Utilisez un modèle NLP en langue japonaise dans Elasticsearch pour permettre les recherches sémantiques


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Trouver rapidement les documents nécessaires dans un grand volume de documents et d'informations produits internes généré tous les jours est une tâche extrêmement importante aussi bien dans la vie professionnelle que personnelle. Toutefois, s'il existe un grand volume de documents dans lesquels effectuer des recherches, le fait de relire tous les documents en temps réel et de trouver le fichier cible est un processus qui peut s'avérer chronophage, même pour les ordinateurs. C'est dans ce contexte que sont apparus Elasticsearch® et d'autres logiciels de moteur de recherche. Lorsqu'un moteur de recherche est utilisé, des données d'index de recherche sont d'abord créées afin que les termes de recherche clés inclus dans les documents puissent être utilisés pour retrouver rapidement ces documents.
Toutefois, même si l'utilisateur possède une idée générale du type d'information qu'il recherche, il peut ne pas se souvenir de mots-clés qui conviennent, ou rechercher une autre expression ayant la même signification. Elasticsearch permet aux synonymes et aux termes similaires d'être définis de sorte à gérer ces situations, mais dans certains cas, il peut être difficile d'utiliser simplement un tableau de correspondances pour convertir une requête de recherche en une requête qui convient davantage.
Pour répondre à ce besoin, Elasticsearch 8.0 a publié la fonctionnalité de recherche vectorielle, qui recherche par contenu sémantique d'une expression. En plus de cela, nous possédons également une série d'articles de blog sur comment utiliser Elasticsearch pour réaliser des recherches vectorielles et autres tâches de NLP. Toutefois, avant la publication de la version 8.8, il n'était pas possible d'analyser correctement du texte dans des langues autres que l'anglais.
Avec la version 8.9, Elastic a ajouté une fonctionnalité permettant d'analyser correctement le japonais dans le traitement d'analyse de texte. Cette fonctionnalité permet à Elasticsearch de réaliser des recherches sémantiques comme une recherche vectorielle sur du texte japonais, ainsi que des tâches de traitement du langage naturel comme l'analyse des sentiments en japonais. Dans cet article, nous fournirons des instructions spécifiques étape par étape concernant l'utilisation de ces fonctionnalités.
Prérequis
Avant de mettre en œuvre la recherche sémantique, confirmez les prérequis d'utilisation de cette fonctionnalité. Dans les clusters Elasticsearch, des rôles de nœuds sont attribués à des rôles individuels. Pendant ce temps, les nœuds de Machine Learning Elasticsearch sont ce qui pilote le modèle de Machine Learning. Pour utiliser cette fonctionnalité, un nœud de Machine Learning doit être actif dans le cluster Elasticsearch, assurez-vous donc de confirmer en avance que tel est le cas. Vous devez également posséder une licence Platinum ou supérieure pour utiliser les nœuds de Machine Learning. Toutefois, une licence d'essai peut être utilisée si vous souhaitez uniquement tester les fonctionnalités et vous assurer qu'elles fonctionnent. Pour vérifier la fonctionnalité opérationnelle dans un environnement de développement ou une instance similaire, activez l'essai sur l'écran Kibana® ou via l'API.
Processus d'exécution d'une recherche sémantique
Les étapes suivantes sont nécessaires pour exécuter une recherche sémantique dans Elasticsearch.
(Préparation) Installez Eland et les bibliothèques associées sur le poste de travail.
Importez le modèle de Machine Learning pour activer les tâches de traitement du langage naturel.
Indexez les résultats de l'analyse de texte dans le modèle de Machine Learning importé.
Lancez une recherche des k plus proches voisins à l'aide du modèle de Machine Learning.
La recherche sémantique n'est pas la seule chose que permet le traitement du langage naturel. Dans la seconde partie de cet article de blog, nous présenterons des exemples de la façon dont le modèle de Machine Learning peut être utilisé, qui permet de réaliser des tâches de classification de textes, afin d'effectuer une analyse des sentiments du texte (catégories positives et négatives).
Nous allons maintenant expliquer en profondeur comment réaliser les tâches suivantes.
