ELSER – Elastic Learned Sparse EncodeR
editELSER – Elastic Learned Sparse EncodeR
editThis functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
Elastic Learned Sparse EncodeR - or ELSER - is a retrieval model trained by Elastic that enables you to perform semantic search to retrieve more relevant search results. This search type provides you search results based on contextual meaning and user intent, rather than exact keyword matches.
ELSER is an out-of-domain model which means it does not require fine-tuning on your own data, making it adaptable for various use cases out of the box.
Tokens - not synonyms
editELSER expands the indexed and searched passages into collections of terms that are learned to co-occur frequently within a diverse set of training data. The terms that the text is expanded into by the model are not synonyms for the search terms; they are learned associations capturing relevance. These expanded terms are weighted as some of them are more significant than others. Then the Elasticsearch rank features field type is used to store the terms and weights at index time, and to search against later.
This approach provides a more understandable search experience compared to vector embeddings. However, attempting to directly interpret the tokens and weights can be misleading, as the expansion essentially results in a vector in a very high-dimensional space. Consequently, certain tokens, especially those with low weight, contain information that is intertwined with other low-weight tokens in the representation. In this regard, they function similarly to a dense vector representation, making it challenging to separate their individual contributions. This complexity can potentially lead to misinterpretations if not carefully considered during analysis.
Requirements
editTo use ELSER, you must have the appropriate subscription level for semantic search or the trial period activated.
The minimum dedicated ML node size for deploying and using the ELSER model is 4 GB in Elasticsearch Service if deployment autoscaling is turned off. Turning on autoscaling is recommended because it allows your deployment to dynamically adjust resources based on demand. Better performance can be achieved by using more allocations or more threads per allocation, which requires bigger ML nodes. Autoscaling provides bigger nodes when required. If autoscaling is turned off, you must provide suitably sized nodes yourself.
Benchmarks
editThe following sections provide information about how ELSER performs on different hardwares and compares the model performance to Elasticsearch BM25 and other strong baselines such as Splade or OpenAI.
Hardware benchmarks
editTwo data sets were utilized to evaluate the performance of ELSER in different
hardware configurations: msmarco-long-light and arguana.
Data set |
Data set size |
Average count of tokens / query |
Average count of tokens / document |
|
37367 documents |
9 |
1640 |
|
8674 documents |
238 |
202 |
The msmarco-long-light data set contains long documents with an average of
over 512 tokens, which provides insights into the performance implications
of indexing and inference time for long documents. This is a subset of the
"msmarco" dataset specifically designed for document retrieval (it shouldn’t be
confused with the "msmarco" dataset used for passage retrieval, which primarily
consists of shorter spans of text).
The arguana data set is a BEIR data set.
It consists of long queries with an average of 200 tokens per query. It can
represent an upper limit for query slowness.
The table below present benchmarking results for ELSER using various hardware configurations.
|
|
||||||
inference |
indexing |
query latency |
inference |
indexing |
query latency |
||
ML node 4GB - 2 vCPUs (1 allocation * 1 thread) |
581 ms/call |
1.7 doc/sec |
713 ms/query |
1200 ms/call |
0.8 doc/sec |
169 ms/query |
|
ML node 16GB - 8 vCPUs (7 allocation * 1 thread) |
568 ms/call |
12 doc/sec |
689 ms/query |
1280 ms/call |
5.4 doc/sec |
159 ms/query |
|
ML node 16GB - 8 vCPUs (1 allocation * 8 thread) |
102 ms/call |
9.7 doc/sec |
164 ms/query |
220 ms/call |
4.5 doc/sec |
40 ms/query |
|
ML node 32 GB - 16 vCPUs (15 allocation * 1 thread) |
565 ms/call |
25.2 doc/sec |
608 ms/query |
1260 ms/call |
11.4 doc/sec |
138 ms/query |
|
Qualitative benchmarks
editThe metric that is used to evaluate ELSER’s ranking ability is the Normalized Discounted Cumulative Gain (NDCG) which can handle multiple relevant documents and fine-grained document ratings. The metric is applied to a fixed-sized list of retrieved documents which, in this case, is the top 10 documents (NDCG@10).
