WARNING: The 1.x versions of Elasticsearch have passed their EOL dates. If you are running a 1.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Retrieving a Document
editRetrieving a Documentedit
A document can be retrieved from a primary shard or from any of its replicas, as shown in Figure 10, “Retrieving a single document”.
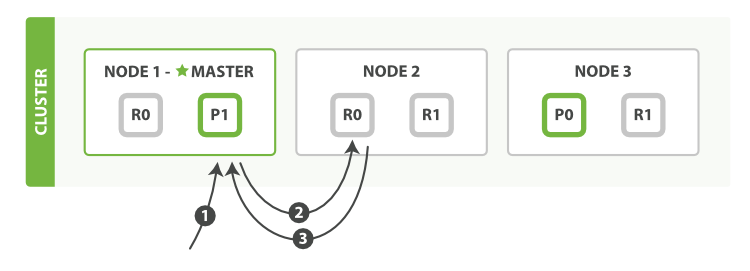
Here is the sequence of steps to retrieve a document from either a primary or replica shard:
-
The client sends a get request to
Node 1. -
The node uses the document’s
_idto determine that the document belongs to shard0. Copies of shard0exist on all three nodes. On this occasion, it forwards the request toNode 2. -
Node 2returns the document toNode 1, which returns the document to the client.
For read requests, the coordinating node will choose a different shard copy on every request in order to balance the load; it round-robins through all shard copies.
It is possible that, while a document is being indexed, the document will already be present on the primary shard but not yet copied to the replica shards. In this case, a replica might report that the document doesn’t exist, while the primary would have returned the document successfully. Once the indexing request has returned success to the user, the document will be available on the primary and all replica shards.