Confluence Cloud connector package
editConfluence Cloud connector package
editIf you do not need the flexibility provided by a connector package, you may prefer the Confluence Cloud connector included with your Elastic deployment.
The connector framework is a tech preview feature. Tech preview features are subject to change and are not covered by the support SLA of generally available (GA) features. Elastic plans to promote this feature to GA in a future release.
Enterprise Search versions 7.15.0 and later are required to connect to Confluence Cloud. This is due to backwards incompatible API changes introduced by Atlassian, the developer of Confluence Cloud.
Additionally, the following patch versions of Enterprise Search are not compatible with Confluence Cloud: 7.17.2, 8.1.1, and 8.1.2. This is due to additional, backwards incompatible API changes introduced by Atlassian.
Confluence Cloud is a team workspace, where knowledge and collaboration meet. Often used as an organizational wiki and intranet, it usually houses valuable information for staff across multiple areas of businesses, large and small.
Use the Elastic Enterprise Search Confluence Cloud connector package to deploy and run a Confluence Cloud connector on your own infrastructure. After registering your connector package, Workplace Search automatically captures, syncs, and indexes the following items from your Confluence Cloud:
Spaces |
Including ID, Content, Type, and timestamps |
Pages |
Including ID, Content, Type, Comments, Project, Collaborators and timestamps |
Blog Posts |
Including ID, Content, Type, Comments, Project, Collaborators and timestamps |
Attachments |
Including ID, Size, Type, Content, Project, Collaborators and timestamps |
(If your deployment is not syncing as expected, see Known issues.)
Known issues
edit-