Installation d'Eland
Elasticsearch est désormais capable de se comporter comme une plateforme de traitement du langage naturel. Toutefois, il n'existe en réalité aucun traitement du langage naturel en profondeur qui soit réellement mis en œuvre dans Elasticsearch. Tout traitement du langage naturel nécessaire doit être importé dans Elasticsearch par l'utilisateur en tant que modèle de Machine Learning. Ce processus d'importation est réalisé à l'aide d'Eland. Puisque les utilisateurs peuvent importer librement un modèle externe de cette façon, ils peuvent ajouter la fonctionnalité de Machine Learning dont ils ont besoin dès qu'ils en ont besoin.
Eland est une bibliothèque Python fournie par Elastic, qui permet aux utilisateurs d'associer des données Elasticsearch à des bibliothèques complètes de Machine Learning Python comme PyTorch et scikit-learn. L'outil de ligne de commande eland_import_hub_model groupé avec Eland peut servir à importer dans Elasticsearch des modèles de NPL ayant été publiés sur Hugging Face. Toutes les tâches de ligne de commande couvertes ci-dessous dans cet article supposent l'utilisation d'un bloc-notes Python comme Google Colaboratory. (Naturellement, d'autres types de terminaux peuvent également être utilisés, comme une machine Mac ou Linux. Dans ces cas-là, ignorez le ! au début des commandes ci-dessous.)
Commencez par installer les bibliothèques indépendantes.
!pip install torch==1.13
!pip install transformers
!pip install sentence_transformers
!pip install fugashi
!pip install ipadic
!pip install unidic_liteFugashi, ipadic et unidic_lite seront nécessaires pour utiliser un modèle japonais.
Une fois ces bibliothèques installées, Eland peut également être installé. Eland 8.9.0 ou une version supérieure sera nécessaire pour utiliser un modèle japonais, assurez-vous donc de noter le numéro de la version.
!pip install elandUne fois l'installation terminée, utilisez la commande ci-dessous pour confirmer qu'Eland peut être utilisé.
!eland_import_hub_model -h
Importation du modèle NLP
La méthode principale d'activation de la recherche vectorielle est la même que celle utilisée en anglais dans cet article. Nous couvrirons brièvement la même procédure ici pour la réviser.
Comme expliqué ci-dessus, le bon modèle de Machine Learning doit être importé dans Elasticsearch pour pouvoir activer le traitement du NLP dans Elasticsearch. Il est possible de mettre vous-même en œuvre un modèle de Machine Learning à l'aide de PyTorch, mais cela nécessite également une expertise suffisante avec le Machine Learning et le traitement du langage naturel, ainsi que la puissance informatique que requiert le Machine Learning. Toutefois, il existe désormais un référentiel en ligne, Hugging Face, fortement utilisé par les chercheurs et les développeurs dans les espaces de Machine Learning et de traitement du langage naturel, et de nombreux modèles y sont publiés. Dans cet exemple, nous utiliserons un modèle publié sur Hugging Face pour mettre en œuvre la fonctionnalité de recherche sémantique.
Pour commencer, choisissons un modèle sur Hugging Face qui intégrera (vectorisera) des phrases japonaises en vecteurs numériques. Dans cet article, nous utiliserons le modèle en lien ci-dessous.
Abordons maintenant certains points à noter lors de la sélection d'un modèle japonais dans la version 8.9.
Pour commencer, seul l'algorithme de modèle BERT est pris en charge. Vérifiez les tags sur Hugging Face ainsi que d'autres informations pour confirmer que le modèle NLP souhaité est un modèle BERT entraîné.
De plus, pour les tâches BERT et les autres tâches de NLP, des tokens sont ensuite "pré-générés" pour le texte saisi, ce qui signifie que le texte est divisé en unités au niveau du mot. Dans ce cas, un moteur d'analyse morphologique de la langue japonaise est utilisé pour pré-générer des tokens pour notre texte japonais. Elasticsearch 8.9 prend en charge l'analyse morphologique avec MeCab. Sur la page d'un modèle de Hugging Face, ouvrez l'onglet "Fichiers et versions" et affichez le contenu du fichier tokenizer_config.json. Confirmez que la valeur de word_tokenizer_type est mecab.
{
"do_lower_case": false,
"word_tokenizer_type": "mecab",
"subword_tokenizer_type": "wordpiece",
"mecab_kwargs": {
"mecab_dic": "unidic_lite"
}
}
Malheureusement, si la valeur du modèle que vous souhaitez utiliser est différente de mecab pour word_tokenizer_type, cela signifie que ce modèle n'est pas encore pris en charge par Elasticsearch. Nous serions ravis de recevoir vos commentaires concernant les types de générateurs de tokens de mots spécifiques (word_tokenizer_type) dont la prise en charge nécessaire.
