Creating anomaly detection jobs
editCreating anomaly detection jobs
editAnomaly detection jobs contain the configuration information and metadata necessary to perform an analytics task.
You can create anomaly detection jobs by using the Create anomaly detection jobs API. Kibana also provides the following wizards to make it easier to create jobs:
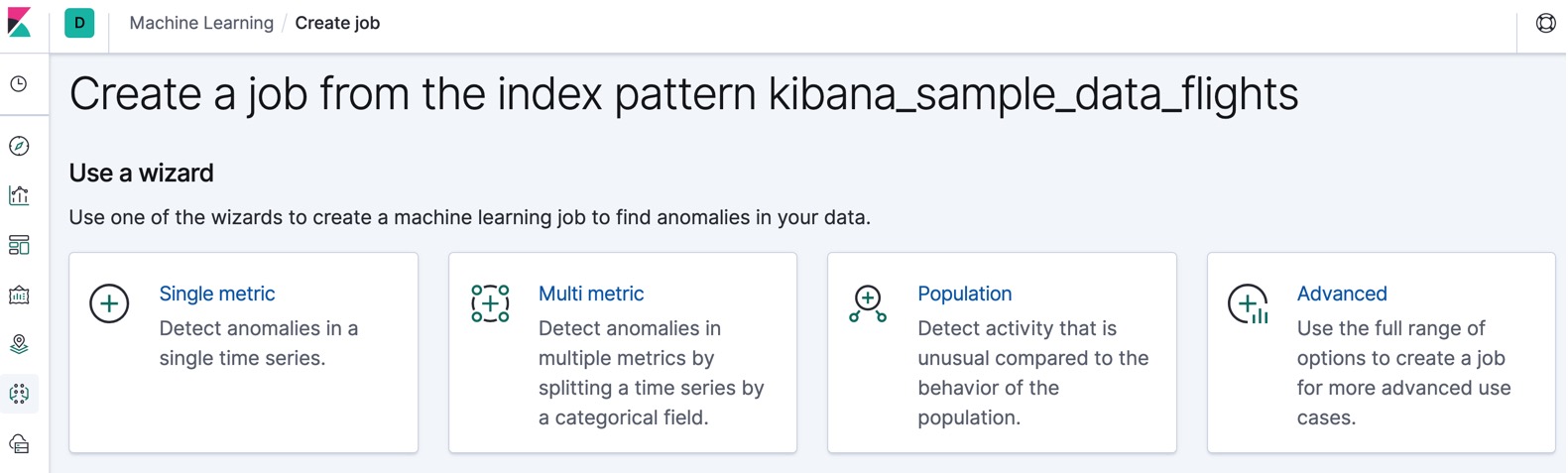
A single metric job is a simple job that contains a single detector. A detector defines the type of analysis that will occur and which fields to analyze. In addition to limiting the number of detectors, the single metric job creation wizard omits many of the more advanced configuration options.
A multi-metric job can contain more than one detector, which is more efficient than running multiple jobs against the same data.
A population job detects activity that is unusual compared to the behavior of the population. For more information, see Performing population analysis.
An advanced job can contain multiple detectors and enables you to configure all job settings.
Kibana can also recognize certain types of data and provide specialized wizards for that context. For example, if you added the sample web log data set, the following wizard appears:

Alternatively, after you load a sample data set on the Kibana home page, you can click View data > ML jobs. There are anomaly detection jobs for both the sample eCommerce orders data set and the sample web logs data set.
