A jornada da Elastic para desenvolver o Elastic Cloud Serverless
Arquitetura de estado que se dimensiona automaticamente, independentemente das necessidades de dados, uso e desempenho


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Como transformar um sistema com estado e sistema crítico de desempenho como o Elasticsearch em um sistema sem servidor?
Na Elastic, reinventamos tudo — do armazenamento à orquestração — para construir uma plataforma verdadeiramente sem servidor na qual os clientes podem confiar.
O Elastic Cloud Serverless é uma plataforma totalmente gerenciada e nativa da nuvem, projetada para trazer o poder do Elastic Stack aos desenvolvedores sem o ônus operacional. Neste post do blog, vamos explicar por que o criamos, como abordamos a arquitetura e o que aprendemos ao longo do caminho.
Por que serverless?
Ao longo dos anos, as expectativas dos clientes mudaram drasticamente. Os usuários não querem mais se preocupar com as complexidades do gerenciamento de infraestrutura, como dimensionamento, monitoramento e redimensionamento. Em vez disso, buscam uma experiência integrada, na qual possam se concentrar exclusivamente em cargas de trabalho. Essa demanda crescente nos impulsionou a desenvolver uma solução que reduz a sobrecarga operacional, oferece uma experiência SaaS sem atritos e introduz um modelo de precificação por uso. Ao eliminar a necessidade de os clientes provisionarem e manterem recursos manualmente, criamos uma plataforma que redimensiona de forma dinâmica com base na demanda, otimizando a eficiência.
Marcos
O Elastic Cloud Serverless está se expandindo rapidamente para atender à demanda dos clientes, tendo atingido disponibilidade geral (DG) na AWS em dezembro de 2024, no GCP em abril de 2025 e no Azure em junho de 2025. Desde então, expandimos para quatro regiões na AWS, três regiões no GCP e uma região no Azure, com regiões adicionais planejadas em todos os três provedores de serviços de nuvem (CSPs).
Repensando a arquitetura: de estado a sem estado
O Elastic Cloud Hosted (ECH) foi inicialmente desenvolvido como um sistema com estado, utilizando armazenamento local baseado em NVMe ou discos gerenciados para assegurar a durabilidade dos dados. À medida que o Elastic Cloud se expandiu globalmente, identificamos uma oportunidade de aperfeiçoar nossa arquitetura para melhor apoiar a eficiência operacional e o crescimento no longo prazo. Nossa abordagem hospedada para gerenciar o estado persistente em ambientes distribuídos mostrou-se eficaz, mas introduziu uma complexidade operacional adicional em relação a substituições de nodes, manutenção, garantia de redundância em zonas de disponibilidade e redimensionamento de cargas de trabalho com uso intensivo de computação, como indexação e busca.
Decidimos modernizar a arquitetura do nosso sistema adotando uma abordagem sem estado. A mudança chave foi descarregar o armazenamento persistente dos nós de computação para os armazenamentos de objetos nativos da nuvem. Isso trouxe múltiplos benefícios: redução da infraestrutura necessária para indexação, habilitação da separação entre busca e índice, eliminação da necessidade de replicação e aprimoramento da durabilidade dos dados ao aproveitar os mecanismos de redundância integrados dos CSPs.
A mudança para o armazenamento de objetos
Uma das principais mudanças em nossa arquitetura foi usar o armazenamento de objetos nativo da nuvem como o principal repositório de dados. O ECH foi projetado para armazenar dados em SSDs NVMe locais ou em discos SSD gerenciados. No entanto, à medida que os volumes de dados aumentavam, também aumentavam os desafios de redimensionamento do armazenamento de forma eficiente. Em seguida, introduzimos instantâneos pesquisáveis no ECH, o que nos permitiu pesquisar dados diretamente de armazenamentos de objetos, reduzindo significativamente os custos de armazenamento, mas precisávamos ir além.
Um dos principais desafios foi determinar se os armazenamentos de objetos poderiam lidar com cargas de trabalho de alta ingestão enquanto mantinham o nível de desempenho que os usuários do Elasticsearch esperam. Por meio de testes e implementações rigorosas, validamos que o armazenamento de objetos pode atender às demandas de indexação em larga escala. A mudança para o armazenamento de objetos eliminou a necessidade de replicação de indexação, reduziu os requisitos de infraestrutura e proporcionou maior durabilidade ao replicar dados entre zonas de disponibilidade, garantindo alta disponibilidade e resiliência.
O diagrama abaixo ilustra a nova arquitetura “sem estado” em comparação com a arquitetura “ECH” existente:

Otimização da eficiência do armazenamento de objetos
Embora a mudança para o armazenamento de objetos tenha proporcionado benefícios operacionais e de durabilidade, ela trouxe um novo desafio: os custos da API de armazenamento de objetos. As gravações no Elasticsearch, principalmente as atualizações de translog, são convertidas diretamente em chamadas de API de armazenamento de objetos, que podem ser redimensionadas de forma rápida e imprevisível, especialmente em cargas de trabalho de alta ingestão ou alta atualização.
