In today's digital landscape, applications are at the heart of both our personal and professional lives. We've grown accustomed to these applications being perpetually available and responsive. This expectation places a significant burden on the shoulders of developers and operations teams.
Site reliability engineers (SREs) face the challenging task of sifting through vast quantities of data, not just from the applications themselves but also from the underlying infrastructure. In addition to data analysis, they are responsible for ensuring the effective use and development of operational tools. The growing volume of data, the daily resolution of issues, and the continuous evolution of tools and processes can detract from the focus on business performance.
Elastic Observability offers a solution to this challenge. It enables SREs to integrate and examine all telemetry data (logs, metrics, traces, and profiling) in conjunction with business metrics. This comprehensive approach to data analysis fosters operational excellence, boosts productivity, and yields critical insights, all of which are integral to maintaining high-performing applications in a demanding digital environment.
To help manage operations and business metrics, Elastic Observability's SLO (Service Level Objectives) feature was introduced in 8.12. This feature enables setting measurable performance targets for services, such as availability, latency, traffic, errors, and saturation or define your own. Key components include:
-
Defining and monitoring SLIs (Service Level Indicators)
-
Monitoring error budgets indicating permissible performance shortfalls
-
Alerting on burn rates showing error budget consumption
Users can monitor SLOs in real-time with dashboards, track historical performance, and receive alerts for potential issues. Additionally, SLO dashboard panels offer customized visualizations.
Service Level Objectives (SLOs) are generally available for our Platinum and Enterprise subscription customers.
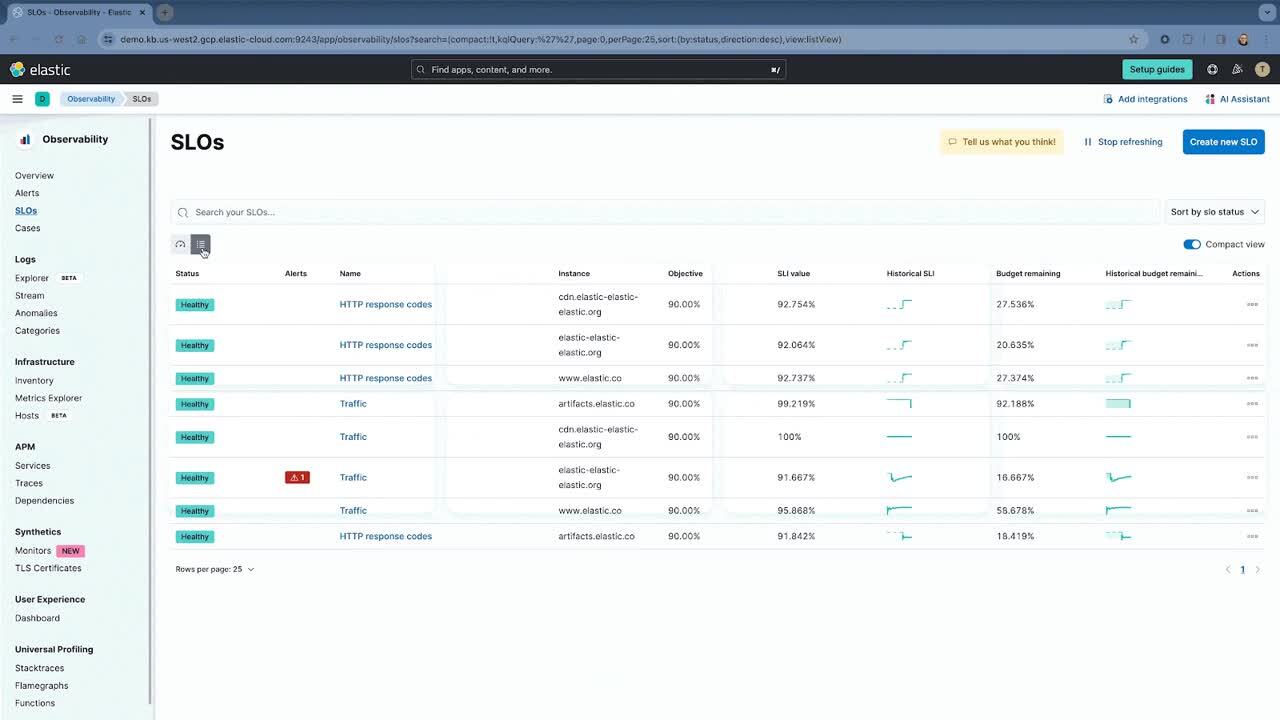
In this blog, we will outline the following:
-
What are SLOs? A Google SRE perspective
-
Several scenarios of defining and managing SLOs
Service Level Objective overview
Service Level Objectives (SLOs) are a crucial component for Site Reliability Engineering (SRE), as detailed in Google's SRE Handbook. They provide a framework for quantifying and managing the reliability of a service. The key elements of SLOs include:
-
Service Level Indicators (SLIs): These are carefully selected metrics, such as uptime, latency, throughput, error rates, or other important metrics, that represent the aspects of the service and are important from an operations or business perspective. Hence, an SLI is a measure of the service level provided (latency, uptime, etc.), and it is defined as a ratio of good over total events, with a range between 0% and 100%.
-
Service Level Objective (SLO): An SLO is the target value for a service level measured as a percentage by an SLI. Above the threshold, the service is compliant. As an example, if we want to use service availability as an SLI, with the number of successful responses at 99.9%, then any time the number of failed responses is > .1%, the SLO will be out of compliance.
