Transforming data with script fields
editTransforming data with script fields
editIf you use datafeeds, you can add scripts to transform your data before
it is analyzed. Datafeeds contain an optional script_fields property, where
you can specify scripts that evaluate custom expressions and return script
fields.
If your datafeed defines script fields, you can use those fields in your anomaly detection job. For example, you can use the script fields in the analysis functions in one or more detectors.
- Example 1: Adding two numerical fields
- Example 2: Concatenating strings
- Example 3: Trimming strings
- Example 4: Converting strings to lowercase
- Example 5: Converting strings to mixed case formats
- Example 6: Replacing tokens
- Example 7: Regular expression matching and concatenation
- Example 8: Splitting strings by domain name
- Example 9: Transforming geo_point data
The following index APIs create and add content to an index that is used in subsequent examples:
PUT /my-index-000001
{
"mappings":{
"properties": {
"@timestamp": {
"type": "date"
},
"aborted_count": {
"type": "long"
},
"another_field": {
"type": "keyword"
},
"clientip": {
"type": "keyword"
},
"coords": {
"properties": {
"lat": {
"type": "keyword"
},
"lon": {
"type": "keyword"
}
}
},
"error_count": {
"type": "long"
},
"query": {
"type": "keyword"
},
"some_field": {
"type": "keyword"
},
"tokenstring1":{
"type":"keyword"
},
"tokenstring2":{
"type":"keyword"
},
"tokenstring3":{
"type":"keyword"
}
}
}
}
PUT /my-index-000001/_doc/1
{
"@timestamp":"2017-03-23T13:00:00",
"error_count":36320,
"aborted_count":4156,
"some_field":"JOE",
"another_field":"SMITH ",
"tokenstring1":"foo-bar-baz",
"tokenstring2":"foo bar baz",
"tokenstring3":"foo-bar-19",
"query":"www.ml.elastic.co",
"clientip":"123.456.78.900",
"coords": {
"lat" : 41.44,
"lon":90.5
}
}
|
In this example, string fields are mapped as |
Example 1: Adding two numerical fields.
PUT _ml/anomaly_detectors/test1
{
"analysis_config":{
"bucket_span": "10m",
"detectors":[
{
"function":"mean",
"field_name": "total_error_count",
"detector_description": "Custom script field transformation"
}
]
},
"data_description": {
"time_field":"@timestamp",
"time_format":"epoch_ms"
}
}
PUT _ml/datafeeds/datafeed-test1
{
"job_id": "test1",
"indices": ["my-index-000001"],
"query": {
"match_all": {
"boost": 1
}
},
"script_fields": {
"total_error_count": {
"script": {
"lang": "expression",
"source": "doc['error_count'].value + doc['aborted_count'].value"
}
}
}
}
|
A script field named |
|
|
The script field is defined in the datafeed. |
This test1 anomaly detection job contains a detector that uses a script field in a
mean analysis function. The datafeed-test1 datafeed defines the script field.
It contains a script that adds two fields in the document to produce a "total"
error count.
The syntax for the script_fields property is identical to that used by Elasticsearch.
For more information, see
Script fields.
You can preview the contents of the datafeed by using the following API:
GET _ml/datafeeds/datafeed-test1/_preview
In this example, the API returns the following results, which contain a sum of
the error_count and aborted_count values:
[
{
"@timestamp": 1490274000000,
"total_error_count": 40476
}
]
This example demonstrates how to use script fields, but it contains insufficient data to generate meaningful results.
You can alternatively use Kibana to create an advanced anomaly detection job that uses
script fields. To add the script_fields property to your datafeed, you must use
the Edit JSON tab. For example:
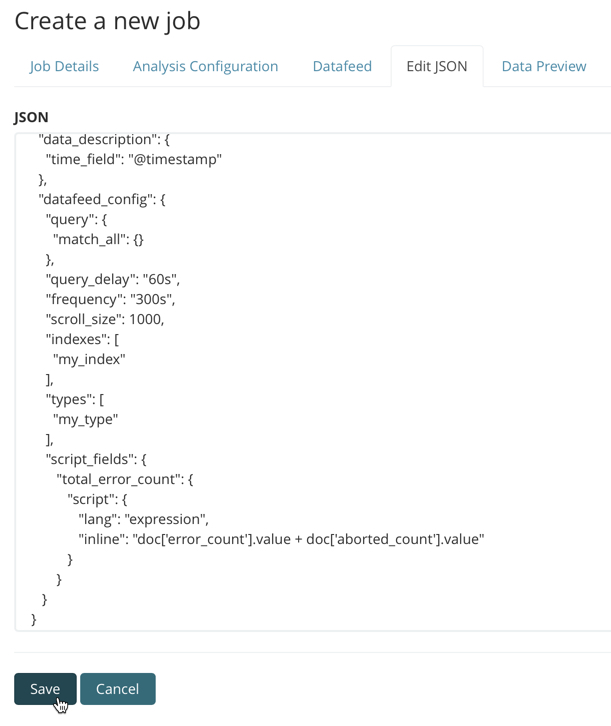
Common script field examples
editWhile the possibilities are limitless, there are a number of common scenarios where you might use script fields in your datafeeds.
Some of these examples use regular expressions. By default, regular expressions are disabled because they circumvent the protection that Painless provides against long running and memory hungry scripts. For more information, see Painless scripting language.
Machine learning analysis is case sensitive. For example, "John" is considered to be different than "john". This is one reason you might consider using scripts that convert your strings to upper or lowercase letters.
Example 2: Concatenating strings.
