WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Near Real-Time Search
editNear Real-Time Search
editWith the development of per-segment search, the delay between indexing a document and making it visible to search dropped dramatically. New documents could be made searchable within minutes, but that still isn’t fast enough.
The bottleneck is the disk. Commiting a new segment to disk requires an
fsync to ensure that the segment is
physically written to disk and that data will not be lost if there is a power
failure. But an fsync is costly; it cannot be performed every time a
document is indexed without a big performance hit.
What was needed was a more lightweight way to make new documents visible to
search, which meant removing fsync from the equation.
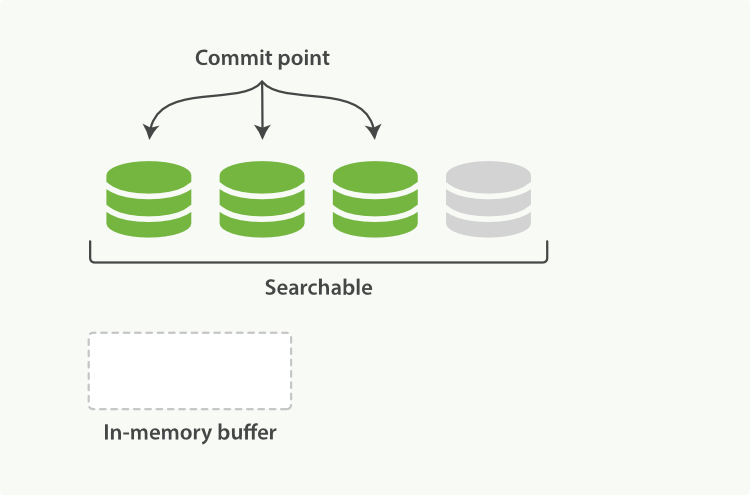
Sitting between Elasticsearch and the disk is the filesystem cache. As before, documents in the in-memory indexing buffer (Figure 19, “A Lucene index with new documents in the in-memory buffer”) are written to a new segment (Figure 20, “The buffer contents have been written to a segment, which is searchable, but is not yet commited”). But the new segment is written to the filesystem cache first—which is cheap—and only later is it flushed to disk—which is expensive. But once a file is in the cache, it can be opened and read, just like any other file.
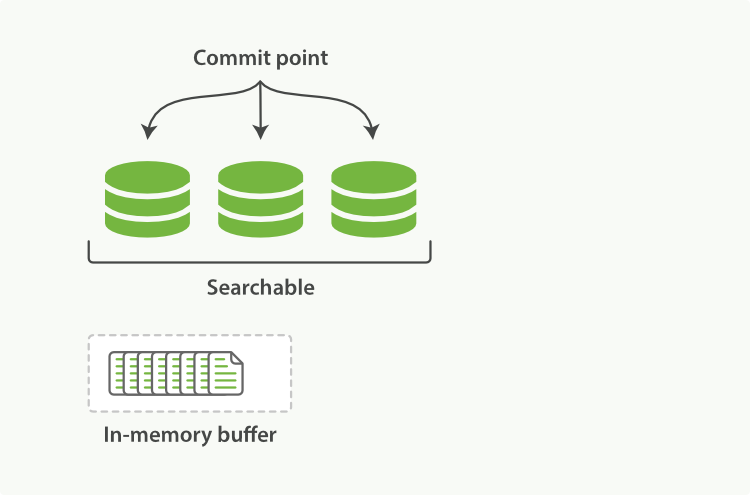
Lucene allows new segments to be written and opened—making the documents they contain visible to search—without performing a full commit. This is a much lighter process than a commit, and can be done frequently without ruining performance.
refresh API
editIn Elasticsearch, this lightweight process of writing and opening a new segment is called a refresh. By default, every shard is refreshed automatically once every second. This is why we say that Elasticsearch has near real-time search: document changes are not visible to search immediately, but will become visible within 1 second.
This can be confusing for new users: they index a document and try to search
for it, and it just isn’t there. The way around this is to perform a manual
refresh, with the refresh API:
While a refresh is much lighter than a commit, it still has a performance cost. A manual refresh can be useful when writing tests, but don’t do a manual refresh every time you index a document in production; it will hurt your performance. Instead, your application needs to be aware of the near real-time nature of Elasticsearch and make allowances for it.
Not all use cases require a refresh every second. Perhaps you are using
Elasticsearch to index millions of log files, and you would prefer to optimize
for index speed rather than near real-time search. You can reduce the
frequency of refreshes on a per-index basis by setting the refresh_interval:
The refresh_interval can be updated dynamically on an existing index. You
can turn off automatic refreshes while you are building a big new index, and then turn them back on when you start using the index in production:
PUT /my_logs/_settings
{ "refresh_interval": -1 }
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
The refresh_interval expects a duration such as 1s (1
second) or 2m (2 minutes). An absolute number like 1 means
1 millisecond--a sure way to bring your cluster to its knees.