Confluence Cloud may require 48 hours to sync new and changed documents to your Workplace Search deployment.
The issue affects Confluence Cloud accounts in particular timezones. Affected accounts do not expose changes to Workplace Search during more frequent syncs.
The delay is caused by an issue in the Confluence Cloud API. Atlassian, the developer of Confluence Cloud, is aware of the issue.
Deploying and running the connector
editVisit the Elastic Enterprise Search connectors repository (8.3 branch). Use the documentation in that repository to deploy and run the connector on your own infrastructure.
During that process you will create an API key.
Record the API key and the deployed connector’s URL. You will need this information in a future step: Entering the connector information within Kibana.
Configuring the Confluence Cloud Connector
editConfiguring the Confluence Cloud connector is the next step prior to connecting the Confluence Cloud service to Workplace Search, and requires that you create an OAuth App from the Confluence Cloud platform. To get started, first log in to Atlassian’s Developer Portal:
Step 1. Click Create, then select OAuth 2.0 integration:
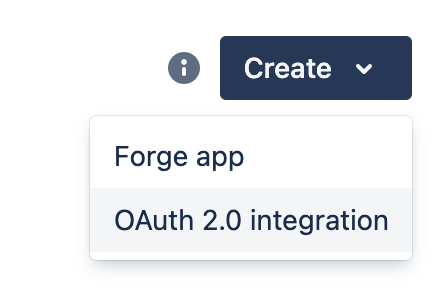
Step 2. Provide a name, agree to the terms, and click Create:
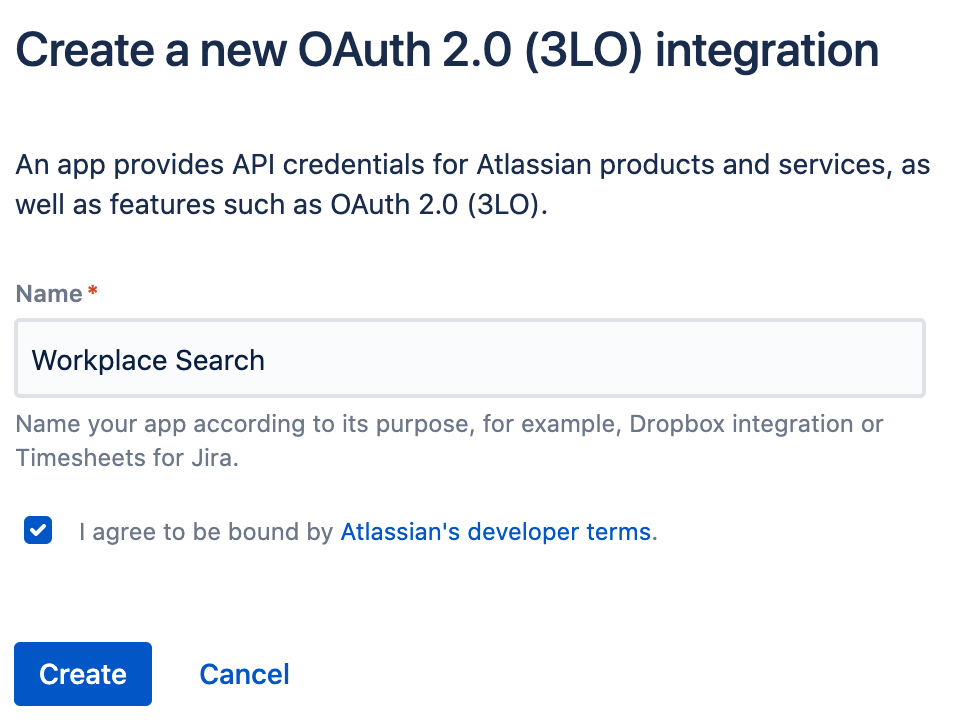
Step 3. Click Settings in the sidebar, add a description and image, and Save changes.
Step 4. Retrieve the application’s Client ID and Client Secret. Keep them handy, we’ll need these in just a few seconds.
Step 5. Create API access and set the right permission level. In the sidebar, click Authorization, locate OAuth 2.0 (3LO), and click Add:
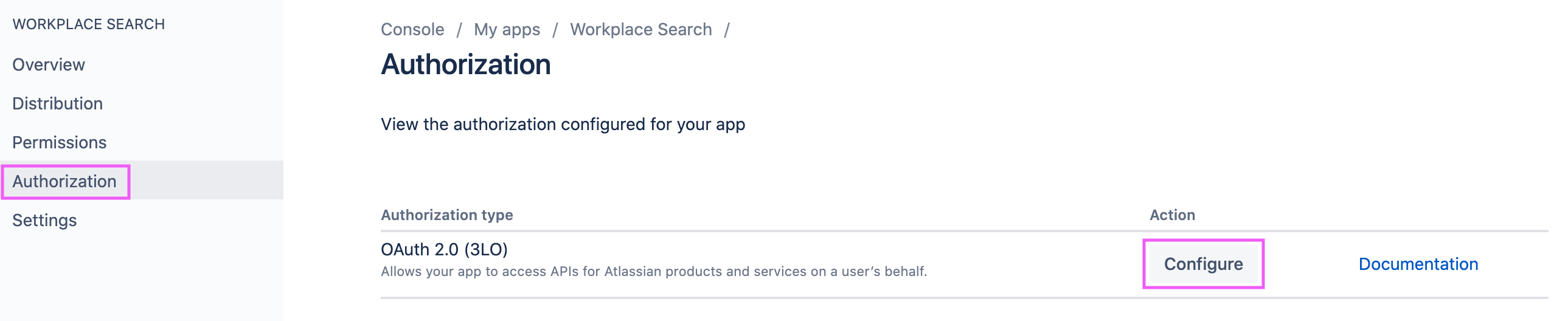
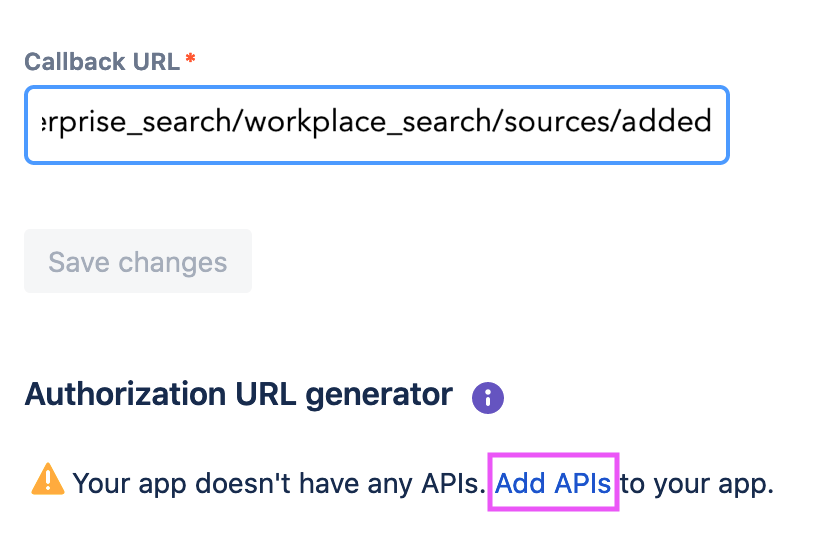
Step 6. Use the Callback URL form to enter the Workplace Search OAuth redirect URL for your deployment.