Une fois que vous avez décidé d'un modèle à importer, les étapes nécessaires pour l'importer sont les mêmes que pour le modèle anglais. Commencez par utiliser eland_import_hub_model pour importer le modèle dans Elasticsearch. Consultez cette page pour savoir comment utiliser eland_import_hub_model.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
Une fois le modèle correctement importé, il sera affiché sous Machine Learning > Gestion des modèles > Modèles entraînés dans Kibana. Ouvrez l'onglet de modèle “Config” pour voir si “bert_ja” est utilisé pour la génération de modèles et si le modèle est configuré correctement pour gérer le japonais.
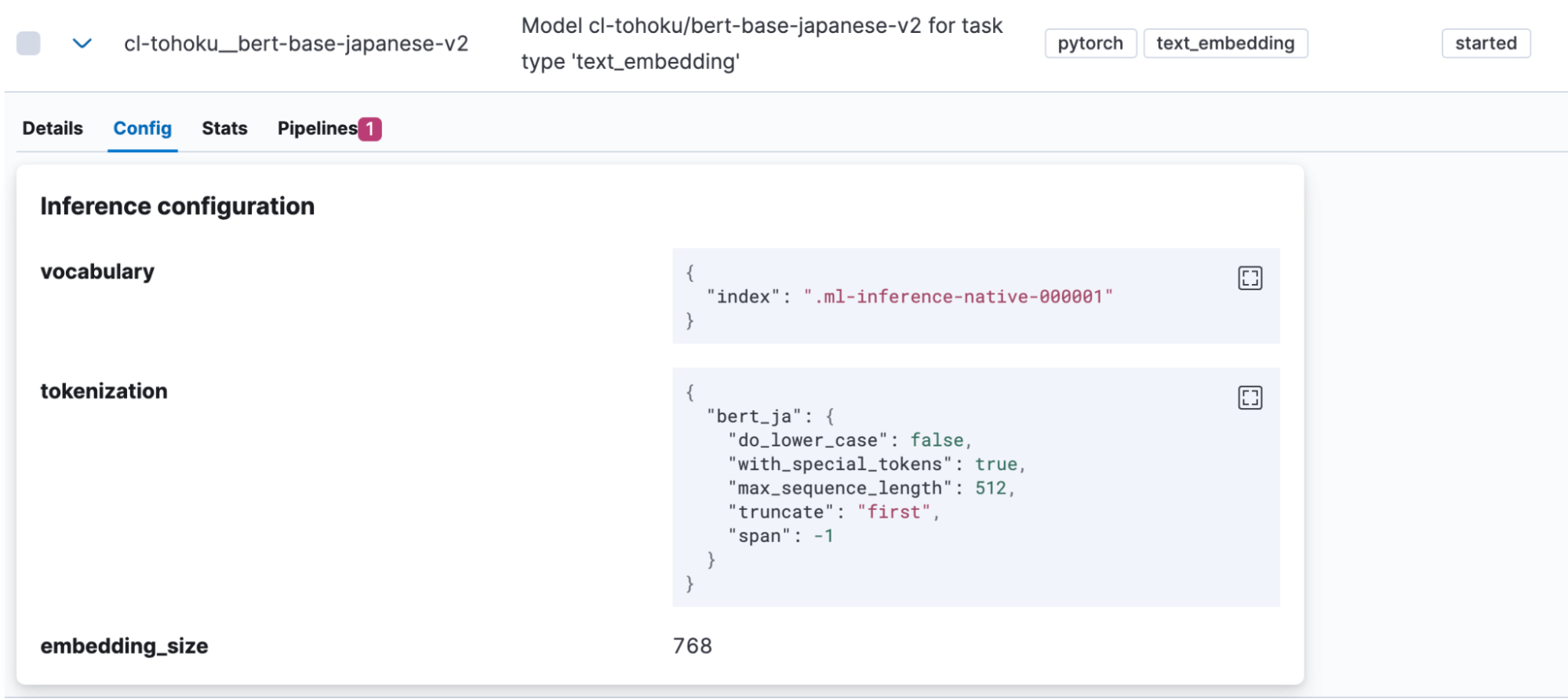
Une fois le téléchargement du modèle terminé, il faut le tester. Cliquez sur un bouton de la colonne Actions pour ouvrir le menu.