The table below shows the performance of ELSER compared to Elasticsearch BM25 with an English analyzer broken down by the 12 data sets used for the evaluation. ELSER has 10 wins, 1 draw, 1 loss and an average improvement in NDCG@10 of 17%.

NDCG@10 for BEIR data sets for BM25 and ELSER - higher values are better)
The following table compares the average performance of ELSER to some other strong baselines. The OpenAI results are separated out because they use a different subset of the BEIR suite.

Average NDCG@10 for BEIR data sets vs. various high quality baselines (higher is better). OpenAI chose a different subset, ELSER results on this set reported separately.
To read more about the evaluation details, refer to this blog post.
Download and deploy ELSER
editYou can download and deploy ELSER either from Machine Learning > Trained Models, from Enterprise Search > Indices, or by using the Dev Console.
Using the Trained Models page
edit- In Kibana, navigate to Machine Learning > Trained Models. ELSER can be found in the list of trained models.
-
Click the Download model button under Actions. You can check the download status on the Notifications page.
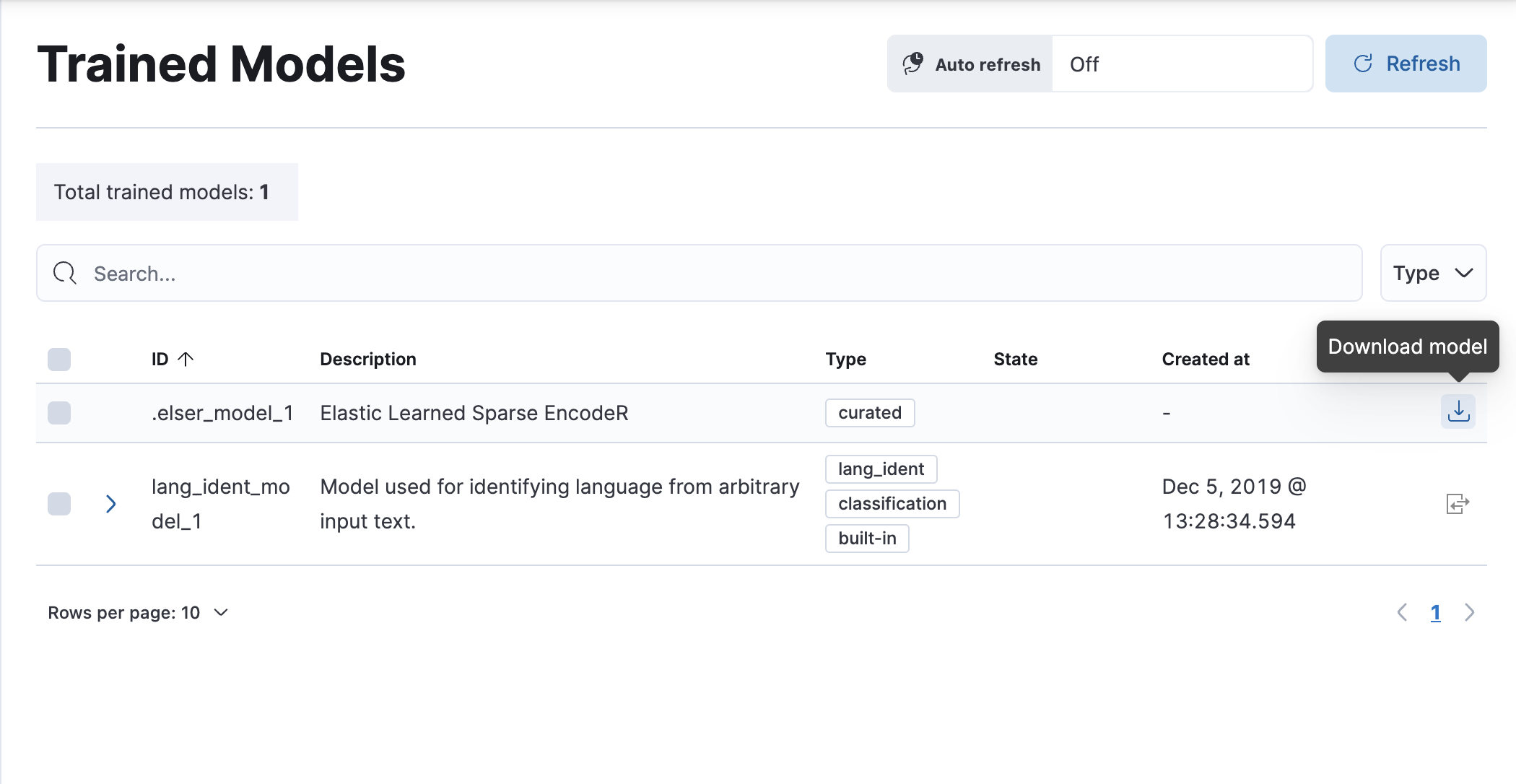
- After the download is finished, start the deployment by clicking the Start deployment button.