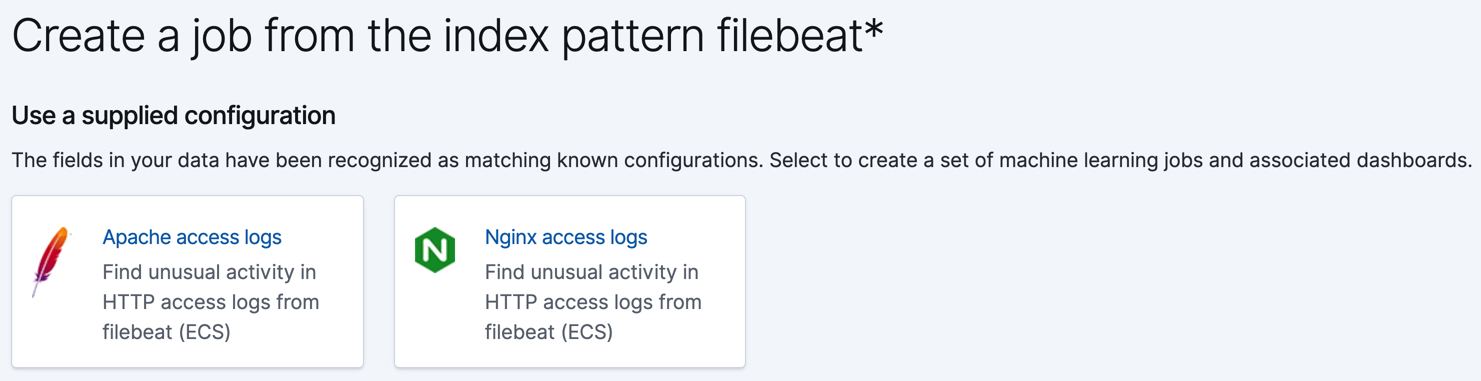
If you use Filebeat to ship access logs from your Nginx and Apache HTTP servers to Elasticsearch and store it using fields and datatypes from the Elastic Common Schema (ECS), the following wizards appear:
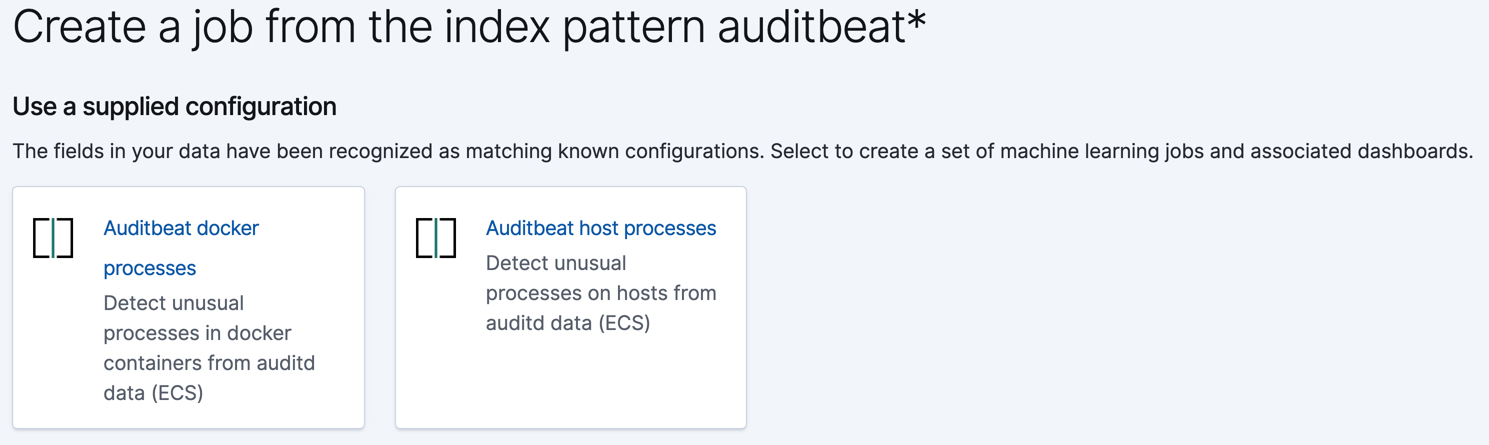
If you use Auditbeat to audit process activity on your systems, the following wizards appear:
Likewise, if you use the Metricbeat system module to monitor your servers, the following wizards appear:

These wizards create anomaly detection jobs, dashboards, searches, and visualizations that are customized to help you analyze your Auditbeat, Filebeat, and Metricbeat data.
If your data is located outside of Elasticsearch, you cannot use Kibana to create your jobs and you cannot use datafeeds to retrieve your data in real time. Anomaly detection is still possible, however, by using APIs to create and manage jobs and post data to them. For more information, see Machine learning anomaly detection APIs.
