Transactions
editTransactions
editA transaction describes an event captured by an Elastic APM agent instrumenting a service. APM agents automatically collect performance metrics on HTTP requests, database queries, and much more.
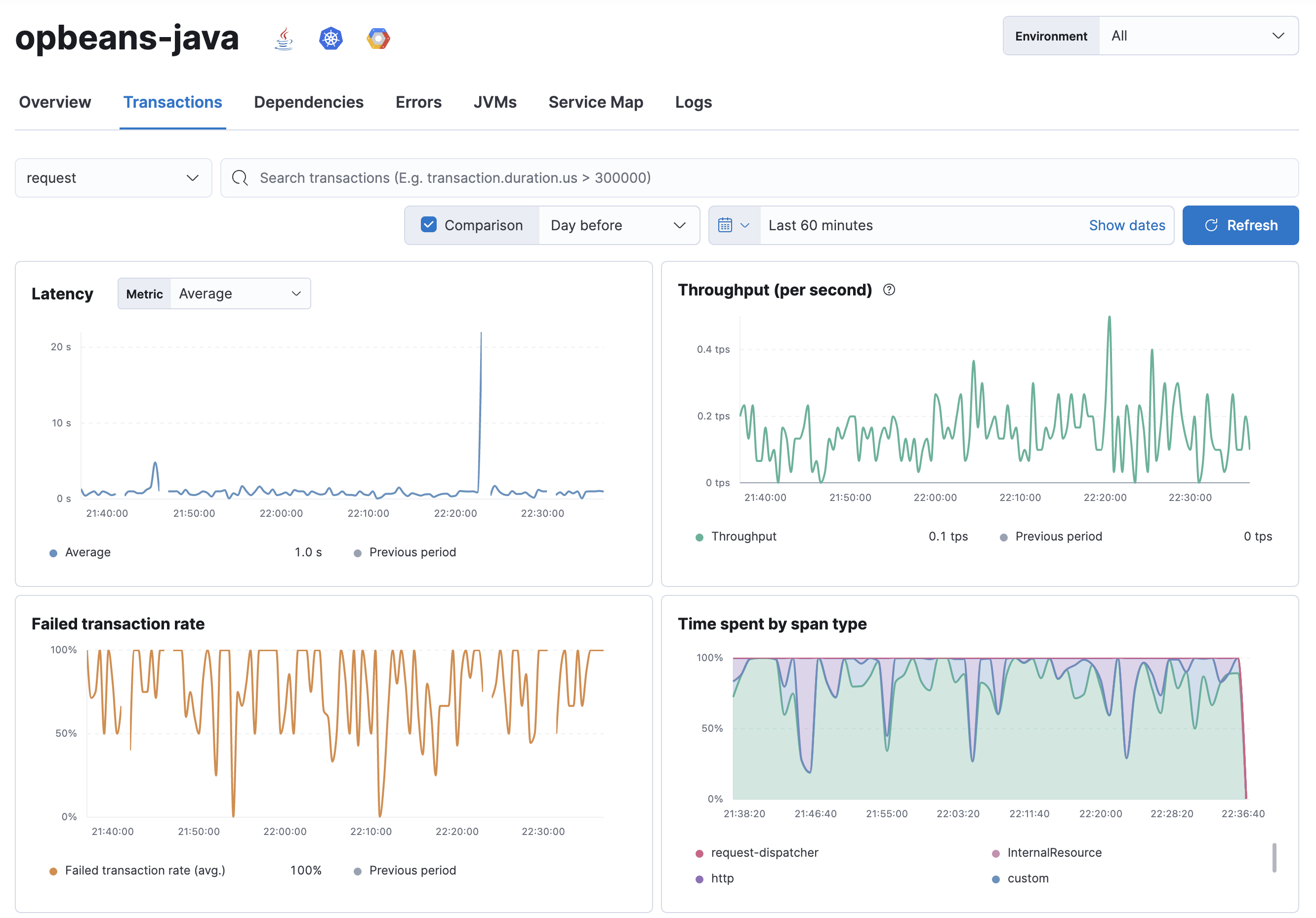
The Latency, transactions per minute, Failed transaction rate, and Average duration by span type charts display information on all transactions associated with the selected service:
- Latency
- Response times for the service. Options include average, 95th, and 99th percentile. If there’s a weird spike that you’d like to investigate, you can simply zoom in on the graph - this will adjust the specific time range, and all of the data on the page will update accordingly.
