Near real-time search
editNear real-time search
editThe overview of documents and indices indicates that when a document is stored in Elasticsearch, it is indexed and fully searchable in near real-time--within 1 second. What defines near real-time search?
Lucene, the Java libraries on which Elasticsearch is based, introduced the concept of per-segment search. A segment is similar to an inverted index, but the word index in Lucene means "a collection of segments plus a commit point". After a commit, a new segment is added to the commit point and the buffer is cleared.
Sitting between Elasticsearch and the disk is the filesystem cache. Documents in the in-memory indexing buffer (Figure 4) are written to a new segment (Figure 5). The new segment is written to the filesystem cache first (which is cheap) and only later is it flushed to disk (which is expensive). However, after a file is in the cache, it can be opened and read just like any other file.
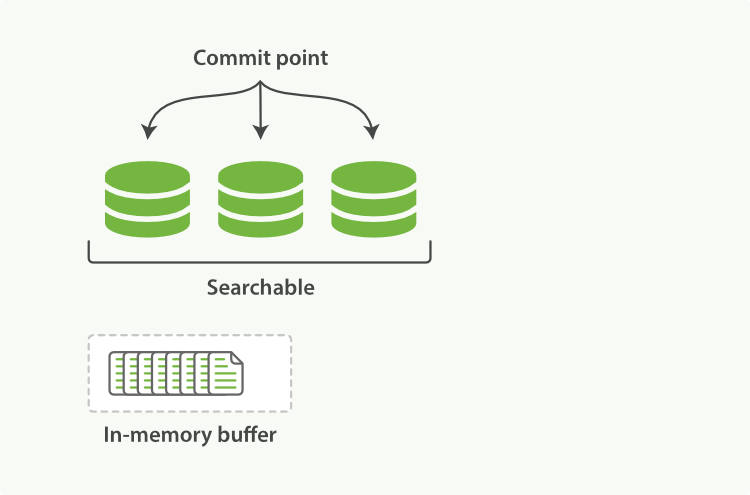
Lucene allows new segments to be written and opened, making the documents they contain visible to search without performing a full commit. This is a much lighter process than a commit to disk, and can be done frequently without degrading performance.
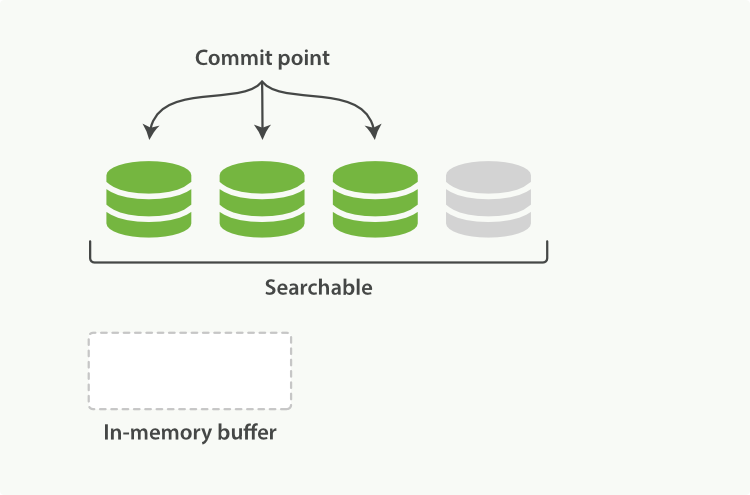
In Elasticsearch, this process of writing and opening a new segment is called a refresh. A refresh makes all operations performed on an index since the last refresh available for search. You can control refreshes through the following means:
- Waiting for the refresh interval
- Setting the ?refresh option
-
Using the Refresh API to explicitly complete a refresh (
POST _refresh)
By default, Elasticsearch periodically refreshes indices every second, but only on indices that have received one search request or more in the last 30 seconds. This is why we say that Elasticsearch has near real-time search: document changes are not visible to search immediately, but will become visible within this timeframe.