Transform overview
editTransform overview
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
You can use transforms to pivot your data into a new entity-centric index. By transforming and summarizing your data, it becomes possible to visualize and analyze it in alternative and interesting ways.
A lot of Elasticsearch indices are organized as a stream of events: each event is an individual document, for example a single item purchase. Transforms enable you to summarize this data, bringing it into an organized, more analysis-friendly format. For example, you can summarize all the purchases of a single customer.
Transforms enable you to define a pivot, which is a set of features that transform the index into a different, more digestible format. Pivoting results in a summary of your data in a new index.
To define a pivot, first you select one or more fields that you will use to group your data. You can select categorical fields (terms) and numerical fields for grouping. If you use numerical fields, the field values are bucketed using an interval that you specify.
The second step is deciding how you want to aggregate the grouped data. When using aggregations, you practically ask questions about the index. There are different types of aggregations, each with its own purpose and output. To learn more about the supported aggregations and group-by fields, see Transform resources.
As an optional step, you can also add a query to further limit the scope of the aggregation.
The transform performs a composite aggregation that paginates through all the data defined by the source index query. The output of the aggregation is stored in a destination index. Each time the transform queries the source index, it creates a checkpoint. You can decide whether you want the transform to run once (batch transform) or continuously (continuous transform). A batch transform is a single operation that has a single checkpoint. Continuous transforms continually increment and process checkpoints as new source data is ingested.
ExampleImagine that you run a webshop that sells clothes. Every order creates a document that contains a unique order ID, the name and the category of the ordered product, its price, the ordered quantity, the exact date of the order, and some customer information (name, gender, location, etc). Your dataset contains all the transactions from last year.
If you want to check the sales in the different categories in your last fiscal year, define a transform that groups the data by the product categories (women’s shoes, men’s clothing, etc.) and the order date. Use the last year as the interval for the order date. Then add a sum aggregation on the ordered quantity. The result is an entity-centric index that shows the number of sold items in every product category in the last year.
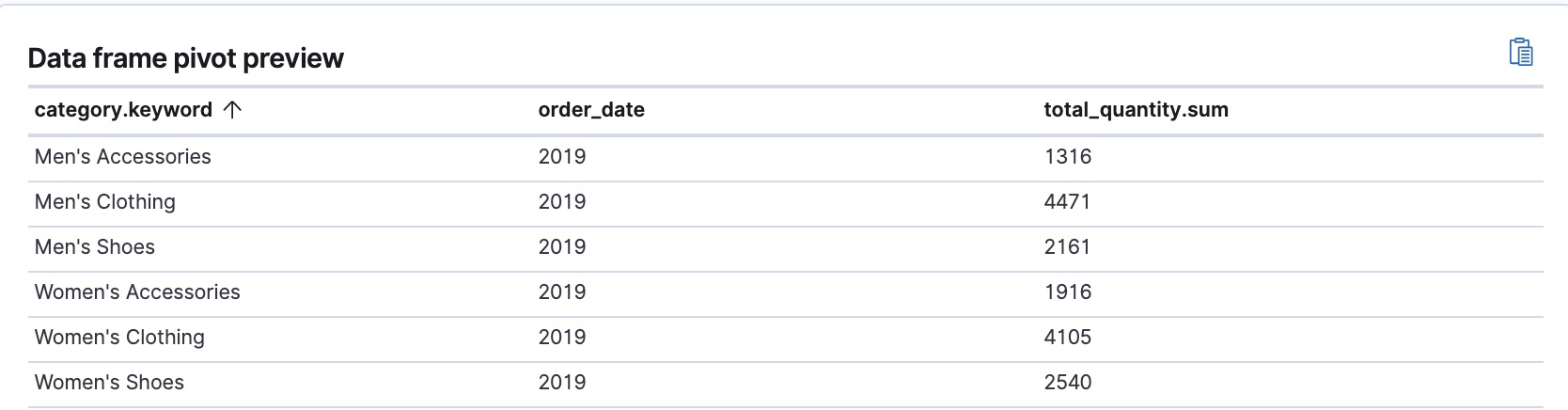
The transform leaves your source index intact. It creates a new index that is dedicated to the transformed data.