- Throughput
-
Visualize response codes:
2xx,3xx,4xx, etc. Useful for determining if more responses than usual are being served with a particular response code. Like in the latency graph, you can zoom in on anomalies to further investigate them.
- Failed transaction rate
-
The failed transaction rate represents the percentage of failed transactions from the perspective of the selected service. It’s useful for visualizing unexpected increases, decreases, or irregular patterns in a service’s transactions.
HTTP transactions from the HTTP server perspective do not consider a
4xxstatus code (client error) as a failure because the failure was caused by the caller, not the HTTP server. Thus,event.outcome=successand there will be no increase in failed transaction rate.HTTP spans from the client perspective however, are considered failures if the HTTP status code is ≥ 400. These spans will set
event.outcome=failureand increase the failed transaction rate.If there is no HTTP status, both transactions and spans are considered successful unless an error is reported.
- Average duration by span type
-
Visualize where your application is spending most of its time. For example, is your app spending time in external calls, database processing, or application code execution?
The time a transaction took to complete is also recorded and displayed on the chart under the "app" label. "app" indicates that something was happening within the application, but we’re not sure exactly what. This could be a sign that the agent does not have auto-instrumentation for whatever was happening during that time.
It’s important to note that if you have asynchronous spans, the sum of all span times may exceed the duration of the transaction.
Transactions table
editThe Transactions table displays a list of transaction groups for the selected service. In other words, this view groups all transactions of the same name together, and only displays one entry for each group.
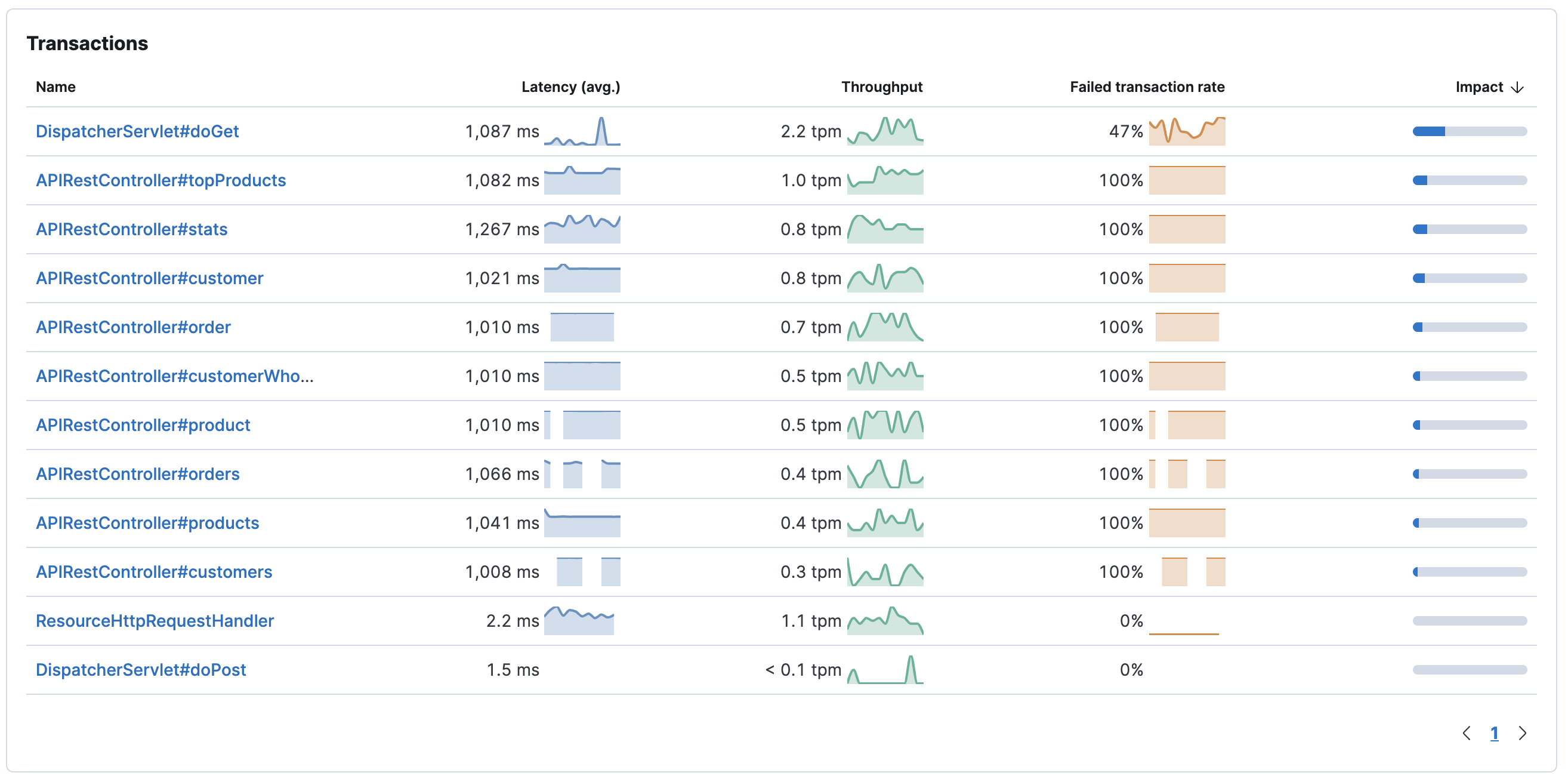
By default, transaction groups are sorted by Impact. Impact helps show the most used and slowest endpoints in your service - in other words, it’s the collective amount of pain a specific endpoint is causing your users. If there’s a particular endpoint you’re worried about, you can click on it to view the transaction details.
