Ingest pipelines
editIngest pipelines
editIngest pipelines let you perform common transformations on your data before indexing. For example, you can use pipelines to remove fields, extract values from text, and enrich your data.
A pipeline consists of a series of configurable tasks called processors. Each processor runs sequentially, making specific changes to incoming documents. After the processors have run, Elasticsearch adds the transformed documents to your data stream or index.

You can create and manage ingest pipelines using Kibana’s Ingest Pipelines feature or the ingest APIs. Elasticsearch stores pipelines in the cluster state.
Prerequisites
edit-
Nodes with the
ingestnode role handle pipeline processing. To use ingest pipelines, your cluster must have at least one node with theingestrole. For heavy ingest loads, we recommend creating dedicated ingest nodes. -
If the Elasticsearch security features are enabled, you must have the
manage_pipelinecluster privilege to manage ingest pipelines. To use Kibana’s Ingest Pipelines feature, you also need thecluster:monitor/nodes/infocluster privileges. -
Pipelines including the
enrichprocessor require additional setup. See Enrich your data.
Create and manage pipelines
editIn Kibana, open the main menu and click Stack Management > Ingest Pipelines. From the list view, you can:
- View a list of your pipelines and drill down into details
- Edit or clone existing pipelines
- Delete pipelines

To create a pipeline, click Create pipeline > New pipeline. For an example tutorial, see Example: Parse logs.
The New pipeline from CSV option lets you use a CSV to create an ingest pipeline that maps custom data to the Elastic Common Schema (ECS). Mapping your custom data to ECS makes the data easier to search and lets you reuse visualizations from other datasets. To get started, check Map custom data to ECS.
You can also use the ingest APIs to create and manage pipelines.
The following create pipeline API request creates
a pipeline containing two set processors followed by a
lowercase processor. The processors run sequentially
in the order specified.
PUT _ingest/pipeline/my-pipeline
{
"description": "My optional pipeline description",
"processors": [
{
"set": {
"description": "My optional processor description",
"field": "my-long-field",
"value": 10
}
},
{
"set": {
"description": "Set 'my-boolean-field' to true",
"field": "my-boolean-field",
"value": true
}
},
{
"lowercase": {
"field": "my-keyword-field"
}
}
]
}
Manage pipeline versions
editWhen you create or update a pipeline, you can specify an optional version
integer. You can use this version number with the
if_version parameter to conditionally
update the pipeline. When the if_version parameter is specified, a successful
update increments the pipeline’s version.
PUT _ingest/pipeline/my-pipeline-id
{
"version": 1,
"processors": [ ... ]
}
To unset the version number using the API, replace or update the pipeline
without specifying the version parameter.
Test a pipeline
editBefore using a pipeline in production, we recommend you test it using sample documents. When creating or editing a pipeline in Kibana, click Add documents. In the Documents tab, provide sample documents and click Run the pipeline.
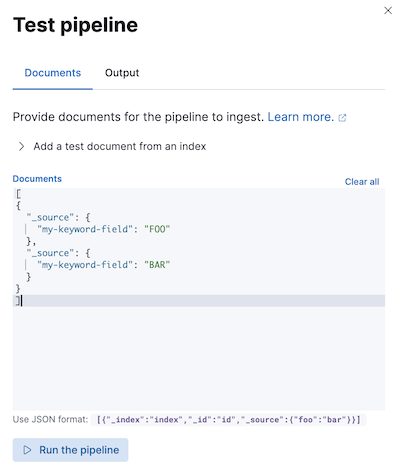
You can also test pipelines using the simulate pipeline
API. You can specify a configured pipeline in the request path. For example,
the following request tests my-pipeline.
POST _ingest/pipeline/my-pipeline/_simulate
{
"docs": [
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
]
}
Alternatively, you can specify a pipeline and its processors in the request body.
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"lowercase": {
"field": "my-keyword-field"
}
}
]
},
"docs": [
{
"_source": {
"my-keyword-field": "FOO"
}
},
{
"_source": {
"my-keyword-field": "BAR"
}
}
]
}
The API returns transformed documents:
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"my-keyword-field": "foo"
},
"_ingest": {
"timestamp": "2099-03-07T11:04:03.000Z"
}
}
},
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"my-keyword-field": "bar"
},
"_ingest": {
"timestamp": "2099-03-07T11:04:04.000Z"
}
}
}
]
}
Add a pipeline to an indexing request
editUse the pipeline query parameter to apply a pipeline to documents in
individual or bulk indexing requests.