Para resolver isso, implementamos um mecanismo de buffer de translog por nó que aglutina as gravações antes de liberar para o armazenamento de objetos, reduzindo muito a amplificação de gravações. Também desacoplamos as atualizações das gravações de armazenamento de objetos, enviando segmentos atualizados diretamente para os nós de pesquisa, enquanto adiamos a persistência do armazenamento de objetos. Esse refinamento arquitetônico reduziu as chamadas de API de armazenamento de objetos relacionadas à atualização em duas ordens de magnitude, sem comprometer a durabilidade dos dados. Para saber mais, consulte este post do blog.
Escolha do Kubernetes para orquestração
O ECH usa um orquestrador de contêineres desenvolvido internamente que também alimenta o Elastic Cloud Enterprise (ECE). Como o desenvolvimento do ECE começou antes mesmo do Kubernetes (K8s) existir, tínhamos a opção de estender o ECE para dar suporte à infraestrutura sem servidor ou usar o K8s para essa infraestrutura. Com a rápida adoção do K8s em todo o setor e o crescente ecossistema em torno dele, decidimos adotar serviços gerenciados do Kubernetes em todos os CSPs no Elastic Cloud Serverless, onde isso se alinha aos nossos objetivos operacionais e de redimensionamento.
Ao adotar o Kubernetes, reduzimos a complexidade operacional, padronizamos as APIs para melhorar a escalabilidade e posicionamos o Elastic Cloud para inovação a longo prazo. O Kubernetes nos permitiu focar em recursos de maior valor em vez de reinventar a orquestração de contêineres.
Kubernetes gerenciado por CSP x Kubernetes autogerenciado
Durante a transição para o Kubernetes, enfrentamos a decisão de gerenciar os clusters do Kubernetes nós mesmos ou usar os serviços gerenciados do Kubernetes fornecidos por CSPs. As implementações do Kubernetes variam muito entre os CSPs, mas para acelerar nossos cronogramas de implantação e reduzir a sobrecarga operacional, optamos por serviços do Kubernetes gerenciados pelo CSP na AWS, no GCP e no Azure. Essa abordagem nos permitiu focar na construção de aplicativos e na adoção das melhores práticas do setor, em vez de lidar com as complexidades do gerenciamento de clusters do Kubernetes.
Nossos principais requisitos incluíam a capacidade de provisionar e gerenciar clusters do Kubernetes de forma consistente em vários CSPs; uma API independente de nuvem para gerenciar computação, armazenamento e bancos de dados; e operações simplificadas que eram econômicas. Além disso, ao escolher o Kubernetes gerenciado pelo CSP, pudemos contribuir com upstream para projetos de código aberto como o Crossplane, aprimorando o ecossistema geral do Kubernetes e, ao mesmo tempo, nos beneficiando dos recursos em evolução.
Desafios de rede e a escolha do Cilium
Operar o Kubernetes em escala, com dezenas de milhares de pods por cluster do Kubernetes, exige uma solução de rede independente de nuvem, que ofereça alto desempenho com latência mínima e suporte a políticas de segurança avançadas. Selecionamos o Cilium, uma solução moderna baseada em eBPF, para atender a esses requisitos. Inicialmente, nosso objetivo era implementar uma solução Cilium uniforme e autogerenciada em todos os CSPs. No entanto, diferenças nas implementações em nuvem nos levaram a adotar uma abordagem híbrida, utilizando soluções Cilium nativas de CSPs, quando disponíveis, e mantendo uma implantação autogerenciada na AWS. Essa flexibilidade garantiu que pudéssemos atender às nossas necessidades de desempenho e segurança sem complexidade desnecessária.
Tráfego de entrada
Para o tráfego de entrada, optamos por adaptar e continuar usando nosso proxy existente e comprovado do ECH. A avaliação não era apenas se poderíamos substituir o proxy por uma solução pronta para uso, mas se deveríamos.
Embora um proxy reverso padrão ofereça funcionalidade básica, ele não teria os recursos diferenciados que o proxy ECH já gerencia. Precisaríamos desenvolver extensões para filtros de tráfego de entrada, suporte para AWS PrivateLink e Google Cloud Private Service Connect, e terminação TLS em conformidade com FIPS. O proxy existente também já passou por todas as auditorias de conformidade relevantes e testes de penetração.
Iniciar com uma nova solução teria exigido um esforço significativo sem oferecer valor adicional ao cliente. Adaptar nosso proxy para Kubernetes envolveu principalmente atualizar como distribuímos a conscientização sobre os endpoints de serviço, mantendo intacta a funcionalidade núcleo e bem testada. Essa abordagem oferece diversas vantagens:
Garante que o comportamento visível ao cliente permaneça consistente entre o ECH e o Kubernetes.
As equipes podem trabalhar de forma mais eficiente com uma base de código familiar e bem compreendida, especialmente ao implementar novos recursos que exigem scripts ou extensões em uma solução pronta para uso.
Podemos desenvolver tanto nossas plataformas ECH quanto Kubernetes com uma única base de código; assim, melhorias em um ambiente se traduzem em melhorias no outro.
As equipes de suporte podem aproveitar o conhecimento existente, reduzindo a curva de aprendizado para a nova plataforma.
