WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Coping with Failure
editCoping with Failure
editWe’ve said that Elasticsearch can cope when nodes fail, so let’s go ahead and try it out. If we kill the first node, our cluster looks like Figure 6, “Cluster after killing one node”.
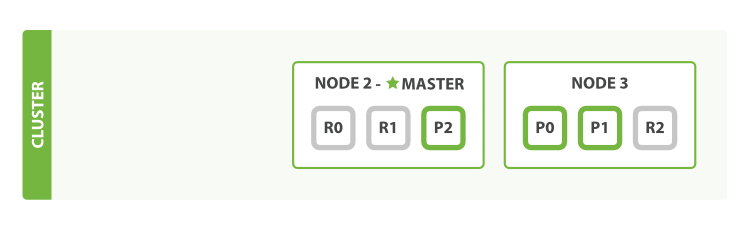
The node we killed was the master node. A cluster must have a master node in
order to function correctly, so the first thing that happened was that the
nodes elected a new master: Node 2.
Primary shards 1 and 2 were lost when we killed Node 1, and our index
cannot function properly if it is missing primary shards. If we had checked
the cluster health at this point, we would have seen status red: not all
primary shards are active!
Fortunately, a complete copy of the two lost primary shards exists on other
nodes, so the first thing that the new master node did was to promote the
replicas of these shards on Node 2 and Node 3 to be primaries, putting us
back into cluster health yellow. This promotion process was instantaneous,
like the flick of a switch.
So why is our cluster health yellow and not green? We have all three primary
shards, but we specified that we wanted two replicas of each primary, and
currently only one replica is assigned. This prevents us from reaching
green, but we’re not too worried here: were we to kill Node 2 as well, our
application could still keep running without data loss, because Node 3
contains a copy of every shard.
If we restart Node 1, the cluster would be able to allocate the missing
replica shards, resulting in a state similar to the one described in
Figure 5, “Increasing the number_of_replicas to 2”. If Node 1 still has copies of the old
shards, it will try to reuse them, copying over from the primary shard
only the files that have changed in the meantime.
By now, you should have a reasonable idea of how shards allow Elasticsearch to scale horizontally and to ensure that your data is safe. Later we will examine the life cycle of a shard in more detail.