POST my-data-stream/_doc?pipeline=my-pipeline
{
"@timestamp": "2099-03-07T11:04:05.000Z",
"my-keyword-field": "foo"
}
PUT my-data-stream/_bulk?pipeline=my-pipeline
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:06.000Z", "my-keyword-field": "foo" }
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:07.000Z", "my-keyword-field": "bar" }
You can also use the pipeline parameter with the update
by query or reindex APIs.
POST my-data-stream/_update_by_query?pipeline=my-pipeline
POST _reindex
{
"source": {
"index": "my-data-stream"
},
"dest": {
"index": "my-new-data-stream",
"op_type": "create",
"pipeline": "my-pipeline"
}
}
Set a default pipeline
editUse the index.default_pipeline index setting to set
a default pipeline. Elasticsearch applies this pipeline to indexing requests if no
pipeline parameter is specified.
Set a final pipeline
editUse the index.final_pipeline index setting to set a
final pipeline. Elasticsearch applies this pipeline after the request or default
pipeline, even if neither is specified.
Pipelines for Beats
editTo add an ingest pipeline to an Elastic Beat, specify the pipeline
parameter under output.elasticsearch in <BEAT_NAME>.yml. For example,
for Filebeat, you’d specify pipeline in filebeat.yml.
output.elasticsearch: hosts: ["localhost:9200"] pipeline: my-pipeline
Pipelines for Fleet and Elastic Agent
editElastic Agent integrations ship with default ingest pipelines that preprocess and enrich data before indexing. Fleet applies these pipelines using index templates that include pipeline index settings. Elasticsearch matches these templates to your Fleet data streams based on the stream’s naming scheme.
Each default integration pipeline calls a nonexistent, unversioned @custom ingest pipeline.
If unaltered, this pipeline call has no effect on your data. However, you can modify this call to
create custom pipelines for integrations that persist across upgrades.
Refer to Tutorial: Transform data with custom ingest pipelines to learn more.
Fleet doesn’t provide a default ingest pipeline for the Custom logs integration, but you can specify a pipeline for this integration using an index template or a custom configuration.
-
Create and test your ingest pipeline. Name your pipeline
logs-<dataset-name>-default. This makes tracking the pipeline for your integration easier.For example, the following request creates a pipeline for the
my-appdataset. The pipeline’s name islogs-my_app-default.PUT _ingest/pipeline/logs-my_app-default { "description": "Pipeline for `my_app` dataset", "processors": [ ... ] } -
Create an index template that includes your pipeline in the
index.default_pipelineorindex.final_pipelineindex setting. Ensure the template is data stream enabled. The template’s index pattern should matchlogs-<dataset-name>-*.You can create this template using Kibana’s Index Management feature or the create index template API.
For example, the following request creates a template matching
logs-my_app-*. The template uses a component template that contains theindex.default_pipelineindex setting.# Creates a component template for index settings PUT _component_template/logs-my_app-settings { "template": { "settings": { "index.default_pipeline": "logs-my_app-default", "index.lifecycle.name": "logs" } } } # Creates an index template matching `logs-my_app-*` PUT _index_template/logs-my_app-template { "index_patterns": ["logs-my_app-*"], "data_stream": { }, "priority": 500, "composed_of": ["logs-my_app-settings", "logs-my_app-mappings"] } - When adding or editing your Custom logs integration in Fleet, click Configure integration > Custom log file > Advanced options.
