Elasticsearch Freeze index API로 고정 인덱스 생성
먼저, 몇 가지 배경 설명
Hot-Warm 아키텍처는 하드웨어를 최대한 활용하고자 할 때 자주 사용됩니다. 이는 로그, 메트릭 및 APM 데이터와 같이 시간 기반 데이터가 있는 경우 특히 유용합니다. 이러한 설정 대부분은 해당 데이터가 읽기 전용이며(수집 후) 인덱스가 시간(또는 크기) 기반일 수 있다는 점을 활용합니다. 따라서 원하는 보존 기간에 따라 쉽게 삭제할 수 있습니다. 이 아키텍처에서는 Elasticsearch 노드를 ‘hot’과 ‘warm’이라는 두 가지 유형으로 분류합니다.
Hot 노드는 가장 최신 데이터를 저장하므로 모든 색인 로드를 처리합니다. 최신 데이터는 대개 쿼리 빈도가 가장 높기 때문에 이러한 노드가 클러스터에서 가장 강력한 노드입니다. 즉, 빠른 스토리지, 고용량 메모리 및 CPU가 탑재됩니다. 하지만 추가 성능에는 많은 비용이 듭니다. 따라서 쿼리 빈도가 낮은 오래된 데이터를 hot 노드에 저장하는 것은 타당하지 않습니다.
반면에 warm 노드는 더 비용 효율적인 방법으로 장기 저장 공간 전용으로 사용할 수 있는 노드입니다. Warm 노드의 데이터는 쿼리 빈도가 높지 않으며, 클러스터 내 데이터는 쿼리를 위해 계속 온라인 상태를 유지하면서 계획된 보존 기간(샤드 할당 필터링을 통해 달성됨)에 따라 hot 노드에서 warm 노드로 이동하게 됩니다.
Elastic Stack 6.3을 시작으로, Elastic에서는 hot-warm 아키텍처를 개선하고 시간 기반 데이터 작업을 간소화할 수 있는 새로운 기능을 구축하고 있습니다.
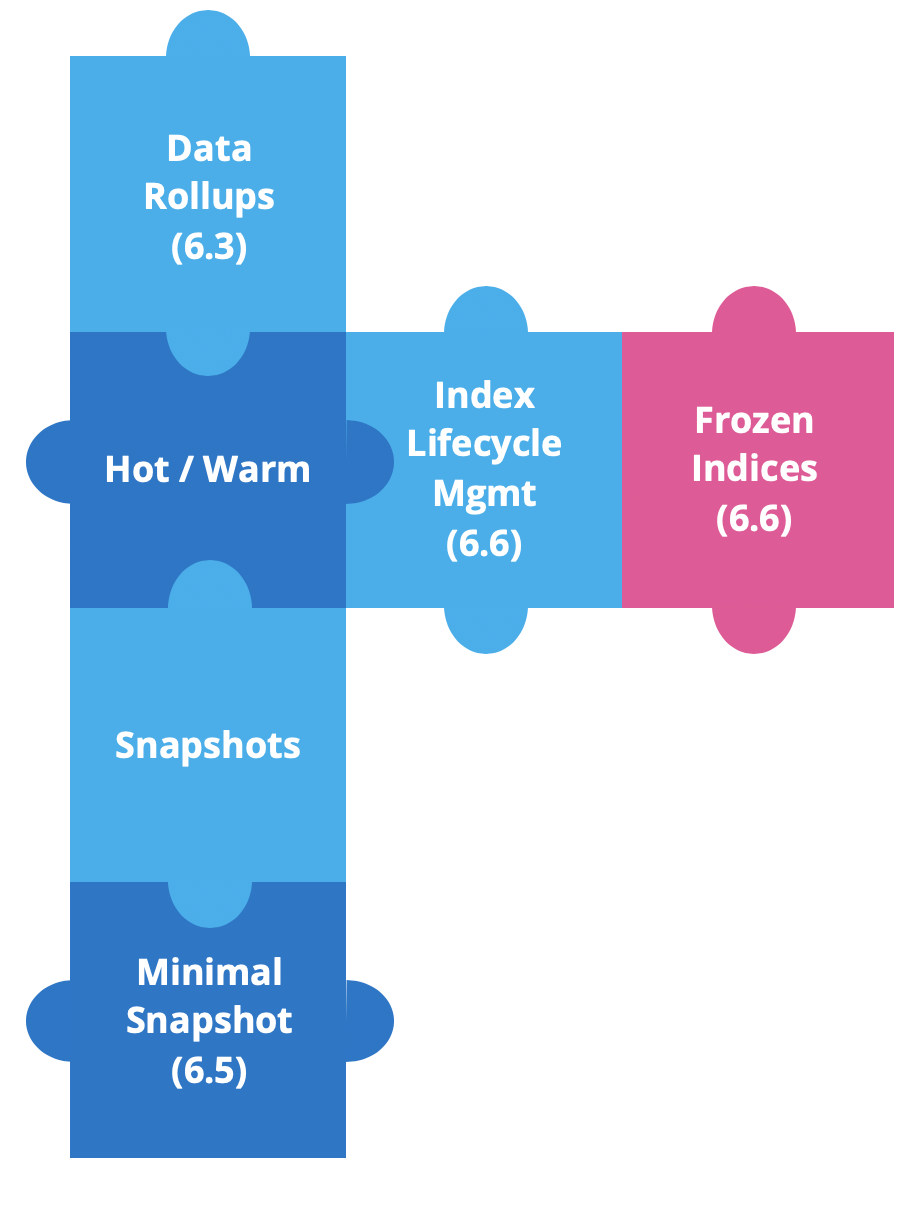