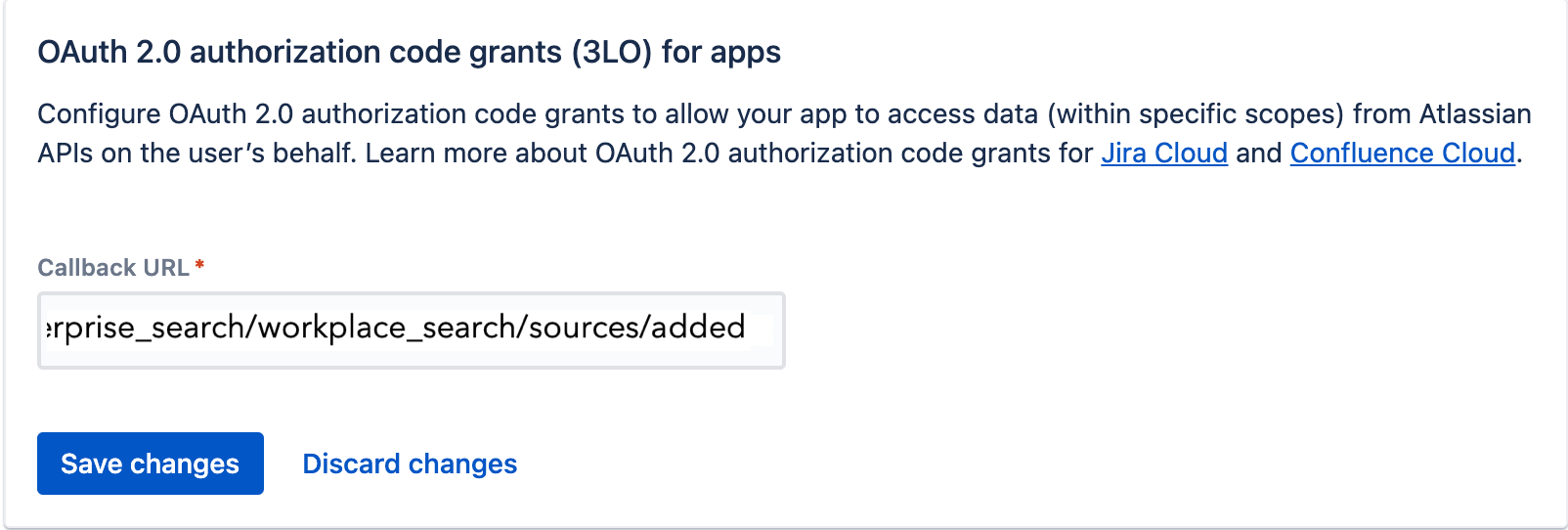
Step 7. A prompt appears. Click the Add APIs hyperlink.