If you only see one route in the Transactions table, or if you have transactions named "unknown route", it could be a symptom that the agent either wasn’t installed correctly or doesn’t support your framework.
For further details, including troubleshooting and custom implementation instructions, refer to the documentation for each APM Agent you’ve implemented.
RUM Transaction overview
editThe transaction overview page is customized for the JavaScript RUM Agent. Specifically, the page highlights page load times for your service:
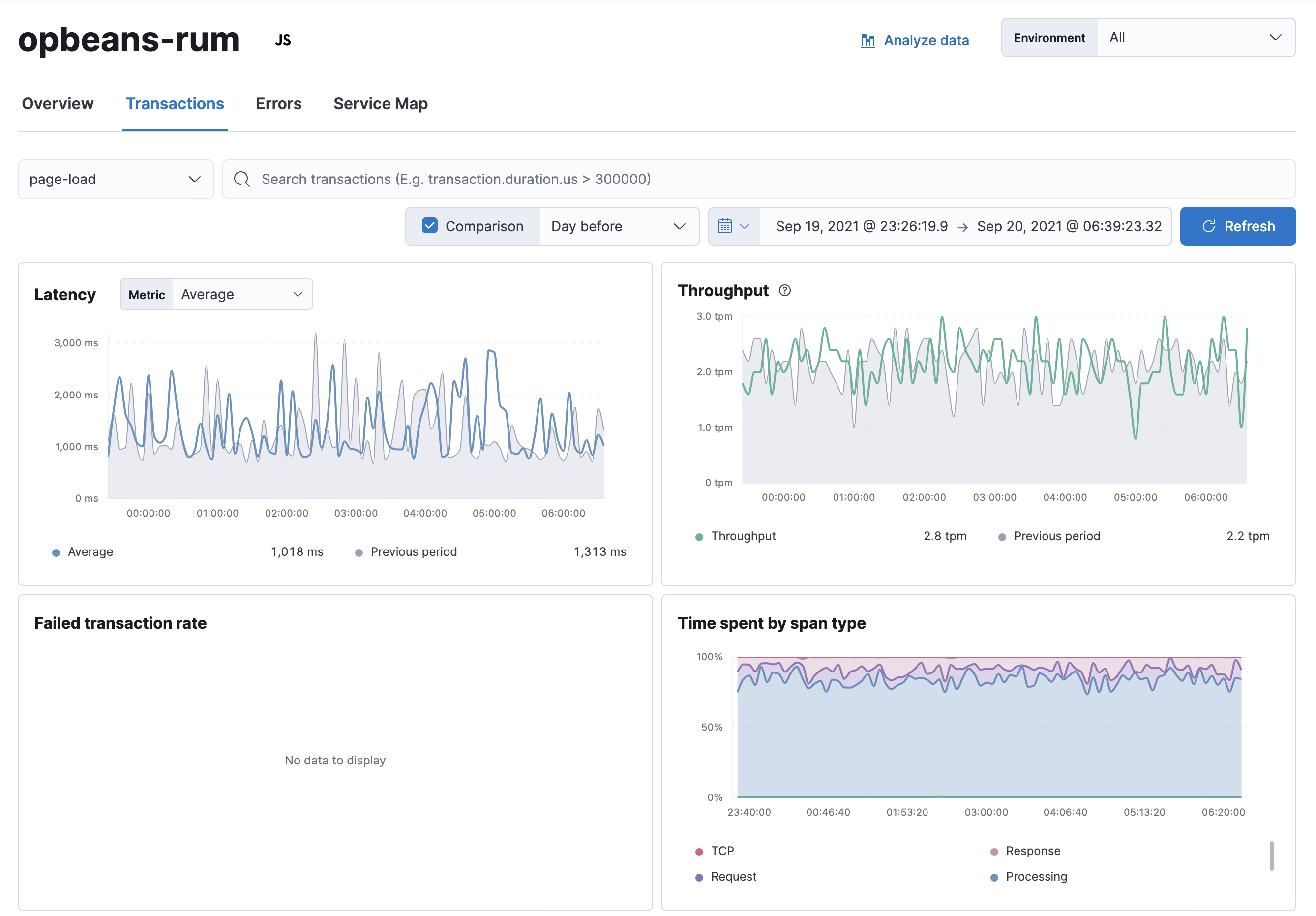
Additional RUM goodies, like core vitals, and visitor breakdown by browser, location, and device, are available in the Observability User Experience tab.
Transaction details
editSelecting a transaction group will bring you to the transaction details. This page is visually similar to the transaction overview, but it shows data from all transactions within the selected transaction group.
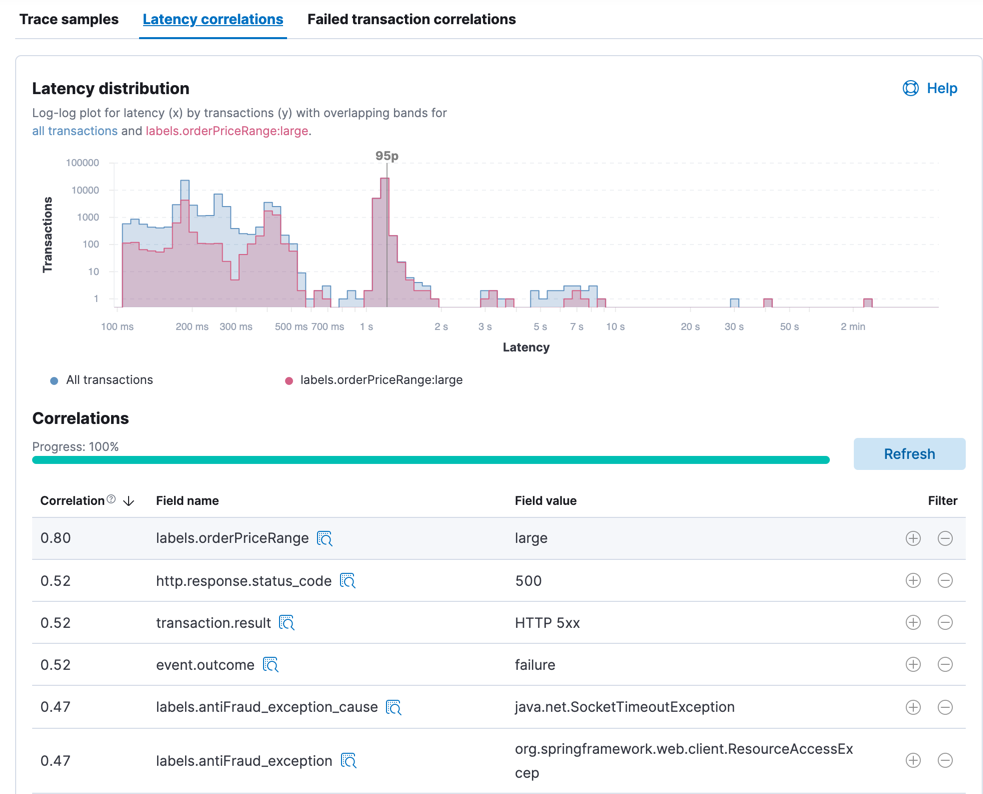
Latency distribution
editA plot of all transaction durations for the given time period. The screenshot below shows a typical distribution, and indicates most of our requests were served quickly — awesome! It’s the requests on the right, the ones taking longer than average, that we probably need to focus on.