-
In Dataset name, specify your dataset’s name. Fleet will add new data for the integration to the resulting
logs-<dataset-name>-defaultdata stream.For example, if your dataset’s name was
my_app, Fleet adds new data to thelogs-my_app-defaultdata stream.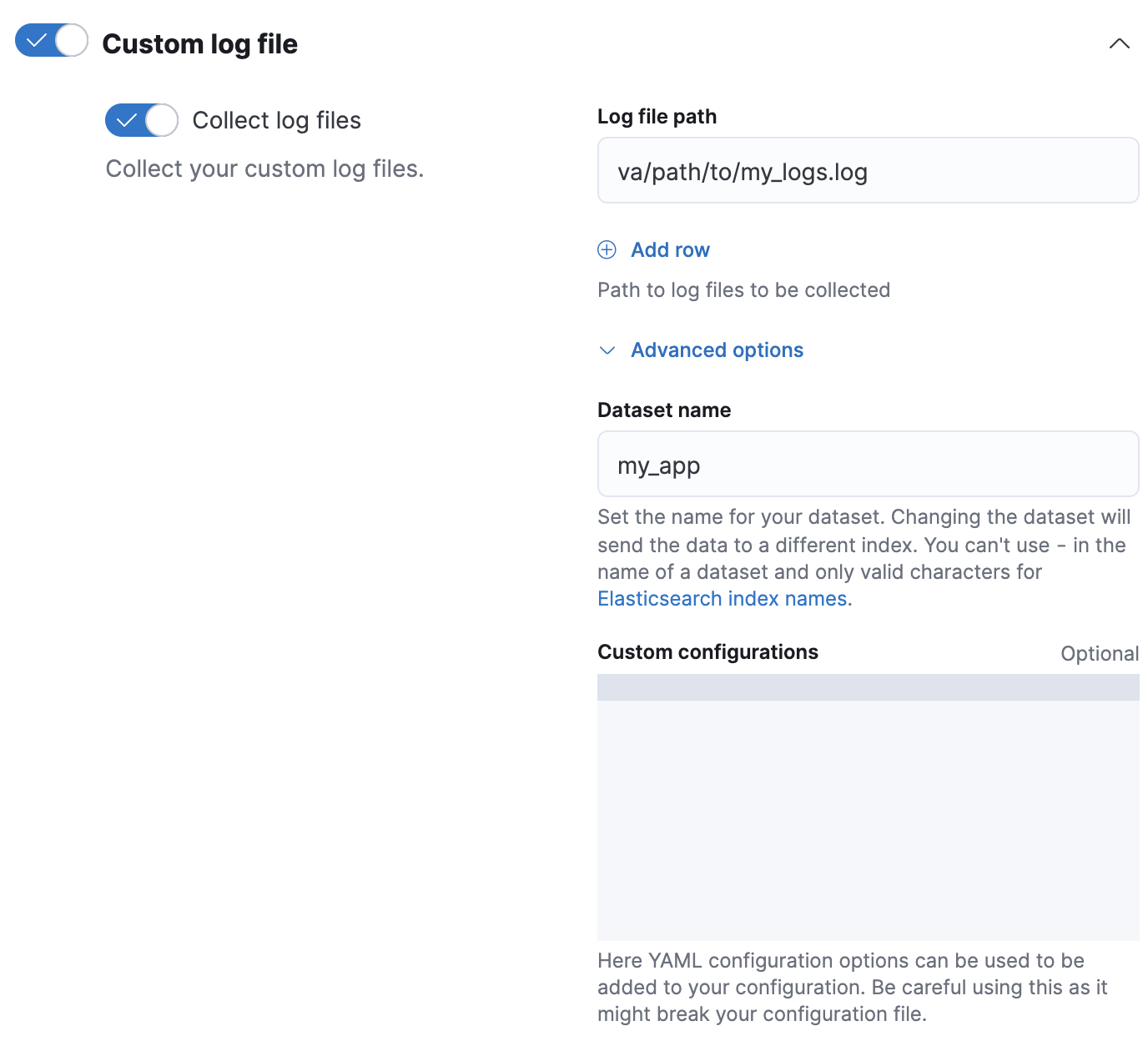
-
Use the rollover API to roll over your data stream. This ensures Elasticsearch applies the index template and its pipeline settings to any new data for the integration.
POST logs-my_app-default/_rollover/
Option 2: Custom configuration
-
Create and test your ingest pipeline. Name your pipeline
logs-<dataset-name>-default. This makes tracking the pipeline for your integration easier.For example, the following request creates a pipeline for the
my-appdataset. The pipeline’s name islogs-my_app-default.PUT _ingest/pipeline/logs-my_app-default { "description": "Pipeline for `my_app` dataset", "processors": [ ... ] } - When adding or editing your Custom logs integration in Fleet, click Configure integration > Custom log file > Advanced options.
