HTTP JSON input
editHTTP JSON input
editUse the httpjson input to read messages from an HTTP API with JSON payloads.
This input supports:
-
Auth
- Basic
- OAuth2
- Retrieval at a configurable interval
- Pagination
- Retries
- Rate limiting
- Proxying
- Request transformations
- Response transformations
Example configurations:
filebeat.inputs:
# Fetch your public IP every minute.
- type: httpjson
interval: 1m
request.url: https://api.ipify.org/?format=json
processors:
- decode_json_fields:
fields: ["message"]
target: "json"
filebeat.inputs:
- type: httpjson
request.url: http://localhost:9200/_search?scroll=5m
request.method: POST
response.split:
target: body.hits.hits
response.pagination:
- set:
target: url.value
value: http://localhost:9200/_search/scroll
- set:
target: url.params.scroll_id
value: '[[.last_response.body._scroll_id]]'
- set:
target: body.scroll
value: 5m
Additionally, it supports authentication via Basic auth, HTTP Headers or oauth2.
Example configurations with authentication:
filebeat.inputs:
- type: httpjson
request.url: http://localhost
request.transforms:
- set:
target: header.Authorization
value: 'Basic aGVsbG86d29ybGQ='
filebeat.inputs:
- type: httpjson
auth.oauth2:
client.id: 12345678901234567890abcdef
client.secret: abcdef12345678901234567890
token_url: http://localhost/oauth2/token
request.url: http://localhost
filebeat.inputs:
- type: httpjson
auth.oauth2:
client.id: 12345678901234567890abcdef
client.secret: abcdef12345678901234567890
token_url: http://localhost/oauth2/token
user: user@domain.tld
password: P@$$W0₹D
request.url: http://localhost
Input state
editThe httpjson input keeps a runtime state between requests. This state can be accessed by some configuration options and transforms.
The state has the following elements:
-
last_response.url.value: The full URL with params and fragments from the last request with a successful response. -
last_response.url.params: Aurl.Valuesof the params from the URL inlast_response.url.value. Can be queried with theGetfunction. -
last_response.header: A map containing the headers from the last successful response. -
last_response.body: A map containing the parsed JSON body from the last successful response. This is the response as it comes from the remote server. -
last_response.page: A number indicating the page number of the last response. -
first_event: A map representing the first event sent to the output (result from applying transforms tolast_response.body). -
last_event: A map representing the last event of the current request in the requests chain (result from applying transforms tolast_response.body). -
url: The last requested URL as a rawurl.URLGo type. -
header: A map containing the headers. References the next request headers when used inrequest.rate_limit.early_limitorresponse.paginationconfiguration sections, and to the last response headers when used inresponse.transforms,response.split, orrequest.rate_limit.limitconfiguration sections. -
body: A map containing the body. References the next request body when used inrequest.rate_limit.early_limitorresponse.paginationconfiguration sections, and to the last response body when used inresponse.transformsorresponse.splitconfiguration sections. -
cursor: A map containing any data the user configured to be stored between restarts (Seecursor).
All of the mentioned objects are only stored at runtime, except cursor, which has values that are persisted between restarts.
Transforms
editA transform is an action that lets the user modify the input state. Depending on where the transform is defined, it will have access for reading or writing different elements of the state.
The access limitations are described in the corresponding configuration sections.
append
editAppends a value to an array. If the field does not exist, the first entry will create a new array. If the field exists, the value is appended to the existing field and converted to a list.
- append:
target: body.foo.bar
value: '[[.cursor.baz]]'
default: "a default value"
-
targetdefines the destination field where the value is stored. -
valuedefines the value that will be stored and it is a value template. -
defaultdefines the fallback value whenevervalueis empty or the template parsing fails. Default templates do not have access to any state, only to functions. -
value_typedefines the type of the resulting value. Possible values are:string,json, andint. Default isstring. -
fail_on_template_errorif set totruean error will be returned and the request will be aborted when the template evaluation fails. Default isfalse.
delete
editDeletes the target field.