저장 공간을 절약하기 위해 데이터 롤업이 버전 6.3에 처음 도입되었습니다. 시계열 데이터의 경우에는 가장 최신 데이터에 대한 세분화된 정보가 필요합니다. 그러나 기존 데이터에도 같은 방식이 필요할 가능성은 거의 없습니다. 일반적으로 기존 데이터는 전체적인 데이터 세트로 살펴보게 됩니다. 바로 롤업이 적합한 경우입니다. 버전 6.5부터는 Kibana에서 롤업 데이터를 생성, 관리 및 시각화할 수 있습니다.
얼마 후 Elastic에서는 소스 전용 스냅샷을 추가했습니다. 이 최소 스냅샷을 사용하면 스냅샷 저장 공간이 대폭 절약되지만, 복원 및 쿼리 작업을 원하는 경우 데이터를 다시 색인해야 합니다. 이 기능은 버전 6.5부터 사용할 수 있습니다.
버전 6.6에서는 인덱스 수명 주기 관리(ILM)와 고정 인덱스라는 두 가지 강력한 기능을 출시했습니다.
ILM은 시간 경과에 따른 인덱스 관리를 자동화할 수 있는 수단을 제공합니다. 인덱스를 hot에서 warm으로 간편하게 옮기거나, 인덱스가 너무 오래된 경우 삭제하거나, 여러 인덱스를 하나의 세그먼트로 강제 병합하는 작업을 자동화합니다.
그리고 이 블로그의 나머지 부분에서는 고정 인덱스에 대해 설명하겠습니다.
인덱스를 고정하는 이유는?
‘오래된’ 데이터의 가장 큰 문제점 중 하나는 그 기간과 관계없이 인덱스가 여전히 메모리에서 상당한 공간을 차지하고 있다는 것입니다. 데이터를 cold 노드에 배치해도 여전히 힙을 사용합니다.
가능한 해결책은 인덱스를 종료하는 것입니다. 인덱스를 종료하면 메모리를 소비하지 않지만, 검색을 실행하려면 인덱스를 다시 열어야 합니다. 인덱스를 다시 열려면 운영 비용이 발생하며 종료되기 전에 사용하던 힙도 필요합니다.
각 노드에는 노드당 저장 공간의 양을 제한하는 메모리(힙) 대 저장 공간 비율이 있습니다. 이 비율은 메모리 집약적 시나리오의 경우는 최소 1:8(메모리:데이터)에서 메모리 요구 사항이 적은 사용 사례에서는 거의 1:100까지 다양합니다.