Camada de provisão do Kubernetes
Após escolher o Kubernetes para o Elastic Cloud Serverless, selecionamos o Crossplane como ferramenta de gerenciamento de infraestrutura. O Crossplane é um projeto de código aberto que estende a API do Kubernetes para permitir o provisionamento e o gerenciamento de infraestrutura e serviços em nuvem usando ferramentas e práticas nativas do Kubernetes. Ele permite que os usuários provisionem, gerenciem e orquestrem recursos de nuvem em vários CSPs a partir de um cluster Kubernetes. Isso é possível por meio do uso de Definições de Recursos Personalizadas (CRDs) para definir recursos e controladores de nuvem e reconciliar o estado desejado especificado nos manifestos do Kubernetes com o estado real dos recursos de nuvem em vários CSPs. Ao utilizar os mecanismos declarativos de configuração e controle do Kubernetes, ele fornece uma maneira consistente e escalável de gerenciar a infraestrutura como código.
O Crossplane possibilita o gerenciamento e a provisão de infraestrutura utilizando as mesmas ferramentas e métodos usados para a implantação de serviços. Isso envolve aproveitar recursos do Kubernetes, uma arquitetura GitOps consistente e ferramentas de observabilidade unificadas. Além disso, desenvolvedores podem criar um ambiente de desenvolvimento completo baseado em Kubernetes, incluindo a infraestrutura periférica, que reflita os ambientes de produção. Isso é alcançado simplesmente criando um recurso do Kubernetes, já que ambos os ambientes são gerados a partir do mesmo código subjacente.
Gerenciamento de infraestrutura
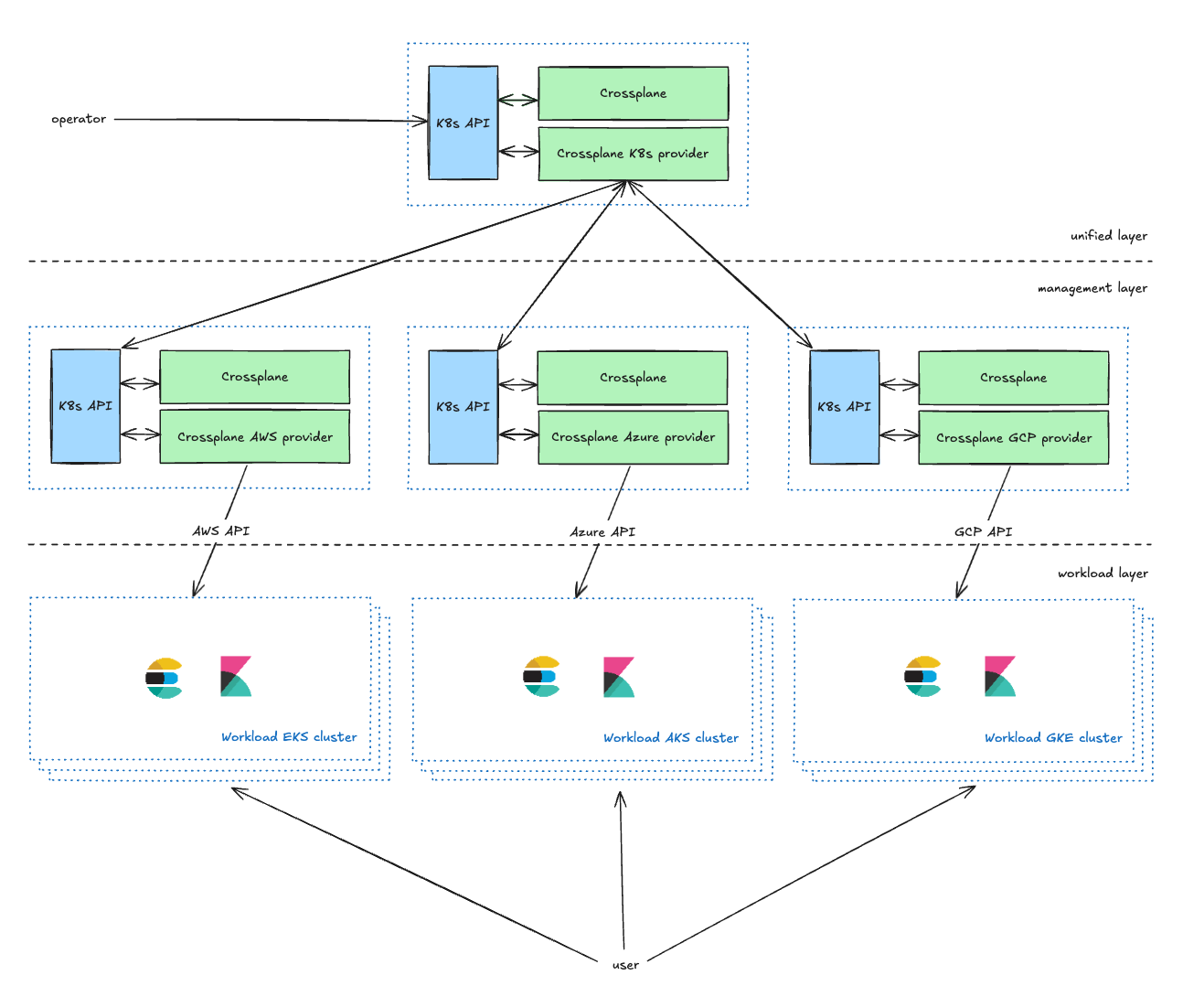
A camada unificada é a camada de gerenciamento voltada para o operador, fornecendo CRDs do Kubernetes para que os proprietários de serviços gerenciem seus clusters do Kubernetes. Eles podem definir parâmetros, incluindo o CSP, a região e o tipo (explicados na próxima seção). Ela enriquece as solicitações dos operadores e as encaminha para a camada de gerenciamento.