- delete:
target: body.foo.bar
-
targetdefines the destination field to delete. Iftargetis a list and not a single element, the complete list will be deleted.
set
editSets a value.
- set:
target: body.foo.bar
value: '[[.cursor.baz]]'
default: "a default value"
-
targetdefines the destination field where the value is stored. -
valuedefines the value that will be stored and it is a value template. -
defaultdefines the fallback value whenevervalueis empty or the template parsing fails. Default templates do not have access to any state, only to functions. -
value_typedefines how the resulting value will be treated. Possible values are:string,json, andint. Default isstring. -
fail_on_template_errorif set totruean error will be returned and the request will be aborted when the template evaluation fails. Default isfalse.
Value templates
editSome configuration options and transforms can use value templates. Value templates are Go templates with access to the input state and to some built-in functions.
Please note that delimiters are changed from the default {{ }} to [[ ]] to improve interoperability with other templating mechanisms.
To see which state elements and operations are available, see the documentation for the option or transform where you want to use a value template.
A value template looks like:
- set:
target: body.foo.bar
value: '[[.cursor.baz]] more data'
default: "a default value"
The content inside the brackets [[ ]] is evaluated. For more information on Go templates please refer to the Go docs.
Some built-in helper functions are provided to work with the input state inside value templates:
-
parseDuration: parses duration strings and returnstime.Duration. Example:[[parseDuration "1h"]]. -
now: returns the currenttime.Timeobject in UTC. Optionally, it can receive atime.Durationas a parameter. Example:[[now (parseDuration "-1h")]]returns the time at 1 hour before now. -
parseTimestamp: parses a timestamp in seconds and returns atime.Timein UTC. Example:[[parseTimestamp 1604582732]]returns2020-11-05 13:25:32 +0000 UTC. -
parseTimestampMilli: parses a timestamp in milliseconds and returns atime.Timein UTC. Example:[[parseTimestamp 1604582732000]]returns2020-11-05 13:25:32 +0000 UTC. -
parseTimestampNano: parses a timestamp in nanoseconds and returns atime.Timein UTC. Example:[[parseTimestamp 1604582732000000000]]returns2020-11-05 13:25:32 +0000 UTC. -
parseDate: parses a date string and returns atime.Timein UTC. By default the expected layout isRFC3339but optionally can accept any of the Golang predefined layouts or a custom one. Example:[[ parseDate "2020-11-05T12:25:32Z" ]],[[ parseDate "2020-11-05T12:25:32.1234567Z" "RFC3339Nano" ]],[[ (parseDate "Thu Nov 5 12:25:32 +0000 2020" "Mon Jan _2 15:04:05 -0700 2006").UTC ]]. -
formatDate: formats atime.Time. By default the format layout isRFC3339but optionally can accept any of the Golang predefined layouts or a custom one. It will default to UTC timezone when formatting, but you can specify a different timezone. If the timezone is incorrect, it will default to UTC. Example:[[ formatDate (now) "UnixDate" ]],[[ formatDate (now) "UnixDate" "America/New_York" ]]. -
getRFC5988Link: extracts a specific relation from a list of RFC5988 links. It is useful when parsing header values for pagination. Example:[[ getRFC5988Link "next" .last_response.header.Link ]]. -
toInt: converts a value of any type to an integer when possible. Returns 0 if the conversion fails. -
add: adds a list of integers and returns their sum. -
mul: multiplies two integers. -
div: does the integer division of two integer values. -
hmac: calculates the hmac signature of a list of strings concatenated together. Returns a hex encoded signature. Supports sha1 or sha256. Example[[hmac "sha256" "secret" "string1" "string2" (formatDate (now) "RFC1123")]] -
base64Encode: Joins and base64 encodes all supplied strings. Example[[base64Encode "string1" "string2"]] -
base64EncodeNoPad: Joins and base64 encodes all supplied strings without padding. Example[[base64EncodeNoPad "string1" "string2"]] -
base64Decode: Decodes the base64 string. Any binary output will be converted to a UTF8 string. -
base64DecodeNoPad: Decodes the base64 string without padding. Any binary output will be converted to a UTF8 string. -
join: joins a list using the specified separator. Example:[[join .body.arr ","]] -