Machine learning job tips
editWhen you create an anomaly detection job in Kibana, the job creation wizards can provide advice based on the characteristics of your data. By heeding these suggestions, you can create jobs that are more likely to produce insightful machine learning results.
Bucket span
editThe bucket span is the time interval that machine learning analytics use to summarize and model data for your job. When you create an anomaly detection job in Kibana, you can choose to estimate a bucket span value based on your data characteristics.
The bucket span must contain a valid time interval. For more information, see Analysis configuration objects.
If you choose a value that is larger than one day or is significantly different than the estimated value, you receive an informational message. For more information about choosing an appropriate bucket span, see Buckets.
Cardinality
editIf there are logical groupings of related entities in your data, machine learning analytics can make data models and generate results that take these groupings into consideration. For example, you might choose to split your data by user ID and detect when users are accessing resources differently than they usually do.
If the field that you use to split your data has many different values, the
job uses more memory resources. In particular, if the cardinality of the
by_field_name, over_field_name, or partition_field_name is greater than
1000, you are advised that there might be high memory usage.
Likewise if you are performing population analysis and the cardinality of the
over_field_name is below 10, you are advised that this might not be a suitable
field to use. For more information, see Performing population analysis.
Detectors
editEach anomaly detection job must have one or more detectors. A detector applies an analytical function to specific fields in your data. If your job does not contain a detector or the detector does not contain a valid function, you receive an error.
If a job contains duplicate detectors, you also receive an error. Detectors are
duplicates if they have the same function, field_name, by_field_name,
over_field_name and partition_field_name.
Influencers
editWhen you create an anomaly detection job, you can specify influencers, which are also sometimes referred to as key fields. Picking an influencer is strongly recommended for the following reasons:
- It allows you to more easily assign blame for the anomaly
- It simplifies and aggregates the results
The best influencer is the person or thing that you want to blame for the anomaly. In many cases, users or client IP addresses make excellent influencers. Influencers can be any field in your data; they do not need to be fields that are specified in your detectors, though they often are.
As a best practice, do not pick too many influencers. For example, you generally do not need more than three. If you pick many influencers, the results can be overwhelming and there is a small overhead to the analysis.
The job creation wizards in Kibana can suggest which fields to use as influencers.
Model memory limits
editFor each anomaly detection job, you can optionally specify a model_memory_limit, which
is the approximate maximum amount of memory resources that are required for
analytical processing. The default value is 1 GB. Once this limit is approached,
data pruning becomes more aggressive. Upon exceeding this limit, new entities
are not modeled.
You can also optionally specify the xpack.ml.max_model_memory_limit setting.
By default, it’s not set, which means there is no upper bound on the acceptable
model_memory_limit values in your jobs.
If you set the model_memory_limit too high, it will be impossible to open
the job; jobs cannot be allocated to nodes that have insufficient memory to run
them.
If the estimated model memory limit for an anomaly detection job is greater than the
model memory limit for the job or the maximum model memory limit for the cluster,
the job creation wizards in Kibana generate a warning. If the estimated memory
requirement is only a little higher than the model_memory_limit, the job will
probably produce useful results. Otherwise, the actions you take to address
these warnings vary depending on the resources available in your cluster:
-
If you are using the default value for the
model_memory_limitand the machine learning nodes in the cluster have lots of memory, the best course of action might be to simply increase the job’smodel_memory_limit. Before doing this, however, double-check that the chosen analysis makes sense. The defaultmodel_memory_limitis relatively low to avoid accidentally creating a job that uses a huge amount of memory. -
If the machine learning nodes in the cluster do not have sufficient memory to accommodate a job of the estimated size, the only options are:
- Add bigger machine learning nodes to the cluster, or
- Accept that the job will hit its memory limit and will not necessarily find all the anomalies it could otherwise find.
If you are using Elastic Cloud Enterprise or the hosted Elasticsearch Service on Elastic Cloud,
xpack.ml.max_model_memory_limit is set to prevent you from creating jobs
that cannot be allocated to any machine learning nodes in the cluster. If you find that you
cannot increase model_memory_limit for your machine learning jobs, the solution is to
increase the size of the machine learning nodes in your cluster.
For more information about the model_memory_limit property and the
xpack.ml.max_model_memory_limit setting, see
Analysis limits and
Machine learning settings.