WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Shard Overallocation
editShard Overallocation
editA shard lives on a single node, but a node can hold multiple shards. Imagine that we created our index with two primary shards instead of one:
With a single node, both shards would be assigned to the same node. From the point of view of our application, everything functions as it did before. The application communicates with the index, not the shards, and there is still only one index.
This time, when we add a second node, Elasticsearch will automatically move one shard from the first node to the second node, as depicted in Figure 50, “An index with two shards can take advantage of a second node”. Once the relocation has finished, each shard will have access to twice the computing power that it had before.
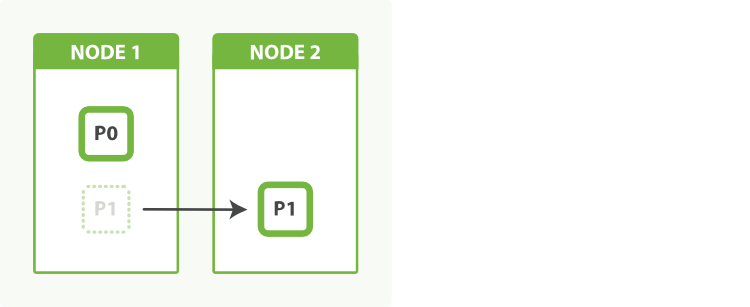
We have been able to double our capacity by simply copying a shard across the network to the new node. The best part is, we achieved this with zero downtime. All indexing and search requests continued to function normally while the shard was being moved.
A new index in Elasticsearch is allotted five primary shards by default. That means that we can spread that index out over a maximum of five nodes, with one shard on each node. That’s a lot of capacity, and it happens without you having to think about it at all!