sprintf: formats according to a format specifier and returns the resulting string. Refer to the Go docs for usage. Example:[[sprintf "%d:%q" 34 "quote this"]] -
hmacBase64: calculates the hmac signature of a list of strings concatenated together. Returns a base64 encoded signature. Supports sha1 or sha256. Example[[hmac "sha256" "secret" "string1" "string2" (formatDate (now) "RFC1123")]] -
uuid: returns a random UUID such asa11e8780-e3e7-46d0-8e76-f66e75acf019. Example:[[ uuid ]] -
userAgent: generates the User Agent with optional additional values. If no arguments are provided, it will generate the default User Agent that is added to all requests by default. It is recommended to delete the existing User-Agent header before setting a new one. Example:[[ userAgent "integration/1.2.3" ]]would generateElastic-Filebeat/8.1.0 (darwin; amd64; 9b893e88cfe109e64638d65c58fd75c2ff695402; 2021-12-15 13:20:00 +0000 UTC; integration_name/1.2.3) -
beatInfo: returns a map containing information about the Beat. Available keys in the map aregoos(running operating system),goarch(running system architecture),commit(git commit of current build),buildtime(compile time of current build),version(version of current build). Example:[[ beatInfo.version ]]returns{version}.
In addition to the provided functions, any of the native functions for time.Time, http.Header, and url.Values types can be used on the corresponding objects. Examples: [[(now).Day]], [[.last_response.header.Get "key"]]
Configuration options
editThe httpjson input supports the following configuration options plus the
Common options described later.
interval
editDuration between repeated requests. It may make additional pagination requests in response to the initial request if pagination is enabled. Default: 60s.
auth.basic.enabled
editWhen set to false, disables the basic auth configuration. Default: true.
Basic auth settings are disabled if either enabled is set to false or
the auth.basic section is missing.
auth.basic.user
editThe user to authenticate with.
auth.basic.password
editThe password to use.
auth.oauth2.enabled
editWhen set to false, disables the oauth2 configuration. Default: true.
OAuth2 settings are disabled if either enabled is set to false or
the auth.oauth2 section is missing.
auth.oauth2.provider
editUsed to configure supported oauth2 providers.
Each supported provider will require specific settings. It is not set by default.
Supported providers are: azure, google.
auth.oauth2.client.id
editThe client ID used as part of the authentication flow. It is always required
except if using google as provider. Required for providers: default, azure.
auth.oauth2.client.secret
editThe client secret used as part of the authentication flow. It is always required
except if using google as provider. Required for providers: default, azure.
auth.oauth2.user
editThe user used as part of the authentication flow. It is required for authentication
- grant type password. It is only available for provider default.
auth.oauth2.password
editThe password used as part of the authentication flow. It is required for authentication
- grant type password. It is only available for provider default.
user and password are required for grant_type password. If user and
password is not used then it will automatically use the token_url and
client credential method.
auth.oauth2.scopes
editA list of scopes that will be requested during the oauth2 flow. It is optional for all providers.
auth.oauth2.token_url
editThe endpoint that will be used to generate the tokens during the oauth2 flow. It is required if no provider is specified.
For azure provider either token_url or azure.tenant_id is required.
auth.oauth2.endpoint_params
editSet of values that will be sent on each request to the token_url. Each param key can have multiple values.
Can be set for all providers except google.
- type: httpjson
auth.oauth2:
endpoint_params:
Param1:
- ValueA
- ValueB
Param2:
- Value
auth.oauth2.azure.tenant_id
editUsed for authentication when using azure provider.
Since it is used in the process to generate the token_url, it can’t be used in
combination with it. It is not required.
For information about where to find it, you can refer to https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal.
auth.oauth2.azure.resource
editThe accessed WebAPI resource when using azure provider.