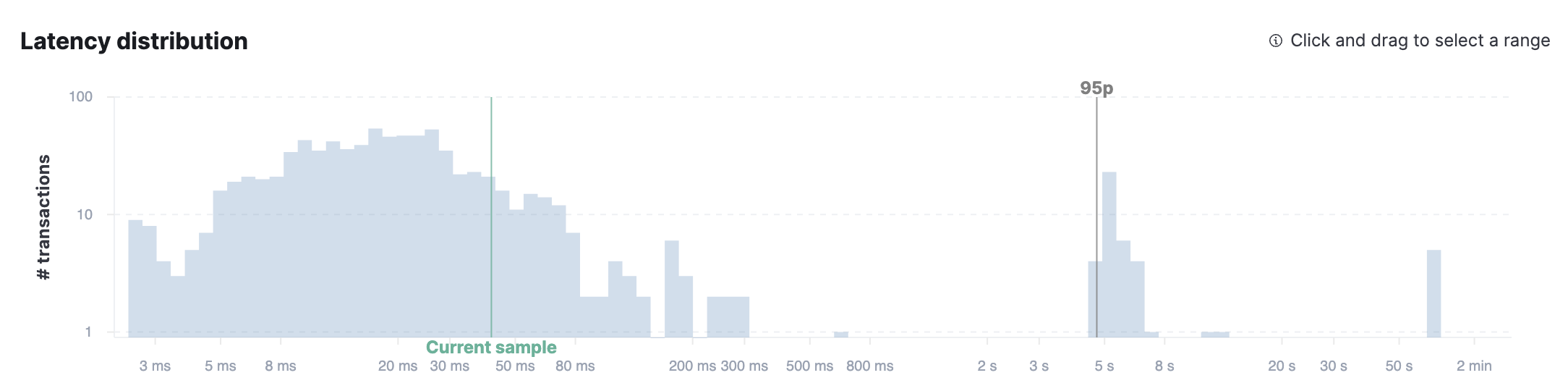
Click and drag to select a latency duration bucket to display up to 500 trace samples.
Trace samples
editTrace samples are based on the bucket selection in the Latency distribution chart; update the samples by selecting a new bucket. The number of requests per bucket is displayed when hovering over the graph, and the selected bucket is highlighted to stand out.
Each bucket presents up to ten trace samples in a timeline, trace sample metadata, and any related logs.
Trace sample timeline
Each sample has a trace timeline waterfall that shows how a typical request in that bucket executed. This waterfall is useful for understanding the parent/child hierarchy of transactions and spans, and ultimately determining why a request was slow. For large waterfalls, expand problematic transactions and collapse well-performing ones for easier problem isolation and troubleshooting.