-
In Dataset name, specify your dataset’s name. Fleet will add new data for the integration to the resulting
logs-<dataset-name>-defaultdata stream.For example, if your dataset’s name was
my_app, Fleet adds new data to thelogs-my_app-defaultdata stream. -
In Custom Configurations, specify your pipeline in the
pipelinepolicy setting.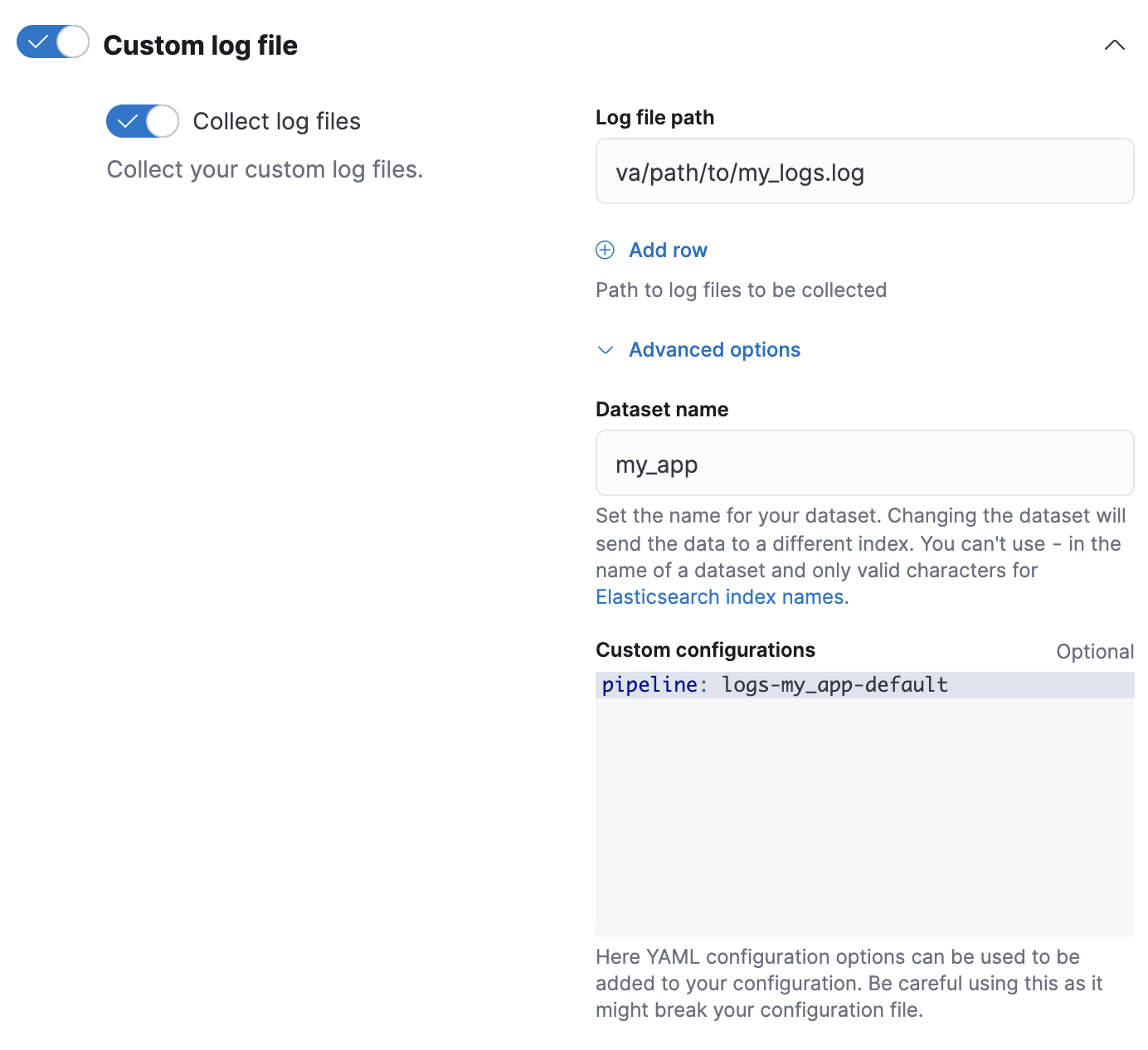
Elastic Agent standalone
If you run Elastic Agent standalone, you can apply pipelines using an
index template that includes the
index.default_pipeline or
index.final_pipeline index setting. Alternatively,
you can specify the pipeline policy setting in your elastic-agent.yml
configuration. See Install standalone Elastic Agents.