It is not required.
auth.oauth2.google.credentials_file
editThe credentials file for Google.
Only one of the credentials settings can be set at once. If none is provided, loading default credentials from the environment will be attempted via ADC. For more information about how to provide Google credentials, please refer to https://cloud.google.com/docs/authentication.
auth.oauth2.google.credentials_json
editYour credentials information as raw JSON.
Only one of the credentials settings can be set at once. If none is provided, loading default credentials from the environment will be attempted via ADC. For more information about how to provide Google credentials, please refer to https://cloud.google.com/docs/authentication.
auth.oauth2.google.jwt_file
editThe JWT Account Key file for Google.
Only one of the credentials settings can be set at once. If none is provided, loading default credentials from the environment will be attempted via ADC. For more information about how to provide Google credentials, please refer to https://cloud.google.com/docs/authentication.
auth.oauth2.google.delegated_account
editEmail of the delegated account used to create the credentials (usually an admin).
request.url
editThe URL of the HTTP API. Required.
request.method
editHTTP method to use when making requests. GET or POST are the options. Default: GET.
request.encode_as
editContentType used for encoding the request body. If set it will force the encoding in the specified format regardless of the Content-Type header value, otherwise it will honor it if possible or fallback to application/json. By default the requests are sent with Content-Type: application/json. Supported values: application/json and application/x-www-form-urlencoded. application/x-www-form-urlencoded will url encode the url.params and set them as the body. It is not set by default.
request.body
editAn optional HTTP POST body. The configuration value must be an object, and it
will be encoded to JSON. This is only valid when request.method is POST.
Defaults to null (no HTTP body).
- type: httpjson
request.method: POST
request.body:
query:
bool:
filter:
term:
type: authentication
request.timeout
editDuration before declaring that the HTTP client connection has timed out. Valid time units are ns, us, ms, s, m, h. Default: 30s.
request.ssl
editThis specifies SSL/TLS configuration. If the ssl section is missing, the host’s CAs are used for HTTPS connections. See SSL for more information.
request.proxy_url
editThis specifies proxy configuration in the form of http[s]://<user>:<password>@<server name/ip>:<port>
filebeat.inputs: # Fetch your public IP every minute. - type: httpjson interval: 1m request.url: https://api.ipify.org/?format=json request.proxy_url: http://proxy.example:8080
request.retry.max_attempts
editThe maximum number of retries for the HTTP client. Default: 5.
request.retry.wait_min
editThe minimum time to wait before a retry is attempted. Default: 1s.
request.retry.wait_max
editThe maximum time to wait before a retry is attempted. Default: 60s.
request.redirect.forward_headers
editWhen set to true request headers are forwarded in case of a redirect. Default: false.
request.redirect.headers_ban_list
editWhen redirect.forward_headers is set to true, all headers except the ones defined in this list will be forwarded. Default: [].
request.redirect.max_redirects
editThe maximum number of redirects to follow for a request. Default: 10.
request.rate_limit.limit
editThe value of the response that specifies the total limit. It is defined with a Go template value.
Can read state from: [.last_response.header]
request.rate_limit.remaining
editThe value of the response that specifies the remaining quota of the rate limit.
It is defined with a Go template value. Can read state from: [.last_response.header]
If the remaining header is missing from the Response, no rate-limiting will occur.
request.rate_limit.reset
editThe value of the response that specifies the epoch time when the rate limit will reset.
It is defined with a Go template value. Can read state from: [.last_response.header]
request.rate_limit.early_limit
editOptionally start rate-limiting prior to the value specified in the Response.
Under the default behavior, Requests will continue while the remaining value is non-zero.
Specifying an early_limit will mean that rate-limiting will occur prior to reaching 0.
-
If the value specified for
early_limitis less than1, the value is treated as a percentage of the Response providedlimit. e.g. specifying0.9will mean that Requests will continue until reaching 90% of the rate-limit — for alimitvalue of120, the rate-limit starts when theremainingreaches12. If thelimitheader is missing from the Response, default rate-limiting will occur (whenremainingreaches0). -
If the value specified for
early_limitis greater than or equal to1, the value is treated as the target value forremaining. e.g. instead of rate-limiting whenremaininghits0, rate-limiting will occur whenremaininghits the value specified.