Sélectionnez "Tester le modèle", puis saisissez n'importe quelle expression japonaise sous "Saisir le texte" et cliquez sur le bouton "Test".
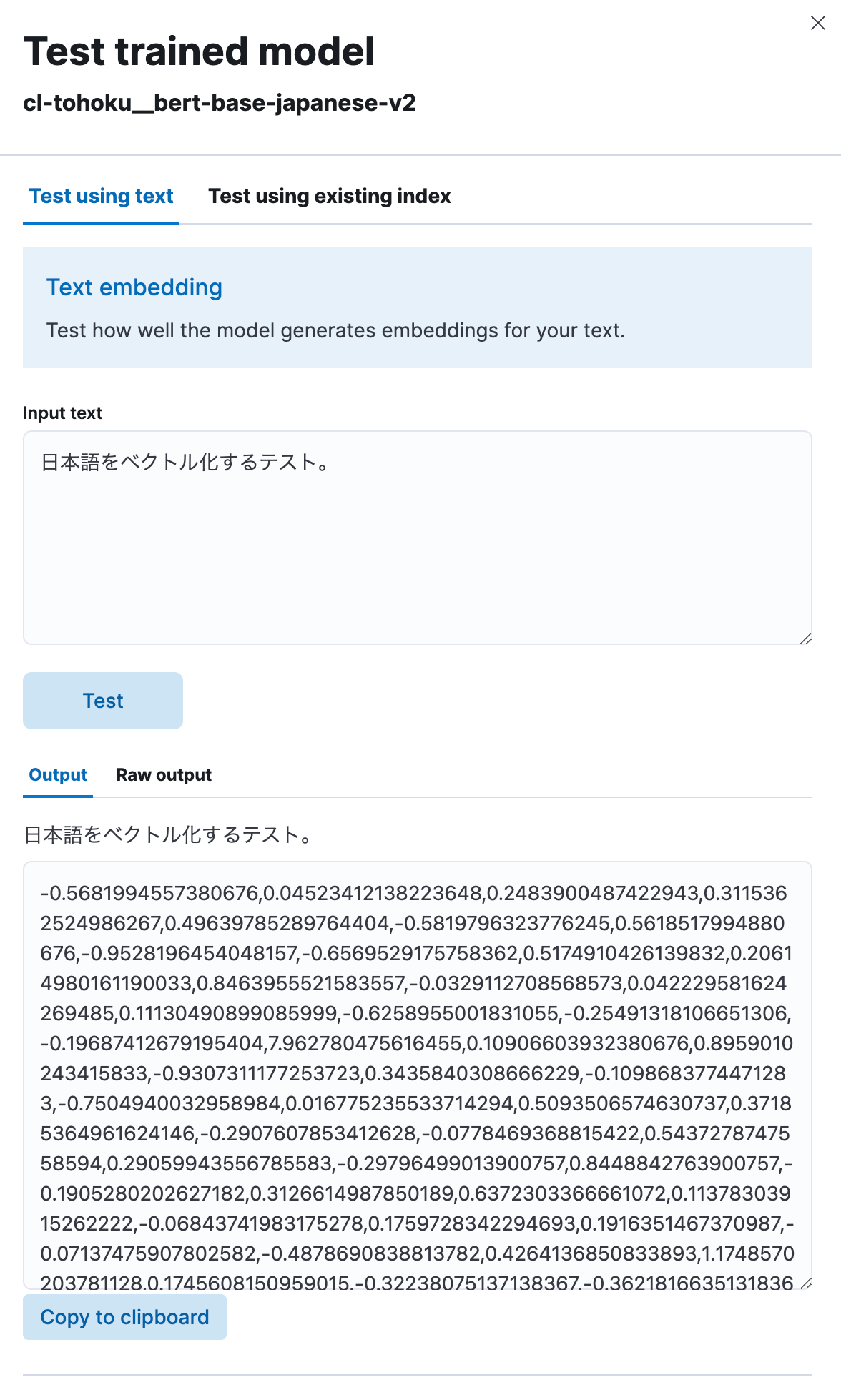
Vous pourrez ensuite voir que le modèle a vectorisé le texte japonais que vous avez saisi en chaîne numérique, comme montré ici. Il semble qu'il fonctionne correctement.