바로 고정 인덱스가 필요한 부분입니다. 인덱스를 계속 열어 두어 검색 가능하게 유지하면서 힙을 차지하지 않게 할 수 있다면 어떨까요? 고정 인덱스를 보존할 저장 공간을 데이터 노드에 추가하고 1:100 비율을 바꿀 수 있습니다. 이때 검색 속도가 느려질 수 있다는 상충 관계를 이해해야 합니다.
인덱스를 고정하면 읽기 전용이 되고 해당 임시 데이터 구조는 메모리에서 삭제됩니다. 그 결과, 고정 인덱스에 대한 쿼리를 실행하는 경우 데이터 구조를 메모리에 로드해야 합니다. 고정 인덱스를 검색하는 속도가 느릴 필요는 없습니다. Lucene은 인덱스 상당 부분을 메모리에 보관하기에 충분한 용량을 가진 파일 시스템 캐시에 크게 의존합니다. 이러한 경우 검색은 샤드당 속도와 비슷합니다. 하지만 노드당 하나의 고정 샤드만 동시에 실행되므로 고정 인덱스는 여전히 스로틀됩니다. 이로 인해 고정되지 않은 인덱스와 비교하여 검색 속도가 느려질 수 있습니다.
고정 작동 방식
고정 인덱스는 전용 search_throttled 스레드 풀을 통해 검색됩니다. 여기에서는 고정 인덱스가 한 번에 하나씩 메모리로 로드되도록 하기 위해 기본적으로 단일 스레드를 사용합니다. 동시 검색이 수행되는 경우, 노드의 메모리가 부족해지는 것을 방지하기 위해 대기열에 올려 추가적인 보호 조치를 취합니다.
따라서 hot-warm 아키텍처에서는 인덱스를 hot에서 warm으로 전환한 다음 아카이빙 또는 삭제하기 전에 인덱스를 고정할 수 있으므로 하드웨어 요구 사항을 줄일 수 있습니다.
고정 인덱스가 도입되기 전에는 인프라 비용을 낮추려면 데이터의 스냅샷을 생성하고 아카이빙해야 했습니다. 이 경우 상당한 운영 비용이 추가됩니다. 또한, 다시 검색해야 하는 경우 데이터를 복원해야 합니다. 이제 상당한 메모리 오버헤드 없이도 기존 데이터를 검색 가능하도록 유지할 수 있습니다. 이미 고정된 인덱스에 다시 써야 한다면, 고정을 해제하면 됩니다.

Elasticsearch 인덱스를 고정하는 방법
고정 인덱스는 클러스터에 쉽게 구현할 수 있습니다. 그러면 Freeze index API를 사용하는 방법과 고정 인덱스를 검색하는 방법을 살펴보겠습니다.
먼저, 테스트 인덱스에 샘플 데이터를 작성하는 것으로 시작합니다.
POST /sampledata/_doc
{
"name": "Jane",
"lastname": "Doe"
}
POST /sampledata/_doc
{
"name": "John",
"lastname": "Doe"
}
그런 다음 데이터가 수집되었는지 확인합니다. 이렇게 하면 2개의 결과가 반환됩니다.
GET /sampledata/_search
모범 사례로서, 인덱스를 고정하기 전에 먼저 force_merge를 실행하는 것이 좋습니다. 그러면 샤드별로 디스크에 하나의 세그먼트만 있게 됩니다. 또한, 압축률이 훨씬 향상되고, 고정 인덱스에 대해 집계 또는 정렬된 검색 요청을 실행할 때 필요한 데이터 구조가 간소화됩니다. 여러 세그먼트가 있는 고정 인덱스에 대한 검색을 실행하면 최대 수백 배의 성능 오버헤드가 발생할 수 있습니다.
POST /sampledata/_forcemerge?max_num_segments=1
다음 단계는 Freeze index API 엔드포인트를 통해 인덱스 고정을 호출하는 것입니다.