A camada de gerenciamento atua como um proxy entre a camada unificada e as APIs do CSP, transformando solicitações da camada unificada em solicitações de recursos do CSP e reportando o status de volta à camada unificada.
Na nossa configuração atual, mantemos dois clusters de gerenciamento Kubernetes para cada provedor de nuvem (CSP) em cada ambiente. Essa abordagem de clusters duplos serve principalmente a dois propósitos. Primeiramente, permite lidar de forma eficaz com possíveis problemas de escalabilidade que possam surgir com o Crossplane. Em segundo lugar — e mais importante —, possibilita o uso de um dos clusters como ambiente canário. Essa estratégia de implantação canário facilita uma distribuição gradual das mudanças, começando por um subconjunto menor e controlado de cada ambiente, minimizando riscos.
A camada de Workload contém todos os clusters de carga de trabalho do kubernetes que executam aplicativos com os quais os usuários interagem (Elasticsearch, Kibana, MIS, etc.).
Gerenciamento da capacidade da nuvem: evitar erros de "falta de capacidade"
Uma suposição comum é que a capacidade da nuvem é infinita, mas, na realidade, os CSPs impõem restrições que podem levar a erros de "capacidade insuficiente". Se um tipo de instância estiver indisponível, precisamos tentar novamente ou alternar continuamente para um tipo de instância alternativo.
Para mitigar isso no Elastic Cloud Serverless, implementamos pools de capacidade baseados em prioridade, permitindo que as cargas de trabalho migrem para usar novos/outros pools de capacidade quando necessário. Além disso, investimos em planejamento proativo de capacidade, reservando recursos de computação antes de picos de demanda. Esses mecanismos garantem alta disponibilidade e, ao mesmo tempo, otimizam a utilização de recursos.
Mantendo-se atualizado
As atualizações de cluster do Kubernetes são demoradas. Para agilizar esse processo, utilizamos um processo de ponta a ponta totalmente automatizado, exigindo intervenção manual apenas para problemas que não podem ser resolvidos automaticamente. Após a conclusão dos testes internos e a aprovação de uma nova versão do Kubernetes, configuramos a versão centralizada. Um sistema automatizado inicia a atualização do plano de controle para cada cluster, com simultaneidade controlada e uma ordem específica. Depois, controladores Kubernetes personalizados realizam implantações azuis e verdes para atualizar os pools de nós. Apesar de os pods dos clientes migrarem para diferentes nós do K8s durante esse processo, a disponibilidade e o desempenho do projeto permanecem inalterados.
Resiliência da arquitetura
Usamos uma arquitetura baseada em células, que nos permite fornecer serviços escaláveis e resilientes. Cada cluster Kubernetes, juntamente com a infraestrutura periférica, é implantado em uma conta CSP separada para permitir o redimensionamento adequado sem ser afetado pelos limites do CSP e para fornecer segurança e isolamento máximos. Cargas de trabalho individuais, cada uma em uma célula, gerenciam aspectos específicos do sistema. Essas células operam de forma independente, permitindo redimensionamento e gerenciamento isolados. Esse design modular minimiza o alcance de falhas e facilita o redimensionamento direcionado, evitando impactos em todo o sistema. Para minimizar ainda mais o impacto potencial de problemas, empregamos implantações canárias tanto para nossos aplicativos quanto para a infraestrutura subjacente.