Mise en œuvre de la recherche sémantique à l'aide de plongements vectoriels
Maintenant que le modèle a été téléchargé, nous pouvons implémenter la fonctionnalité de recherche sémantique (recherche vectorielle) dans Elasticsearch.
Pour commencer, afin d'effectuer une recherche vectorielle, il est nécessaire d'indexer les valeurs vectorielles dans lesquelles le texte japonais d'origine a été intégré. Pour ce faire, nous créerons un pipeline qui inclut un processeur d'inférence pour vectoriser le texte japonais avant qu'il soit saisi dans l'index, à l'aide du modèle téléchargé précédemment.
PUT _ingest/pipeline/japanese-text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Lorsque le processeur d'inférence est utilisé, le modèle indiqué dans model_id est appliqué au texte enregistré dans le champ cible (dans ce cas, le titre) et la sortie de celui-ci est stockée dans target_field. De plus, chaque modèle attend un champ différent (dans ce cas, text_field) pour la valeur de saisie du processus. Pour cette raison, field_map est utilisé pour indiquer la correspondance entre le véritable champ de saisie de la cible du processus et le nom de champ attendu par le modèle de ML.
Une fois le pipeline configuré, il peut être utilisé pour créer des index. Étant donné que des champs seront nécessaires dans ces index pour stocker les vecteurs, nous définirons le mapping approprié. Dans l'exemple ci-dessous, le champ text_embedding.predicted_value est défini de sorte à contenir des données dense_vector à 768 dimensions. Veuillez noter que le nombre de dimensions varie selon les modèles. Vérifiez la page du modèle sur Hugging Face (valeur hidden_size dans le config.json du modèle) ou ailleurs, et définissez un nombre approprié.
PUT japanese-text-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
S'il existe déjà un index qui inclut les données de texte japonais ciblées pour la recherche, alors l'API de réindexation peut être utilisée. Dans cet exemple, les données de texte originales se trouvent dans l'index de texte japanese-text. Un document qui contient la vectorisation de ce texte est inscrit dans l'index japanese-text-embeddings.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "japanese-text"
},
"dest": {
"index": "japanese-text-with-embeddings",
"pipeline": "japanese-text-embeddings"
}
}
Sinon, un document peut être inscrit directement à des fins de test en précisant un pipeline créé comme montré ci-dessous, et en le stockant dans l'index.
POST japanese-text-with-embeddings/_doc?pipeline=japanese-text-embeddings
{
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。"
}
Une fois le document vectorisé inscrit, il est enfin possible d'exécuter une recherche. Une recherche par kNN (k plus proches voisins) est une méthode disponible qui utilise les vecteurs. Nous allons maintenant exécuter une recherche vectorielle kNN en utilisant l'option query_vector_builder dans l'API standard _search. Lorsque query_vector_builder est utilisé, le modèle indiqué dans model_id peut servir à convertir le texte de model_text en requête contenant un facteur dans lequel le texte est intégré.
GET japanese-text-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": "日本語でElasticsearchを検索したい"
}
}
}
}
Lorsque cette requête de recherche est exécutée, vous recevez le type de réponse suivant.
"hits": [
{
"_index": "japanese-text-with-embeddings",
"_id": "vOD6MIoBdRdLZd7EKaBy",
"_score": 0.82438844,
"_source": {
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。",
"text_embedding": {
"predicted_value": [
-0.13586345314979553,
-0.6291824579238892,
0.32779985666275024,
0.36690405011177063,
(略、768次元のベクトルが表示される)
],
"model_id": "cl-tohoku__bert-base-japanese-v2"
}
}
}
]
La recherche a abouti ! La recherche contient également des champs dans lesquels le japonais a été intégré. Dans la plupart des cas d'utilisation réels, il n'est pas nécessaire que ce texte soit inclus dans la réponse. Dans ces cas-là, utilisez le paramètre _source ou une autre méthode pour exclure ces informations de la réponse (ou réaliser une autre action similaire).
Pour ajuster le classement des recherches, la fonctionnalité de Fusion des rangs réciproques (RRF), qui mélange adroitement les résultats des recherches vectorielles et des recherches standard par mots-clés, a été publiée. Pensez également à y jeter un œil.
