Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
Introduction
In this blog post, I'll demonstrate the process of loading, analyzing, and visualizing data using Elasticsearch, Python, and Kibana. While the examples will revolve around Boston Celtics data, the techniques and concepts can be applied to other datasets. You can view the complete code for this blog post.
The choice to use Boston Celtics' data stemmed from a personal experience. I was going through a stressful time about a year ago and ended up at a basketball game. For the entire time, I could disconnect and find focus in a way I hadn't previously been able to. The first team that I got into was the Boston Celtics. The Boston Celtics are an unusual team, and while they've often been at the top of power rankings for the NBA this season, they only sometimes lead the league in many core metrics.
Using data visualization, I could dive deeper into this team, answer some critical questions about it, and analyze the season better.
Steps to analyze data using Python, Elasticsearch & Kibana
Prerequisites
- This tutorial uses Elasticsearch version 8.11; if you are new, check out our Quick Starts on Elasticsearch and Kibana.
- Download the latest version of Python if you don’t have it installed on your machine. This example utilizes Python 3.12.1.
- You will use the nba_api package to get recent statistics about the Boston Celtics, Jupyter Notebooks, and the Elasticsearch Python Client. While testing this code, I got an error unless I had pandas installed since the nba_data creates pandas DataFrames.
To install these packages, you can run the following command.
- You will want to load a Jupyter Notebook to work with your data interactively. To do so, you can run the following in your terminal.
In the right-hand corner, you can select where it says “New” to create a new Jupyter Notebook.
Step 1: Parsing and cleaning the data
The first step will be to connect to NBA data and load that data into Elasticsearch. You will first need to import the required libraries. For this example, you will use nba_api’s static team data to get information about the Boston Celtics. The leaguegamefinder endpoint allows you to get information. To connect to Elastic, you will use the Elasticsearch Python Client, elasticsearch. To enter your passwords via an interactive prompt, you’ll use getpass.
To load these packages, you can use the following code:
You will want to get the team data from the NBA team static dataset, which has an ID for each team. You can use a list comprehension to find the team with the abbreviation of BOS for Boston. Once you get the complete Celtics object, you can narrow it down to just the ID, which you can use to find game data.
Now, you can use the Celtics' ID to get all the available game data for the team. You view the first five results to ensure the data was correctly loaded using the .head() method.
While working with this data, I noticed that data for the year includes pre-season data. So, I used the season dates to narrow the data down to the current season. In a Jupyter Notebook, you can call current_season to view the full DataFrame.
Since null values can create issues when loading your data to Elasticsearch, you can double-check that this data has none. The line below returns a boolean value, letting you know if your data has any null values. Since this dataset returns a value of False, it has no null values, so we don't have to do further cleaning.
Step 2: Loading the data into Elasticsearch
After parsing the NBA data and finishing cleaning your data, you can create variables for your Elastic Cloud ID and Elastic API Key. Using getpass, you can securely enter your credentials.
Once you've entered your credentials, you can connect to Elasticsearch using the elasticsearch client.
Before you can load your data into Elastic, you must create an index. You can create one for the current season.
You can create a function to load data from the current season into Elasticsearch. Each game is considered a document.
The helpers feature of the Python client allows you to efficiently upload your DataFrame, which holds data on the current season's games, into Elasticsearch. By calling the doc_generator function you just created, you can convert your DataFrame into documents.
Step 3: Writing queries with Elasticsearch
Now that your data is loaded, you can start writing queries with Elasticsearch to learn more about how the Boston Celtics perform this season. First, you can create a query to see how many wins they have had so far this season and return the count of wins as a result.
While working with complex datasets, writing sentences to help explain the dataset is sometimes helpful. Here is one example of how many games the Boston Celtics have won this season.
The output should look something like this:
A streak in sports refers to a consecutive series of games or events in which a team or individual consistently wins or loses. Streaks are significant because they reflect a period of either exceptional performance (winning streak) or a challenging phase (losing streak). While analyzing how well a team is performing, examining how many streaks they have is often helpful. You can create a query that allows you to sort the wins and losses by game data.
You can use the es.search() method to create a search based on the query above.
The following code creates a JSON object of game date with the game result.
To view the top five streaks of the season, you can create a dictionary of each streak and sort it accordingly.
Step 4: Creating a dashboard with Kibana
While we can continue writing queries to learn more about the Boston Celtics, creating a dashboard is a more efficient way to draw insights from your data.