Plano de Controle vs. Plano de Dados: O Modelo Push
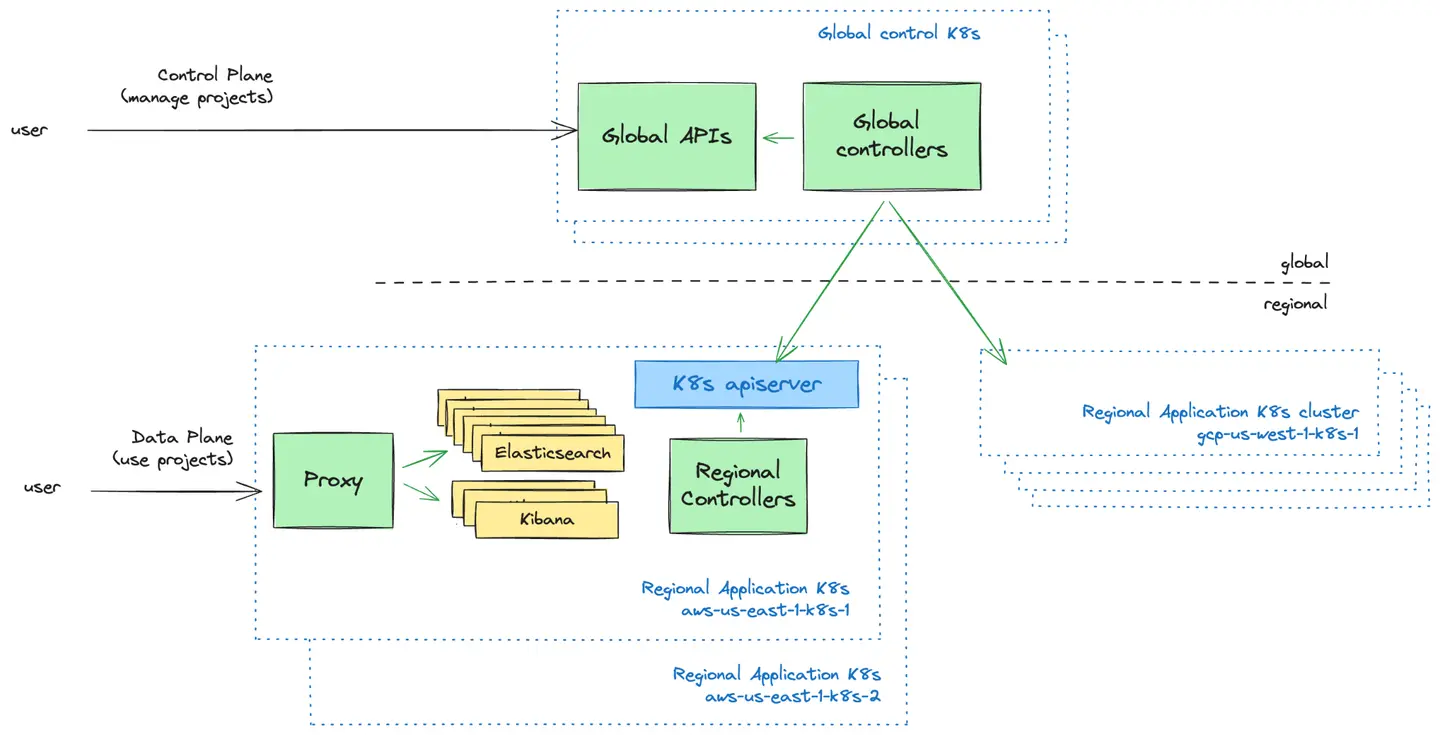
O Control Plane é a camada de gerenciamento voltada para o usuário. Fornecemos interfaces de usuário (UIs) e APIs para que os usuários gerenciem seus projetos do Elastic Cloud Serverless. É aqui que os usuários podem criar novos projetos, controlar quem tem acesso a seus projetos e obter uma visão geral de seus projetos.
O plano de dados é a camada de infraestrutura que alimenta os projetos do Elastic Cloud Serverless e com a qual os usuários interagem quando desejam usar seus projetos.
Uma decisão fundamental de design que enfrentamos foi como o plano de controle global deveria se comunicar com os clusters do Kubernetes no plano de dados. Nós exploramos dois modelos:
Modelo Push: o plano de controle envia proativamente configurações para clusters regionais do Kubernetes.
Modelo Pull: clusters regionais do Kubernetes buscam periodicamente configurações do plano de controle.
Após avaliar ambas as abordagens, adotamos o modelo Push devido à sua simplicidade, fluxo de dados unidirecional e capacidade de operar clusters Kubernetes de forma independente do plano de controle durante falhas. Este modelo nos permitiu manter uma lógica de agendamento simples enquanto reduzíamos a sobrecarga operacional e as complexidades na recuperação de falhas.
Redimensionamento automático: além do redimensionamento horizontal e vertical
Para proporcionar uma experiência realmente sem servidor, precisávamos de um mecanismo inteligente de redimensionamento automático que ajustasse dinamicamente os recursos conforme as exigências da carga de trabalho. Nossa jornada começou com o redimensionamento horizontal básico, mas logo percebemos que serviços diferentes tinham necessidades de redimensionamento exclusivas. Alguns necessitavam de recursos computacionais adicionais, enquanto outros demandavam uma maior alocação de memória.
Aprimoramos nossa abordagem ao criar controladores personalizados de redimensionamento automático que analisam métricas específicas de carga de trabalho em tempo real, permitindo um redimensionamento dinâmico que é tanto responsivo quanto eficiente em termos de recursos. Como resultado, podemos redimensionar perfeitamente as operações de indexação e de busca no Elasticsearch sem superprovisão. Essa estratégia permite o uso de redimensionamento automático multidimensional de pods, permitindo que as cargas de trabalho sejam redimensionadas horizontal e verticalmente com base na CPU, memória e métricas personalizadas geradas pela carga de trabalho.
Para nossas cargas de trabalho do Elasticsearch, usamos uma API específica para serverless do Elasticsearch que retorna certas métricas chave sobre o cluster. Veja como funciona: os recomendadores sugerem os recursos de computação necessários (réplicas, memória e CPU) e armazenamento para um determinado nível. Essas recomendações são então convertidas por mapeadores em configurações concretas de computação e armazenamento aplicáveis a contêineres. Para evitar flutuações rápidas de redimensionamento, os estabilizadores filtram essas recomendações. Os limitadores então entram em ação, impondo tanto restrições mínimas quanto máximas de recursos. A saída do limitador é utilizada para ajustar a implantação do Kubernetes após considerar algumas políticas de restrição opcionais.