POST /sampledata/_freeze
고정 인덱스 검색
이제 인덱스가 고정되었기 때문에 일반적인 검색은 작동하지 않는다는 것을 알 수 있습니다. 노드당 메모리 소비를 제한하기 위해 고정 인덱스가 스로틀되기 때문입니다. 실수로 고정 인덱스를 대상으로 할 수 있으므로, 요청에 ignore_throttled=false를 추가하여 실수로 인한 속도 저하를 방지하겠습니다.
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
이제 다음 요청을 실행하여 새로운 인덱스의 상태를 확인할 수 있습니다.
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
이렇게 하면 인덱스 상태가 ‘open’인 다음과 비슷한 결과가 반환됩니다.
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
위에서 언급했듯이 클러스터의 메모리가 부족하지 않도록 보호해야 하므로, 노드 검색을 위해 동시에 로드할 수 있는 고정 인덱스 수에는 제한이 있습니다. search_throttled 스레드 풀의 스레드 수는 기본적으로 1이며 기본 대기열은 100입니다. 즉, 둘 이상의 요청을 실행하면 최대 100개까지 대기열에 올라갑니다. 다음 요청을 사용해 스레드 풀 상태를 모니터링하여 대기열과 거부 상태를 확인할 수 있습니다.
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
다음과 유사한 응답이 반환됩니다.
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
고정 인덱스는 조금 더 느릴 수 있지만, 매우 효율적인 방식으로 사전에 필터링할 수 있습니다. 또한, 요청 파라미터 pre_filter_shard_size를 1로 설정하는 것이 좋습니다.
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
이렇게 하면 쿼리에 큰 오버헤드가 추가되지 않고 일반적인 시나리오를 활용할 수 있습니다. 예를 들어 시계열 인덱스에서 날짜 범위를 검색할 때 모든 샤드가 일치하지는 않습니다.
고정된 Elasticsearch 인덱스에 쓰는 방법
이미 고정된 인덱스에 쓰려고 하면 어떻게 될까요? 직접 알아보겠습니다.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
어떻게 되었나요? 고정 인덱스는 읽기 전용이므로 쓰기가 차단됩니다. 인덱스 설정에서 이를 확인할 수 있습니다.
GET /sampledata/_settings?flat_settings=true
다음과 같이 반환됩니다.
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
Unfreeze index API를 사용하여 인덱스에서 고정 해제 엔드포인트를 호출해야 합니다.
POST /sampledata/_unfreeze
이제 세 번째 문서를 생성하고 검색할 수 있습니다.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
고정 해제는 예외적인 상황에서만 수행되어야 합니다. 그리고 최적의 성능을 보장하려면 인덱스를 다시 고정하기 전에 항상 ‘force_merge’를 실행해야 합니다.
Kibana에서 고정 인덱스 사용
시작하려면 sample flight data와 같은 샘플 데이터를 로드해야 합니다.
Sample flight data에서 [Add] 버튼을 클릭합니다.
이제 [View data] 버튼을 클릭하면 로드된 데이터가 표시됩니다. 대시보드는 다음과 비슷한 형태입니다.
