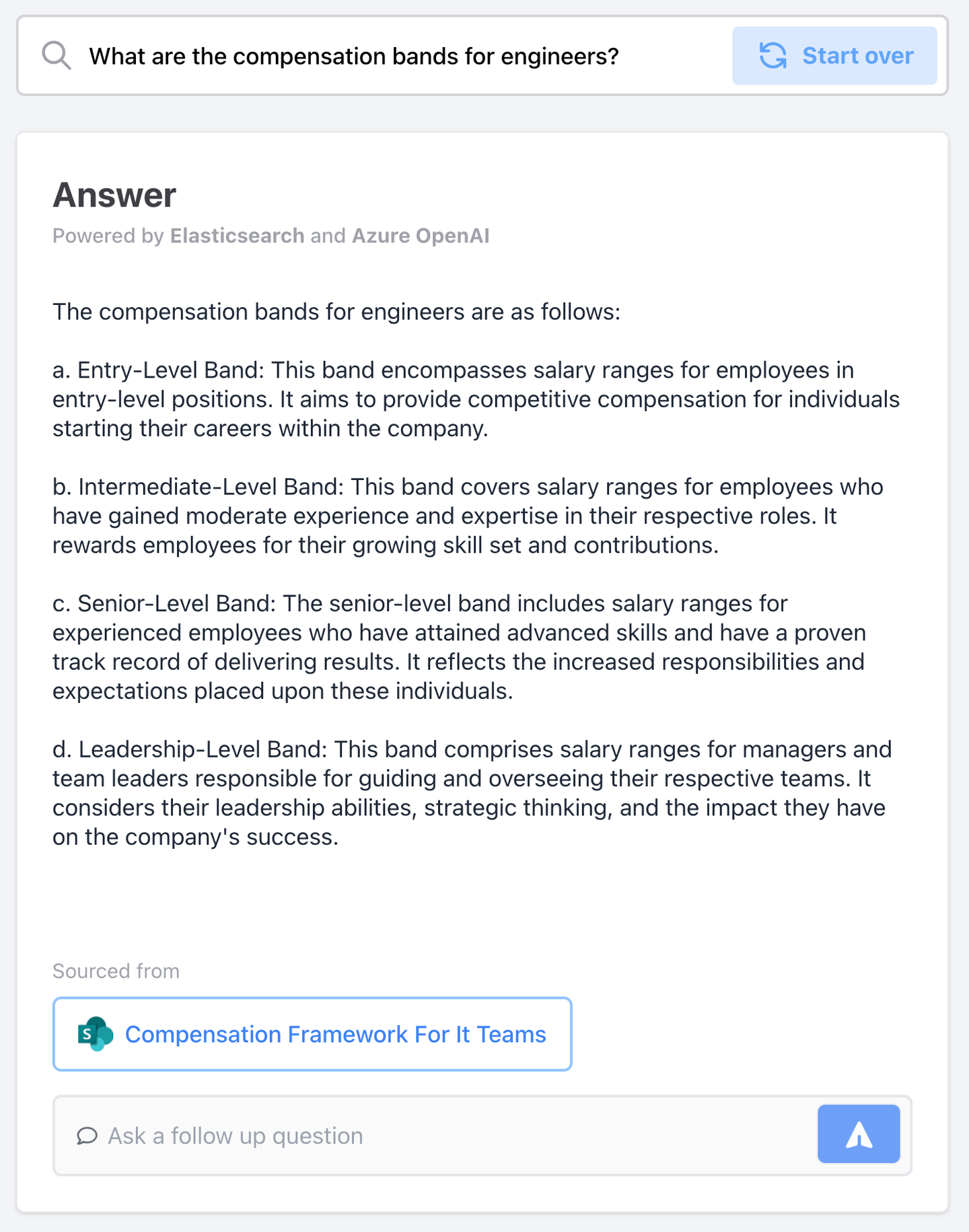
comp details
The chatbot returns what looks like a helpful answer; however, remember, only Managers should have access to this detail!
Elastic RBAC features
Before we examine the answer to the compensation question with RBAC enabled, let’s briefly discuss Elasticsearch’s RBAC capabilities at a high level.
Cluster Level
The most general access level is the cluster level. Can a user or account log in to the cluster?
Index Level
Once you can log in, can the account read the data in the access, and can it write, modify, and delete the index?
Document Level
When a user can query an index, can they retrieve all the documents in the index, or can they only read documents that match a particular set of metadata?
Read more deail in our Blog - Document-Level Attribute-Based Access Control in Elasticsearch
Field Level
When a document is returned as part of a query, can the account view all the fields or only select fields?
Attribute
Use attributes to restrict access to documents in search queries and aggregations.