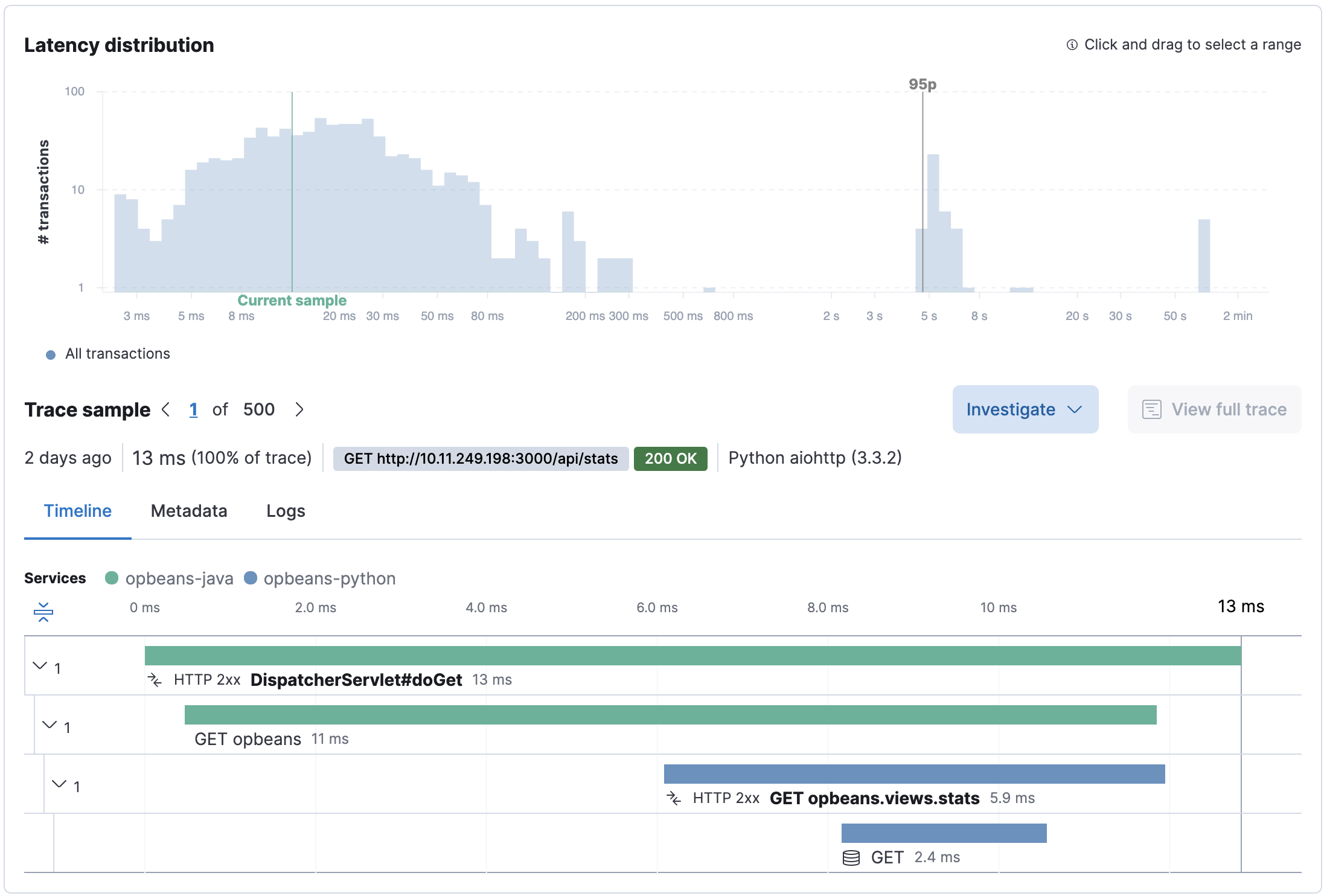
More information on timeline waterfalls is available in spans.
Trace sample metadata
Learn more about a trace sample in the Metadata tab:
- Labels - Custom labels added by agents
- HTTP request/response information
- Host information
- Container information
- Service - The service/application runtime, agent, name, etc..
- Process - The process id that served up the request.
- Agent information
- URL
- User - Requires additional configuration, but allows you to see which user experienced the current transaction.
All of this data is stored in documents in Elasticsearch. This means you can select "Actions - View transaction in Discover" to see the actual Elasticsearch document under the discover tab.
