WARNING: This documentation covers Elasticsearch 2.x. The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Add Failover
editAdd Failover
editRunning a single node means that you have a single point of failure—there is no redundancy. Fortunately, all we need to do to protect ourselves from data loss is to start another node.
If we start a second node, our cluster would look like Figure 3, “A two-node cluster—all primary and replica shards are allocated”.
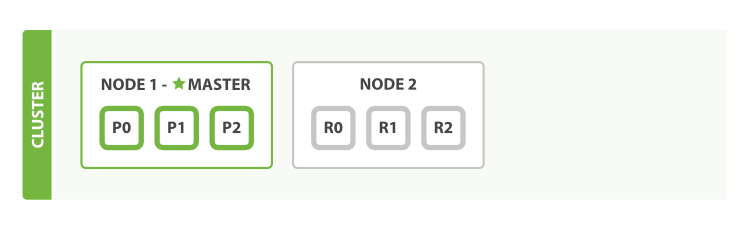
The second node has joined the cluster, and three replica shards have been allocated to it—one for each primary shard. That means that we can lose either node, and all of our data will be intact.
Any newly indexed document will first be stored on a primary shard, and then copied in parallel to the associated replica shard(s). This ensures that our document can be retrieved from a primary shard or from any of its replicas.
The cluster-health now shows a status of green, which means that all six
shards (all three primary shards and all three replica shards) are active:
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
Our cluster is not only fully functional, but also always available.