-
Error budget: This represents the threshold of acceptable errors, balancing the need for reliability with practical limits. It is defined as 100% minus the SLO quantity of errors that is tolerated.
-
Burn rate: This concept relates to how quickly the service is consuming its error budget, which is the acceptable threshold for unreliability agreed upon by the service providers and its users.
Understanding these concepts and effectively implementing them is essential for maintaining a balance between innovation and reliability in service delivery. For more detailed information, you can refer to Google's SRE Handbook.
One main thing to remember is that SLO monitoring is not incident monitoring. SLO monitoring is a proactive, strategic approach designed to ensure that services meet established performance standards and user expectations. It involves tracking Service Level Objectives, error budgets, and the overall reliability of a service over time. This predictive method helps in preventing issues that could impact users and aligns service performance with business objectives.
In contrast, incident monitoring is a reactive process focused on detecting, responding to, and mitigating service incidents as they occur. It aims to address unexpected disruptions or failures in real time, minimizing downtime and impact on service. This includes monitoring system health, errors, and response times during incidents, with a focus on rapid response to minimize disruption and preserve the service's reputation.
Elastic®’s SLO capability is based directly off the Google SRE Handbook. All the definitions and semantics are utilized as described in Google’s SRE handbook. Hence users can perform the following on SLOs in Elastic:
-
Define an SLO on an SLI such as KQL (log based query), service availability, service latency, custom metric, histogram metric, or a timeslice metric. Additionally, set the appropriate threshold.
-
Utilize occurrence versus time slice based budgeting. Occurrences is the number of good events over the number of total events to compute the SLO. Timeslices break the overall time window into slammer slices of a defined duration and compute the number of good slices over the total slices to compute the SLO. Timeslice targets are more accurate and useful when calculating things like a service’s SLO when trying to meet agreed upon customer targets.
-
Manage all the SLOs in a singular location.
-
Trigger alerts from the defined SLO, whether the SLI is off, burn rate is used up, or the error rate is X.
-
Create unique service level dashboards with SLO information for a more comprehensive view of the service.
SREs need to be able to manage business metrics.
SLOs based on logs: NGINX availability
Defining SLOs does not always mean metrics need to be used. Logs are a rich form of information, even when they have metrics embedded in them. Hence it’s useful to understand your business and operations status based on logs.