It is not set by default (by default the rate-limiting as specified in the Response is followed).
request.transforms
editList of transforms to apply to the request before each execution.
Available transforms for request: [append, delete, set].
Can read state from: [.last_response.*, .last_event.*, .cursor.*, .header.*, .url.*, .body.*].
Can write state to: [body.*, header.*, url.*].
filebeat.inputs:
- type: httpjson
request.url: http://localhost:9200/_search?scroll=5m
request.method: POST
request.transforms:
- set:
target: body.from
value: '[[now (parseDuration "-1h")]]'
response.decode_as
editContentType used for decoding the response body. If set it will force the decoding in the specified format regardless of the Content-Type header value, otherwise it will honor it if possible or fallback to application/json. Supported values: application/json, application/x-ndjson, text/csv. It is not set by default.
For text/csv, one event for each line will be created, using the header values as the object keys. For this reason is always assumed that a header exists.
response.transforms
editList of transforms to apply to the response once it is received.
Available transforms for response: [append, delete, set].
Can read state from: [.last_response.*, .last_event.*, .cursor.*, .header.*, .url.*].
Can write state to: [body.*].
filebeat.inputs:
- type: httpjson
request.url: http://localhost:9200/_search?scroll=5m
request.method: POST
response.transforms:
- delete:
target: body.very_confidential
response.split:
target: body.hits.hits
response.pagination:
- set:
target: url.value
value: http://localhost:9200/_search/scroll
- set:
target: url.params.scroll_id
value: '[[.last_response.body._scroll_id]]'
- set:
target: body.scroll
value: 5m
response.split
editSplit operation to apply to the response once it is received. A split can convert a map, array, or string into multiple events.
response.split[].target
editDefines the target field upon the split operation will be performed.
response.split[].type
editDefines the field type of the target. Allowed values: array, map, string. string requires the use of the delimiter options to specify what characters to split the string on. delimiter always behaves as if keep_parent is set to true. Default: array.
response.split[].transforms
editA set of transforms can be defined. This list will be applied after response.transforms and after the object has been modified based on response.split[].keep_parent and response.split[].key_field.
Available transforms for response: [append, delete, set].
Can read state from: [.last_response.*, .first_event.*, .last_event.*, .cursor.*, .header.*, .url.*].
Can write state to: [body.*].
in this context, body.* will be the result of all the previous transformations.
response.split[].keep_parent
editIf set to true, the fields from the parent document (at the same level as target) will be kept. Otherwise a new document will be created using target as the root. Default: false.
response.split[].delimiter
editRequired if using split type of string. This is the sub string used to split the string. For example if delimiter was "\n" and the string was "line 1\nline 2", then the split would result in "line 1" and "line 2".
response.split[].key_field
editValid when used with type: map. When not empty, defines a new field where the original key value will be stored.
response.split[].ignore_empty_value
editIf set to true, empty or missing value will be ignored and processing will pass on to the next nested split operation instead of failing with an error. Default: false.
response.split[].split
editNested split operation. Split operations can be nested at will. An event won’t be created until the deepest split operation is applied.
response.request_body_on_pagination
editIf set to true, the values in request.body are sent for pagination requests. Default: false.
response.pagination
editList of transforms that will be applied to the response to every new page request. All the transforms from request.transform will be executed and then response.pagination will be added to modify the next request as needed. For subsequent responses, the usual response.transforms and response.split will be executed normally.
Available transforms for pagination: [append, delete, set].
Can read state from: [.last_response.*, .first_event.*, .last_event.*, .cursor.*, .header.*, .url.*, .body.*].
Can write state to: [body.*, header.*, url.*].