Before making a dashboard, you will need to create a data view to ensure Kibana can access the data in your Elasticsearch index. For your data view, you will need to give it a name, select the index or pattern representing multiple indices you want to visualize and provide a timestamp field so you can create time-based visualizations.

After you've created a data view, you can start to create a dashboard. Under the header "Analytics," select where it says "Dashboard," and click where it says "Create Dashboard."
An excellent visualization to start with is creating a title visualization for your dashboard. You can select a text visualization and markdown to add an image to the title.

To learn if the Celtics are winning more games than losing, you can create a waffle chart to illustrate that at this point in the season, the Celtics are winning more games than losing.

You can see the configuration of this chart here:
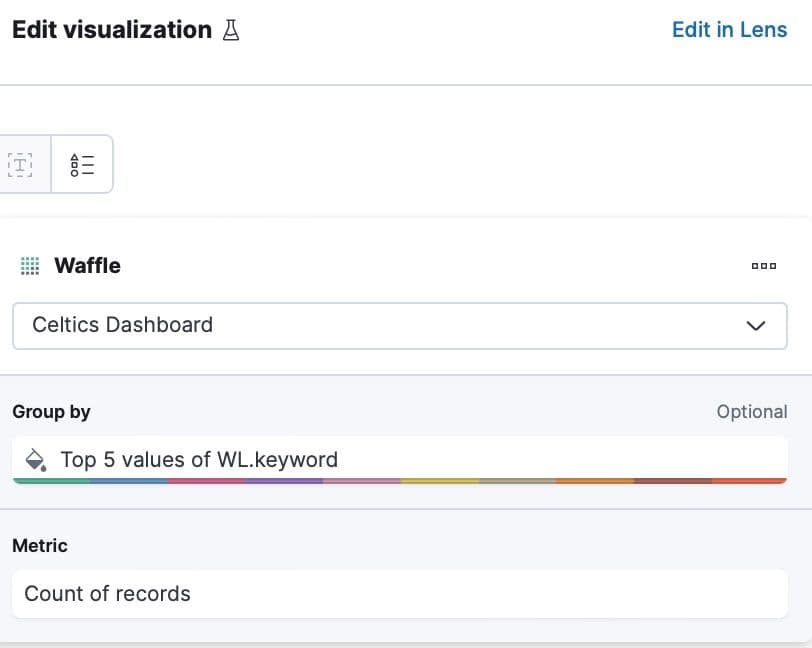
Maintaining more assists than turnovers is a crucial indicator of effective ball movement within a team. The accompanying visualization, current as of the date of this blog post, clearly illustrates that the team is performing well in this aspect, showcasing proficient ball distribution and teamwork.

The configuration of this visualization looks like this:

The plus-minus in basketball shows how many more points the Boston Celtics had over the other team, this statistic is often used to explain the impact a team has had on the game. A high plus score indicates that the team tends to do well in terms of scoring or preventing goals/points when that team is playing. A high minus score suggests the opposite – that the team tends to be outscored. At the beginning of season there was an outlier with one game where the Celtics scored over 50 points more than the other team but this normalized over time. The most recent game (at the time of writing), against the Milwaukee Bucks was also an outlier as well.

Below is the configuration of the above visualization.