Cela conclut notre discussion sur comment activer la recherche sémantique à l'aide de la recherche vectorielle. Bien que la configuration de cette fonctionnalité puisse nécessiter davantage de travail qu'une recherche standard, et qu'il est possible que vous rencontriez du vocabulaire de Machine Learning unique, vous pourrez exécuter des recherches quasiment identiques à des recherches normales une fois la phase de configuration terminée ; alors n'hésitez pas à l'essayer.
Classification de textes (analyse des sentiments)
Puisque nous avons vu que nous pouvions utiliser la recherche vectorielle à l'aide des k plus proches voisins en japonais, regardons comment utiliser d'autres tâches de NLP de la même façon.
La classification de textes est une tâche dans laquelle la saisie de texte est placée dans certaines catégories. Pour cet exemple, nous utiliserons un modèle d'analyse des sentiments trouvé sur Hugging Face, qui évalue si la saisie de texte japonais s'accompagne d'un sentiment positif ou d'un sentiment négatif (koheiduck/bert-japanese-finetuned-sentiment). En regardant son tokenizer_config.json, nous pouvons voir que ce modèle utilise également mecab comme word_tokenizer_type, il peut donc être utilisé avec le bert_ja d'Elasticsearch.
Comme nous l'avons fait précédemment, utilisez eland_import_hub_model pour importer le modèle dans Elasticsearch.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id koheiduck/bert-japanese-finetuned-sentiment \
--task-type text_classification \
--start
Une fois le modèle correctement importé, il sera affiché sous Machine Learning > Gestion des modèles > Modèles entraînés dans Kibana.
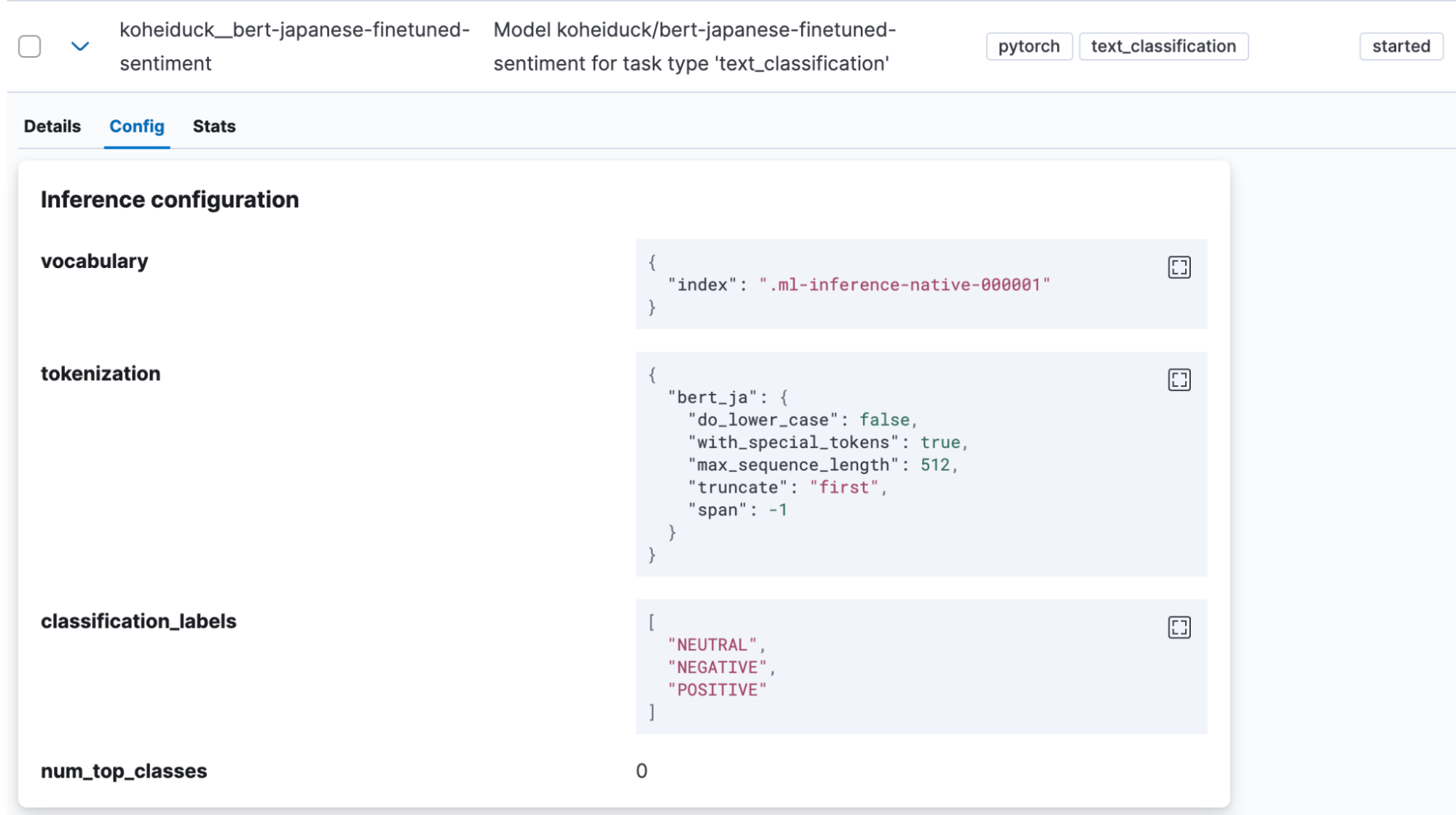
Dans ce cas également, cliquez sur “Tester le modèle” dans le menu Actions.