Elastic allows you to create an SLO based on specific fields in the log message, which don’t have to be metrics. A simple example is a simple multi-tier app that has a web server layer (nginx), a processing layer, and a database layer.
Let’s say that your processing layer is managing a significant number of requests. You want to ensure that the service is up properly. The best way is to ensure that all http.response.status_code are less than 500. Anything less ensures the service is up and any errors (like 404) are all user or client errors versus server errors.
If we use Discover in Elastic, we see that there are close to 2M log messages over a seven-day time frame.
Additionally, the number of messages with http.response.status_code > 500 is minimal, like 17K.
Rather than creating an alert, we can create an SLO with this query:
We chose to use occurrences as the budgeting method to keep things simple.
Once defined, we can see how well our SLO is performing over a seven-day time frame. We can see not only the SLO, but also the burn rate, the historical SLI, and error budget, and any specific alerts against the SLO.
Not only do we get information about the violation, but we also get:
-
Historical SLI (7 days)
-
Error budget burn down
-
Good vs. bad events (24 hours)
We can see how we’ve easily burned through our error budget.
Hence something must be going on with nginx. To investigate, all we need to do is utilize the AI Assistant, and use its natural language interface to ask questions to help analyze the situation.
Let’s use Elastic’s AI Assistant to analyze the breakdown of http.response.status_code across all the logs from the past seven days. This helps us understand how many 50X errors we are getting.
As we can see, the number of 502s is minimal compared to the number of overall messages, but it is affecting our SLO.
However, it seems like Nginx is having an issue. In order to reduce the issue, we also ask the AI Assistant how to work on this error. Specifically, we ask if there is an internal runbook the SRE team has created.
AI Assistant gets a runbook the team has added to its knowledge base. I can now analyze and try to resolve or reduce the issue with nginx.
While this is a simple example, there are an endless number of possibilities that can be defined based on KQL. Some other simple examples:
-
99% of requests occur under 200ms
-
99% of log message are not errors
Application SLOs: OpenTelemetry demo cartservice
A common application developers and SREs use to learn about OpenTelemetry and test out Observability features is the OpenTelemetry demo.
This demo has feature flags to simulate issues. With Elastic’s alerting and SLO capability, you can also determine how well the entire application is performing and how well your customer experience is holding up when these feature flags are used.
Elastic supports OpenTelemetry by taking OTLP directly with no need for an Elastic specific agent. You can send in OpenTelemetry data directly from the application (through OTel libraries) and through the collector.
We’ve brought up the OpenTelemetry demo on a K8S cluster (AWS EKS) and turned on the cartservice feature flag. This inserts errors into the cartservice. We’ve also created two SLOs to monitor the cartservice’s availability and latency.
We can see that the cartservice’s availability is violated. As we drill down, we see that there aren’t as many successful transactions, which is affecting the SLO.
As we drill into the service, we can see in Elastic APM that there is a higher than normal failure rate of about 5.5% for the emptyCart service.
We can investigate this further in APM, but that is a discussion for another blog. Stay tuned to see how we can use Elastic’s machine learning, AIOps, and AI Assistant to understand the issue.
Conclusion
SLOs allow you to set clear, measurable targets for your service performance, based on factors like availability, response times, error rates, and other key metrics. Hopefully with the overview we’ve provided in this blog, you can see that:
-
SLOs can be based on logs. In Elastic, you can use KQL to essentially find and filter on specific logs and log fields to monitor and trigger SLOs.
-
AI Assistant is a valuable, easy-to-use capability to analyze, troubleshoot, and even potentially resolve SLO issues.
-
APM Service based SLOs are easy to create and manage with integration to Elastic APM. We also use OTel telemetry to help monitor SLOs.
For more information on SLOs in Elastic, check out Elastic documentation and the following resources:
Ready to get started? Sign up for Elastic Cloud and try out the features and capabilities I’ve outlined above to get the most value and visibility out of your SLOs.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.