Examples using split:
-
We have a response with two nested arrays, and we want a document for each of the elements of the inner array:
{ "this": "is kept", "alerts": [ { "this_is": "also kept", "entities": [ { "something": "something" }, { "else": "else" } ] }, { "this_is": "also kept 2", "entities": [ { "something": "something 2" }, { "else": "else 2" } ] } ] }The config will look like:
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array keep_parent: true split: # paths in nested splits need to represent the state of body, not only their current level of nesting target: body.alerts.entities type: array keep_parent: trueThis will output:
[ { "this": "is kept", "alerts": { "this_is": "also kept", "entities": { "something": "something" } } }, { "this": "is kept", "alerts": { "this_is": "also kept", "entities": { "else": "else" } } }, { "this": "is kept", "alerts": { "this_is": "also kept 2", "entities": { "something": "something 2" } } }, { "this": "is kept", "alerts": { "this_is": "also kept 2", "entities": { "else": "else 2" } } } ] -
We have a response with an array with two objects, and we want a document for each of the object keys while keeping the keys values:
{ "this": "is not kept", "alerts": [ { "this_is": "kept", "entities": { "id1": { "something": "something" } } }, { "this_is": "kept 2", "entities": { "id2": { "something": "something 2" } } } ] }The config will look like:
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array keep_parent: false split: # this time alerts will not exist because previous keep_parent is false target: body.entities type: map keep_parent: true key_field: idThis will output:
[ { "this_is": "kept", "entities": { "id": "id1", "something": "something" } }, { "this_is": "kept 2", "entities": { "id": "id2", "something": "something 2" } } ] -
We have a response with an array with two objects, and we want a document for each of the object keys while applying a transform to each:
{ "this": "is not kept", "alerts": [ { "this_is": "also not kept", "entities": { "id1": { "something": "something" } } }, { "this_is": "also not kept", "entities": { "id2": { "something": "something 2" } } } ] }The config will look like:
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.alerts type: array split: transforms: - set: target: body.new value: will be added to each target: body.entities type: mapThis will output:
[ { "something": "something", "new": "will be added for each" }, { "something": "something 2", "new": "will be added for each" } ] -
We have a response with a keys whose value is a string. We want the string to be split on a delimiter and a document for each sub strings.
{ "this": "is kept", "lines": "Line 1\nLine 2\nLine 3" }The config will look like:
filebeat.inputs: - type: httpjson interval: 1m request.url: https://example.com response.split: target: body.lines type: string delimiter: "\n"This will output:
[ { "this": "is kept", "lines": "Line 1" }, { "this": "is kept", "lines": "Line 2" }, { "this": "is kept", "lines": "Line 3" } ]
chain
editA chain is a list of requests to be made after the first one.
chain[].step
editContains basic request and response configuration for chained calls.
chain[].step.request
editPlease refer request parameters. Required.
Example:
First call: https://example.com/services/data/v1.0/
Second call: https://example.com/services/data/v1.0/1/export_ids
Third call: https://example.com/services/data/v1.0/export_ids/file_1/info
chain[].step.response.split
editPlease refer response split parameter.
chain[].step.replace
editA [JSONPath](JSONPath) string to parse values from responses JSON, collected from previous chain steps. Place same replace string in url where collected values from previous call should be placed. Required.
Example:
filebeat.inputs:
- type: httpjson
enabled: true
# first call
request.url: https://example.com/services/data/v1.0/records
interval: 1h
chain:
# second call
- step:
request.url: https://example.com/services/data/v1.0/$.records[:].id/export_ids
request.method: GET
replace: $.records[:].id
# third call
- step:
request.url: https://example.com/services/data/v1.0/export_ids/$.file_name/info
request.method: GET
replace: $.file_name
Example:
-
First call to collect record ids
request_url: https://example.com/services/data/v1.0/records
response_json:
{ "records": [ { "id": 1, }, { "id": 2, }, { "id": 3, }, ] } -
Second call to collect
file_nameusing collected ids from first call.request_url using id as 1: https://example.com/services/data/v1.0/1/export_ids
response_json using id as 1:
{ "file_name": "file_1" }request_url using id as 2: https://example.com/services/data/v1.0/2/export_ids
response_json using id as 2:
{ "file_name": "file_2" } -
Third call to collect
filesusing collectedfile_namefrom second call.request_url using file_name as file_1: https://example.com/services/data/v1.0/export_ids/file_1/info
request_url using file_name as file_2: https://example.com/services/data/v1.0/export_ids/file_2/info
Collect and make events from response in any format supported by httpjson for all calls.