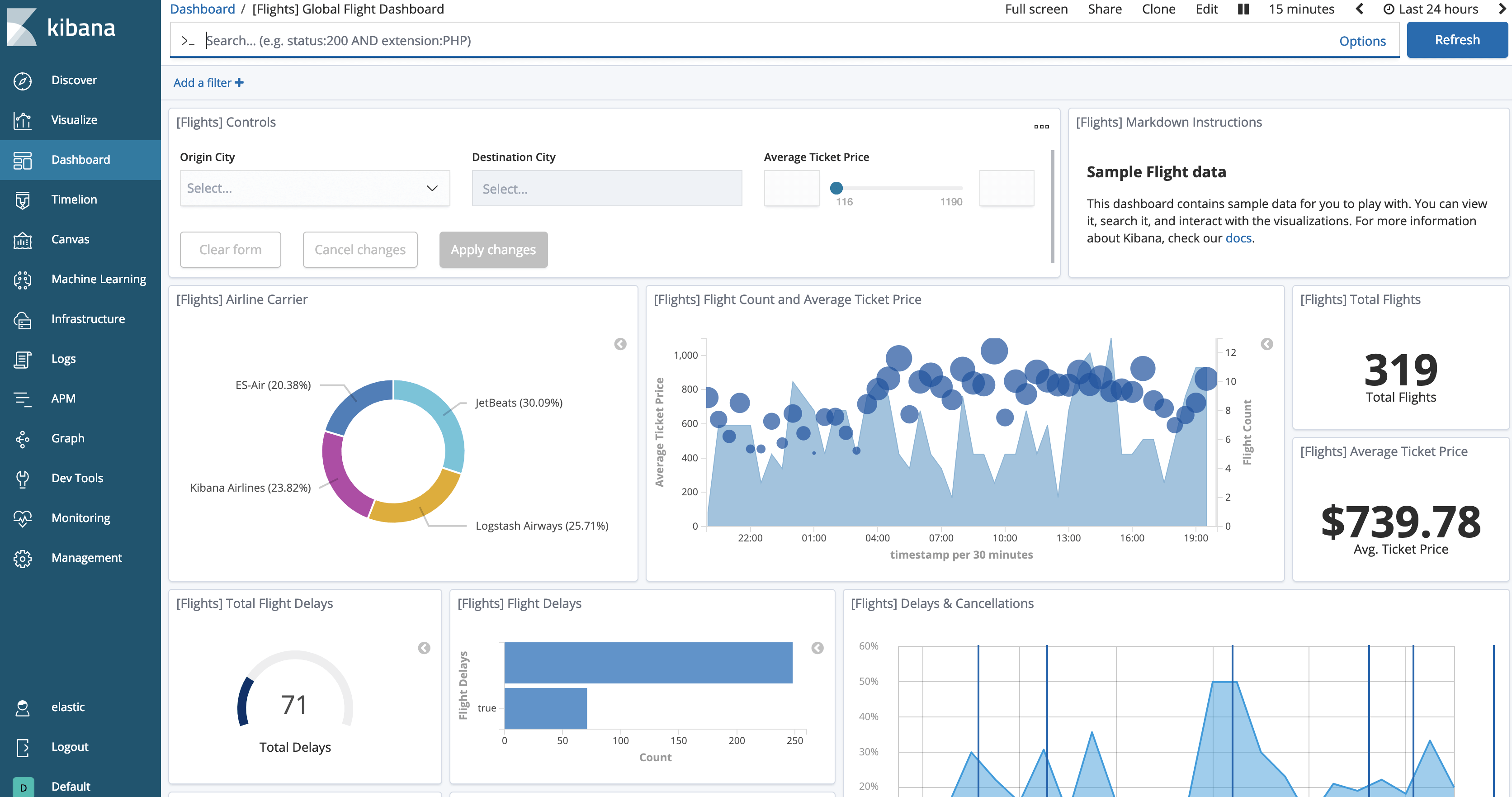
이제 인덱스 고정을 테스트할 수 있습니다.
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
대시보드로 돌아가면 데이터가 ‘사라진’ 것을 알 수 있습니다.