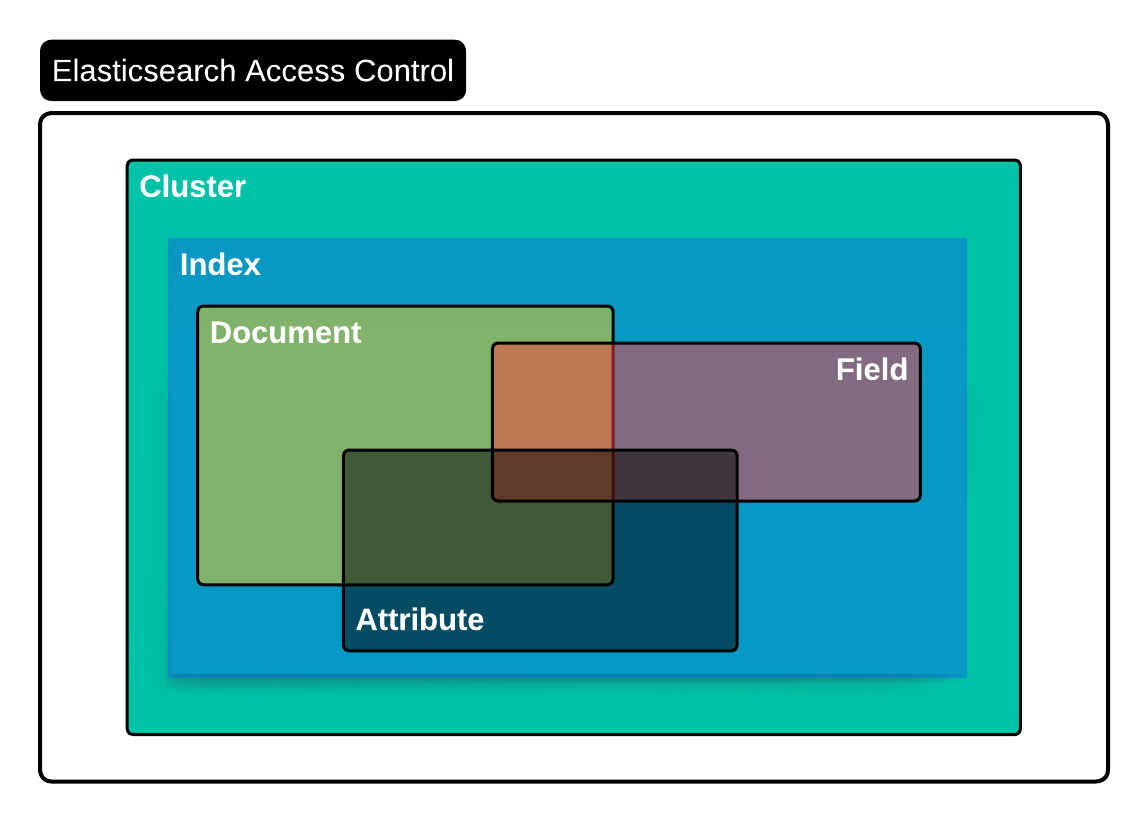
Data Security Levels
A generalized representation of RBAC levels in Elasticsearch
For a simple example demonstrating how RBAC affects the indices and documents users from different groups are allowed to query, check out the sample Jypyter notebook in the Search Labs Repo here.
Elasticsearch can integrate with external authentication systems such as Active Directory, LDAP, SAML, and more. External groups are mapped to internal Elasticsearch roles when integrated with these providers. This offers several advantages over managing data access at the application level. First, the mapping between external and internal roles only needs to be configured once. It only requires updates when new index patterns are created or when modifications to group access types are needed. Second, by managing access at the group level within Elasticsearch, only their membership needs updating as users join or leave groups. Their access permissions automatically adjust to reflect their current group affiliations.
This second point is especially important. When access roles change, the permissions need to propagate to all systems in real-time. RBAC ensures this change takes affect rather than having to chang access in multiple programs.
For a detailed look at how RBAC fits into a Search Center of Excellent, check out the excellent blog here.
Our documentation goes into more detail about each access level.
RAG with RBAC
Now that we understand the various access levels Elasticsearch can employ let's return to our RAG examples. In the last example, our Slackbot asked our engineer a helpful compensation question. However, because this information should have been restricted to Managers, it should not have provided that detail!
We could configure restrictions on this data in many ways, but we will keep our RBAC example simple, have two access levels for our HR dataset, and split the data over two indexes. One index will be hrdata-general, and one will be hrdata-restricted. Every employee will have access to hrdata-general, and only Managers will have access to hrdata-restricted. Users can query one or both indices based on the role mapping between the company’s LDAP settings and Elasticsearch users/roles.
When the Engineer asks about compensation again, this time with proper RBAC implemented, it does not provide the restricted information.