httpjson chain will only create and ingest events from last call on chained configurations. Also, the current chain only supports the following: request.url, request.method, request.transforms, request.body, response.transforms and response.split.
cursor
editCursor is a list of key value objects where arbitrary values are defined. The values are interpreted as value templates and a default template can be set. Cursor state is kept between input restarts and updated once all the events for a request are published.
Each cursor entry is formed by:
-
A
valuetemplate, which will define the value to store when evaluated. -
A
defaulttemplate, which will define the value to store when the value template fails or is empty. -
An
ignore_empty_valueflag. When set totrue, will not store empty values, preserving the previous one, if any. Default:true.
Can read state from: [.last_response.*, .first_event.*, .last_event.*].
Default templates do not have access to any state, only to functions.
filebeat.inputs:
- type: httpjson
interval: 1m
request.url: https://api.ipify.org/?format=json
response.transforms:
- set:
target: body.last_requested_at
value: '[[.cursor.last_requested_at]]'
default: "[[now]]"
cursor:
last_requested_at:
value: '[[now]]'
processors:
- decode_json_fields:
fields: ["message"]
target: "json"
Request life cycle
edit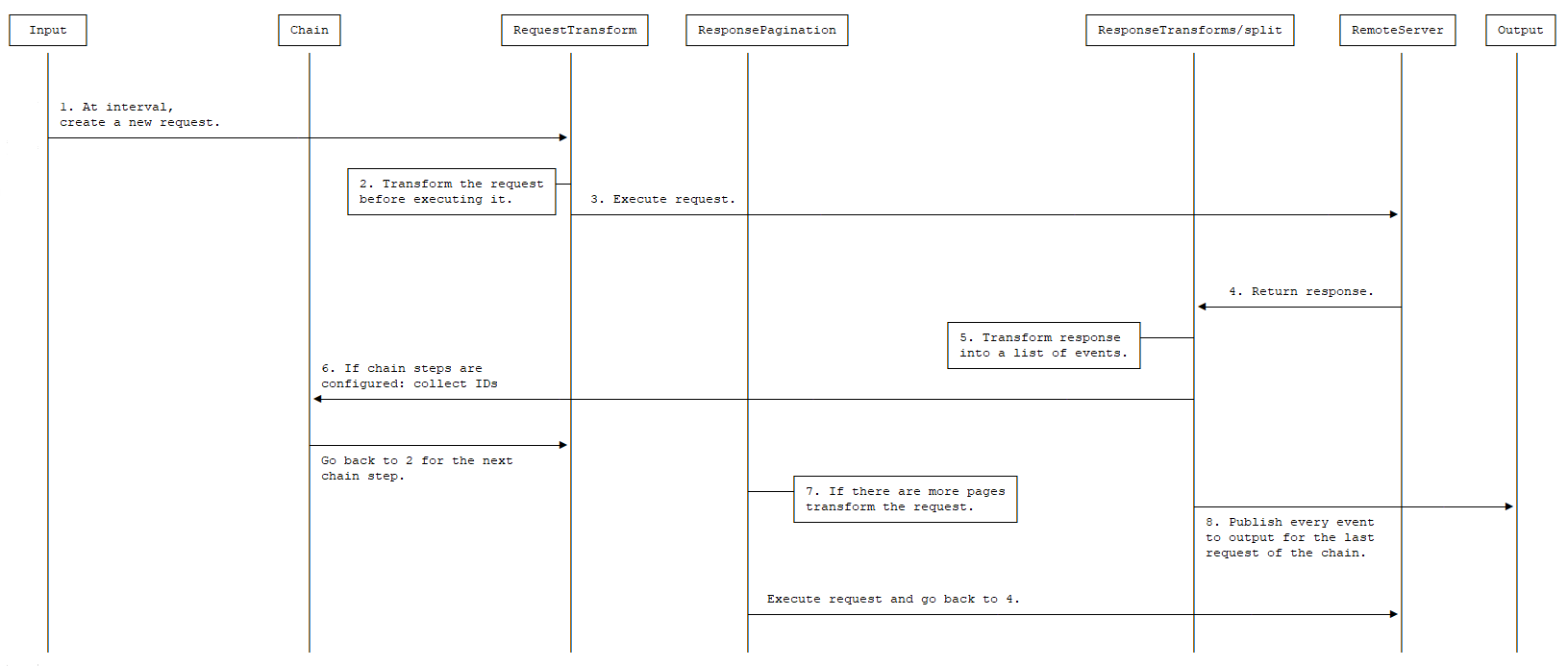
- At every defined interval a new request is created.
