Pipeline Viewer UI
editPipeline Viewer UI
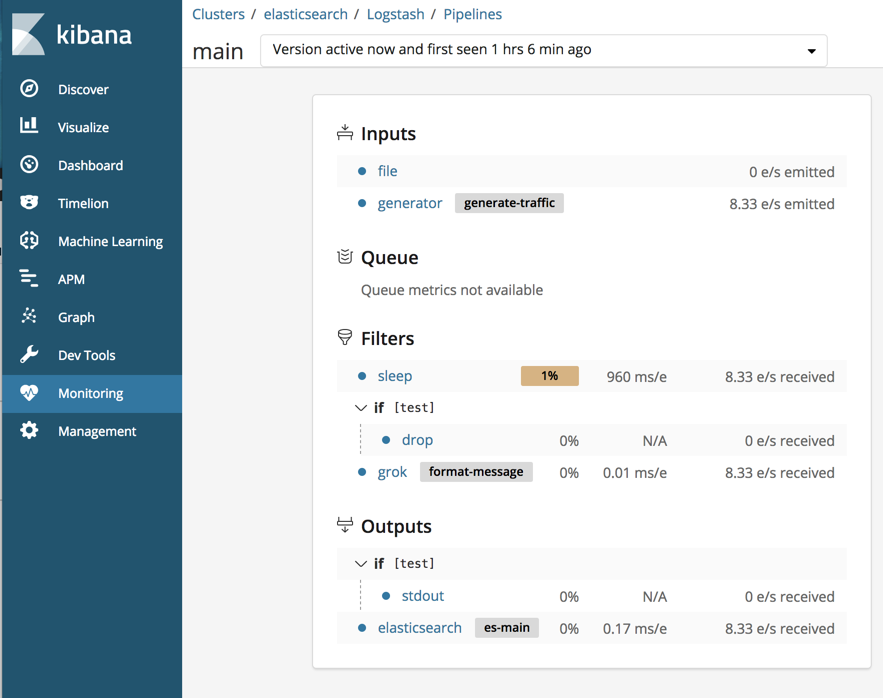
editThe pipeline viewer UI offers additional visibility into the behavior and performance of complex pipeline configurations. Use the pipeline viewer to visualize and monitor the behavior of complex Logstash pipeline configurations. You can see and interact with a tree view that illustrates the pipeline topology, data flow, and branching logic.
The pipeline viewer highlights CPU% and event latency in cases where the values are anomalous. This information helps you quickly identify processing that is disproportionately slow.
Prerequisites
editBefore using the pipeline viewer:
- Configure Logstash monitoring.
- Start the Logstash pipeline that you want to monitor.
Logstash begins shipping metrics to the monitoring cluster.
View the pipeline
editTo view the pipeline:
- Kibana → Monitoring → Logstash → Pipelines
Each pipeline is identified by a pipeline ID (main by default). For each
pipeline, you see the pipeline’s throughput and the number
of nodes on which the pipeline is running during the selected time range.
Many elements in the tree are clickable. For example, you can click the plugin name to expand the detail view.
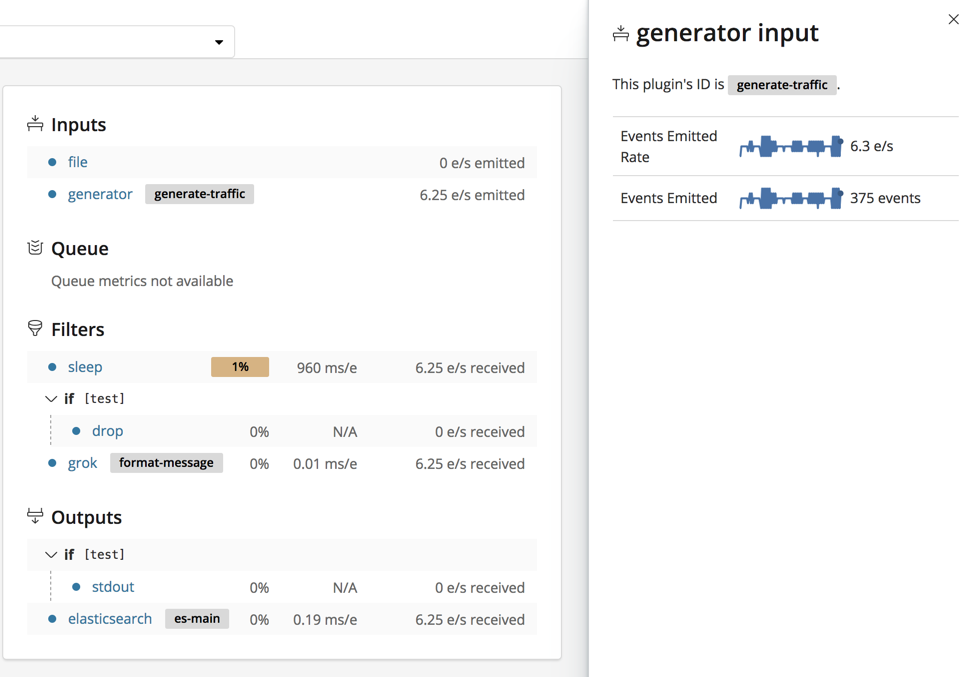
Click the arrow beside a branch name to collapse or expand it.
Notes and best practices
editUse semantic IDs.
Specify semantic IDs when you configure the stages in your Logstash pipeline.
Otherwise, Logstash generates them for you. Semantic IDs help you identify
configurations that are causing bottlenecks. For example, you may have several
grok filters running in your pipeline. If you have specified semantic IDs, you
can tell at a glance which filters are slow. Semantic IDs, such as
apacheParsingGrok and cloudwatchGrok, point you to the grok filters that are
causing bottlenecks.
Outliers. Values and stats that are anomalously slow or otherwise out of line are highlighted. This doesn’t necessarily indicate a problem, but it highlights potential bottle necks so that you can find them quickly.
Some plugins are slower than others due to the nature of the work they do. For instance, you may find that a grok filter that uses a complicated regexp runs a lot slower than a mutate filter that simply adds a field. The grok filter might be highlighted in this case, though it may not be possible to further optimize its work.
Versioning. Version information is available from the dropdown list beside the pipeline ID. Logstash generates a new version each time you modify a pipeline, and stores multiple versions of the pipeline stats. Use this information to see how changes over time affect throughput and other metrics. Logstash does not store multiple versions of the pipeline configurations.