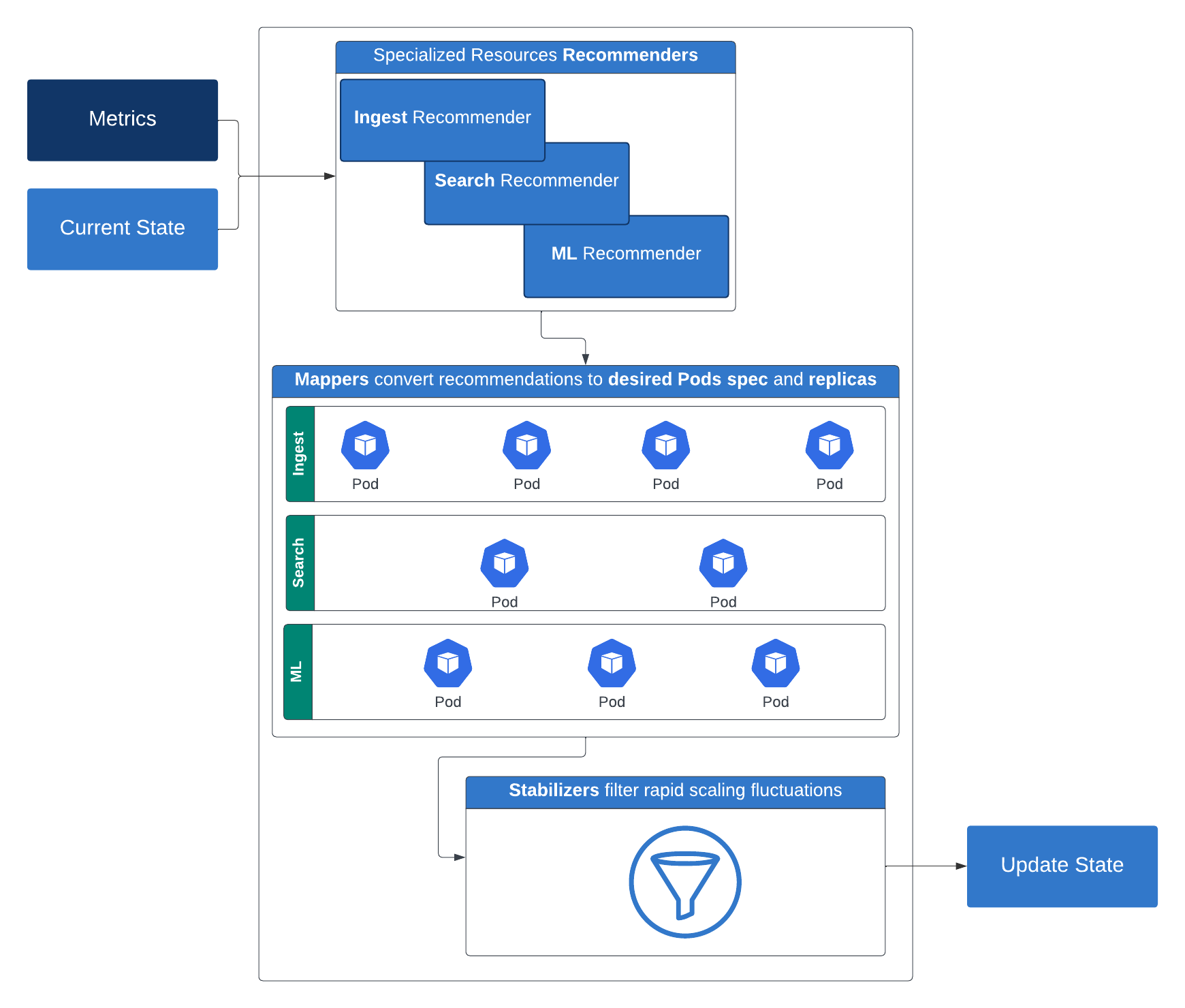
Essa estratégia de redimensionamento inteligente e em camadas garante desempenho e eficiência em diversas cargas de trabalho e é um grande passo em direção a uma plataforma verdadeiramente sem servidor.
O Elastic Cloud Serverless apresenta recursos de redimensionamento automático diferenciados, adaptados à camada de pesquisa, aproveitando entradas como janelas de dados otimizadas, configurações de potência de pesquisa e métricas de carga de pesquisa (incluindo carga do thread pool e carga da fila). Esses sinais trabalham juntos para definir configurações de base e acionar decisões de redimensionamento dinâmico com base nos padrões de uso de pesquisa do cliente. Para uma análise mais aprofundada do redimensionamento automático da camada de pesquisa, leia este post do blog. Para saber mais sobre como funciona o redimensionamento automático da camada de indexação, confira este post do blog.
Criação de um modelo de preços flexível
Um princípio fundamental da computação serverless é alinhar os custos com o uso real. Queríamos um modelo de preços que fosse simples, flexível e transparente. Depois de avaliar várias abordagens, projetamos um modelo que equilibra diferentes cargas de trabalho em nossas soluções núcleo:
Observability e Security: cobrados com base nos dados ingeridos e retidos, com preços escalonados
Elasticsearch (Search): preços baseados em unidades de computação virtuais, incluindo ingestão, busca, machine learning e retenção de dados
Essa abordagem oferece aos clientes preços de pagamento conforme o uso, proporcionando maior flexibilidade e previsibilidade de custos.
Para implementar esse modelo de precificação (que passou por muitas iterações durante a fase de desenvolvimento), sabíamos que precisávamos de uma arquitetura com escalabilidade e flexibilidade. Por fim, construímos um pipeline que suporta um modelo de propriedade distribuída, com diferentes equipes responsáveis por diferentes componentes do processo de ponta a ponta. Abaixo, descrevemos os dois principais segmentos desse pipeline: coleta de uso medido por meio do pipeline de uso, e cálculos de cobrança por meio do pipeline de cobrança.