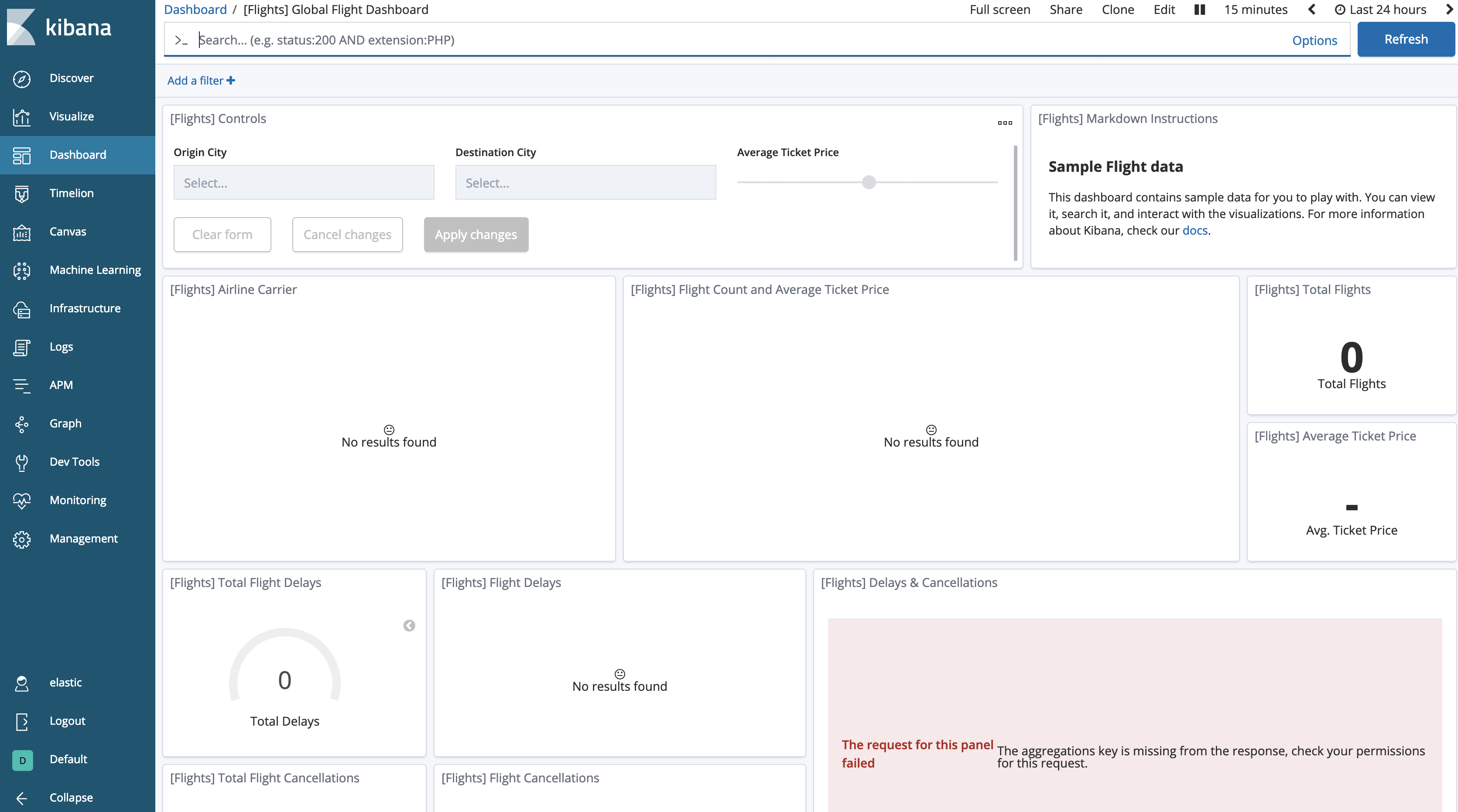
고정 인덱스에 대한 검색은 기본적으로 비활성화되어 있으므로 이를 허용하도록 Kibana에 알려야 합니다.
Kibana Management로 이동하여 [Advanced Settings]를 선택합니다. [Search] 섹션에서 [Search in frozen indices]가 비활성화된 것이 보일 것입니다. 토글키로 활성화한 후 변경 사항을 저장합니다.

그러면 항공편 대시보드에 데이터가 다시 표시됩니다.
결론
고정 인덱스는 hot-warm 아키텍처에서 매우 강력한 도구입니다. 온라인 검색을 유지하면서 보존 기간을 늘릴 수 있는 비용 효율적인 솔루션을 지원합니다. 자사의 하드웨어 및 데이터로 검색 지연 시간을 테스트하여 고정 인덱스의 적절한 규모 및 검색 지연 시간을 정하는 것이 좋습니다.
Freeze index API에 대한 자세한 내용은 Elasticsearch 설명서를 확인하세요. 언제나처럼 질문이 있으시면 토론 포럼에 글을 남겨 주세요. 고정 기능을 유용하게 활용하시길 바랍니다!