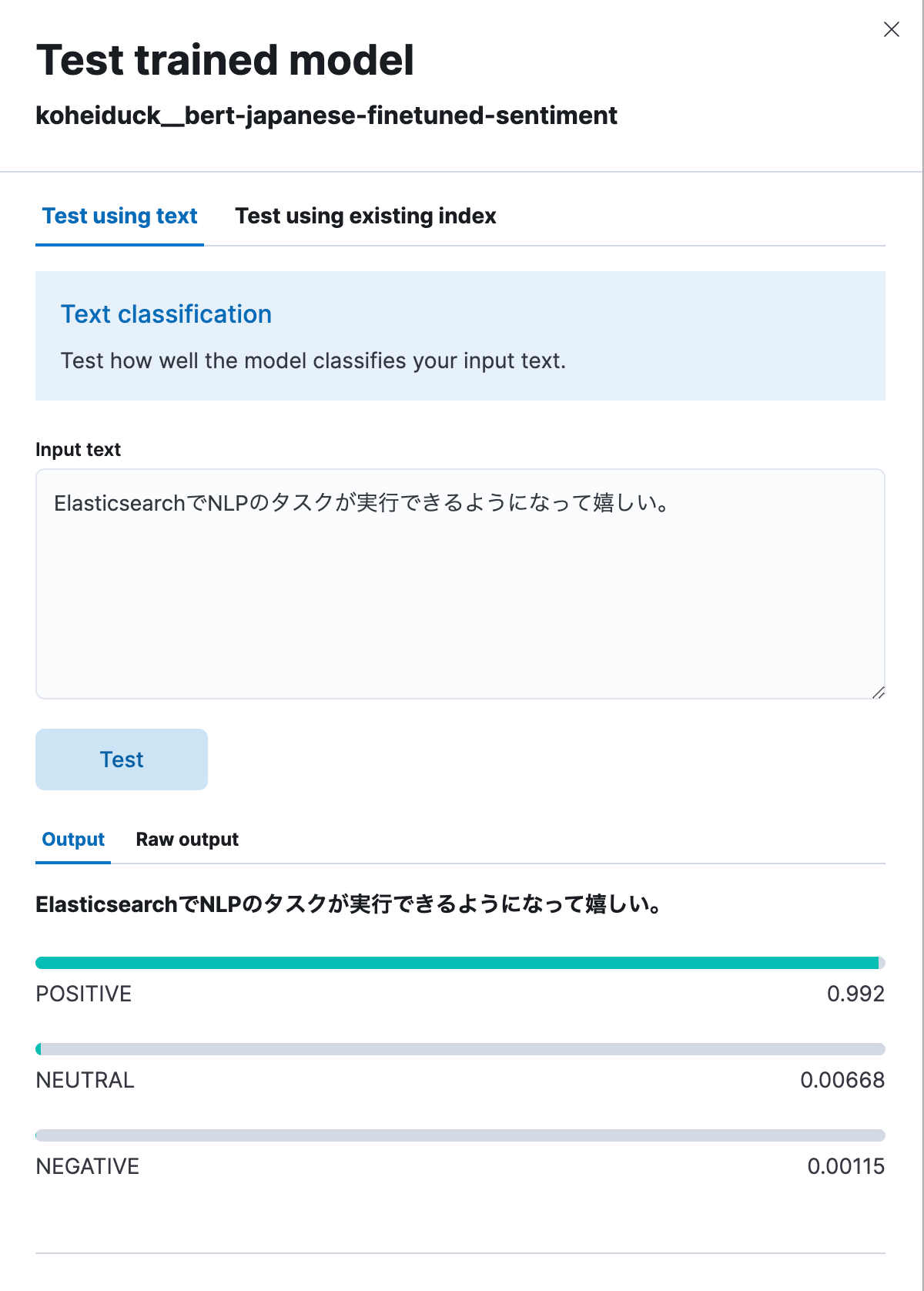
Comme précédemment, cela affichera une boîte de dialogue pour les tests. Saisissez ici le texte à classifier, et le texte sera classifié en POSITIF, NEUTRE ou NÉGATIF. Pour tester cela, saisissons la phrase suivante : "Je suis ravi de pouvoir désormais exécuter des tâches de NLP avec Elasticsearch." Comme montré ci-dessous, cela a généré un résultat positif à 99,2 %.