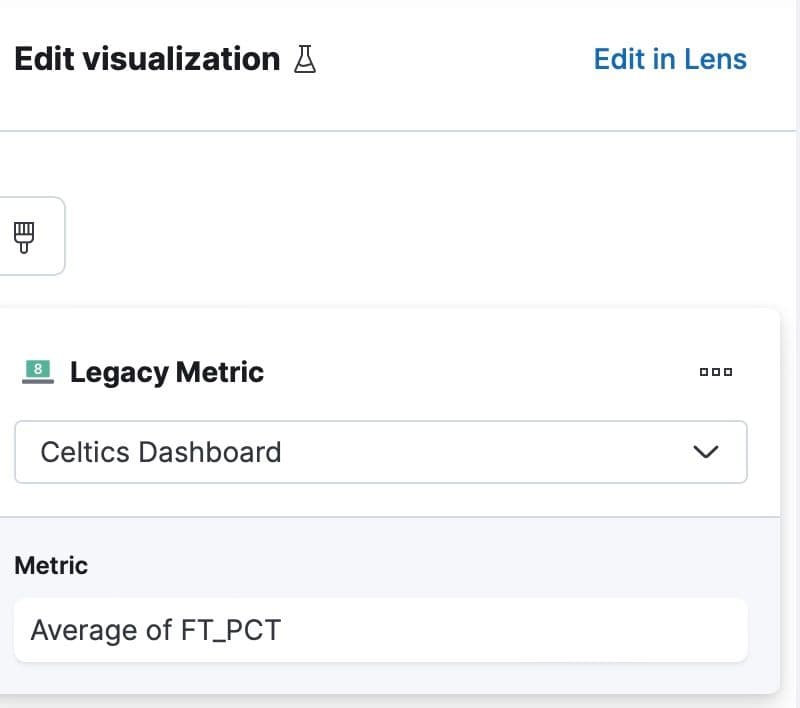
To learn more about how often the Celtics are making shots, you can create a few top lines, including:
- What is the average field goal percentage?
- What is the average field goal percentage from the three-point line?
- What is the average free throw percentage?

The configuration of these top lines looks like this in Kibana:
Configuration of field goal percentage topline:

Configuration of field goal percentage from the three point line topline:

Configuration of free throw percentage topline:
The final visualization examines whether the Celtics' scoring increases with more steals and blocks. The colors represent the average of blocks plus the average of steals. The green gets dark as the number of blocks and steals increases. However, the absence of a discernible pattern in the data suggests no significant correlation between these defensive actions and their overall scoring.

The configuration of this visualization should look like this:

