Define processors
editDefine processors
editElastic Agent processors are lightweight processing components that you can use to parse, filter, transform, and enrich data at the source. For example, you can use processors to:
- reduce the number of exported fields
- enhance events with additional metadata
- perform additional processing and decoding
- sanitize data
Each processor receives an event, applies a defined action to the event, and returns the event. If you define a list of processors, they are executed in the order they are defined.
event -> processor 1 -> event1 -> processor 2 -> event2 ...
Elastic Agent processors execute before ingest pipelines, which means that your processor configurations cannot refer to fields that are created by ingest pipelines or Logstash. For more limitations, refer to What are some limitations of using processors?
Where are processors valid?
editThe processors described in this section are valid:
-
Under integration settings in the Integrations UI in Kibana. For example, when configuring an Nginx integration, you can define processors for a specific dataset under Advanced options. The processor in this example adds geo metadata to the Nginx access logs collected by Elastic Agent:
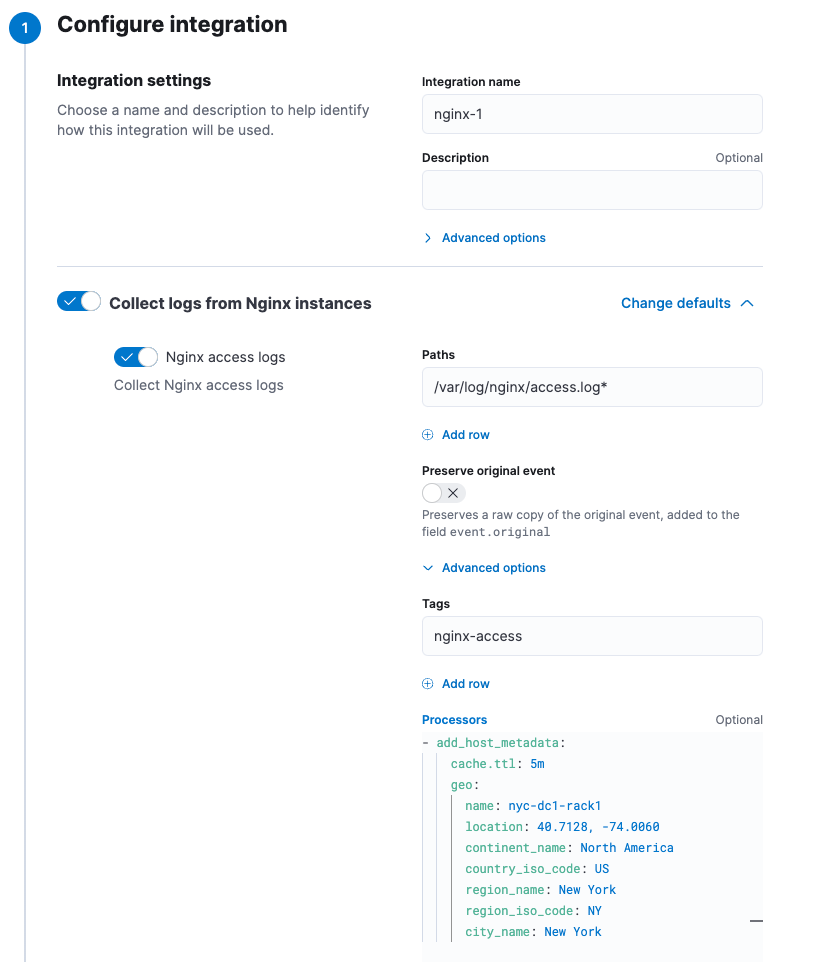
Some integrations do not currently support processors.
-
Under input configuration settings for standalone Elastic Agents. For example:
inputs: - type: logfile use_output: default data_stream: namespace: default streams: - data_stream: dataset: nginx.access type: logs ignore_older: 72h paths: - /var/log/nginx/access.log* tags: - nginx-access exclude_files: - .gz$ processors: - add_host_metadata: cache.ttl: 5m geo: name: nyc-dc1-rack1 location: '40.7128, -74.0060' continent_name: North America country_iso_code: US region_name: New York region_iso_code: NY city_name: New York - add_locale: null
You can define processors that apply to a specific input defined in the configuration. Applying a processor to all the inputs on a global basis is currently not supported.
What are some limitations of using processors?
editProcessors have the following limitations.
- Cannot enrich events with data from Elasticsearch or other custom data sources.
- Cannot process data after it’s been converted to the Elastic Common Schema (ECS) because the conversion is performed by Elasticsearch ingest pipelines. This means that your processor configuration cannot refer to fields that are created by ingest pipelines or Logstash because those fields are created after the processor runs, not before.
- May break integration ingest pipelines in Elasticsearch if the user-defined processing removes or alters fields expected by ingest pipelines.
-
If you create new fields via processors, you are responsible for setting up
field mappings in the
*-@customcomponent template and making sure the new mappings are aligned with ECS.
What other options are available for processing data?
editThe Elastic Stack provides several options for processing data collected by Elastic Agent. The option you choose depends on what you need to do:
| If you need to… | Do this… |
|---|---|
Sanitize or enrich raw data at the source |
Use an Elastic Agent processor |
Convert data to ECS, normalize field data, or enrich incoming data |
Use ingest pipelines |
Define or alter the schema at query time |
Use runtime fields |
Do something else with your data |
Use Logstash plugins |
How are Elastic Agent processors different from Logstash plugins or ingest pipelines?
editLogstash plugins and ingest pipelines both require you to send data to another system for processing. Processors, on the other hand, allow you to apply processing logic at the source. This means that you can filter out data you don’t want to send across the connection, and you can spread some of the processing load across host systems running on edge nodes.