-
Provide a deployment ID, select the priority, and set the number of allocations and threads per allocation values.
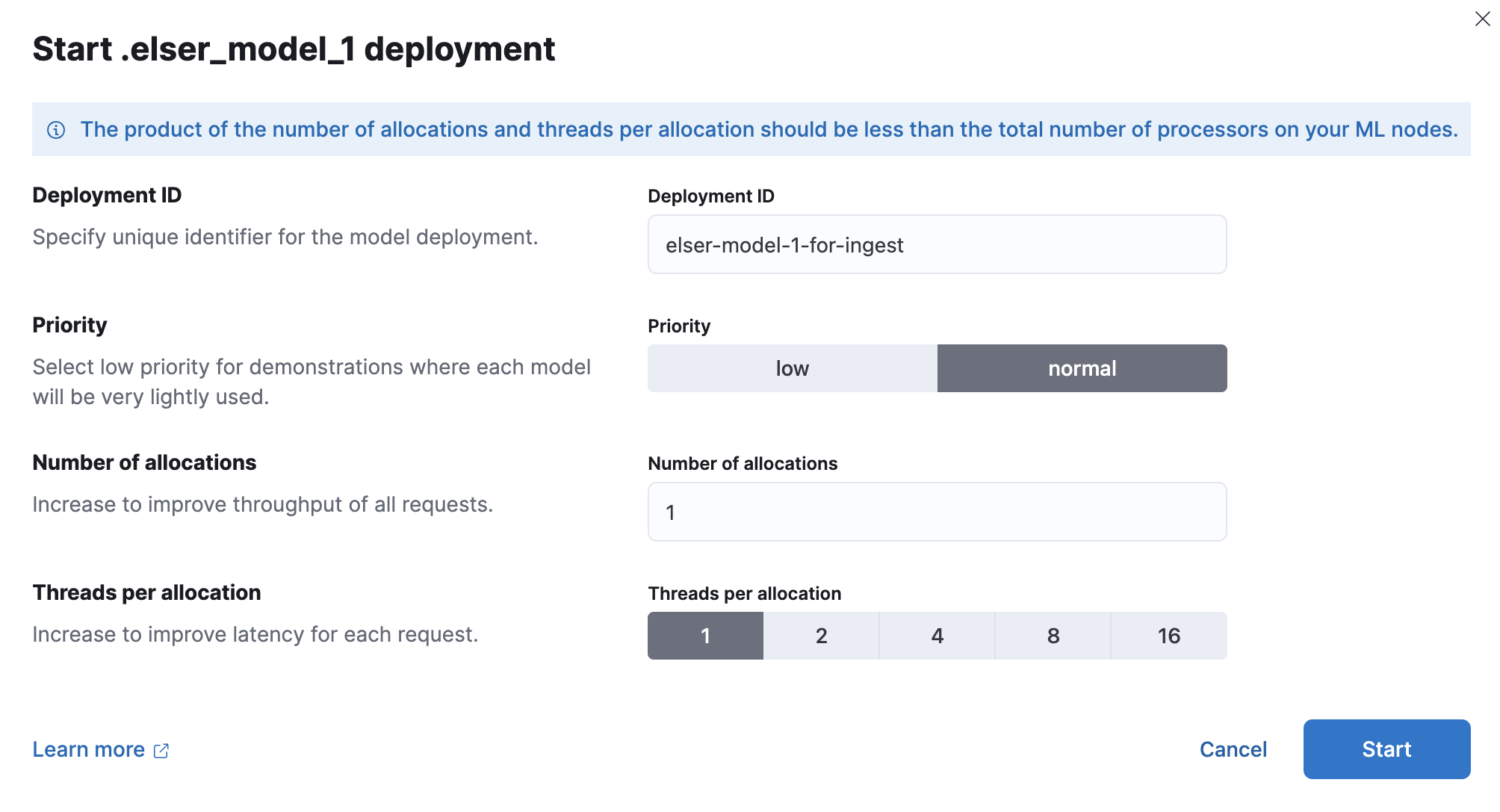
- Click Start.