Conclusion
By visualizing data in this way, you can robustly interact with your data and draw further insights. Be sure to check out the complete code for this blog post. As a next step, create a data pipeline to programmatically get the data into your dashboard or utilize some of our machine learning features, such as anomaly detection. You also can expand this dataset by adding historical Celtics data or comparing the Celtics to other teams across the NBA. We hope you can continue to use Python, Elasticsearch, and Kibana. As always, let us know if you need if this blog post inspires you to build anything or if you have any questions on our Discuss forums and the community Slack channel.
How to analyze data using Python, Elasticsearch, and Kibana
1
Prerequisites
Ensure Elasticsearch, Python, and Kibana are properly running/configured.
2
Parse and clean the dataset
Make sure to clean the data before loading it into Elasticsearch.
3
Load the data
Load the data into Elasticsearch. Remember that before you can load your data into Elasticsearch, you must create an index.
4
Write queries
Write queries with Elasticsearch to extract insights from your data.
5
Create a dashboard
Create a dashboard with Kibana. Use Kibana to create visualizations and dashboards based on your data. Customize the dashboards to display relevant metrics.
Related Content
How to instrument your search API with OpenTelemetry and query it with ES|QL
Add custom attributes to OpenTelemetry spans and run six ES|QL queries that reveal your top searches, zero-result rate and slowest queries.
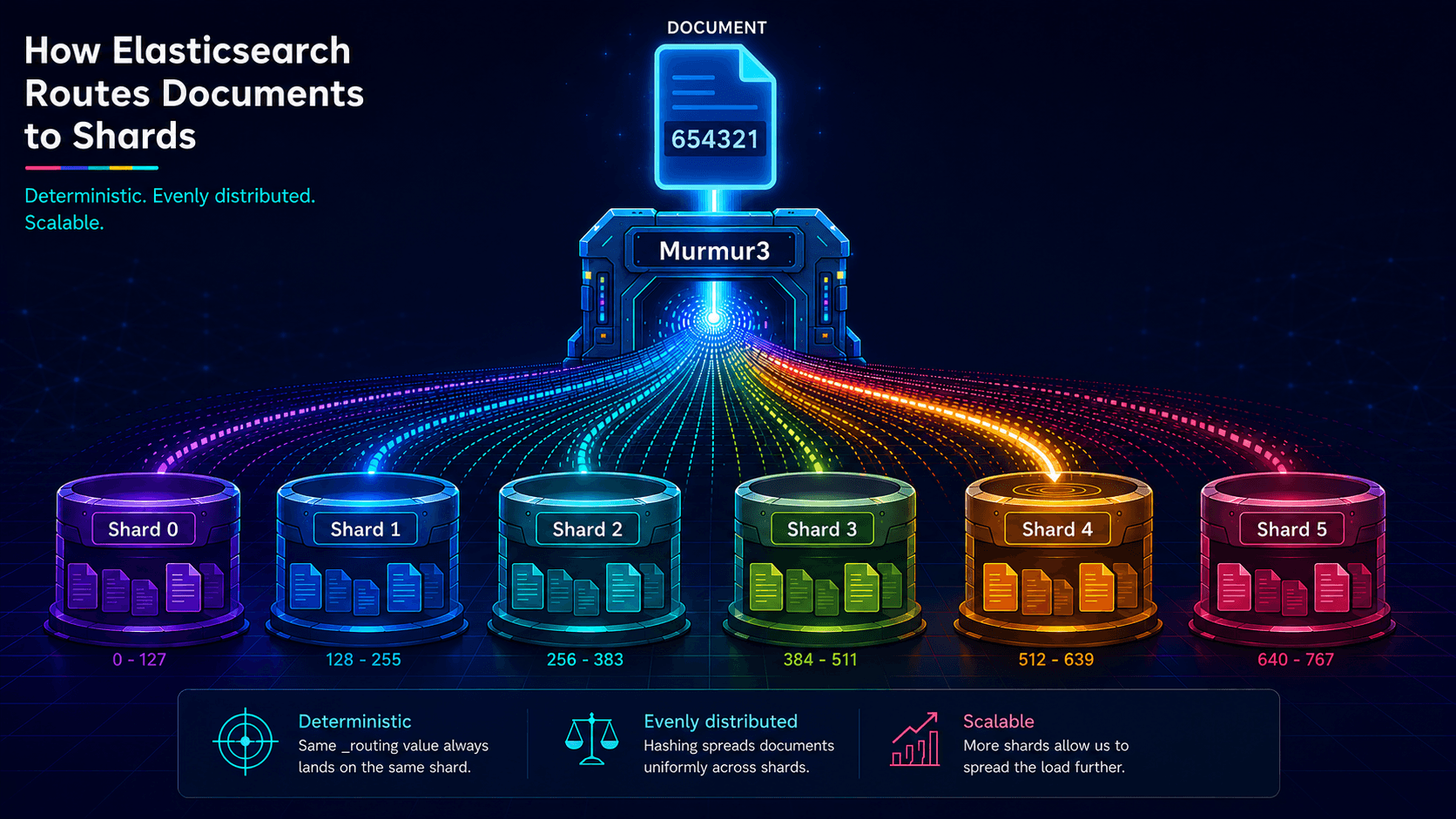
The hash() Elasticsearch won't name and the 12 bytes that prove it's Murmur3
Elasticsearch's routing formula uses MurmurHash3, but the docs never say so. This post names the function, walks through the full shard calculation, and shows you how to reproduce it externally.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.
June 10, 2026
Your AI agent reads the fine print: building a RAG pipeline over EU regulations with Elasticsearch and OGX
Learn how to configure Elasticsearch as an OGX vector store, ingest EU regulation PDFs and build a Python RAG agent that runs hybrid BM25 and vector search with source-level citations.