Vous trouverez ci-dessous le même processus exécuté via API.
POST _ml/trained_models/koheiduck__bert-japanese-finetuned-sentiment/_infer
{
"docs": [{"text_field": "ElasticsearchでNLPのタスクが実行できるようになって嬉しい。"}],
"inference_config": {
"text_classification": {
"num_top_classes": 3
}
}
}
La réponse est la suivante :
{
"inference_results": [
{
"predicted_value": "POSITIVE",
"top_classes": [
{
"class_name": "POSITIVE",
"class_probability": 0.9921651090124636,
"class_score": 0.9921651090124636
},
{
"class_name": "NEUTRAL",
"class_probability": 0.006682728902566756,
"class_score": 0.006682728902566756
},
{
"class_name": "NEGATIVE",
"class_probability": 0.0011521620849697567,
"class_score": 0.0011521620849697567
}
],
"prediction_probability": 0.9921651090124636
}
]
}Puisque ce processus peut également être exécuté avec le processeur d'inférence, il est possible de joindre ces résultats d'analyse avant l'indexation du texte japonais. Par exemple, le fait d'appliquer ce processus aux commentaires de produits spécifiques pourrait aider à convertir les notes des utilisateurs pour ces produits en valeurs numériques.
Commentaires
Dans la version 8.9 d'Elasticsearch, la compatibilité du modèle NLP pour la langue japonaise en est encore à l'étape de préversion technique. Veuillez contacter Elastic® si vous rencontrez des bugs ou avez besoin d'aide avec les algorithmes non-BERT ou les générateurs de tokens non-MeCab, etc.
Utiliser GitHub Issues est le meilleur moyen d'envoyer des commentaires à Elastic. Dans le référentiel elastic/elasticsearch, sous "Problèmes", ajoutez la balise :ml et présentez votre demande. L'équipe concernée mènera son enquête.
En tant qu'architecte consultant pour Elastic (je ne fais donc pas partie de l'équipe de développement), j'ai pu ajouter la prise en charge de la langue japonaise en envoyant une requête d'extraction pour une modification via GitHub en tant que contributeur externe. Si vous êtes développeur et souhaitez demander l'ajout d'une fonctionnalité pour un cas d'utilisation spécifique, n'hésitez pas à essayer, comme je l'ai fait.
Conclusion
Pour le moment, Elastic investit de nombreuses ressources dans l'implémentation d'une fonctionnalité de NLP à l'aide du Machine Learning dans ses fonctionnalités de recherche, et il existe de plus en plus de fonctions similaires pouvant être exécutées dans Elasticsearch. Cependant, la plupart des fonctionnalités sont d'abord publiées avec une compatibilité pour la langue anglaise et une compatibilité limitée pour les autres langues.
Toutefois, nous sommes vraiment ravis que la compatibilité avec le japonais ait été ajoutée. Nous espérons que ces nouvelles fonctionnalités Elasticsearch vous aideront à donner plus de sens à vos recherches.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'intelligence artificielle générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'intelligence artificielle avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'intelligence artificielle ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer