本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
多文档模式
edit多文档模式
editmget 和 bulk API 的模式类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中。
它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端,如 Figure 12, “使用 mget 取回多个文档” 所示。
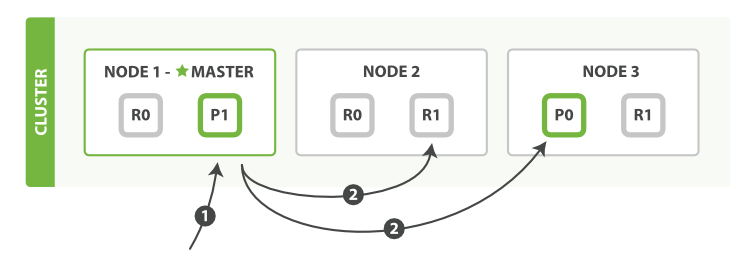
mget 取回多个文档以下是使用单个 mget 请求取回多个文档所需的步骤顺序:
-
客户端向
Node 1发送mget请求。 -
Node 1为每个分片构建多文档获取请求,然后并行转发这些请求到托管在每个所需的主分片或者副本分片的节点上。一旦收到所有答复,Node 1构建响应并将其返回给客户端。
可以对 docs 数组中每个文档设置 routing 参数。
bulk API, 如 Figure 13, “使用 bulk 修改多个文档” 所示, 允许在单个批量请求中执行多个创建、索引、删除和更新请求。
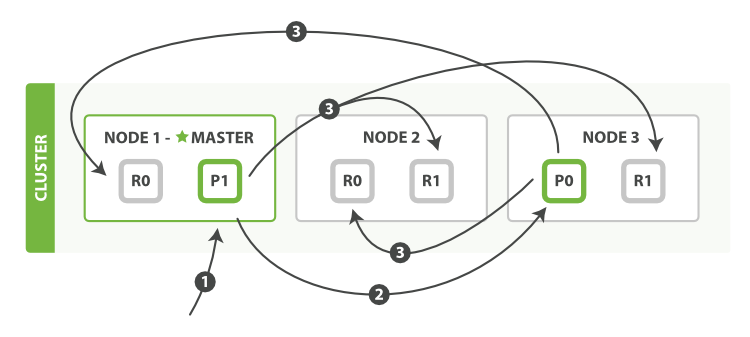
bulk 修改多个文档bulk API 按如下步骤顺序执行:
-
客户端向
Node 1发送bulk请求。 -
Node 1为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。 - 主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。 一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端。
bulk API 还可以在整个批量请求的最顶层使用 consistency 参数,以及在每个请求中的元数据中使用 routing 参数。
为什么是有趣的格式?
edit当我们早些时候在代价较小的批量操作章节了解批量请求时,您可能会问自己,
"为什么 bulk API 需要有换行符的有趣格式,而不是发送包装在 JSON 数组中的请求,例如 mget API?" 。
为了回答这一点,我们需要解释一点背景:在批量请求中引用的每个文档可能属于不同的主分片,
每个文档可能被分配给集群中的任何节点。这意味着批量请求 bulk 中的每个 操作 都需要被转发到正确节点上的正确分片。
如果单个请求被包装在 JSON 数组中,那就意味着我们需要执行以下操作:
- 将 JSON 解析为数组(包括文档数据,可以非常大)
- 查看每个请求以确定应该去哪个分片
- 为每个分片创建一个请求数组
- 将这些数组序列化为内部传输格式
- 将请求发送到每个分片
这是可行的,但需要大量的 RAM 来存储原本相同的数据的副本,并将创建更多的数据结构,Java虚拟机(JVM)将不得不花费时间进行垃圾回收。
相反,Elasticsearch可以直接读取被网络缓冲区接收的原始数据。
它使用换行符字符来识别和解析小的 action/metadata 行来决定哪个分片应该处理每个请求。
这些原始请求会被直接转发到正确的分片。没有冗余的数据复制,没有浪费的数据结构。整个请求尽可能在最小的内存中处理。