-
The request is transformed using the configured
request.transforms. - The resulting transformed request is executed.
- The server responds (here is where any retry or rate limit policy takes place when configured).
-
The response is transformed using the configured
response.transformsandresponse.split. -
If a chain step is configured. Each step will generate new requests based on collected IDs from responses. The requests will be transformed using configured
request.transformsand the resulting generated transformed requests will be executed. This process will happen for all the steps mentioned in the chain. - Each resulting event is published to the output.
-
If a
response.paginationis configured and there are more pages, a new request is created using it, otherwise the process ends until the next interval.

- Response from regular call will be processed.
- Extract data from response and generate new requests from responses.
- Process generated requests and collect responses from server.
- Go back to step-2 for the next step.
- Publish collected responses from the last chain step.
Common options
editThe following configuration options are supported by all inputs.
enabled
editUse the enabled option to enable and disable inputs. By default, enabled is
set to true.
tags
editA list of tags that Filebeat includes in the tags field of each published
event. Tags make it easy to select specific events in Kibana or apply
conditional filtering in Logstash. These tags will be appended to the list of
tags specified in the general configuration.
Example:
filebeat.inputs: - type: httpjson . . . tags: ["json"]
fields
editOptional fields that you can specify to add additional information to the
output. For example, you might add fields that you can use for filtering log
data. Fields can be scalar values, arrays, dictionaries, or any nested
combination of these. By default, the fields that you specify here will be
grouped under a fields sub-dictionary in the output document. To store the
custom fields as top-level fields, set the fields_under_root option to true.
If a duplicate field is declared in the general configuration, then its value
will be overwritten by the value declared here.
filebeat.inputs:
- type: httpjson
. . .
fields:
app_id: query_engine_12
fields_under_root
editIf this option is set to true, the custom
fields are stored as top-level fields in
the output document instead of being grouped under a fields sub-dictionary. If
the custom field names conflict with other field names added by Filebeat,
then the custom fields overwrite the other fields.
processors
editA list of processors to apply to the input data.
See Processors for information about specifying processors in your config.
pipeline
editThe ingest pipeline ID to set for the events generated by this input.
The pipeline ID can also be configured in the Elasticsearch output, but this option usually results in simpler configuration files. If the pipeline is configured both in the input and output, the option from the input is used.
keep_null
editIf this option is set to true, fields with null values will be published in
the output document. By default, keep_null is set to false.
index
editIf present, this formatted string overrides the index for events from this input
(for elasticsearch outputs), or sets the raw_index field of the event’s
metadata (for other outputs). This string can only refer to the agent name and
version and the event timestamp; for access to dynamic fields, use
output.elasticsearch.index or a processor.
Example value: "%{[agent.name]}-myindex-%{+yyyy.MM.dd}" might
expand to "filebeat-myindex-2019.11.01".
publisher_pipeline.disable_host
editBy default, all events contain host.name. This option can be set to true to
disable the addition of this field to all events. The default value is false.