Pipeline de uso
Componentes voltados para o usuário, como Elasticsearch e Kibana, enviam dados de uso medidos para o serviço de api de utilização, executado em cada cluster de carga de trabalho. Esse serviço realiza um enriquecimento nos dados e os coloca em uma fila. O serviço de envio de utilização, então, extrai esses dados da fila e os encaminha para o armazenamento de objetos. Essa arquitetura desacoplada é necessária para tornar o pipeline resiliente ao enviar dados entre regiões e CSPs, pois priorizamos a entrega em vez da latência. Assim que os dados chegam ao armazenamento de objetos, eles ficam disponíveis para outros processos em modo somente leitura para transformações ou agregações adicionais (por exemplo, para faturamento ou análise).
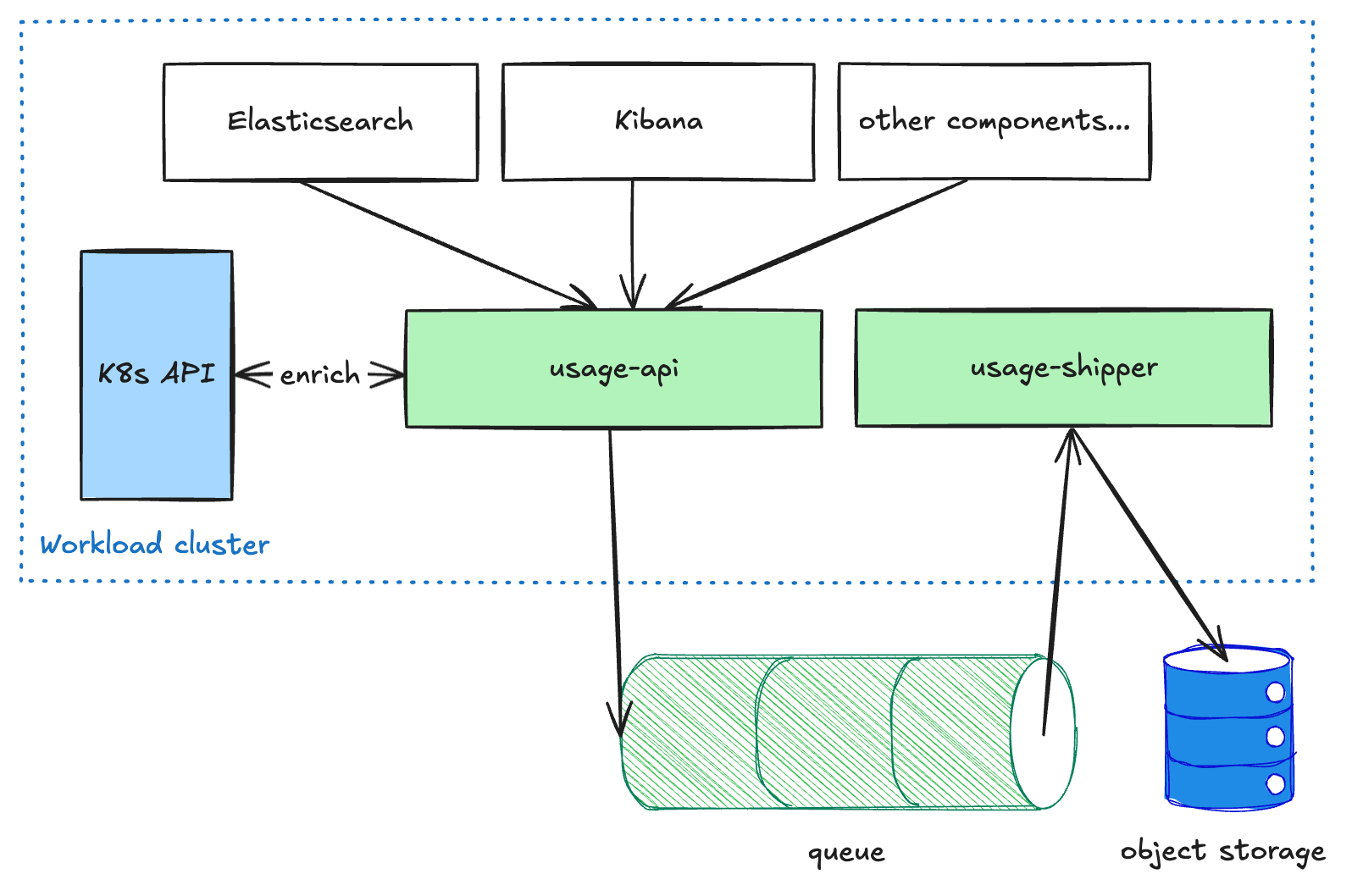
Pipeline de faturamento
Assim que os registros de uso são depositados no armazenamento de objetos, o pipeline de faturamento coleta os dados e os transforma em quantidades de ECU (Unidades Elásticas de Consumo, nossa unidade de faturamento independente de moeda) pelas quais faturamos. O processo básico é assim:
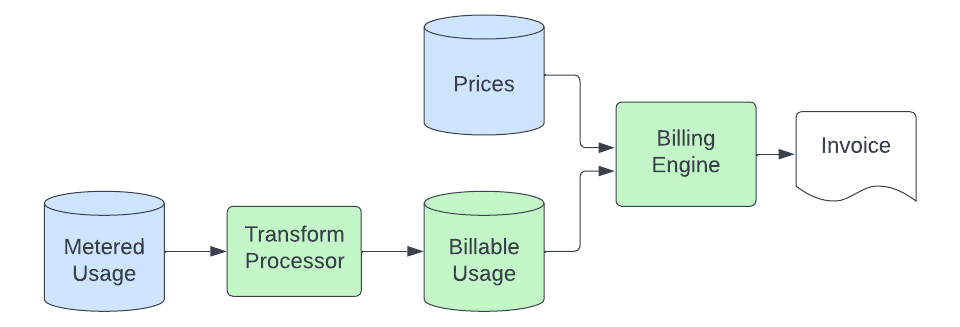
Um processo de transformação consome os registros de uso medido do armazenamento de objetos e os converte em registros que podem ser efetivamente cobrados. Este processo envolve a conversão de unidades (a aplicação com medição pode medir o armazenamento em bytes, mas podemos cobrar em GB), filtragem das fontes de uso pelas quais não cobramos, mapeamento do registro para um produto específico (isso envolve a análise de metadados nos registros de uso para associar o uso a um produto específico da solução que tenha um preço único) e envio desses dados para um cluster do Elasticsearch que é consultado pelo nosso mecanismo de cobrança. O objetivo desta etapa de transformação é fornecer um local centralizado onde a lógica reside para converter os registros genéricos de uso medido em quantidades específicas do produto que estão prontas para precificação. Isso nos permite manter essa lógica especializada fora dos aplicativos medidos e do mecanismo de cobrança, que queremos manter simples e agnóstico ao produto.
O mecanismo de faturamento então mapeia esses registros de uso faturável, que agora contêm um identificador que mapeia para um produto em nosso banco de dados de preços. No mínimo, esse processo envolve somar o uso em um determinado período e multiplicar a quantidade pelo preço do produto para calcular as ECUs. Em alguns casos, ele também deve segmentar o uso em níveis com base no uso acumulado ao longo do mês e mapeá-los para níveis de produtos com preços individuais. Para tolerar atrasos no processo upstream sem registros perdidos, o uso é faturado no momento em que chega ao armazenamento de dados de uso faturável, mas é precificado de acordo com o momento em que ocorreu (para garantir que não apliquemos o preço errado para uso que chegou "atrasado"). Isso oferece um recurso de "autocorreção" ao nosso processo de faturamento.
