WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Query Phase
editQuery Phase
editDuring the initial query phase, the query is broadcast to a shard copy (a primary or replica shard) of every shard in the index. Each shard executes the search locally and builds a priority queue of matching documents.
The query phase process is depicted in Figure 14, “Query phase of distributed search”.
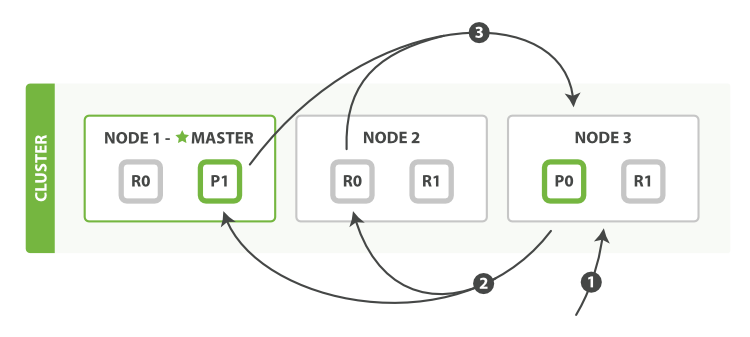
The query phase consists of the following three steps:
-
The client sends a
searchrequest toNode 3, which creates an empty priority queue of sizefrom + size. -
Node 3forwards the search request to a primary or replica copy of every shard in the index. Each shard executes the query locally and adds the results into a local sorted priority queue of sizefrom + size. -
Each shard returns the doc IDs and sort values of all the docs in its
priority queue to the coordinating node,
Node 3, which merges these values into its own priority queue to produce a globally sorted list of results.
When a search request is sent to a node, that node becomes the coordinating node. It is the job of this node to broadcast the search request to all involved shards, and to gather their responses into a globally sorted result set that it can return to the client.
The first step is to broadcast the request to a shard copy of every node in
the index. Just like document GET requests, search requests
can be handled by a primary shard or by any of its replicas. This is how more
replicas (when combined with more hardware) can increase search throughput.
A coordinating node will round-robin through all shard copies on subsequent
requests in order to spread the load.
Each shard executes the query locally and builds a sorted priority queue of
length from + size—in other words, enough results to satisfy the global
search request all by itself. It returns a lightweight list of results to the
coordinating node, which contains just the doc IDs and any values required for
sorting, such as the _score.
The coordinating node merges these shard-level results into its own sorted priority queue, which represents the globally sorted result set. Here the query phase ends.
An index can consist of one or more primary shards, so a search request against a single index needs to be able to combine the results from multiple shards. A search against multiple or all indices works in exactly the same way—there are just more shards involved.