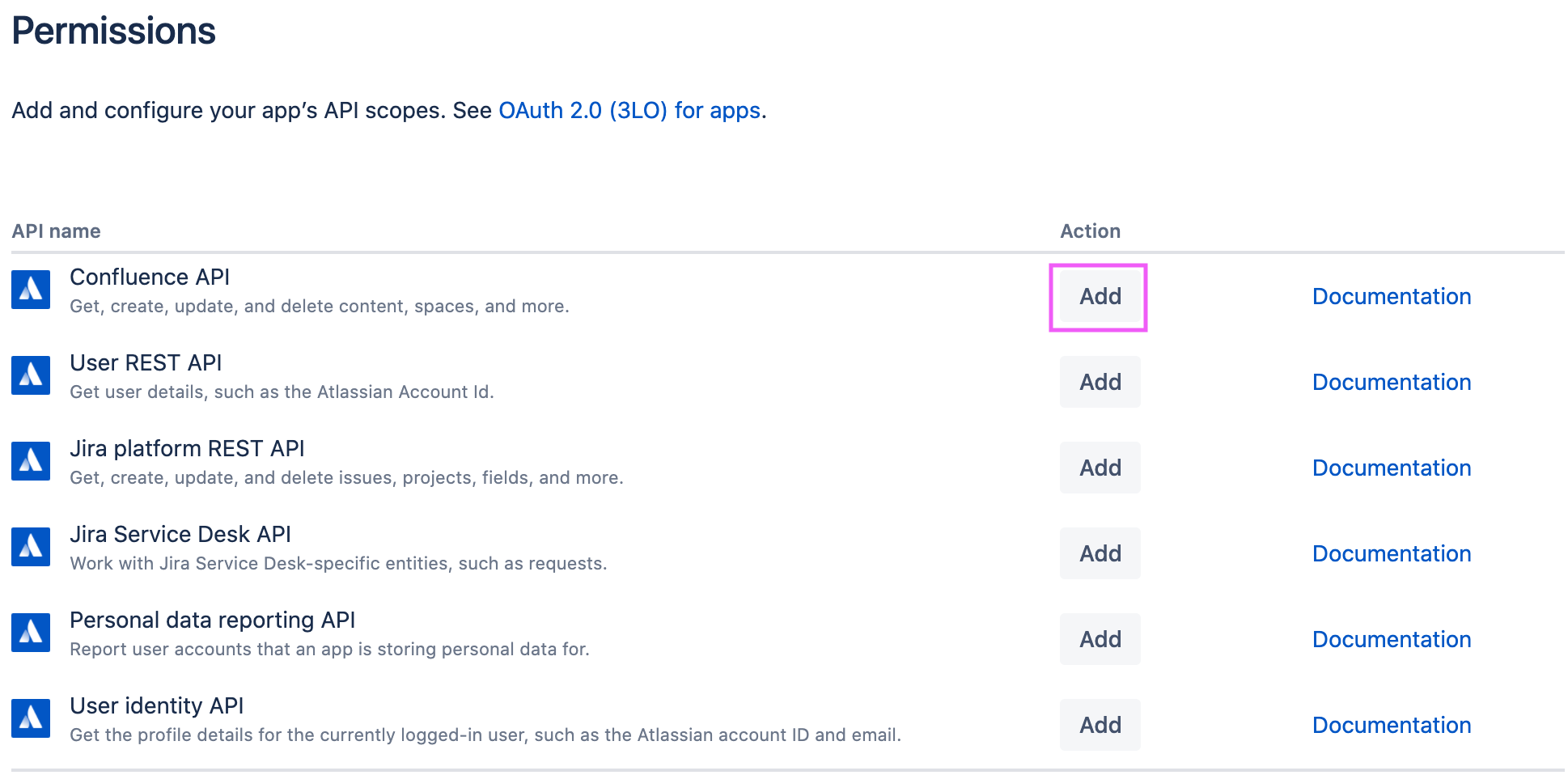
Step 8. Click Permissions, find Confluence API and click Add, then Configure:
Step 9. Enable a series of permissions. Add the following and save:
-
read:confluence-space.summary- Read Confluence space summary -
read:confluence-props- Read Confluence content properties -
read:confluence-content.all- Read Confluence detailed content -
read:confluence-content.summary- Read Confluence content summary -
search:confluence- Search Confluence content and space summaries -
read:confluence-user- Read user -
readonly:content.attachment:confluence- Download content attachments
Step 10. Next, return to Kibana to enter the connector and OAuth client information. From the Workplace Search administrative dashboard’s Sources area, locate Confluence and provide both the Client ID and Client Secret, as well as your Confluence instance Base URL. Do not include a trailing slash:
https://example.atlassian.net
Entering the connector information within Kibana
editIf you started this process within Kibana, return to Kibana to enter the connector and OAuth client information. Alternatively, if you started from this document, open Kibana now.