Por fim, uma vez que as ECUs são calculadas, avaliamos quaisquer custos adicionais (como os de suporte) e então inserimos isso nos cálculos de faturamento, que, por fim, resultam em uma fatura (enviada por nós ou por um de nossos parceiros de marketplace de nuvem). Esta parte final do processo não é nova ou exclusiva do Serverless e é tratada pelos mesmos sistemas que faturam nosso produto hospedado.
Conclusões
Construir uma plataforma de infraestrutura que ofereça funcionalidades semelhantes em vários CSPs é um desafio complexo. Equilibrar confiabilidade, escalabilidade e eficiência de custo requer iteração contínua e concessões. As implementações do Kubernetes variam significativamente entre os provedores de serviços em nuvem, e garantir uma experiência consistente entre eles requer testes e personalização extensivos.
Além disso, adotar uma arquitetura serverless não é apenas uma transformação técnica, mas também uma mudança cultural. É necessário passar da solução de problemas reativa para a otimização proativa do sistema e priorizar a automação para minimizar a carga operacional. Ao longo de nossa jornada, aprendemos que construir uma plataforma serverless bem-sucedida envolve tanto decisões arquitetônicas quanto fomentar uma mentalidade que abrace a inovação e o aprimoramento contínuos.
Um olhar para o futuro
O sucesso no mundo serverless depende de oferecer uma experiência excepcional ao cliente, otimizar proativamente as operações e equilibrar continuamente confiabilidade, escalabilidade e eficiência de custos. Olhando para o futuro, nosso foco continua em desenvolver novos recursos para nossos clientes no Elastic Cloud Serverless, tornando o serverless o melhor lugar para executar o Elasticsearch para todos.
O futuro da busca, segurança e observabilidade está aqui sem comprometer a velocidade, a escala ou o custo. Experimente o Elastic Cloud Serverless e o Search AI Lake para desbloquear novas oportunidades com seus dados. Saiba mais sobre as possibilidades do serverless ou comece sua avaliação gratuita agora mesmo.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste artigo permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis no momento poderão não ser entregues ou não chegarem no prazo previsto.
Nesta postagem do blog, podemos ter usado ou feito referência a ferramentas de IA generativa de terceiros, que são de propriedade e operadas por seus respectivos proprietários. A Elastic não tem nenhum controle sobre as ferramentas de terceiros e não temos nenhuma responsabilidade ou obrigação por seu conteúdo, operação ou uso, nem por qualquer perda ou dano que possa surgir do uso de tais ferramentas. Tenha cuidado ao usar ferramentas de IA com informações pessoais, sensíveis ou confidenciais. Os dados que você enviar poderão ser usados para treinamento de IA ou outros fins. Não há garantia de que as informações fornecidas serão mantidas seguras ou confidenciais. Você deve se familiarizar com as práticas de privacidade e os termos de uso de qualquer ferramenta de IA generativa antes de usá-la.
Elastic, Elasticsearch e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir