Como migrar do Elasticsearch autogerenciado para o Elastic Cloud na AWS
Cada vez mais, estamos vendo cargas de trabalho locais serem migradas para a nuvem. O Elasticsearch existe há muitos anos com nossos usuários e clientes geralmente gerenciando-o eles mesmos no local. O Elasticsearch Service no Elastic Cloud, nosso serviço do Elasticsearch gerenciado que é executado na Amazon Web Services (AWS), no Google Cloud e no Microsoft Azure em muitas regiões diferentes, é a melhor maneira de consumir o Elastic Stack e nossas soluções para busca empresarial, observabilidade e segurança.
Se você tem interesse em migrar do Elasticsearch autogerenciado, o Elasticsearch Service cuida do seguinte:
- Provisionamento e gerenciamento da infraestrutura subjacente
- Criação e gerenciamento dos clusters do Elasticsearch
- Redimensionamento dos clusters para cima e para baixo
- Atualizações, patches e snapshots
Com isso, você pode concentrar seu tempo e esforço na resolução de outros desafios.
Este post do blog explora como migrar para o Elasticsearch Service gerando um snapshot do seu cluster do Elasticsearch e restaurando-o no Elasticsearch Service.
Gerar um snapshot do cluster
A primeira coisa a considerar ao migrar do Elasticsearch autogerenciado para o Elasticsearch Service é qual provedor de serviços em nuvem e região você gostaria de usar. Isso normalmente dependerá de suas cargas de trabalho existentes implantadas, da estratégia de nuvem e uma série de outros fatores.
Aqui veremos o processo para o Elasticsearch Service na AWS. Em breve, veremos como fazer o mesmo para o Google Cloud e o Azure.
A maneira mais fácil de migrar dados de um cluster do Elasticsearch para outro cluster é gerar um snapshot do cluster e usar esse snapshot para restaurá-lo no novo cluster do Elasticsearch Service.
Há várias maneiras de gerar um snapshot de um cluster. A mais fácil é executar uma operação de snapshot único.
Supondo que seu Elasticsearch esteja ingerindo dados constantemente, a desvantagem da operação de snapshot único é que há um intervalo de tempo e perda de dados entre o momento em que o snapshot é gerado e quando ele é restaurado no novo cluster. Para minimizar essa defasagem, é aconselhável criar uma política de ciclo de vida de snapshot. Se o cluster do Elasticsearch não estiver ingerindo dados constantemente, como para um caso de uso de busca, um snapshot único será adequado.
Antes de criar um snapshot de um cluster local, você precisa configurar o bucket do AWS S3 onde o snapshot do cluster local será armazenado. Esse é o local de onde o novo cluster do Elasticsearch Service em execução na AWS restaurará o estado do cluster.
As etapas gerais necessárias para fazer isso são as seguintes:
- Configurar o armazenamento na nuvem (neste caso, o bucket do AWS S3)
- Configurar o repositório do snapshot local
- Configurar sua política de snapshot
- Provisionar o novo cluster no Elasticsearch Service
- Configurar o repositório do snapshot customizado do cluster do Elasticsearch Service
- Restaurar o cluster do Elasticsearch Service de um snapshot local
Configurar o armazenamento na nuvem
- Crie um bucket do S3. O bucket do S3 deve estar na mesma região selecionada para o cluster do Elasticsearch Service:
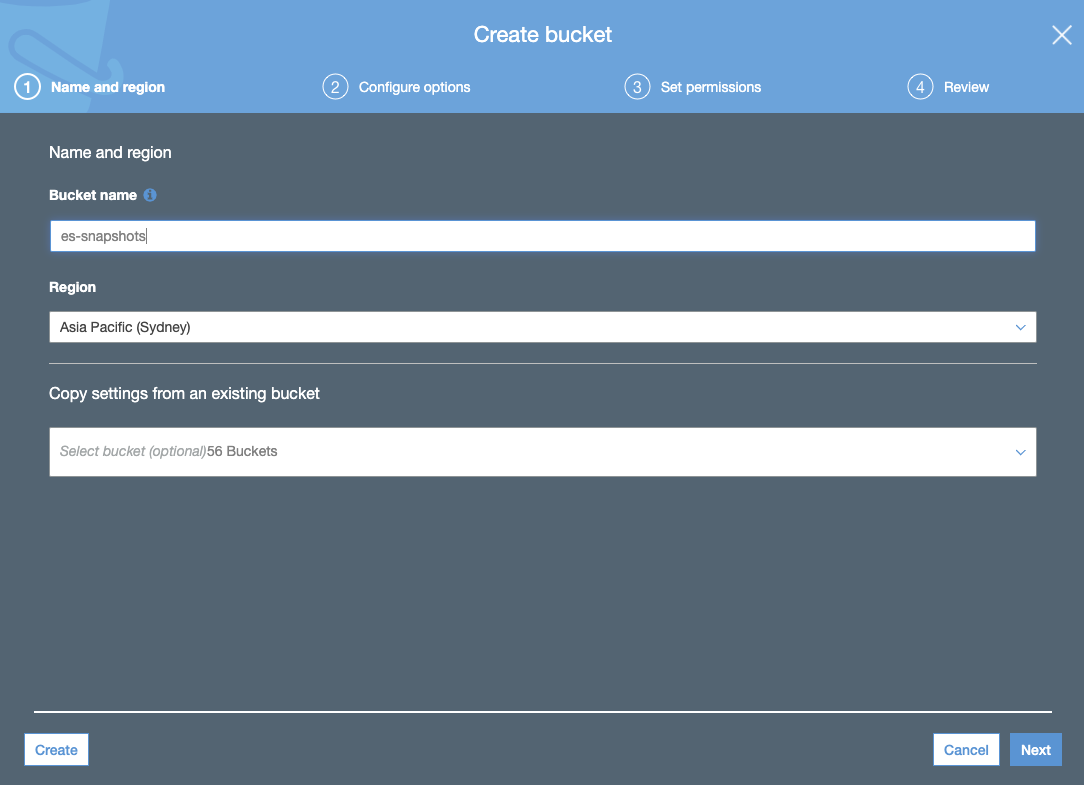
- Crie a política de bucket do S3 por meio da guia JSON e adicione o JSON da política de bucket do S3 (usando o nome do seu bucket):
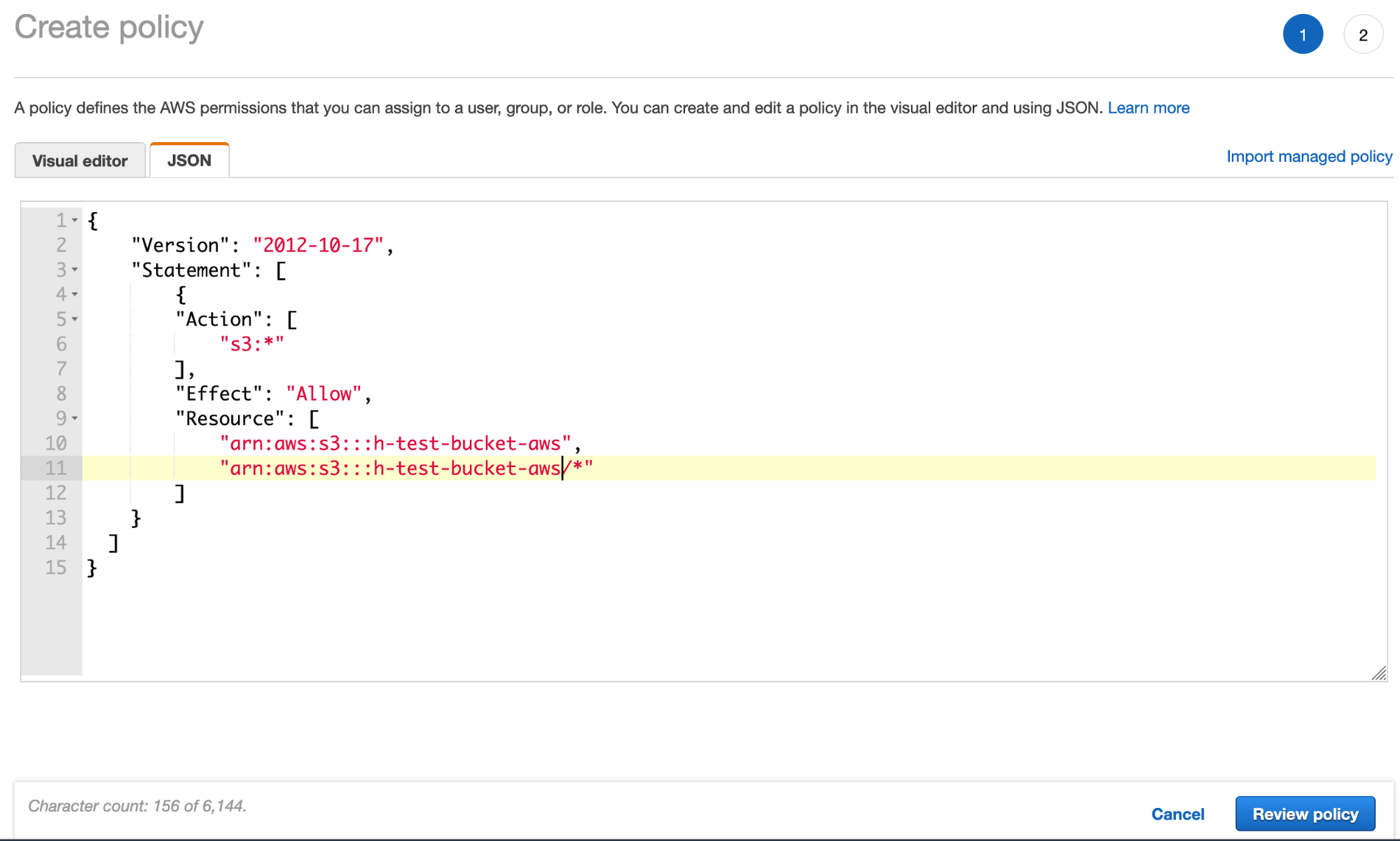
- Clique em Review policy (Conferir política) e dê um nome à sua política:
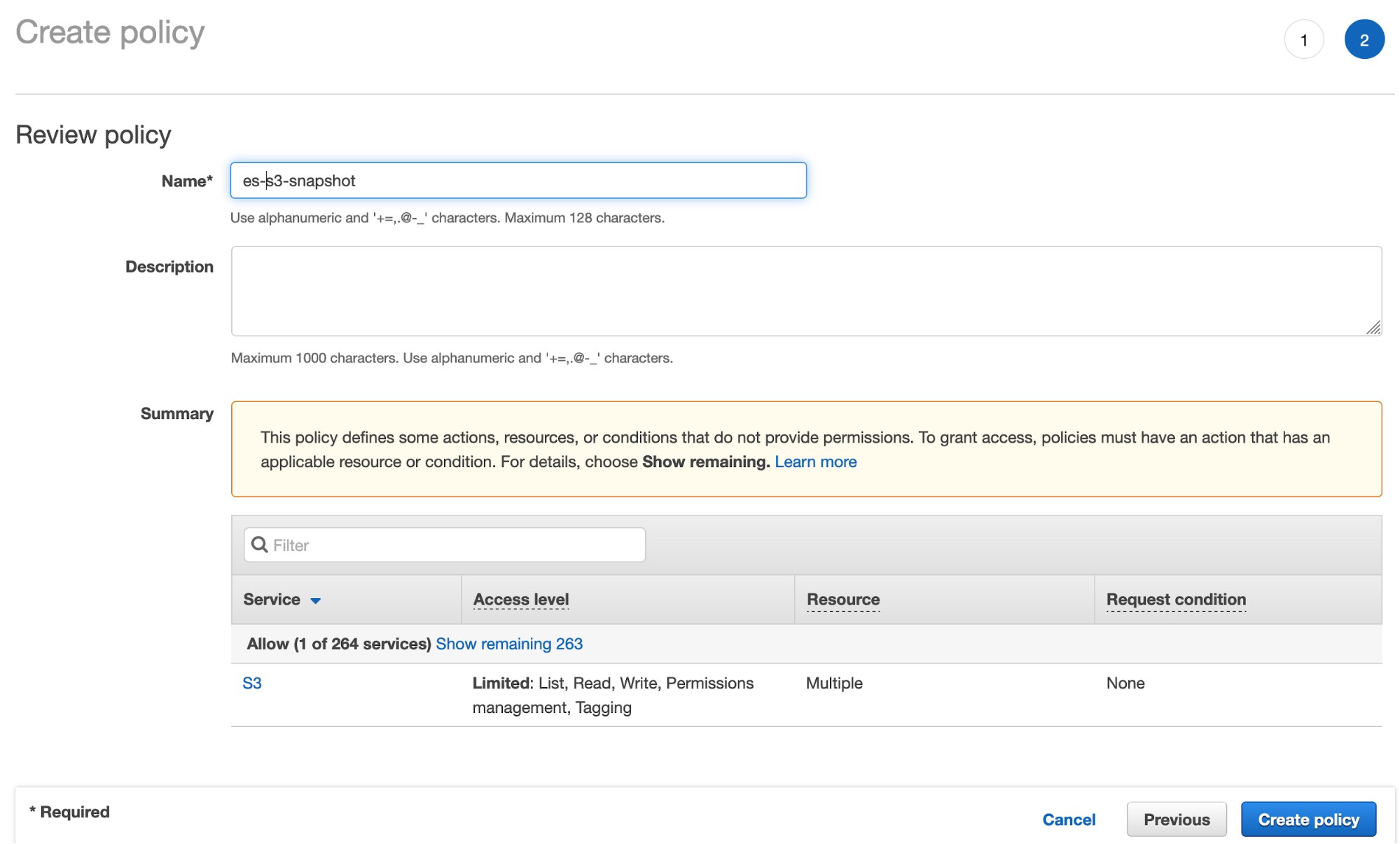
- Crie o usuário do IAM e atribua a política de bucket do S3 criada acima:
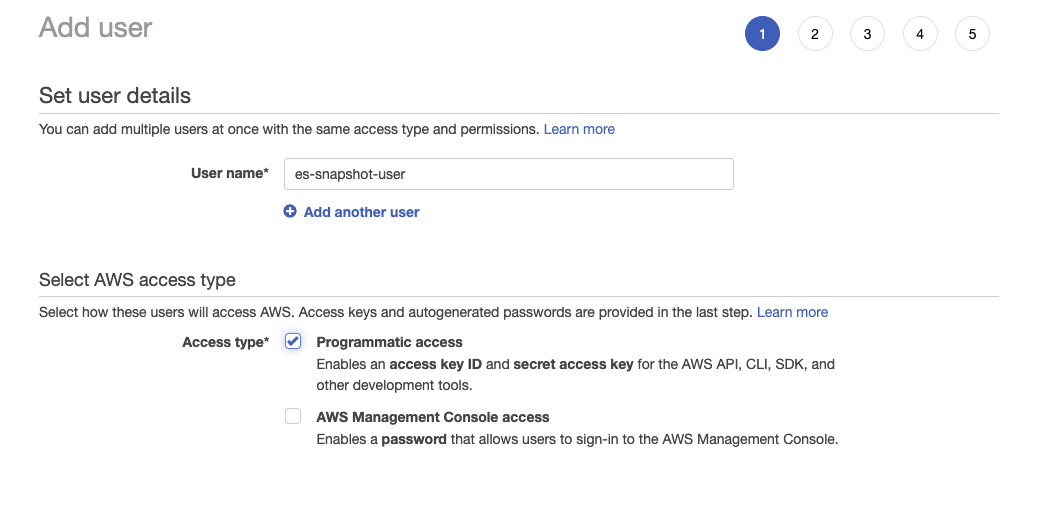
- Clique em Next: Permissions (Próximo: Permissões), selecione Attach existing policies directly (Anexar políticas existentes diretamente) e procure a política que você criou na etapa anterior:
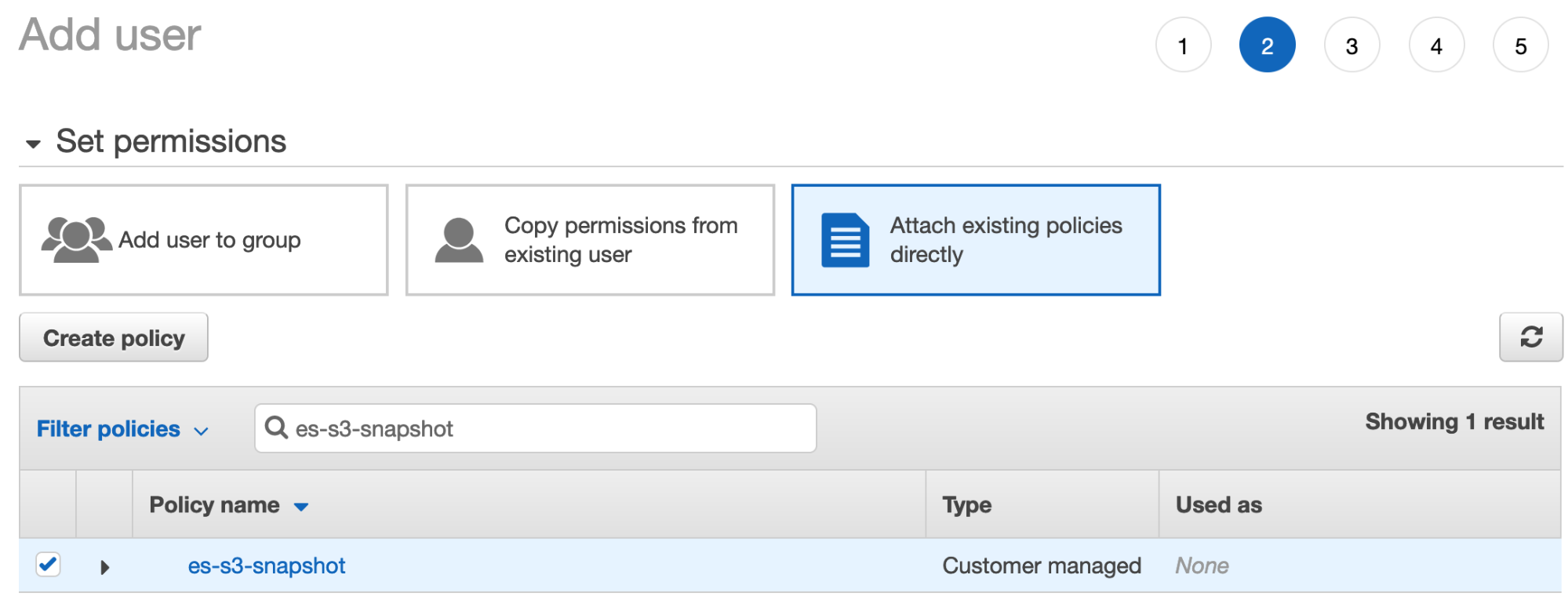
- Verifique se essa política está marcada e clique em Next: Tags (Próximo: Tags). Você pode pular a adição de tags e clicar em Create User (Criar usuário).
- Baixe as credenciais de segurança do usuário.
Configurar o repositório do snapshot local
1. Instale o plugin do S3
Instale o plugin do S3 para Elasticsearch em sua implantação local executando o seguinte comando em cada nó local do Elasticsearch no diretório inicial do Elasticsearch:
sudo bin/elasticsearch-plugin install repository-s3
Você terá de reiniciar o nó depois de executar esse comando.
2. Configure as permissões do cliente do S3
Configure as permissões do cliente do S3 no cluster local executando os seguintes comandos:
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
Isso é necessário para que o cluster local tenha as credenciais necessárias para gravar os snapshots no S3. Access_key e secret_key estão disponíveis do usuário do IAM criado na etapa anterior.
Configurar sua política de snapshot
1. Configure o repositório de snapshots
Configure o repositório de snapshots do S3 em seu cluster local executando o comando a seguir em Kibana Dev Tools. Aqui estamos informando ao cluster local em qual bucket do S3 gravar o snapshot. O usuário do IAM que você acabou de criar deve ter permissões para gravar e ler nesse bucket do S3.
PUT _snapshot/{ "type": "s3", "settings": { "bucket": " " } }
2. Crie uma política de snapshot
Em seguida, você criará uma política de snapshot em seu cluster local que armazenará o snapshot no bucket do S3 recém-criado:
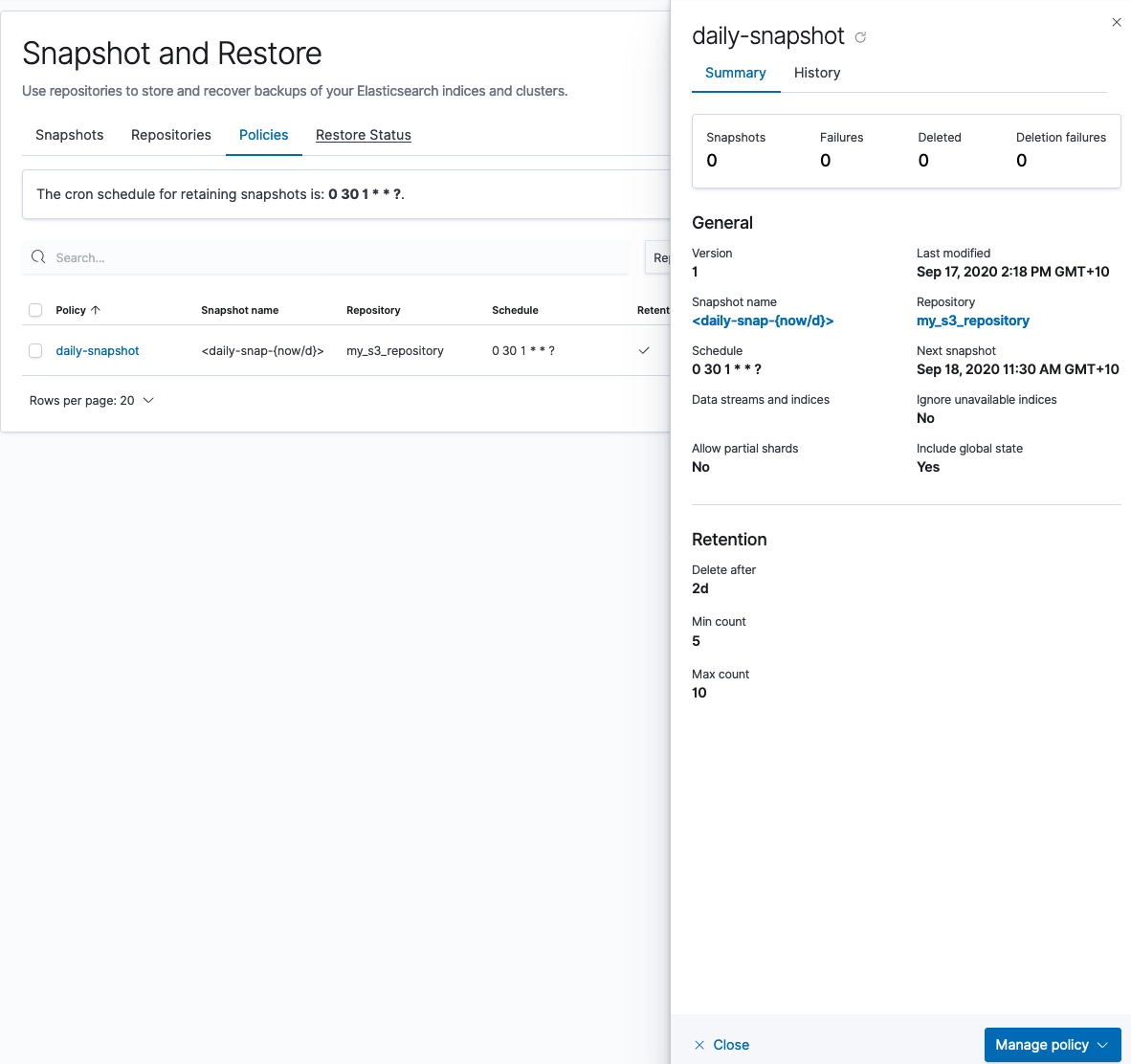
Você também pode criar um snapshot único no Kibana Dev Tools:
PUT /_snapshot// ?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false }
Verifique se os snapshots estão funcionando com a execução deste comando no Dev Tools:
GET _snapshot//_all
Provisionar o novo cluster no Elasticsearch Service
Assim que tivermos snapshots funcionando no S3, será a hora de provisionar um novo cluster no Elasticsearch Service em cloud.elastic.co. Aqui você pode escolher o caso de uso que melhor reflita a sua carga de trabalho existente, a região da AWS e sua versão do Elasticsearch.
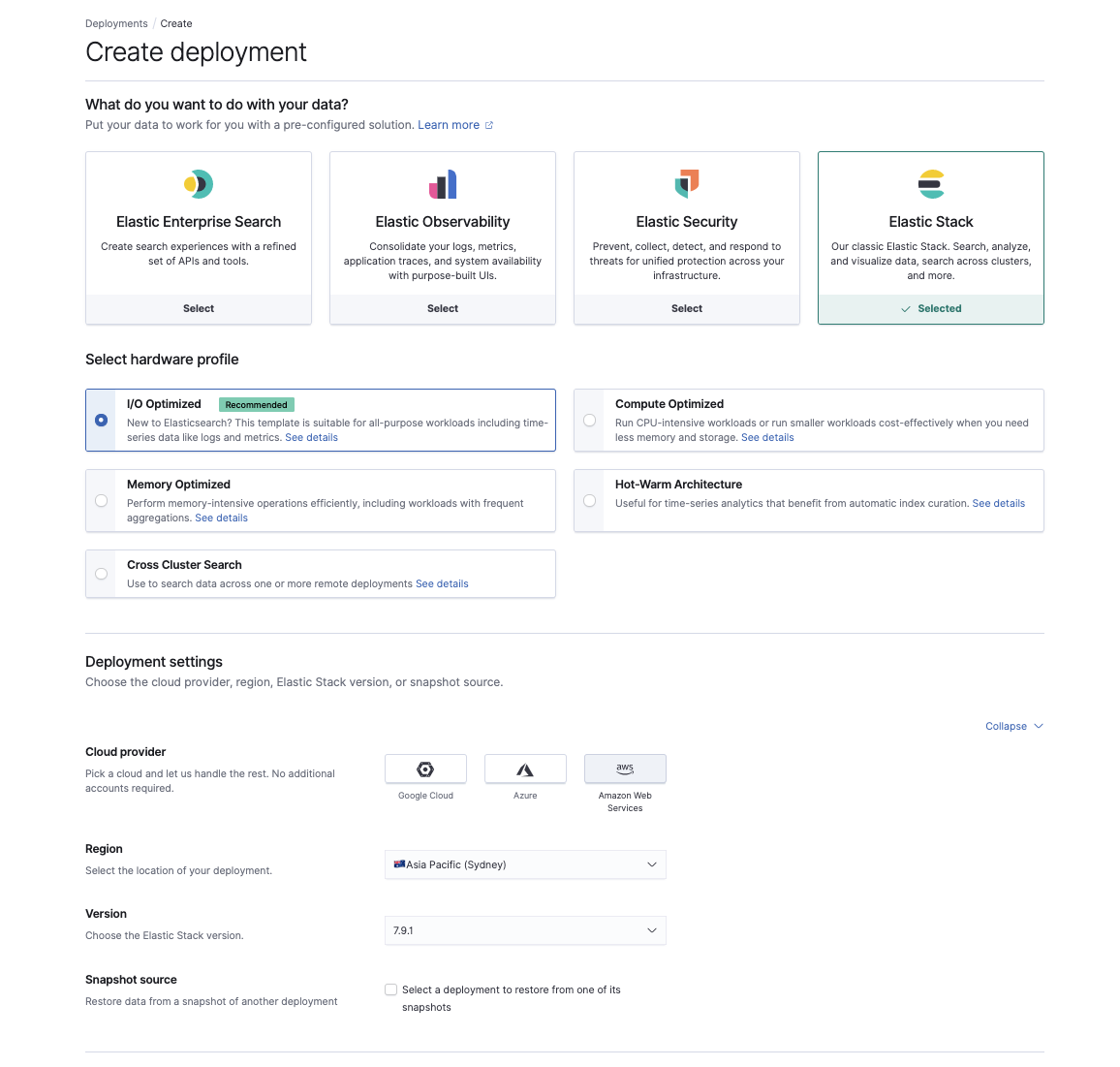
No console do Elasticsearch Service, defina as configurações do keystore do cluster:
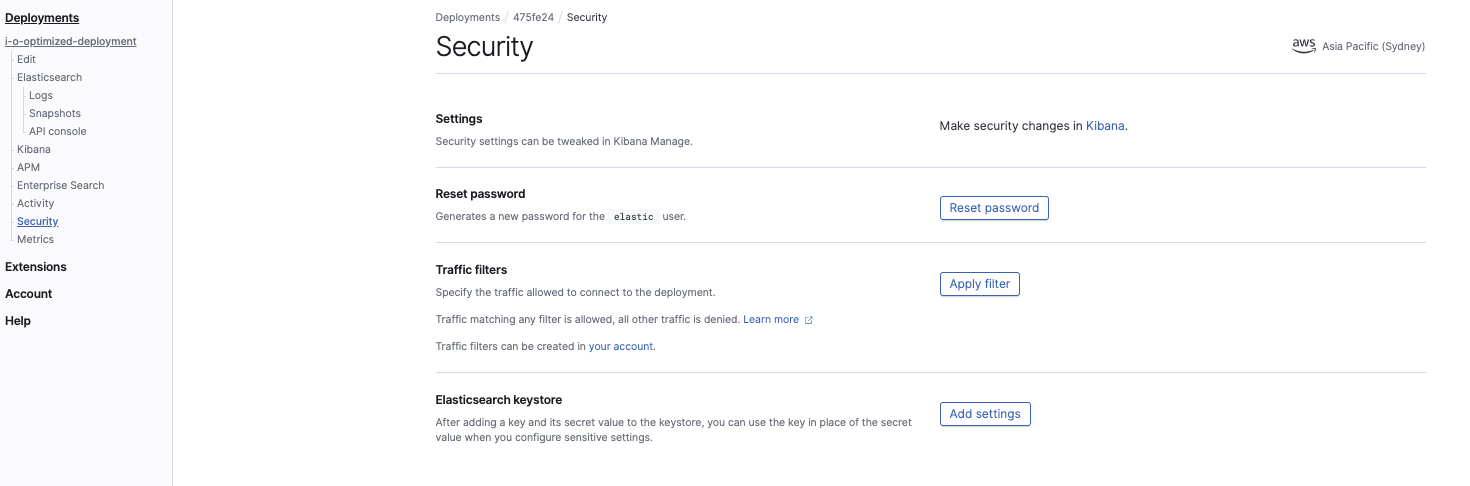
As duas configurações que precisamos definir são as seguintes:
s3.client.default.access_key s3.client.default.secret_key
Isso é necessário para que o cluster do Elasticsearch Service tenha permissão para ler o snapshot do bucket do S3. Elas serão as mesmas que as credenciais de segurança do usuário do IAM.
Configurar o repositório do snapshot customizado do cluster do Elasticsearch Service
Agora temos de criar um novo repositório de snapshots no cluster do Elasticsearch Service. Isso informa ao Elasticsearch Service onde o snapshot do qual queremos restaurar está localizado no S3. Para fazer isso, faça login no Kibana, selecione Stack Management (Gerenciamento da stack) e navegue até as configurações de Snapshot and Restore (Snapshot e restauração). Selecione Register a repository (Registrar um repositório):
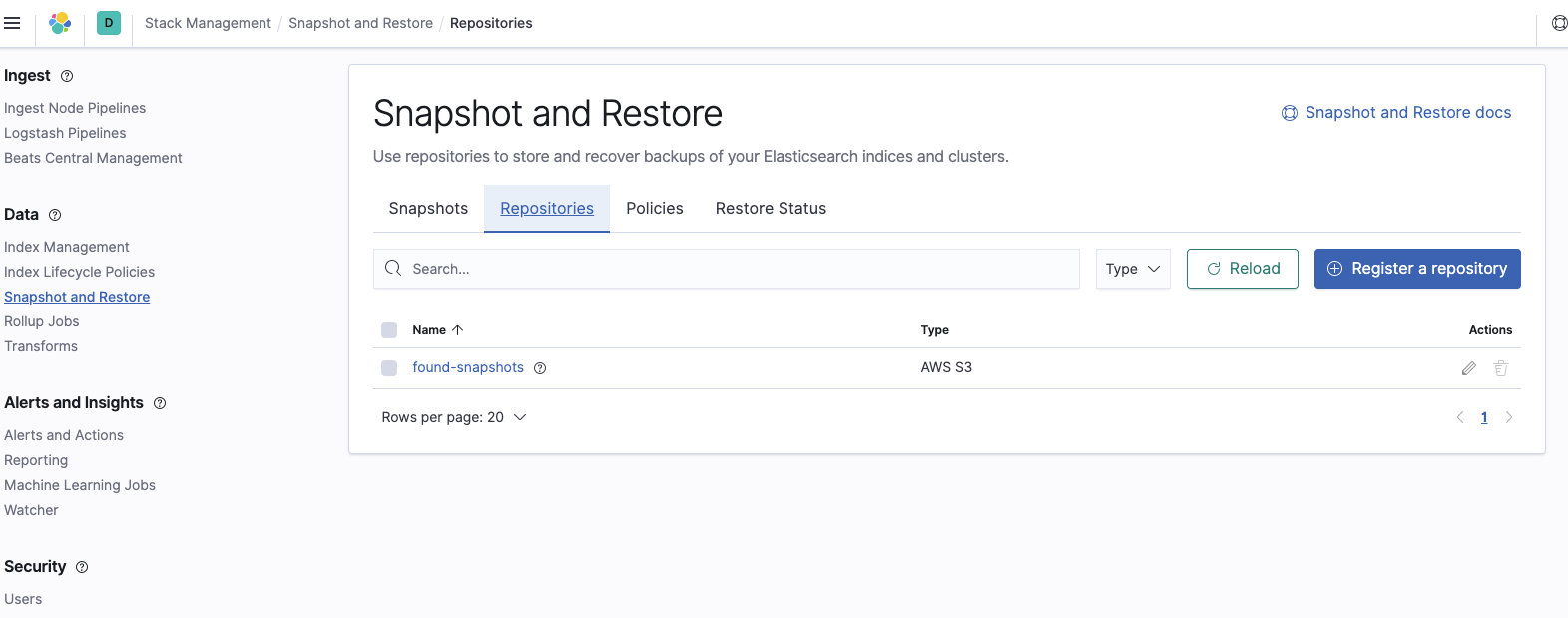
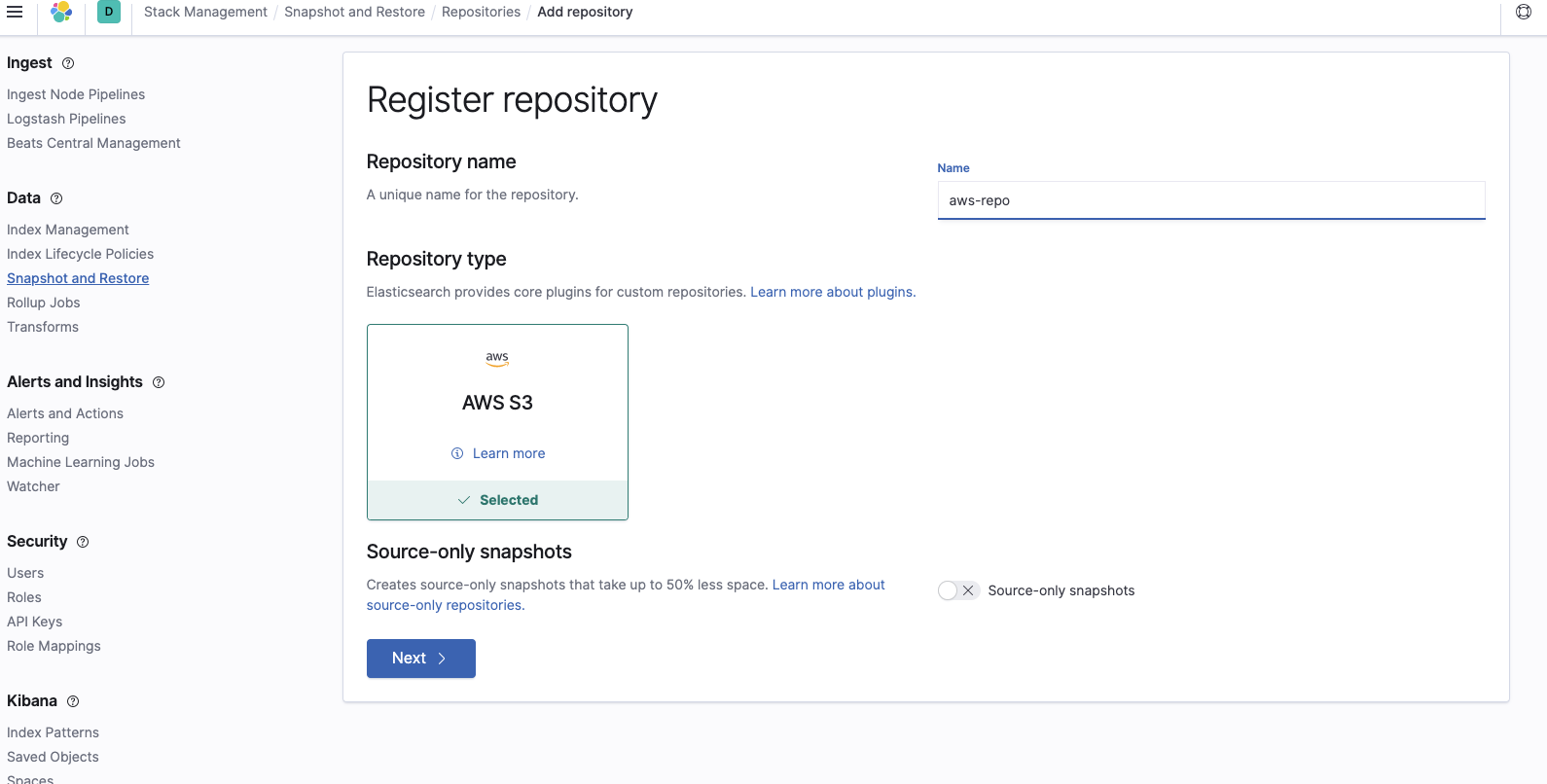
Adicione o nome do bucket onde os snapshots estão localizados:
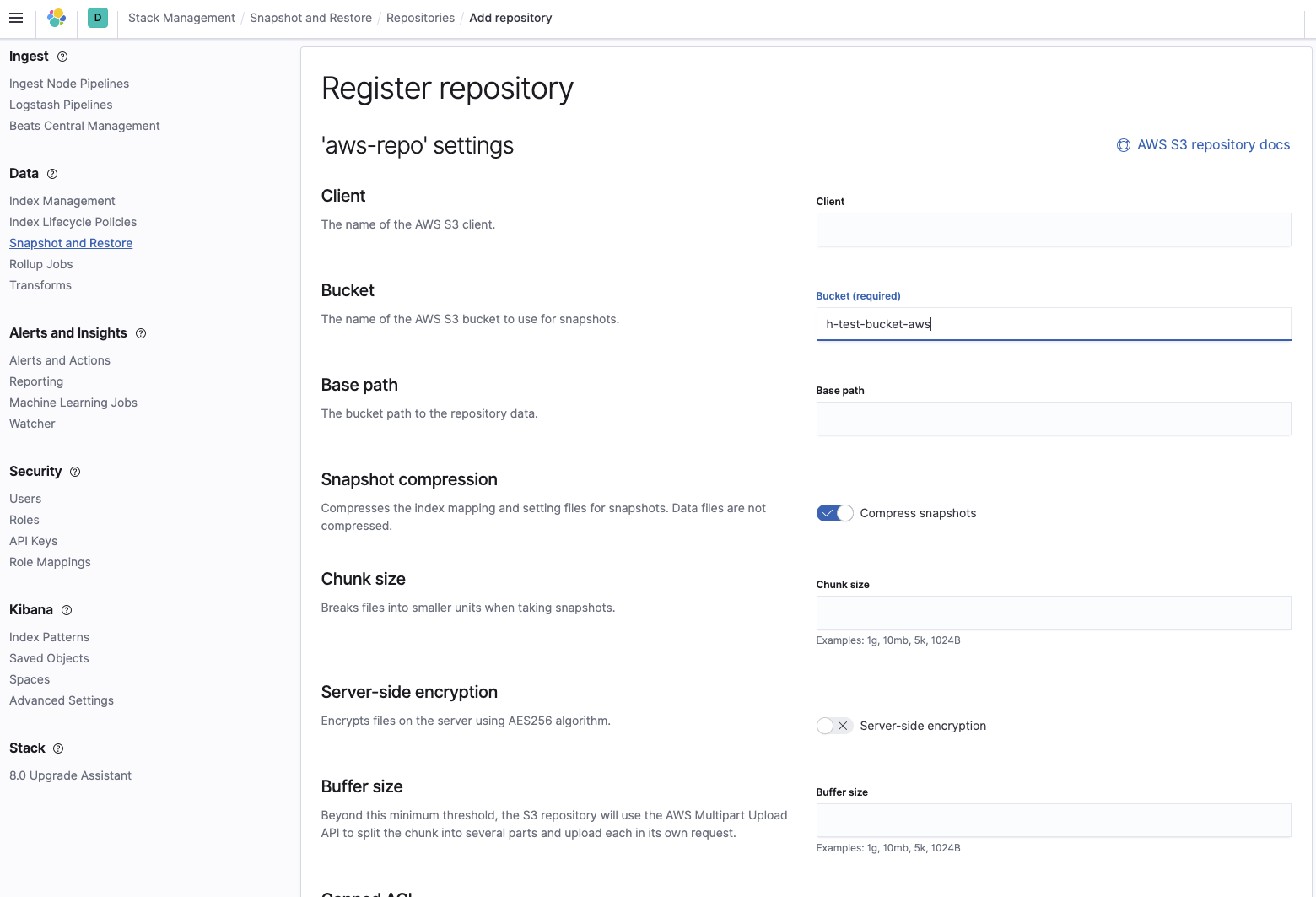
Então, verifique se o repositório foi configurado corretamente:
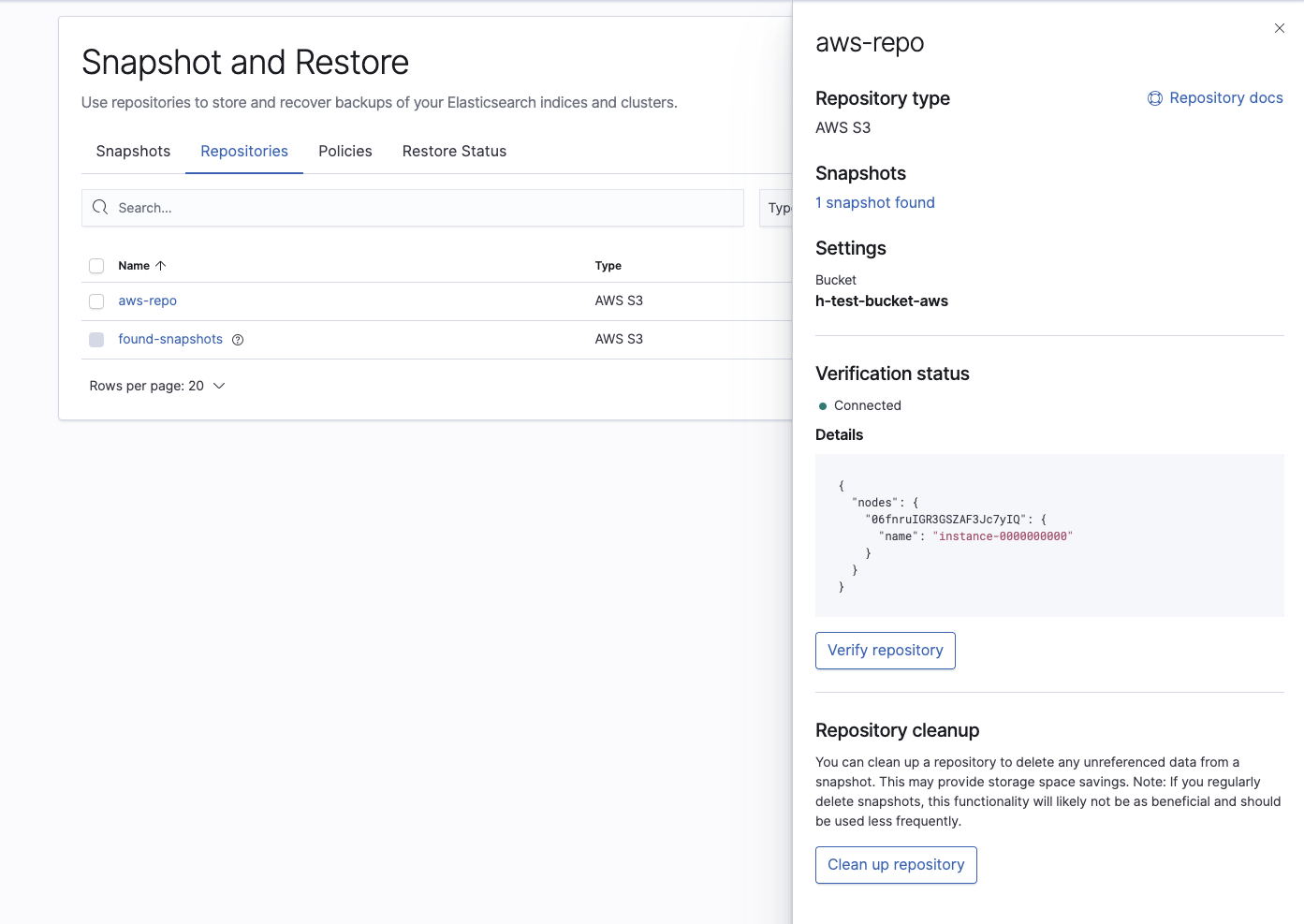
Por fim, confirme se o cluster do Elasticsearch Service consegue ver o snapshot que queremos restaurar:
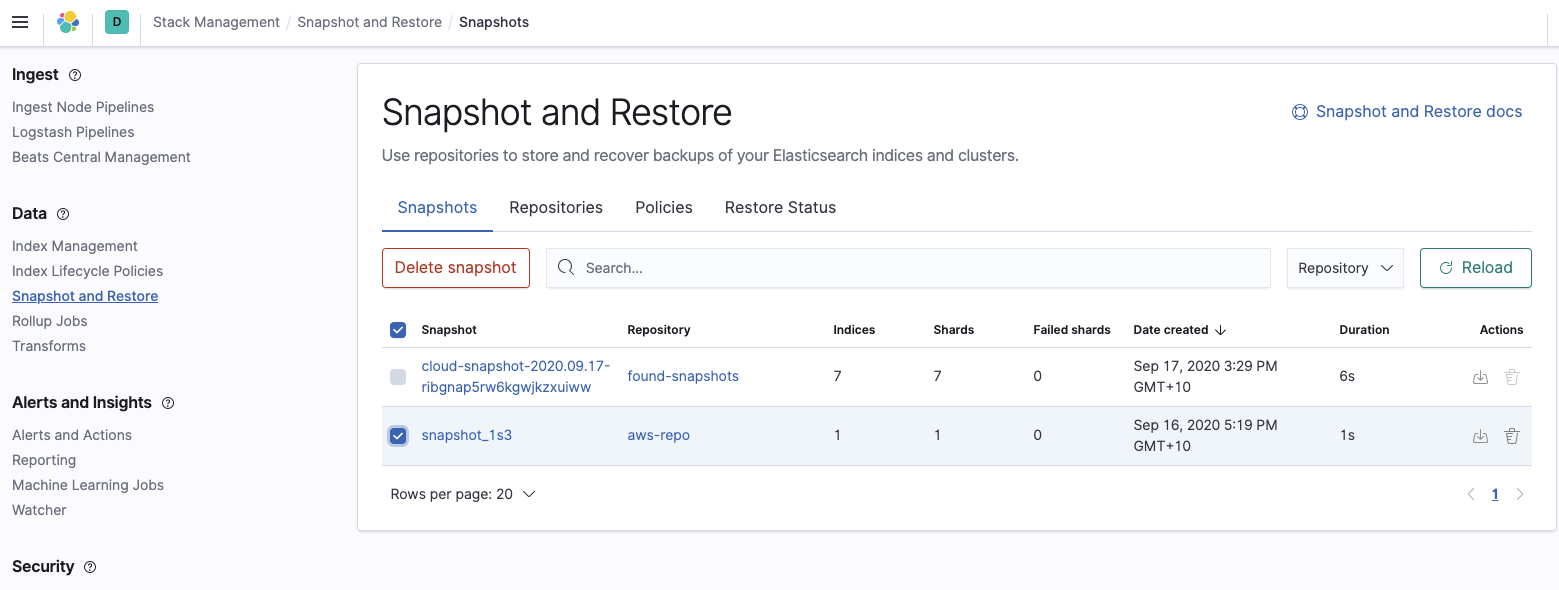
Restaurar o cluster do Elasticsearch Service do snapshot
Para restaurar o snapshot, vá para o console da API do cluster do Elasticsearch Service no console