Using the Indices page in Enterprise Search
editYou can also download and deploy ELSER to an inference pipeline directly from the Enterprise Search app.
- In Kibana, navigate to Enterprise Search > Indices.
- Select the index from the list that has an inference pipeline in which you want to use ELSER.
- Navigate to the Pipelines tab.
- Under Machine Learning Inference Pipelines, click the Deploy button to begin downloading the ELSER model. This may take a few minutes depending on your network. Once it’s downloaded, click the Start single-threaded button to start the model with basic configuration or select the Fine-tune performance option to navigate to the Trained Models page where you can configure the model deployment.
Using the Dev Console
edit- In Kibana, navigate to the Dev Console.
-
Create the ELSER model configuration by running the following API call:
PUT _ml/trained_models/.elser_model_1 { "input": { "field_names": ["text_field"] } }The API call automatically initiates the model download if the model is not downloaded yet.
-
Deploy the model by using the start trained model deployment API with a delpoyment ID:
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=for_search
You can deploy the model multiple times with different deployment IDs.
After the deployment is complete, ELSER is ready to use either in an ingest
pipeline or in a text_expansion query to perform semantic search.
Deploy ELSER in an air-gapped environment
editIf you want to deploy ELSER in a restricted or closed network, you have two options:
- create your own HTTP/HTTPS endpoint with the model artifacts on it,
- put the model artifacts into a directory inside the config directory on all master-eligible nodes.
You need the following files in your system:
https://ml-models.elastic.co/elser_model_1.metadata.json https://ml-models.elastic.co/elser_model_1.pt https://ml-models.elastic.co/elser_model_1.vocab.json
Using an HTTP server
editINFO: If you use an existing HTTP server, note that the model downloader only supports passwordless HTTP servers.
You can use any HTTP service to deploy ELSER. This example uses the official Nginx Docker image to set a new HTTP download service up.
- Download the model artifact files from https://ml-models.elastic.co/.
- Put the files into a subdirectory of your choice.
-
Run the following commands:
export ELASTIC_ML_MODELS="/path/to/models" docker run --rm -d -p 8080:80 --name ml-models -v ${ELASTIC_ML_MODELS}:/usr/share/nginx/html nginxDon’t forget to change
/path/to/modelsto the path of the subdirectory where the model artifact files are located.These commands start a local Docker image with an Nginx server with the subdirectory containing the model files. As the Docker image has to be downloaded and built, the first start might take a longer period of time. Subsequent runs start quicker.
-
Verify that Nginx runs properly by visiting the following URL in your browser:
http://{IP_ADDRESS_OR_HOSTNAME}:8080/elser_model_1.metadata.jsonIf Nginx runs properly, you see the content of the metdata file of the model.
-
Point your Elasticsearch deployment to the model artifacts on the HTTP server by adding the following line to the
config/elasticsearch.ymlfile:xpack.ml.model_repository: http://{IP_ADDRESS_OR_HOSTNAME}:8080If you use your own HTTP or HTTPS server, change the address accordingly. It is important to specificy the protocol ("http://" or "https://"). Ensure that all master-eligible nodes can reach the server you specify.
- Repeat step 5 on all master-eligible nodes.
- Restart the master-eligible nodes one by one.
The HTTP server is only required for downloading the model. After the download has finished, you can stop and delete the service. You can stop the Docker image used in this example by running the following command:
docker stop ml-models
Using file-based access
editFor a file-based access, follow these steps:
- Download the model artifact files from https://ml-models.elastic.co/.
-
Put the files into a
modelssubdirectory inside theconfigdirectory of your Elasticsearch deployment. -
Point your Elasticsearch deployment to the model directory by adding the following line to the
config/elasticsearch.ymlfile:xpack.ml.model_repository: file://${path.home}/config/models/` - Repeat step 2 and step 3 on all master-eligible nodes.
- Restart the master-eligible nodes one by one.