WARNING: The 1.x versions of Elasticsearch have passed their EOL dates. If you are running a 1.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Creating, Indexing, and Deleting a Document
editCreating, Indexing, and Deleting a Documentedit
Create, index, and delete requests are write operations, which must be successfully completed on the primary shard before they can be copied to any associated replica shards, as shown in Figure 9, “Creating, indexing, or deleting a single document”.
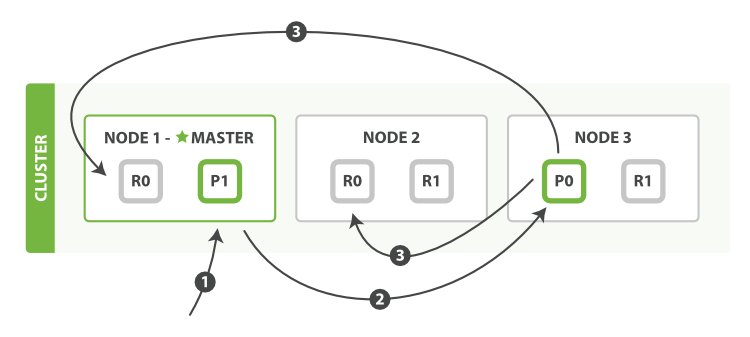
Here is the sequence of steps necessary to successfully create, index, or delete a document on both the primary and any replica shards:
-
The client sends a create, index, or delete request to
Node 1. -
The node uses the document’s
_idto determine that the document belongs to shard0. It forwards the request toNode 3, where the primary copy of shard0is currently allocated. -
Node 3executes the request on the primary shard. If it is successful, it forwards the request in parallel to the replica shards onNode 1andNode 2. Once all of the replica shards report success,Node 3reports success to the coordinating node, which reports success to the client.
By the time the client receives a successful response, the document change has been executed on the primary shard and on all replica shards. Your change is safe.
There are a number of optional request parameters that allow you to influence this process, possibly increasing performance at the cost of data security. These options are seldom used because Elasticsearch is already fast, but they are explained here for the sake of completeness:
-
replication -
The default value for replication is
sync. This causes the primary shard to wait for successful responses from available replica shards before returning.If you set
replicationtoasync, it will return success to the client as soon as the request has been executed on the primary shard. It will still forward the request to the replicas, but you will not know whether the replicas succeeded.This option is mentioned specifically to advise against using it. The default
syncreplication allows Elasticsearch to exert back pressure on whatever system is feeding it with data. Withasyncreplication, it is possible to overload Elasticsearch by sending too many requests without waiting for their completion. -
consistency -
By default, the primary shard requires a quorum, or majority, of shard copies (where a shard copy can be a primary or a replica shard) to be available before even attempting a write operation. This is to prevent writing data to the “wrong side” of a network partition. A quorum is defined as follows:
int( (primary + number_of_replicas) / 2 ) + 1
The allowed values for
consistencyareone(just the primary shard),all(the primary and all replicas), or the defaultquorum, or majority, of shard copies.Note that the
number_of_replicasis the number of replicas specified in the index settings, not the number of replicas that are currently active. If you have specified that an index should have three replicas, a quorum would be as follows:int( (primary + 3 replicas) / 2 ) + 1 = 3
But if you start only two nodes, there will be insufficient active shard copies to satisfy the quorum, and you will be unable to index or delete any documents.
-
timeout -
What happens if insufficient shard copies are available? Elasticsearch waits, in the hope that more shards will appear. By default, it will wait up to 1 minute. If you need to, you can use the
timeoutparameter to make it abort sooner:100is 100 milliseconds, and30sis 30 seconds.
A new index has 1 replica by default, which means that two active shard
copies should be required in order to satisfy the need for a quorum.
However, these default settings would prevent us from doing anything useful
with a single-node cluster. To avoid this problem, the requirement for
a quorum is enforced only when number_of_replicas is greater than 1.