Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
Being a central component of data flow between producers and consumers, it often happens that a single Logstash is responsible for driving multiple parallel streams of events. The existence of these multiple isolated flows pose a few challenges for Logstash, since historically, each individual instance has supported a single pipeline, composed of an input, a filter, and an output stage.
Users have found ways of implementing multiple isolated flows in a single pipeline, mainly through conditionals: tagging events early on in the input section and then creating conditional branches through the filters and outputs, applying different sets of plugins to different tags or event values. This is a very common solution we often see in the community, but there are several pains users feel when implementing it:
Conditional hell
While implementing isolated multiple flows using conditionals works, it's easy to see how the existence of a single pipeline and single stages of processing makes the configuration extremely verbose and hard to manage as complexity increases.
For a simple pipeline that houses two flows:
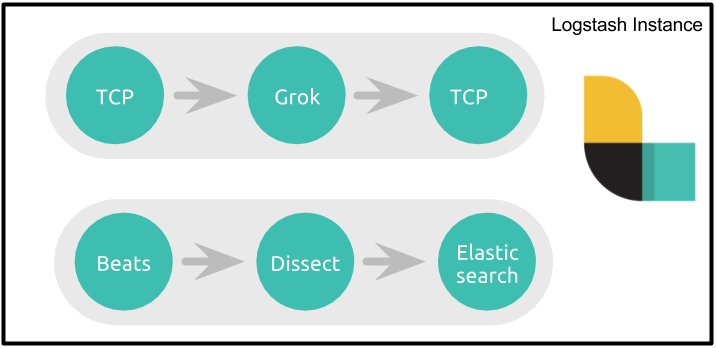
The corresponding Logstash pipeline configuration is already riddled with primitives (marked in bold) whose only purpose is to keep the flows separate:
input {
beats { port => 3444 tag => apache }
tcp { port => 4222 tag => firewall }
}
filter {
if "apache" in [tags] {
dissect { ... }
} else if "firewall" in [tags] {
grok { ... }
}
}
output {
if "apache" in [tags] {
elasticsearch { ... }
} else if "firewall" in [tags] {
tcp { ... }
}
}
Unfortunately, this is not the only issue with this solution..
Lack of congestion isolation
If you're familiar with how Logstash works, you know that the output section of the pipeline receives a batch of event and will not move to the next batch until all events and gone through all of the outputs. This means that, for the pipeline above, if the TCP socket destination isn't reachable, Logstash won't process other batches of events, which in turn means that Elasticsearch won't receive events, and back pressure will be applied to both the TCP input and the Beats input.
Different flows have different needs
If the TCP-> Grok -> TCP data flow handles a very high volume of small messages and the Beats -> Dissect -> ES flow has large documents with less events per second, then it would be ideal to have the former flow with many workers and bigger batches, and the latter with less workers and smaller batches.
With a single pipeline, the Filters+Output section will have a single set of parameters, and will process batches mixed with events from both flows.
Also, if you're using configuration reloading, changing a grok pattern for the first flow will stop Beats from receiving data and sending to Elasticsearch.
The current solution: Multiple Logstash Instances
The problems described above can be solved by having multiple Logstash instances in the same machine, which can then be managed independently, but even this solution creates other problems:
- The RPM/DEB packages (namely the init scripts) aren't meant to handle multiple instances of Logstash
- Each new instance of Logstash also means a whole new JVM instance too
- Monitoring multiple instances of Logstash is more complex, requiring the monitoring solution to ping multiple APIs, one for each instance.
We're proud to announce that the solution to all of these issues will arrive in the upcoming Logstash 6.0, with the new Multiple Pipelines feature!
Multiple Pipelines
Multiple pipelines is the ability to execute, in a single instance of Logstash, one or more pipelines, by reading their definitions from a configuration file called `pipelines.yml`.
This file lives in your configuration folder and looks something like this:
- pipeline.id: apache
pipeline.batch.size: 125
queue.type: persisted
path.config: "/path/to/config/apache.cfg"
queue.page_capacity: 50mb
- pipeline.id: test
pipeline.batch.size: 2
pipeline.batch.delay: 1
queue.type: memory
config.string: "input { tcp { port => 3333 } } output { stdout {} }"
This YAML file contains a list of hashes (or dictionaries), where each one represents a pipeline, and the keys and values are setting names for that pipeline. The values of settings which are omitted fall back to their default values (configurable in the already familiar `logstash.yml`), and only pipeline specific settings can be configured (i.e. setting `node.id` will throw an error).
Launching Logstash with Multiple Pipelines
By default, if Logstash is started with neither `-e` or `-f` (or their equivalents in `logstash.yml`), it will read the `pipelines.yml` file and start those pipelines. Using either of these flags causes the `pipelines.yml` to be ignored.
Reloading is also fully supported in Multiple Pipelines. If started with `-r` or if `config.reload.automatic` is set to true, the `pipelines.yml` is periodically read and individual pipelines can be reloaded, added or removed. Changes to the `path.config` files of individual pipelines will also cause those to be reloaded.
This means that our initial example can now be implemented using multiple pipelines:
- pipeline.id: apache
path.config: "/path/to/config/apache.cfg"
- pipeline.id: firewall
path.config: "/path/to/config/firewall.cfg"
And the individual configuration files without the conditional hell:
# apache.cfg
input { beats { port => 3444 } }
filter { dissect { ... } }
output { elasticsearch { ... } }
# firewall.cfg
input { tcp { port => 4222 } }
filter { grok { ... } }
output { tcp { ... } }
You can find documentation on the Multiple Pipelines feature here.
What else?
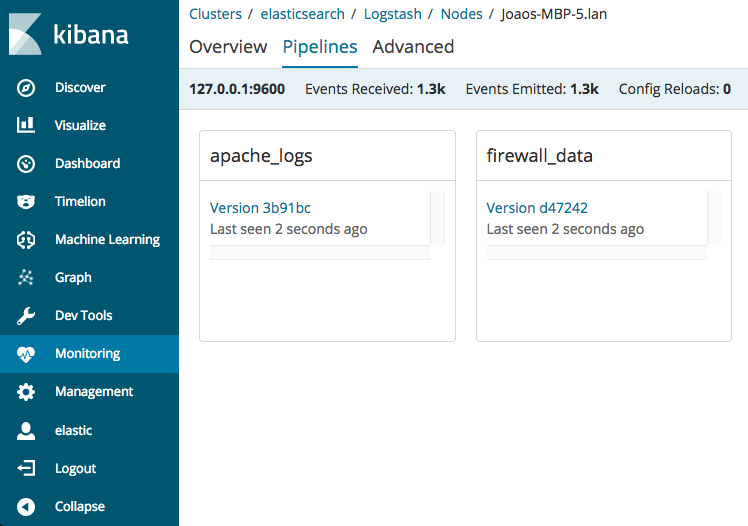
If you're using X-Pack, Monitoring will support the Multiple Pipelines out of the box:
Conclusion
We truly hope this feature makes the lives of our many users just a little bit easier. Multiple pipelines allows you to get more out of a single Logstash instance, giving you the flexibility to process separate event flows without having to work around the constraint of a single pipeline.
If you're interested in helping testing this feature before 6.0 is out, you can become an Elastic Pioneer -- all you need to do is try out the latest preview release and give us feedback for an opportunity to win some sweet Elastic swag!