- Navigate to Enterprise Search → Workplace Search → Sources → Add Source → Confluence Cloud.
- Choose Configure Confluence Cloud.
- Locate Connector Package and choose Instructions.
- Enter the values you previously recorded within the fields Connector URL and Connector API key.
- Choose Save configuration.
Entering the OAuth client information within Kibana
editContinuing from above, you must now enter the OAuth client information within Kibana.
- Enter the values you previously recorded within the fields Client Id and Client secret.
- Choose Save configuration.
The Confluence Cloud connector is now configured, and ready to be used to synchronize content! In order to capture data, you must now connect a Confluence Cloud instance with the adequate authentication credentials.
Connecting Confluence Cloud to Workplace Search
editOnce the Confluence Cloud connector has been configured, you may connect a Confluence Cloud instance to your organization.
Step 1. Head to your organization’s Workplace Search administrative dashboard, and locate the Sources tab.
Step 2. Click Add a new source.
Step 3. Select Confluence Cloud in the Configured Sources list, and follow the Confluence Cloud authentication flow as presented.
Step 4. Upon the successful authentication flow, you will be redirected to Workplace Search.
Confluence Cloud content will now be captured and will be ready for search gradually as it is synced. Once successfully configured and connected, the Confluence Cloud synchronization automatically occurs every 2 hours.
(If your deployment is not syncing as expected, see Known issues.)
Document-level permissions
editYou can synchronize document access permissions from Confluence Cloud to Workplace Search. This will ensure the right people see the right documents.
Synchronized fields
editThe following table lists the fields synchronized from the connected source to Workplace Search. The attributes in the table apply to the default search application, as follows:
- Display name - The label used when displayed in the UI
- Field name - The name of the underlying field attribute
- Faceted filter - whether the field is a faceted filter by default, or can be enabled (see also: Customizing filters)
-
Automatic query refinement preceding phrases - The default list of phrases that must precede a value of this field in a search query in order to automatically trigger query refinement. If "None," a value from this field may trigger refinement regardless of where it is found in the query string. If
'', a value from this field must be the first token(s) in the query string. IfN.A., automatic query refinement is not available for this field by default. All fields that have a faceted filter (defaultorconfigurable) can also be configured for automatic query refinement; see also Update a content source, Get a content source’s automatic query refinement details and Customizing filters.
| Display name | Field name | Faceted filter | Automatic query refinement preceding phrases |
|---|---|---|---|
Id |
|
No |
N.A. |
URL |
|
No |
N.A. |
Title |
|
No |
N.A. |
Type |
|
Default |
None |
Description |
|
No |
N.A. |
Body |
|
No |
N.A. |
Comments |
|
No |
N.A. |
Created by |
|
Default |
[ |
Project |
|
Default |
N.A. |
Created at |
|
No |
N.A. |
Updated at |
|
No |
N.A. |
Last updated |
|
No |
N.A. |
Size |
|
No |
N.A. |
Container |
|
Configurable |
N.A. |
Media type |
|
Configurable |
None |
Extension |
|
Configurable |
None |