WARNING: This documentation covers Elasticsearch 2.x. The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Scale Horizontallyedit
What about scaling as the demand for our application grows? If we start a third node, our cluster reorganizes itself to look like Figure 4, “A three-node cluster—shards have been reallocated to spread the load”.
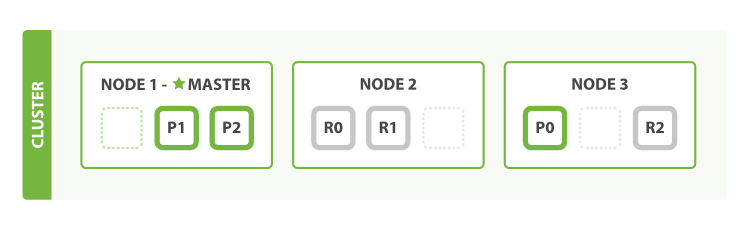
One shard each from Node 1 and Node 2 have moved to the new
Node 3, and we have two shards per node, instead of three.
This means that the hardware resources (CPU, RAM, I/O) of each node
are being shared among fewer shards, allowing each shard to perform
better.
A shard is a fully fledged search engine in its own right, and is capable of using all of the resources of a single node. With our total of six shards (three primaries and three replicas), our index is capable of scaling out to a maximum of six nodes, with one shard on each node and each shard having access to 100% of its node’s resources.
Then Scale Some Moreedit
But what if we want to scale our search to more than six nodes?
The number of primary shards is fixed at the moment an index is created. Effectively, that number defines the maximum amount of data that can be stored in the index. (The actual number depends on your data, your hardware and your use case.) However, read requests—searches or document retrieval—can be handled by a primary or a replica shard, so the more copies of data that you have, the more search throughput you can handle.
The number of replica shards can be changed dynamically on a live cluster,
allowing us to scale up or down as demand requires. Let’s increase the number
of replicas from the default of 1 to 2:
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
As can be seen in Figure 5, “Increasing the number_of_replicas to 2”, the blogs index now
has nine shards: three primaries and six replicas. This means that we can scale out to
a total of nine nodes, again with one shard per node. This would allow us to
triple search performance compared to our original three-node cluster.
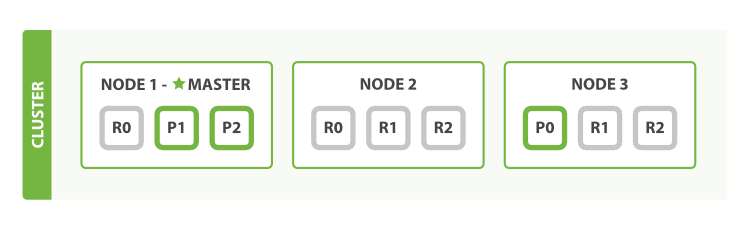
number_of_replicas to 2Of course, just having more replica shards on the same number of nodes doesn’t increase our performance at all because each shard has access to a smaller fraction of its node’s resources. You need to add hardware to increase throughput.
But these extra replicas do mean that we have more redundancy: with the node configuration above, we can now afford to lose two nodes without losing any data.