do Elasticsearch Service e execute os três comandos a seguir. Observe que todos os três comandos são executados como POST no console da API.
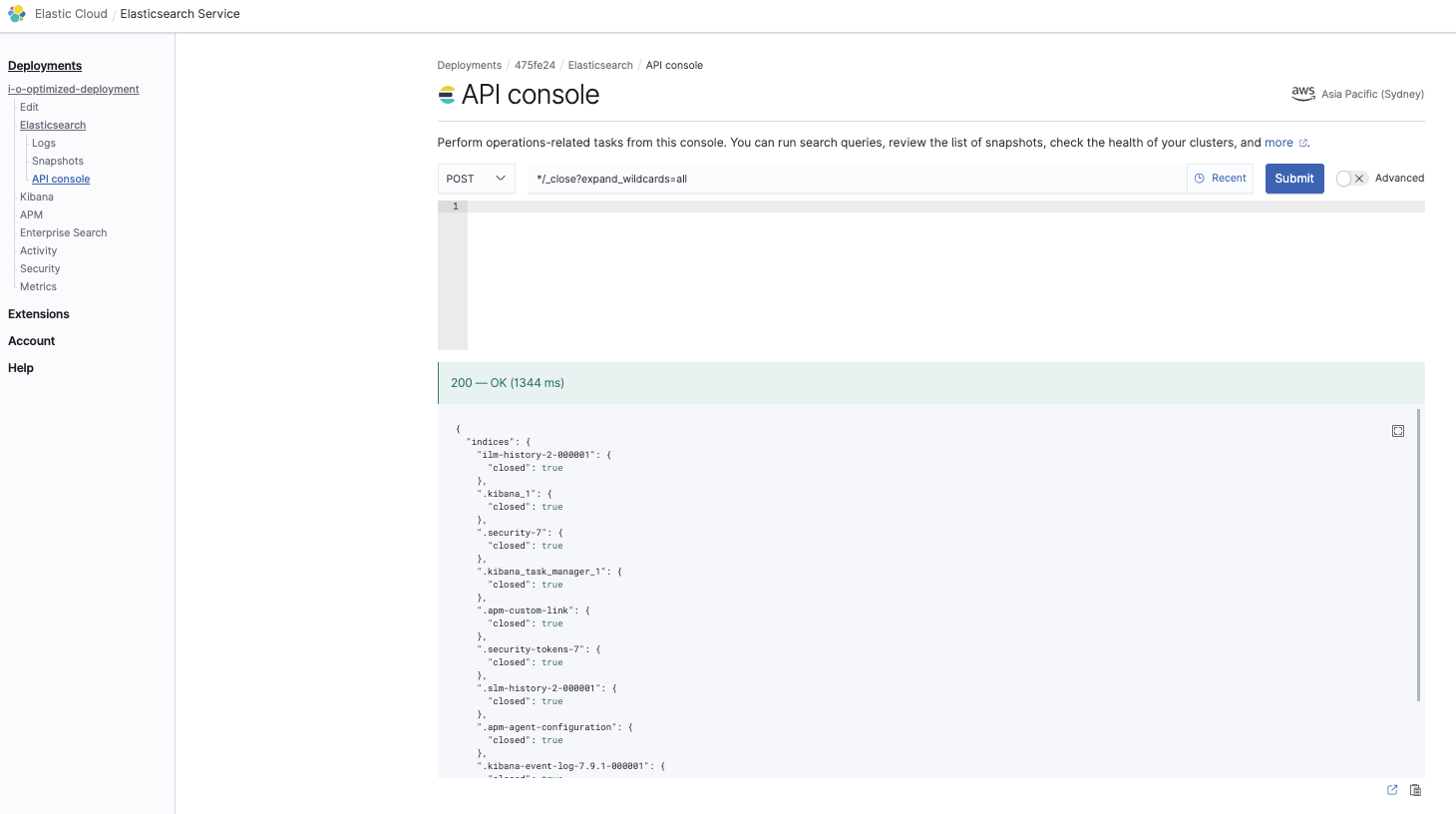
Feche todos os índices
*/_close?expand_wildcards=all
Isso é para garantir que todos os índices sejam fechados primeiro para que não haja conflitos durante a fase de restauração:
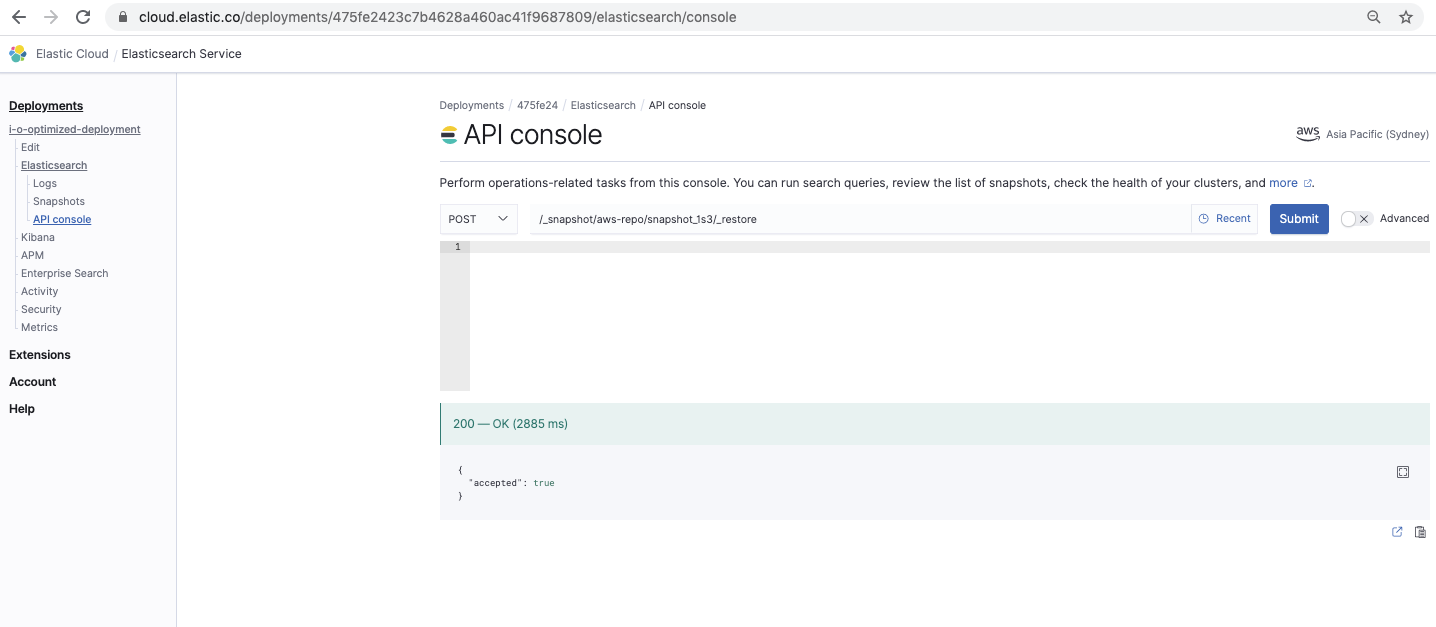
Restaure o snapshot
/_snapshot// /_restore
Esse comando restaura o snapshot:
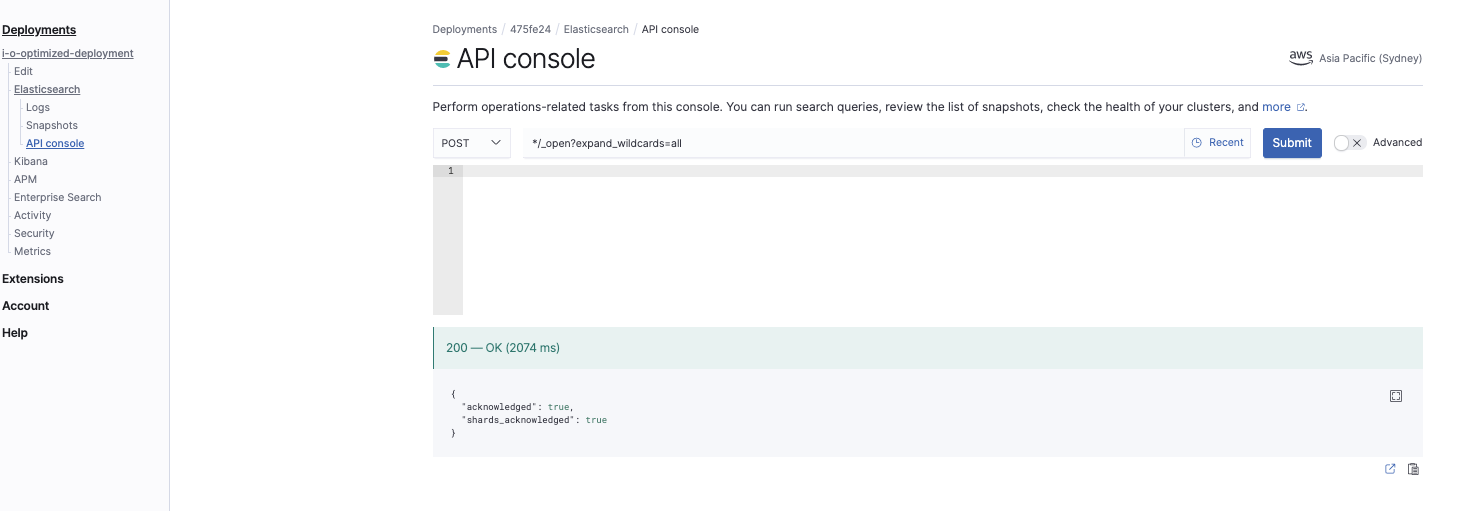
Abra todos os índices
*/_open?expand_wildcards=all
Esse comando abre todos os índices:
Verificar a restauração do snapshot
Verifique se você restaurou o snapshot com todos os índices. Entre no Kibana e execute o seguinte comando no Dev Tools:
GET _cat/indices
Neste ponto, você deverá ter o novo cluster em execução no Elasticsearch Service com os mesmos dados do cluster autogerenciado do qual gerou o snapshot. Agora você pode redirecionar suas fontes de ingestão, como Beats ou Logstash, para o novo endpoint do Elasticsearch Service, que pode ser encontrado no console Elastic Cloud.