WARNING: Version 2.1 has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Usage
editUsage
editElasticsearch on YARN allows through the command-line to provision, start, monitor and stop an Elasticsearch cluster inside a YARN environment.
Simply download elasticsearch-yarn-<version>.jar in a location of choice and make sure to have Hadoop/YARN available and configured in your classpath; double check through the hadoop version command:
$ hadoop version Hadoop 2.4.1 Subversion http://svn.apache.org/repos/asf/hadoop/common -r 1604318 Compiled by jenkins on 2014-06-21T05:43Z Compiled with protoc 2.5.0 From source with checksum bb7ac0a3c73dc131f4844b873c74b630 This command was run using /opt/share/hadoop/common/hadoop-common-2.4.1.jar
Once you have confirmed Hadoop is properly configured, do a basic sanity check for Elasticsearch on YARN by invoking hadoop jar:
$ hadoop jar elasticsearch-yarn-<version>.jar
No command specified
Usage:
-download-es : Downloads Elasticsearch.zip
-install : Installs/Provisions Elasticsearch-YARN into HDFS
-install-es : Installs/Provisions Elasticsearch into HDFS
-start : Starts provisioned Elasticsearch in YARN
-status : Reports status of Elasticsearch in YARN
-stop : Stops Elasticsearch in YARN
-help : Prints this help
Configuration options can be specified _after_ each command; see the documentation for more information.
Each command should be self-explanatory. The typical usage scenario is:
Download the Elasticsearch version needed
editThis is a one-time action; if you already have Elasticsearch at hand, deploy it under downloads sub-folder. To wit:
$ hadoop jar elasticsearch-yarn-<version> -download-es Downloading Elasticsearch 1.6.0 Downloading ...........................................................................DONE
If you want to use a different version of Elasticsearch, you can specify so through the es.version parameter (see the Configuration section.
(Optional) Configuring Elasticsearch
editIf the default Elasticsearch is not suitable, for example certain plugins need to be installed or the storage path needs to be defined as mentioned here, one should do so by modifying the Elasticsearch archive as it will serve as the blueprint of all nodes installed within YARN.
Provision Elasticsearch into HDFS
editNow that we have downloaded Elasticsearch, let us upload it into HDFS so it becomes available to the Hadoop nodes. This is another one-time action (as long as your HDFS cluster and the target location remain in place):
$ hadoop jar elasticsearch-yarn-<version>.jar -install-es Uploaded /opt/es-yarn/downloads/elasticsearch-<version>.zip to HDFS at hdfs://127.0.0.1:50463/apps/elasticsearch/elasticsearch-<version>.zip
This command uploads the elasticsearch-<version>.zip (that we just downloaded) to HDFS (based on the Hadoop configuration detected in the classpath) under /apps/elasticsearch folder. Again the location can be changed if needed.
Note that the uploaded ZIP can be configured accordingly to your setup - for example, one can include her own configuration (such as using a certain storage location) to override the defaults or for example certain plugins. The zip acts as a template so be sure to include everything that need in it.
Provision Elasticsearch-YARN into HDFS
editLet us do the same one-time command with the Elasticsearch-YARN jar:
$ hadoop jar elasticsearch-yarn-<version>.jar -install Uploaded opt/es-yarn/elasticsearch-yarn-<version>.jar to HDFS at hdfs://127.0.0.1:50463/apps/elasticsearch/elasticsearch-yarn-<version>.jar
You can verify the provisioning by interrogating HDFS either through the web console or hadoop CLI:
$ hadoop fs -ls /apps/elasticsearch Found 2 items -rw-r--r-- 1 hdfs hdfs 30901787 2014-11-13 10:17 /apps/elasticsearch/elasticsearch-<version>.zip -rw-r--r-- 1 hdfs hdfs 52754 2014-11-13 16:16 /apps/elasticsearch/elasticsearch-yarn-<version>.jar
Start Elasticsearch on YARN
editOnce the necessary artifacts are in HDFS, one can start Elasticsearch:
$ hadoop jar elasticsearch-yarn-<version>.jar -start Launched a 1 node Elasticsearch-YARN cluster [application_1415813090693_0001@http://hadoop:8088/proxy/application_1415921358606_0001/] at Wed Nov 14 19:24:53 EET 2014
By default only a single node is created; to start multiple nodes use the containers parameter (see Configuration for more information):
$ hadoop jar elasticsearch-yarn-<version>.jar -start containers=2 Launched a 2 nodes Elasticsearch-YARN cluster [application_1415921358606_0006@http://hadoop:8088/proxy/application_1415921358606_0006/] at Wed Nov 14 19:28:46 EET 2014
That’s it!
Get status of Elasticsearch clusters in YARN
editThere are plenty of tools in Hadoop to check running YARN applications; with Elasticsearch YARN try the -status command:
$ hadoop jar elasticsearch-yarn-<version>.jar -status Id State Status Start Time Finish Time Tracking URL application_1415921358606_0007 RUNNING UNDEFINED 11/14/14 19:34 PM N/A http://hadoop:8088/proxy/application_1415921358606_0007/A
If you prefer the web ui, point your browser to the cluster console (typically on port 8088 - http://hadoop:8088/cluster) and the newly created Elasticsearch cluster, or rather
its ApplicationMaster will show up:
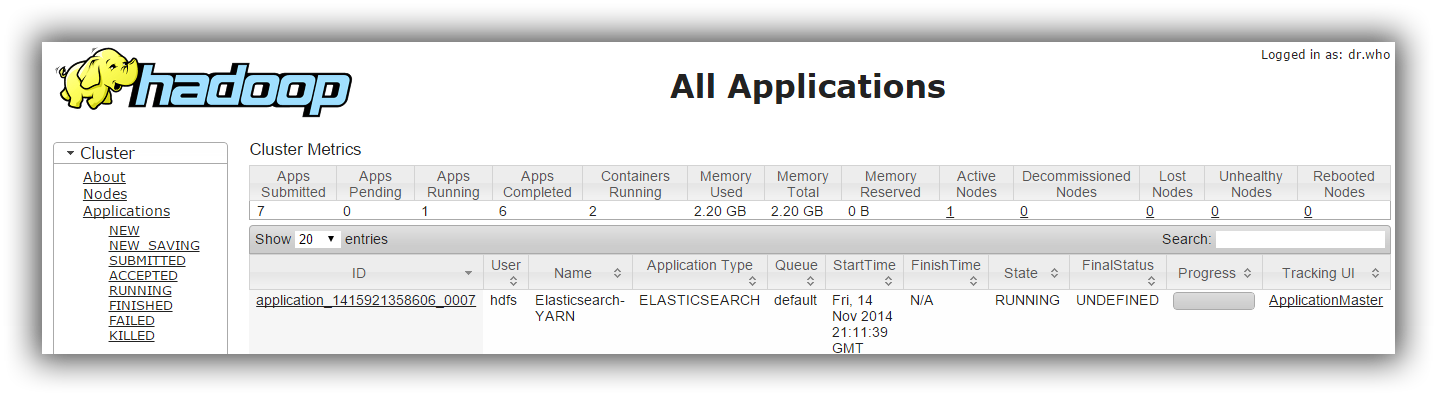
One can inspect the containers manually by checking the container list (typically by accessing the ApplicationManager UI):
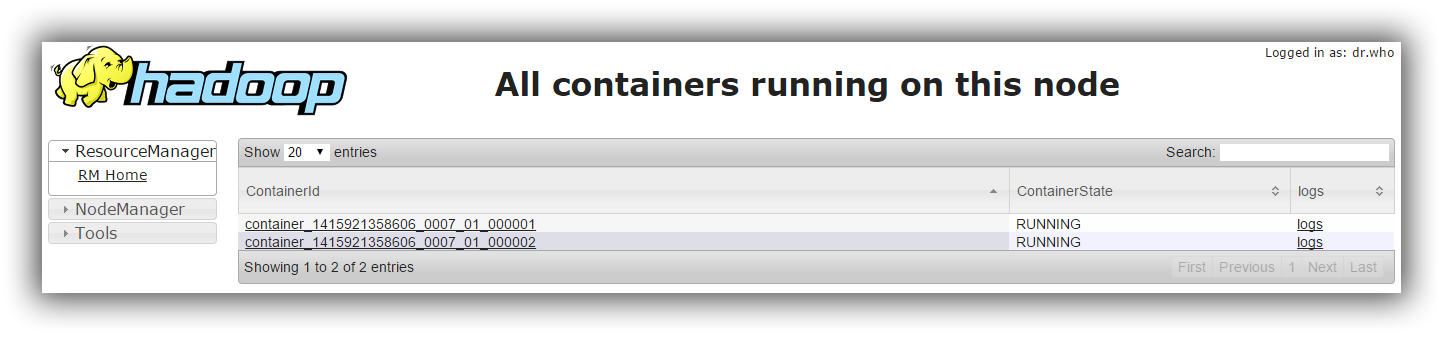
You should be able to see the application and the associated containers marked as RUNNING ; if that is not the case, check out the logs to see what is wrong.
Stop Elasticsearch clusters in YARN
editTo shutdown your cluster, use the -stop command:
$ hadoop jar elasticsearch-yarn-<version>.jar -stop Stopped Elasticsearch-YARN cluster with id application_1415921358606_0007
Configuration
editElasticsearch on YARN offers various knobs for tweaking its behavior - all can be passed as options after each command, overriding the default configuration. Multiple options can be specified (if you specify the same parameter multiple times, the last one wins):
$ hadoop jar elasticsearch-yarn-<version>.jar [-command] [option.name]=[option.value] [option.name]=[option.value]
The following parameter are available:
-
download.local.dir(default ./downloads/) -
Local folder where Elasticsearch on YARN downloads remote artifacts (like
Elasticsearch.zip) -
hdfs.upload.dir(default /apps/elasticsearch/) - HDFS folder used for provisioning
-
es.version(default 1.6.0) - Elasticsearch version used for downloading, provisioning HDFS and running on the YARN cluster
-
containers(default 1) - The number of containers or Elasticsearch nodes for starting the cluster
-
container.mem(default 2048) - Memory requested for each YARN container
-
container.vcores(default 1) - CPU cores requested for each YARN container
-
container.priority(default -1) - YARN queue priority for each container
-
env.<NAME> -
Pattern for setting up environment variables on each container - each property starting with
env.prefix will be set remotely on each container:
$ hadoop jar elasticsearch-yarn-<version>.jar [-command] env.ES_USE_GC_LOGGING=true env.PROP=someValue
Sets up on each container two variables ES_USE_GC_LOGGING and PROP.
-
loadConfig - Property file to be loaded as configuration. That is, instead of specifying the options in each command, save them to a file and use that instead. For example the above example, the two options (for setting the container environment variables) can be moved into a properties file
# extra-cfg.properties env.ES_USE_GC_LOGGING=true env.PROP=someValue
and tell Elasticsearch on YARN to load it:
$ hadoop jar elasticsearch-yarn-<version>.jar [-command] loadConfig=extra-cfg.properties