PUT _ml/anomaly_detectors/test2
{
"analysis_config":{
"bucket_span": "10m",
"detectors":[
{
"function":"low_info_content",
"field_name":"my_script_field",
"detector_description": "Custom script field transformation"
}
]
},
"data_description": {
"time_field":"@timestamp",
"time_format":"epoch_ms"
}
}
PUT _ml/datafeeds/datafeed-test2
{
"job_id": "test2",
"indices": ["my-index-000001"],
"query": {
"match_all": {
"boost": 1
}
},
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "doc['some_field'].value + '_' + doc['another_field'].value"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
|
The script field has a rather generic name in this case, since it will be used for various tests in the subsequent examples. |
|
|
The script field uses the plus (+) operator to concatenate strings. |
The preview datafeed API returns the following results, which show that "JOE" and "SMITH " have been concatenated and an underscore was added:
[
{
"@timestamp": 1490274000000,
"my_script_field": "JOE_SMITH "
}
]
POST _ml/datafeeds/datafeed-test2/_update
{
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "doc['another_field'].value.trim()"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
The preview datafeed API returns the following results, which show that "SMITH " has been trimmed to "SMITH":
[
{
"@timestamp": 1490274000000,
"my_script_field": "SMITH"
}
]
Example 4: Converting strings to lowercase.
POST _ml/datafeeds/datafeed-test2/_update
{
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "doc['some_field'].value.toLowerCase()"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
|
This script field uses the |
The preview datafeed API returns the following results, which show that "JOE" has been converted to "joe":
[
{
"@timestamp": 1490274000000,
"my_script_field": "joe"
}
]
Example 5: Converting strings to mixed case formats.
POST _ml/datafeeds/datafeed-test2/_update
{
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "doc['some_field'].value.substring(0, 1).toUpperCase() + doc['some_field'].value.substring(1).toLowerCase()"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
|
This script field is a more complicated example of case manipulation. It uses
the |
The preview datafeed API returns the following results, which show that "JOE" has been converted to "Joe":
[
{
"@timestamp": 1490274000000,
"my_script_field": "Joe"
}
]
POST _ml/datafeeds/datafeed-test2/_update
{
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "/\\s/.matcher(doc['tokenstring2'].value).replaceAll('_')"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
The preview datafeed API returns the following results, which show that "foo bar baz" has been converted to "foo_bar_baz":
[
{
"@timestamp": 1490274000000,
"my_script_field": "foo_bar_baz"
}
]
Example 7: Regular expression matching and concatenation.
POST _ml/datafeeds/datafeed-test2/_update
{
"script_fields": {
"my_script_field": {
"script": {
"lang": "painless",
"source": "def m = /(.*)-bar-([0-9][0-9])/.matcher(doc['tokenstring3'].value); return m.find() ? m.group(1) + '_' + m.group(2) : '';"
}
}
}
}
GET _ml/datafeeds/datafeed-test2/_preview
|
This script field looks for a specific regular expression pattern and emits the matched groups as a concatenated string. If no match is found, it emits an empty string. |
The preview datafeed API returns the following results, which show that "foo-bar-19" has been converted to "foo_19":
[
{
"@timestamp": 1490274000000,
"my_script_field": "foo_19"
}
]
Example 8: Splitting strings by domain name.
PUT _ml/anomaly_detectors/test3
{
"description":"DNS tunneling",
"analysis_config":{
"bucket_span": "30m",
"influencers": ["clientip","hrd"],
"detectors":[
{
"function":"high_info_content",
"field_name": "sub",
"over_field_name": "hrd",
"exclude_frequent":"all"
}
]
},
"data_description": {
"time_field":"@timestamp",
"time_format":"epoch_ms"
}
}
PUT _ml/datafeeds/datafeed-test3
{
"job_id": "test3",
"indices": ["my-index-000001"],
"query": {
"match_all": {
"boost": 1
}
},
"script_fields":{
"sub":{
"script":"return domainSplit(doc['query'].value).get(0);"
},
"hrd":{
"script":"return domainSplit(doc['query'].value).get(1);"
}
}
}
GET _ml/datafeeds/datafeed-test3/_preview
If you have a single field that contains a well-formed DNS domain name, you can
use the domainSplit() function to split the string into its highest registered
domain and the sub-domain, which is everything to the left of the highest
registered domain. For example, the highest registered domain of
www.ml.elastic.co is elastic.co and the sub-domain is www.ml. The
domainSplit() function returns an array of two values: the first value is the
subdomain; the second value is the highest registered domain.
The preview datafeed API returns the following results, which show that "www.ml.elastic.co" has been split into "elastic.co" and "www.ml":
[
{
"@timestamp": 1490274000000,
"clientip.keyword": "123.456.78.900",
"hrd": "elastic.co",
"sub": "www.ml"
}
]
Example 9: Transforming geo_point data.
PUT _ml/anomaly_detectors/test4
{
"analysis_config":{
"bucket_span": "10m",
"detectors":[
{
"function":"lat_long",
"field_name": "my_coordinates"
}
]
},
"data_description": {
"time_field":"@timestamp",
"time_format":"epoch_ms"
}
}
PUT _ml/datafeeds/datafeed-test4
{
"job_id": "test4",
"indices": ["my-index-000001"],
"query": {
"match_all": {
"boost": 1
}
},
"script_fields": {
"my_coordinates": {
"script": {
"source": "doc['coords.lat'].value + ',' + doc['coords.lon'].value",
"lang": "painless"
}
}
}
}
GET _ml/datafeeds/datafeed-test4/_preview
In Elasticsearch, location data can be stored in geo_point fields but this data type is
not supported natively in machine learning analytics. This example of a script field
transforms the data into an appropriate format. For more information,
see Geographic functions.
The preview datafeed API returns the following results, which show that
41.44 and 90.5 have been combined into "41.44,90.5":
[
{
"@timestamp": 1490274000000,
"my_coordinates": "41.44,90.5"
}
]