Pipelines in Enterprise Search
editWhen you create Elasticsearch indices for Enterprise Search use cases, for example, using the web crawler or connectors, these indices are automatically set up with specific ingest pipelines. These processors help optimize your content for search. Refer to the Enterprise Search documentation for more information.
Access source fields in a processor
editProcessors have read and write access to an incoming document’s source fields.
To access a field key in a processor, use its field name. The following set
processor accesses my-long-field.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"field": "my-long-field",
"value": 10
}
}
]
}
You can also prepend the _source prefix.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"field": "_source.my-long-field",
"value": 10
}
}
]
}
Use dot notation to access object fields.
If your document contains flattened objects, use the
dot_expander processor to expand them first. Other
ingest processors cannot access flattened objects.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"dot_expander": {
"description": "Expand 'my-object-field.my-property'",
"field": "my-object-field.my-property"
}
},
{
"set": {
"description": "Set 'my-object-field.my-property' to 10",
"field": "my-object-field.my-property",
"value": 10
}
}
]
}
Several processor parameters support Mustache
template snippets. To access field values in a template snippet, enclose the
field name in triple curly brackets:{{{field-name}}}. You can use template
snippets to dynamically set field names.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Set dynamic '<service>' field to 'code' value",
"field": "{{{service}}}",
"value": "{{{code}}}"
}
}
]
}
Access metadata fields in a processor
editProcessors can access the following metadata fields by name:
-
_index -
_id -
_routing -
_dynamic_templates
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Set '_routing' to 'geoip.country_iso_code' value",
"field": "_routing",
"value": "{{{geoip.country_iso_code}}}"
}
}
]
}
Use a Mustache template snippet to access metadata field values. For example,
{{{_routing}}} retrieves a document’s routing value.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Use geo_point dynamic template for address field",
"field": "_dynamic_templates",
"value": {
"address": "geo_point"
}
}
}
]
}
The set processor above tells ES to use the dynamic template named geo_point
for the field address if this field is not defined in the mapping of the index
yet. This processor overrides the dynamic template for the field address if
already defined in the bulk request, but has no effect on other dynamic
templates defined in the bulk request.
If you automatically generate
document IDs, you cannot use {{{_id}}} in a processor. Elasticsearch assigns
auto-generated _id values after ingest.
Access ingest metadata in a processor
editIngest processors can add and access ingest metadata using the _ingest key.
Unlike source and metadata fields, Elasticsearch does not index ingest metadata fields by
default. Elasticsearch also allows source fields that start with an _ingest key. If
your data includes such source fields, use _source._ingest to access them.
Pipelines only create the _ingest.timestamp ingest metadata field by default.
This field contains a timestamp of when Elasticsearch received the document’s indexing
request. To index _ingest.timestamp or other ingest metadata fields, use the
set processor.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "Index the ingest timestamp as 'event.ingested'",
"field": "event.ingested",
"value": "{{{_ingest.timestamp}}}"
}
}
]
}
Handling pipeline failures
editA pipeline’s processors run sequentially. By default, pipeline processing stops when one of these processors fails or encounters an error.
To ignore a processor failure and run the pipeline’s remaining processors, set
ignore_failure to true.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"ignore_failure": true
}
}
]
}
Use the on_failure parameter to specify a list of processors to run
immediately after a processor failure. If on_failure is specified, Elasticsearch
afterward runs the pipeline’s remaining processors, even if the on_failure
configuration is empty.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": false
}
}
]
}
}
]
}
Nest a list of on_failure processors for nested error handling.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"rename": {
"description": "Rename 'provider' to 'cloud.provider'",
"field": "provider",
"target_field": "cloud.provider",
"on_failure": [
{
"set": {
"description": "Set 'error.message'",
"field": "error.message",
"value": "Field 'provider' does not exist. Cannot rename to 'cloud.provider'",
"override": false,
"on_failure": [
{
"set": {
"description": "Set 'error.message.multi'",
"field": "error.message.multi",
"value": "Document encountered multiple ingest errors",
"override": true
}
}
]
}
}
]
}
}
]
}
You can also specify on_failure for a pipeline. If a processor without an
on_failure value fails, Elasticsearch uses this pipeline-level parameter as a fallback.
Elasticsearch will not attempt to run the pipeline’s remaining processors.
PUT _ingest/pipeline/my-pipeline
{
"processors": [ ... ],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
}
]
}
Additional information about the pipeline failure may be available in the
document metadata fields on_failure_message, on_failure_processor_type,
on_failure_processor_tag, and on_failure_pipeline. These fields are
accessible only from within an on_failure block.
The following example uses the metadata fields to include information about pipeline failures in documents.
PUT _ingest/pipeline/my-pipeline
{
"processors": [ ... ],
"on_failure": [
{
"set": {
"description": "Record error information",
"field": "error_information",
"value": "Processor {{ _ingest.on_failure_processor_type }} with tag {{ _ingest.on_failure_processor_tag }} in pipeline {{ _ingest.on_failure_pipeline }} failed with message {{ _ingest.on_failure_message }}"
}
}
]
}
Conditionally run a processor
editEach processor supports an optional if condition, written as a
Painless script. If provided, the processor only
runs when the if condition is true.
if condition scripts run in Painless’s
ingest processor context. In
if conditions, ctx values are read-only.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents with 'network.name' of 'Guest'",
"if": "ctx?.network?.name == 'Guest'"
}
}
]
}
If the script.painless.regex.enabled cluster
setting is enabled, you can use regular expressions in your if condition
scripts. For supported syntax, see Painless
regular expressions.
If possible, avoid using regular expressions. Expensive regular expressions can slow indexing speeds.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"set": {
"description": "If 'url.scheme' is 'http', set 'url.insecure' to true",
"if": "ctx.url?.scheme =~ /^http[^s]/",
"field": "url.insecure",
"value": true
}
}
]
}
You must specify if conditions as valid JSON on a single line. However, you
can use the Kibana
console's triple quote syntax to write and debug larger scripts.
If possible, avoid using complex or expensive if condition scripts.
Expensive condition scripts can slow indexing speeds.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": """
Collection tags = ctx.tags;
if(tags != null){
for (String tag : tags) {
if (tag.toLowerCase().contains('prod')) {
return false;
}
}
}
return true;
"""
}
}
]
}
You can also specify a stored script as the
if condition.
PUT _scripts/my-prod-tag-script
{
"script": {
"lang": "painless",
"source": """
Collection tags = ctx.tags;
if(tags != null){
for (String tag : tags) {
if (tag.toLowerCase().contains('prod')) {
return false;
}
}
}
return true;
"""
}
}
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that don't contain 'prod' tag",
"if": { "id": "my-prod-tag-script" }
}
}
]
}
Incoming documents often contain object fields. If a processor script attempts
to access a field whose parent object does not exist, Elasticsearch returns a
NullPointerException. To avoid these exceptions, use
null safe
operators, such as ?., and write your scripts to be null safe.
For example, ctx.network?.name.equalsIgnoreCase('Guest') is not null safe.
ctx.network?.name can return null. Rewrite the script as
'Guest'.equalsIgnoreCase(ctx.network?.name), which is null safe because
Guest is always non-null.
If you can’t rewrite a script to be null safe, include an explicit null check.
PUT _ingest/pipeline/my-pipeline
{
"processors": [
{
"drop": {
"description": "Drop documents that contain 'network.name' of 'Guest'",
"if": "ctx.network?.name != null && ctx.network.name.contains('Guest')"
}
}
]
}
Conditionally apply pipelines
editCombine an if condition with the pipeline processor
to apply other pipelines to documents based on your criteria. You can use this
pipeline as the default pipeline in an
index template used to configure multiple data streams or
indices.
PUT _ingest/pipeline/one-pipeline-to-rule-them-all
{
"processors": [
{
"pipeline": {
"description": "If 'service.name' is 'apache_httpd', use 'httpd_pipeline'",
"if": "ctx.service?.name == 'apache_httpd'",
"name": "httpd_pipeline"
}
},
{
"pipeline": {
"description": "If 'service.name' is 'syslog', use 'syslog_pipeline'",
"if": "ctx.service?.name == 'syslog'",
"name": "syslog_pipeline"
}
},
{
"fail": {
"description": "If 'service.name' is not 'apache_httpd' or 'syslog', return a failure message",
"if": "ctx.service?.name != 'apache_httpd' && ctx.service?.name != 'syslog'",
"message": "This pipeline requires service.name to be either `syslog` or `apache_httpd`"
}
}
]
}
Get pipeline usage statistics
editUse the node stats API to get global and per-pipeline ingest statistics. Use these stats to determine which pipelines run most frequently or spend the most time processing.
GET _nodes/stats/ingest?filter_path=nodes.*.ingest