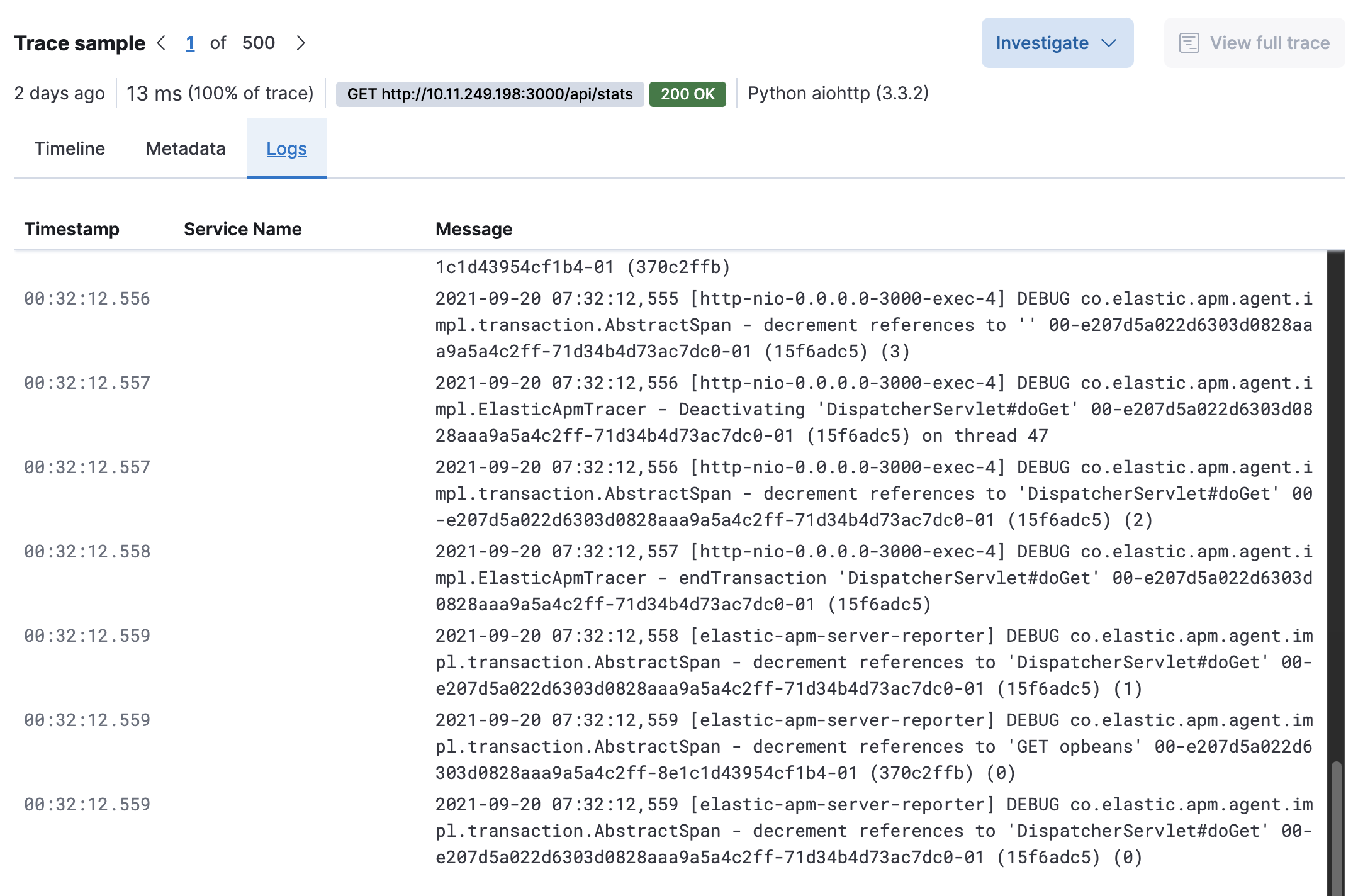
Trace sample logs
The Logs tab displays logs related to the sampled trace.
Logs provide detailed information about specific events, and are crucial to successfully debugging slow or erroneous transactions.
If you’ve correlated your application’s logs and traces, you never have to search for relevant data; it’s all provided on this. Viewing log and trace data together allows you to quickly diagnose and solve problems.
Correlations
editCorrelations surface attributes of your data that are potentially correlated with high-latency or erroneous transactions. To learn more, see Find transaction latency and failure correlations.