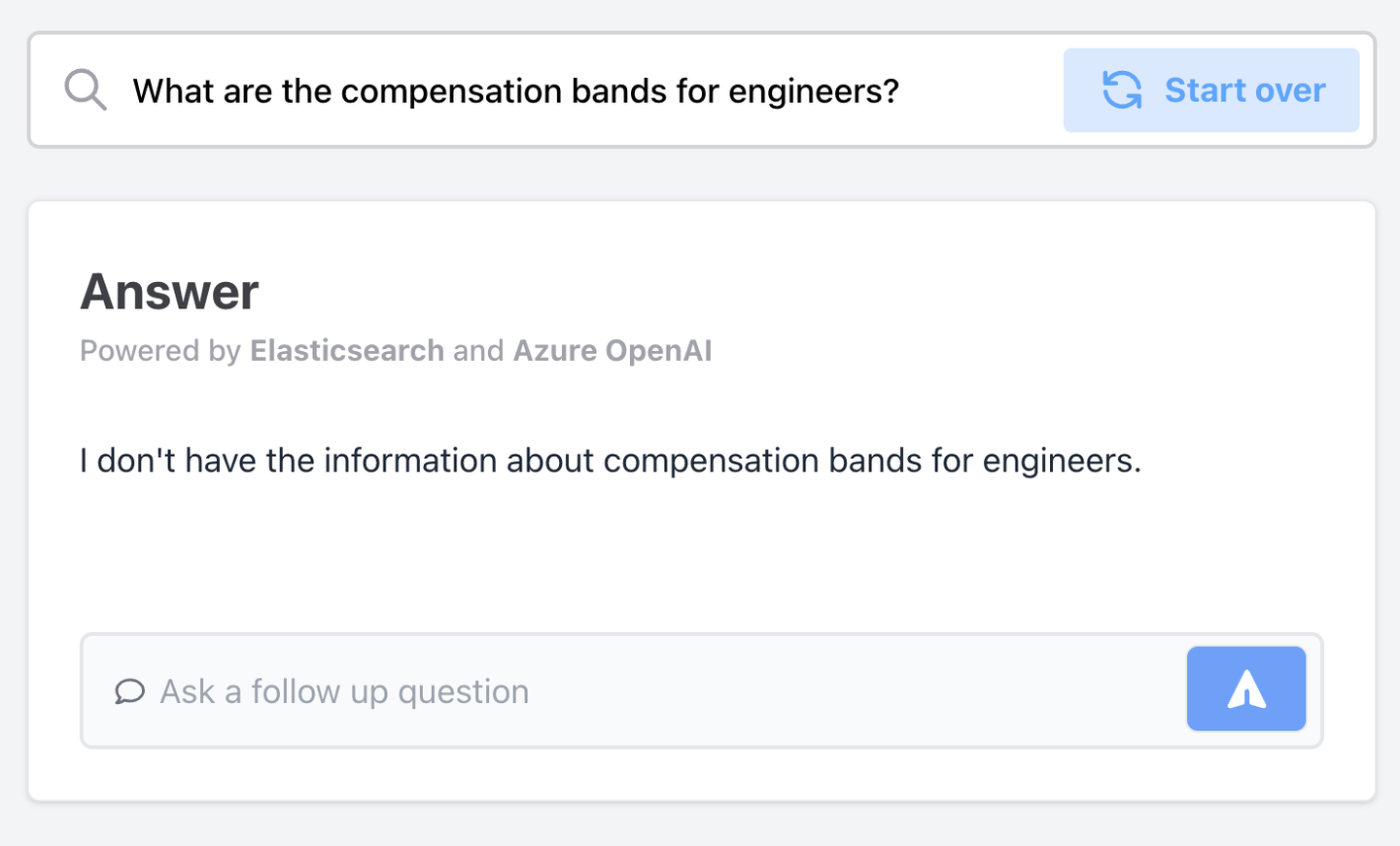
comp for eng with RABC
When a Manager logs into this chatbot and asks the same question, that user’s RBAC settings allow them access to the restricted HR dataset.
comp details for managers with RBAC
This answer is correctly restricted to the Manager role, whereas without RBAC restriction, all employees could query and get responses from the restricted dataset.
This example shows how index-level access helps secure which indices groups can access. However, as mentioned above, Elasticsearch provides many additional and more granular ways to secure your data. Look out for a follow-up to this blog, where we will discuss and provide code examples for some advanced RBAC configurations.
Wrapup
Integrating Retrieval Augmented Generation (RAG) with Role-Based Access Control (RBAC) in Elasticsearch offers a robust and secure solution for internal and external applications. RAG enhances the capabilities of large language models, while RBAC ensures that access to sensitive data is meticulously controlled, maintaining the integrity and confidentiality of your company's information. This combination is particularly critical in a production environment where data protection is paramount. As we've demonstrated, implementing RBAC in Elasticsearch is practical and straightforward, making it an ideal choice for any company looking to leverage the power of AI while ensuring data privacy.
We encourage you to explore this capability further and consider how it can be applied to your unique business needs. Remember, Search AI is not just about generating intelligent responses but also about protecting your valuable data assets.
Related Content


Retrieval Augmented Generation (RAG) using Cohere Command model through Amazon Bedrock and domain data in Elasticsearch